 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Ear SpO2 for Classification of Cognitive Workload
Jan 03, 2021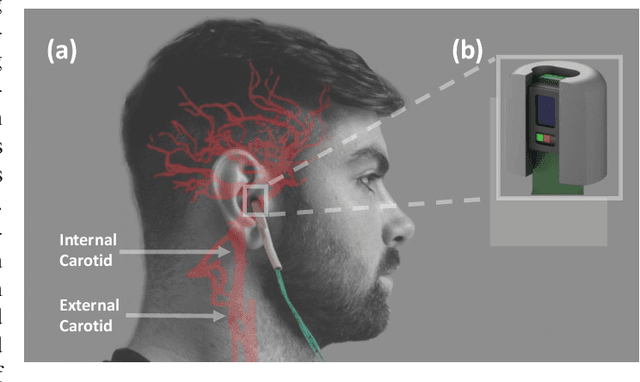
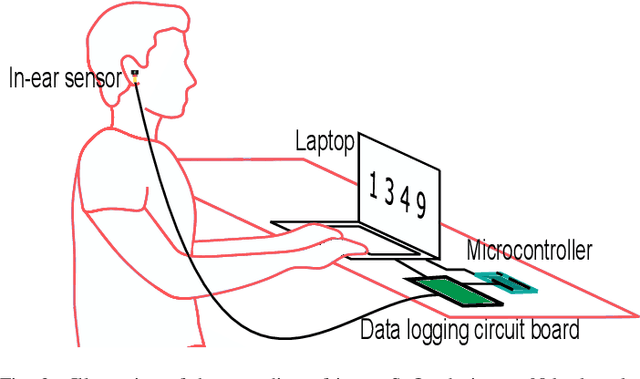
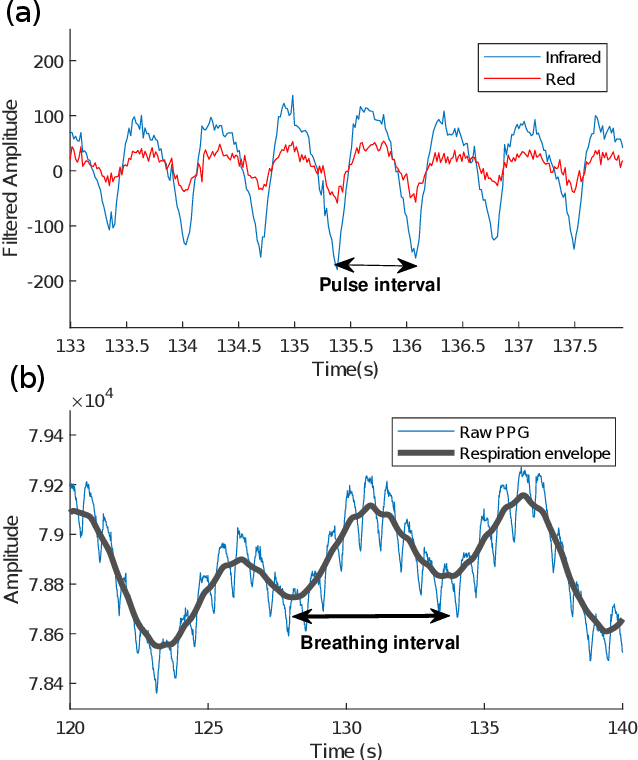
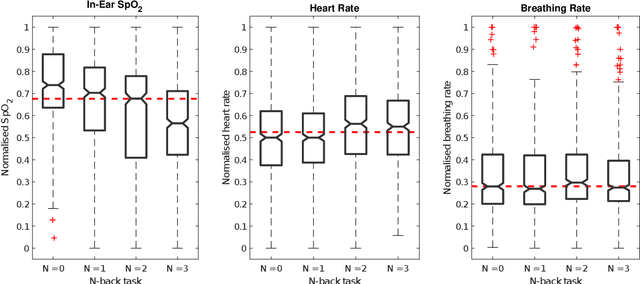
Classification of cognitive workload promises immense benefit in diverse areas ranging from driver safety to augmenting human capability through closed loop brain computer interface. The brain is the most metabolically active organ in the body and increases its metabolic activity and thus oxygen consumption with increasing cognitive demand. In this study, we explore the feasibility of in-ear SpO2 cognitive workload tracking. To this end, we preform cognitive workload assessment in 8 subjects, based on an N-back task, whereby the subjects are asked to count and remember the number of odd numbers displayed on a screen in 5 second windows. The 2 and 3-back tasks lead to either the lowest median absolute SpO2 or largest median decrease in SpO2 in all of the subjects, indicating a robust and measurable decrease in blood oxygen in response to increased cognitive workload. Using features derived from in-ear pulse oximetry, including SpO2, pulse rate and respiration rate, we were able to classify the 4 N-back task categories, over 5 second epochs, with a mean accuracy of 94.2%. Moreover, out of 21 total features, the 9 most important features for classification accuracy were all SpO2 related features. The findings suggest that in-ear SpO2 measurements provide valuable information for classification of cognitive workload over short time windows, which together with the small form factor promises a new avenue for real time cognitive workload tracking.
Learning to Observe: Approximating Human Perceptual Thresholds for Detection of Suprathreshold Image Transformations
Dec 13, 2019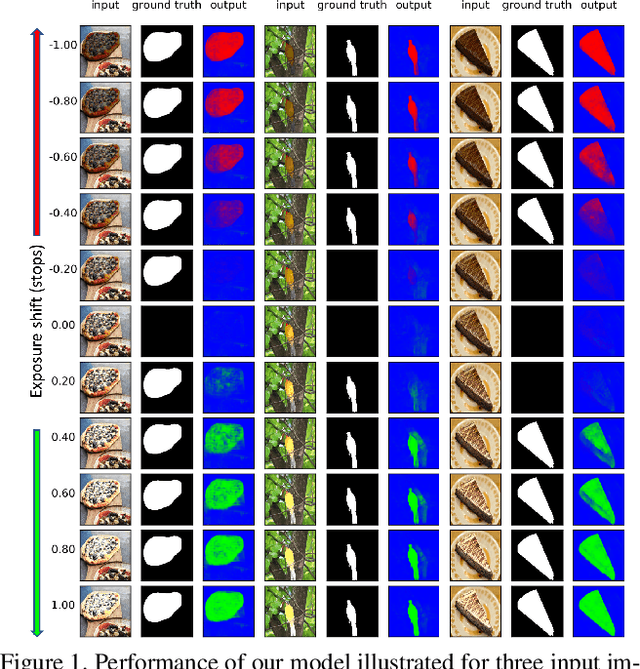
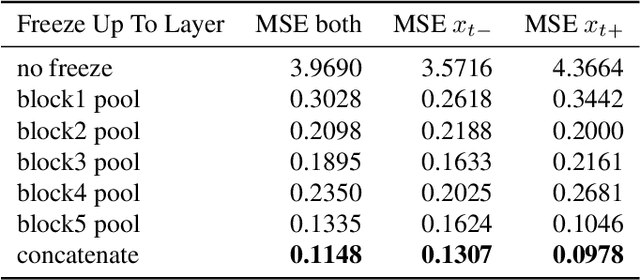
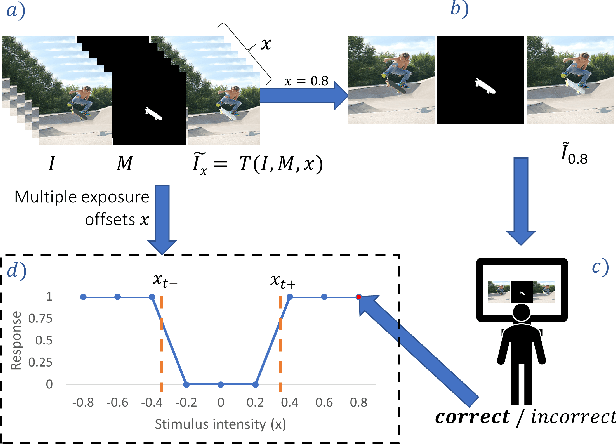
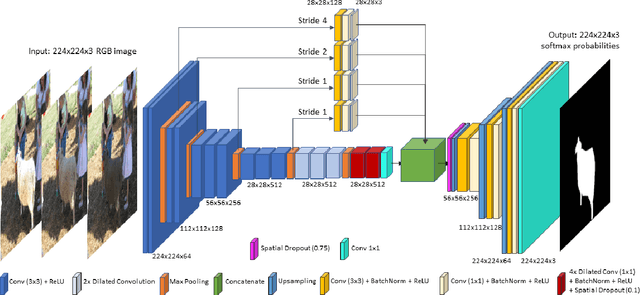
Many tasks in computer vision are often calibrated and evaluated relative to human perception. In this paper, we propose to directly approximate the perceptual function performed by human observers completing a visual detection task. Specifically, we present a novel methodology for learning to detect image transformations visible to human observers through approximating perceptual thresholds. To do this, we carry out a subjective two-alternative forced-choice study to estimate perceptual thresholds of human observers detecting local exposure shifts in images. We then leverage transformation equivariant representation learning to overcome issues of limited perceptual data. This representation is then used to train a dense convolutional classifier capable of detecting local suprathreshold exposure shifts - a distortion common to image composites. In this context, our model is able to approximate perceptual thresholds with an average error of 0.1148 exposure stops between empirical and predicted thresholds. It can also be trained to detect a range of different pixel-wise transformation.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.