 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Musical Style with Transformer Autoencoders
Dec 10, 2019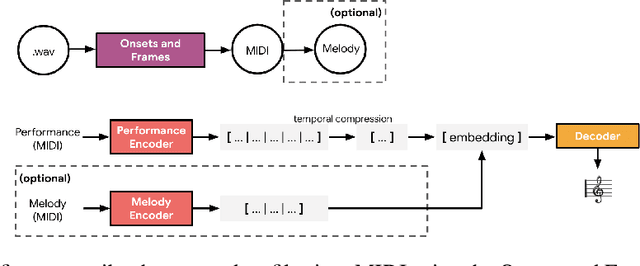


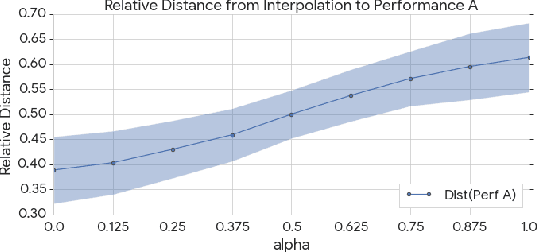
We consider the problem of learning high-level controls over the global structure of sequence generation, particularly in the context of symbolic music generation with complex language models. In this work, we present the Transformer autoencoder, which aggregates encodings of the input data across time to obtain a global representation of style from a given performance. We show it is possible to combine this global embedding with other temporally distributed embeddings, enabling improved control over the separate aspects of performance style and and melody. Empirically, we demonstrate the effectiveness of our method on a variety of music generation tasks on the MAESTRO dataset and a YouTube dataset with 10,000+ hours of piano performances, where we achieve improvements in terms of log-likelihood and mean listening scores as compared to relevant baselines.
Enabling Factorized Piano Music Modeling and Generation with the MAESTRO Dataset
Oct 30, 2018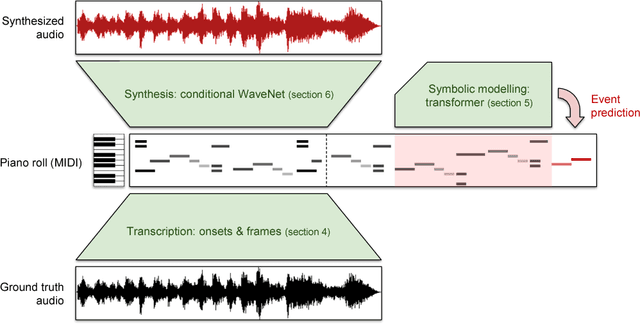

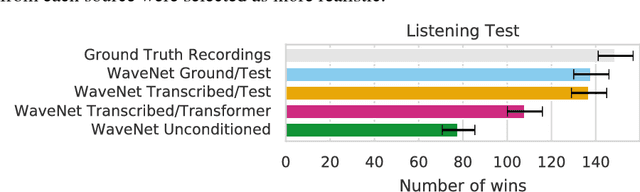
Generating musical audio directly with neural networks is notoriously difficult because it requires coherently modeling structure at many different timescales. Fortunately, most music is also highly structured and can be represented as discrete note events played on musical instruments. Herein, we show that by using notes as an intermediate representation, we can train a suite of models capable of transcribing, composing, and synthesizing audio waveforms with coherent musical structure on timescales spanning six orders of magnitude (~0.1 ms to ~100 s), a process we call Wave2Midi2Wave. This large advance in the state of the art is enabled by our release of the new MAESTRO (MIDI and Audio Edited for Synchronous TRacks and Organization) dataset, composed of over 172 hours of virtuosic piano performances captured with fine alignment (~3 ms) between note labels and audio waveforms. The networks and the dataset together present a promising approach toward creating new expressive and interpretable neural models of music.
Piano Genie
Oct 11, 2018
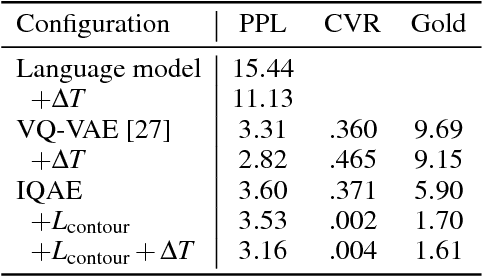
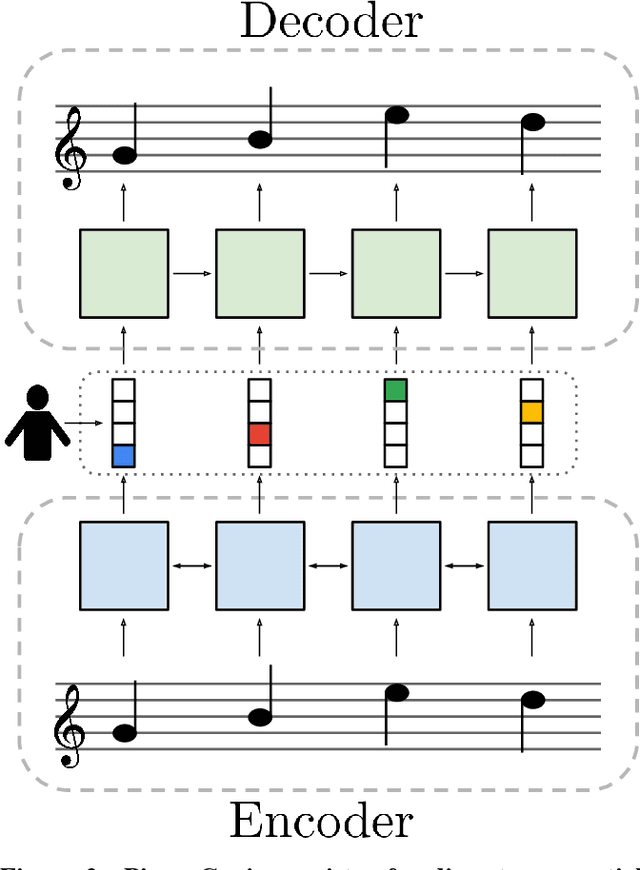
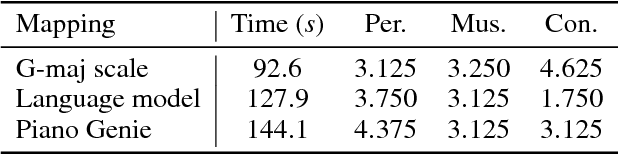
We present Piano Genie, an intelligent controller which allows non-musicians to improvise on the piano. With Piano Genie, a user performs on a simple interface with eight buttons, and their performance is decoded into the space of plausible piano music in real time. To learn a suitable mapping procedure for this problem, we train recurrent neural network autoencoders with discrete bottlenecks: an encoder learns an appropriate sequence of buttons corresponding to a piano piece, and a decoder learns to map this sequence back to the original piece. During performance, we substitute a user's input for the encoder output, and play the decoder's prediction each time the user presses a button. To improve the interpretability of Piano Genie's performance mechanics, we impose musically-salient constraints over the encoder's outputs.
Music Transformer
Oct 10, 2018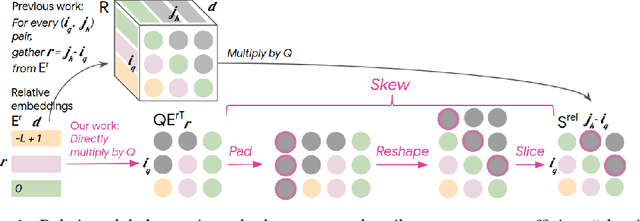

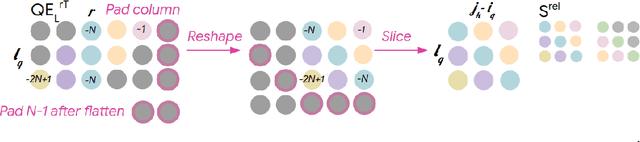

Music relies heavily on repetition to build structure and meaning. Self-reference occurs on multiple timescales, from motifs to phrases to reusing of entire sections of music, such as in pieces with ABA structure. The Transformer (Vaswani et al., 2017), a sequence model based on self-attention, has achieved compelling results in many generation tasks that require maintaining long-range coherence. This suggests that self-attention might also be well-suited to modeling music. In musical composition and performance, however, relative timing is critically important. Existing approaches for representing relative positional information in the Transformer modulate attention based on pairwise distance (Shaw et al., 2018). This is impractical for long sequences such as musical compositions since their memory complexity is quadratic in the sequence length. We propose an algorithm that reduces the intermediate memory requirements to linear in the sequence length. This enables us to demonstrate that a Transformer with our modified relative attention mechanism can generate minute-long (thousands of steps) compositions with compelling structure, generate continuations that coherently elaborate on a given motif, and in a seq2seq setup generate accompaniments conditioned on melodies. We evaluate the Transformer with our relative attention mechanism on two datasets, JSB Chorales and Piano-e-competition, and obtain state-of-the-art results on the latter.
This Time with Feeling: Learning Expressive Musical Performance
Aug 10, 2018
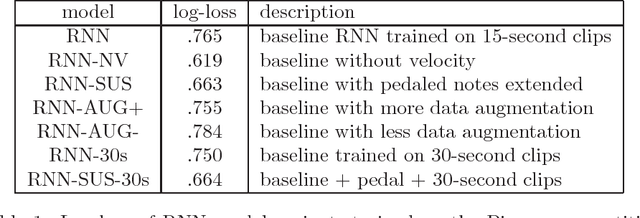

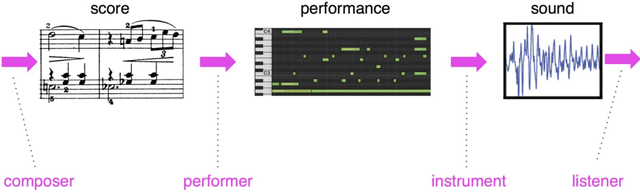
Music generation has generally been focused on either creating scores or interpreting them. We discuss differences between these two problems and propose that, in fact, it may be valuable to work in the space of direct $\it performance$ generation: jointly predicting the notes $\it and$ $\it also$ their expressive timing and dynamics. We consider the significance and qualities of the data set needed for this. Having identified both a problem domain and characteristics of an appropriate data set, we show an LSTM-based recurrent network model that subjectively performs quite well on this task. Critically, we provide generated examples. We also include feedback from professional composers and musicians about some of these examples.
Onsets and Frames: Dual-Objective Piano Transcription
Jun 05, 2018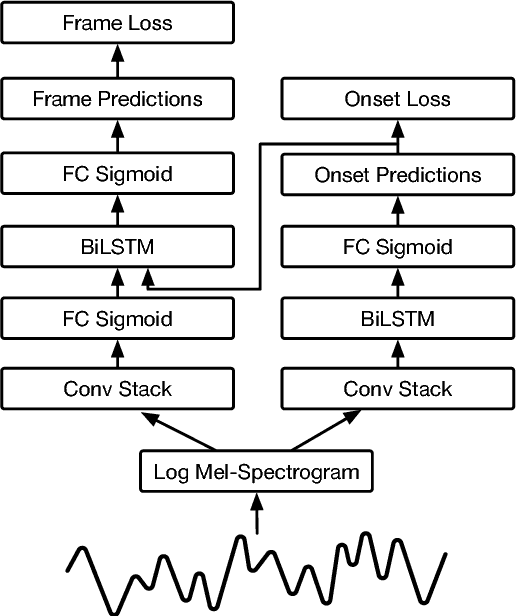

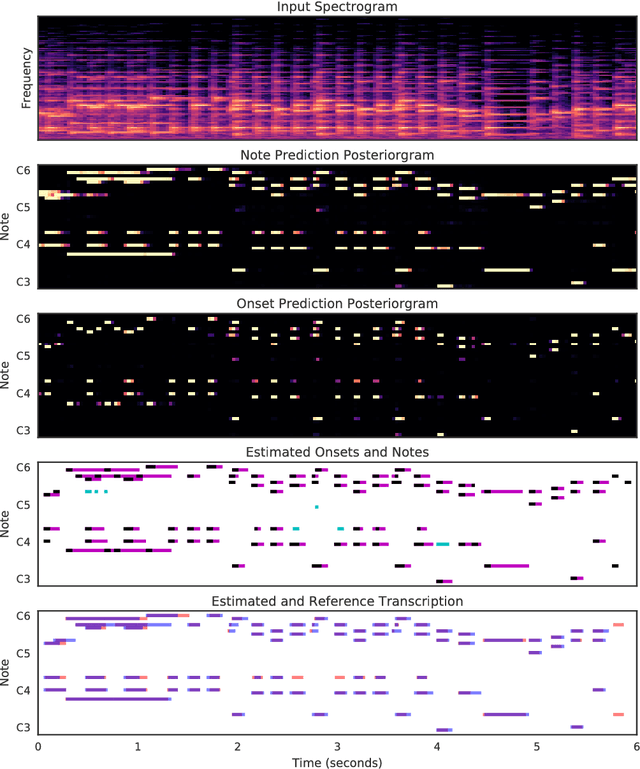
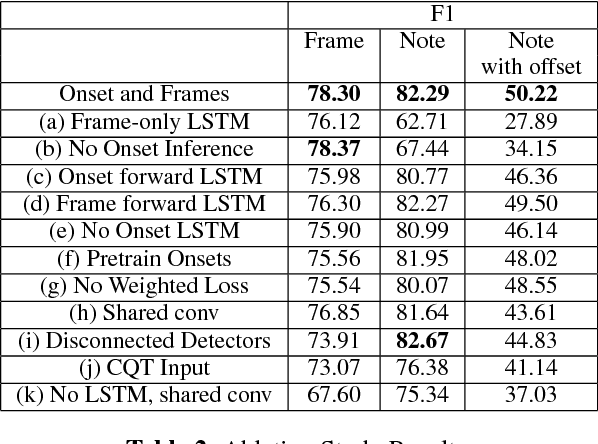
We advance the state of the art in polyphonic piano music transcription by using a deep convolutional and recurrent neural network which is trained to jointly predict onsets and frames. Our model predicts pitch onset events and then uses those predictions to condition framewise pitch predictions. During inference, we restrict the predictions from the framewise detector by not allowing a new note to start unless the onset detector also agrees that an onset for that pitch is present in the frame. We focus on improving onsets and offsets together instead of either in isolation as we believe this correlates better with human musical perception. Our approach results in over a 100% relative improvement in note F1 score (with offsets) on the MAPS dataset. Furthermore, we extend the model to predict relative velocities of normalized audio which results in more natural-sounding transcriptions.
Learning a Latent Space of Multitrack Measures
Jun 01, 2018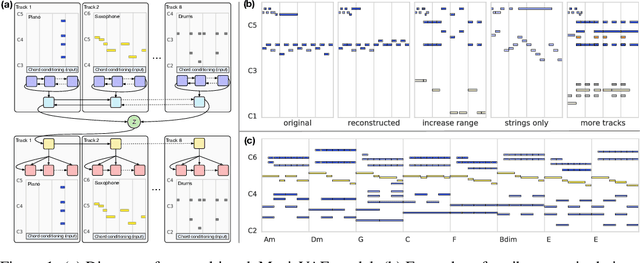
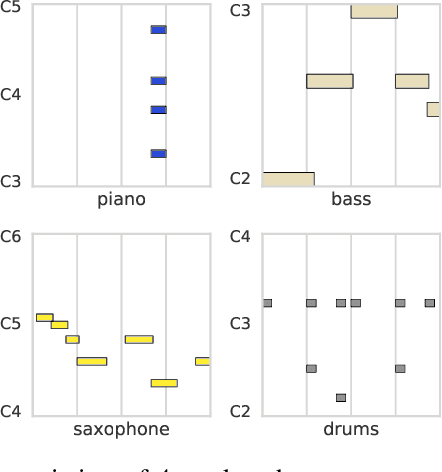
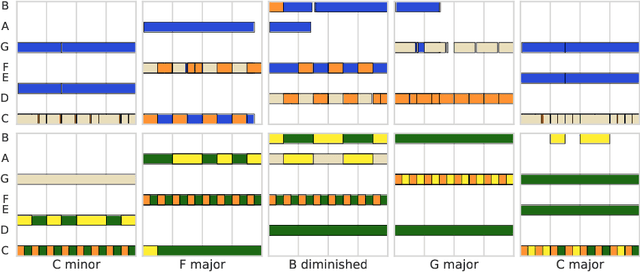
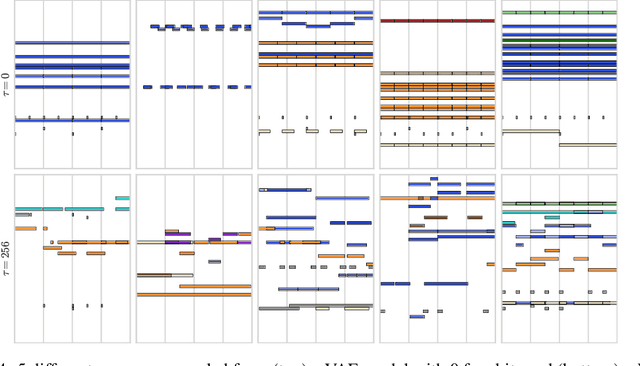
Discovering and exploring the underlying structure of multi-instrumental music using learning-based approaches remains an open problem. We extend the recent MusicVAE model to represent multitrack polyphonic measures as vectors in a latent space. Our approach enables several useful operations such as generating plausible measures from scratch, interpolating between measures in a musically meaningful way, and manipulating specific musical attributes. We also introduce chord conditioning, which allows all of these operations to be performed while keeping harmony fixed, and allows chords to be changed while maintaining musical "style". By generating a sequence of measures over a predefined chord progression, our model can produce music with convincing long-term structure. We demonstrate that our latent space model makes it possible to intuitively control and generate musical sequences with rich instrumentation (see https://goo.gl/s2N7dV for generated audio).