Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis Time with Feeling: Learning Expressive Musical Performance
Paper and Code

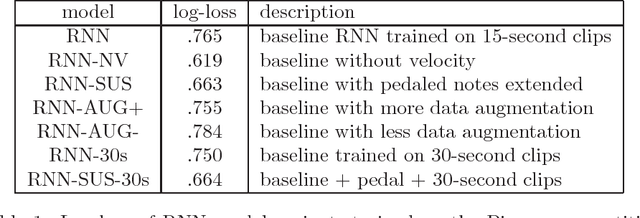

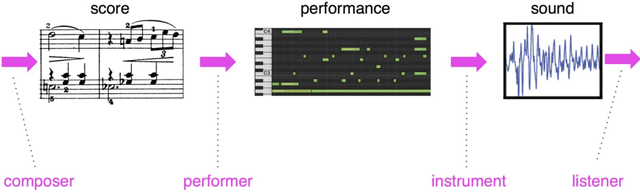
Music generation has generally been focused on either creating scores or interpreting them. We discuss differences between these two problems and propose that, in fact, it may be valuable to work in the space of direct $\it performance$ generation: jointly predicting the notes $\it and$ $\it also$ their expressive timing and dynamics. We consider the significance and qualities of the data set needed for this. Having identified both a problem domain and characteristics of an appropriate data set, we show an LSTM-based recurrent network model that subjectively performs quite well on this task. Critically, we provide generated examples. We also include feedback from professional composers and musicians about some of these examples.
* Includes links to urls for audio samples
View paper on