 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Information Accelerates Learning in RL
Jul 24, 2020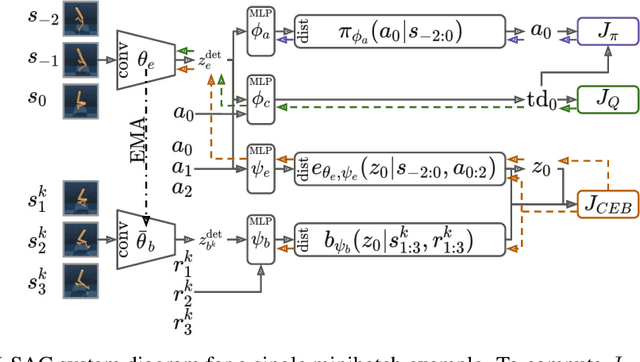
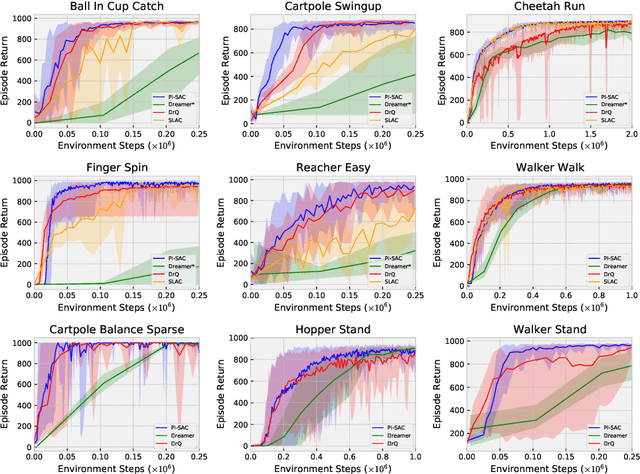
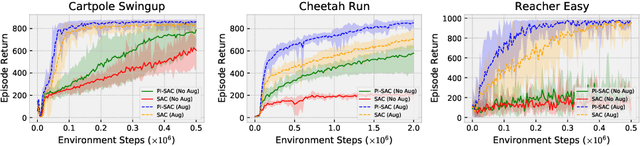
The Predictive Information is the mutual information between the past and the future, I(X_past; X_future). We hypothesize that capturing the predictive information is useful in RL, since the ability to model what will happen next is necessary for success on many tasks. To test our hypothesis, we train Soft Actor-Critic (SAC) agents from pixels with an auxiliary task that learns a compressed representation of the predictive information of the RL environment dynamics using a contrastive version of the Conditional Entropy Bottleneck (CEB) objective. We refer to these as Predictive Information SAC (PI-SAC) agents. We show that PI-SAC agents can substantially improve sample efficiency over challenging baselines on tasks from the DM Control suite of continuous control environments. We evaluate PI-SAC agents by comparing against uncompressed PI-SAC agents, other compressed and uncompressed agents, and SAC agents directly trained from pixels.
Cycles in Causal Learning
Jul 24, 2020In the causal learning setting, we wish to learn cause-and-effect relationships between variables such that we can correctly infer the effect of an intervention. While the difference between a cyclic structure and an acyclic structure may be just a single edge, cyclic causal structures have qualitatively different behavior under intervention: cycles cause feedback loops when the downstream effect of an intervention propagates back to the source variable. We present three theoretical observations about probability distributions with self-referential factorizations, i.e. distributions that could be graphically represented with a cycle. First, we prove that self-referential distributions in two variables are, in fact, independent. Second, we prove that self-referential distributions in N variables have zero mutual information. Lastly, we prove that self-referential distributions that factorize in a cycle, also factorize as though the cycle were reversed. These results suggest that cyclic causal dependence may exist even where observational data suggest independence among variables. Methods based on estimating mutual information, or heuristics based on independent causal mechanisms, are likely to fail to learn cyclic casual structures. We encourage future work in causal learning that carefully considers cycles.
An Unsupervised Information-Theoretic Perceptual Quality Metric
Jun 11, 2020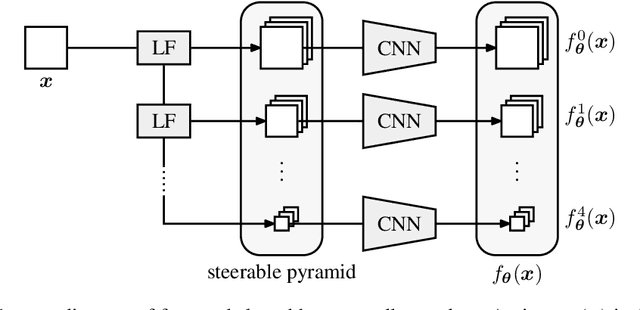
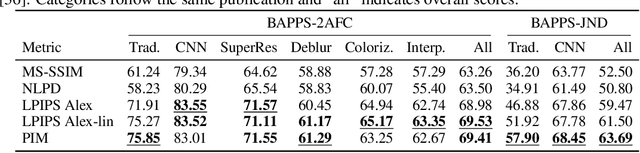
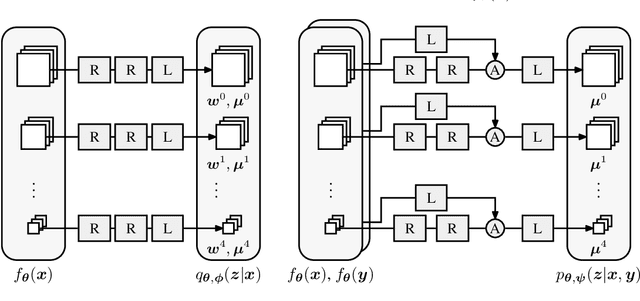
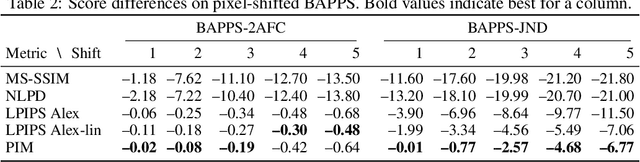
Tractable models of human perception have proved to be challenging to build. Hand-designed models such as MS-SSIM remain popular predictors of human image quality judgements due to their simplicity and speed. Recent modern deep learning approaches can perform better, but they rely on supervised data which can be costly to gather: large sets of class labels such as ImageNet, image quality ratings, or both. We combine recent advances in information-theoretic objective functions with a computational architecture informed by the physiology of the human visual system and unsupervised training on pairs of video frames, yielding our Perceptual Information Metric (PIM). We show that PIM is competitive with supervised metrics on the recent and challenging BAPPS image quality assessment dataset. We also perform qualitative experiments using the ImageNet-C dataset, and establish that our approach is robust with respect to architectural details.
CEB Improves Model Robustness
Feb 13, 2020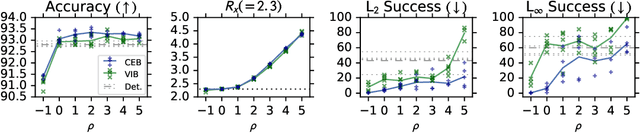
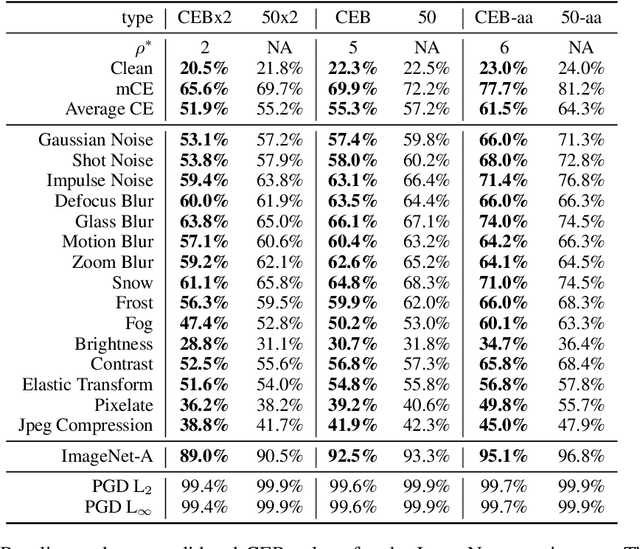
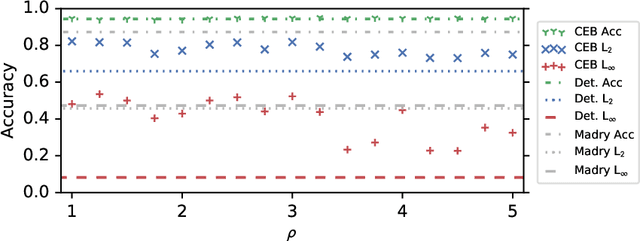
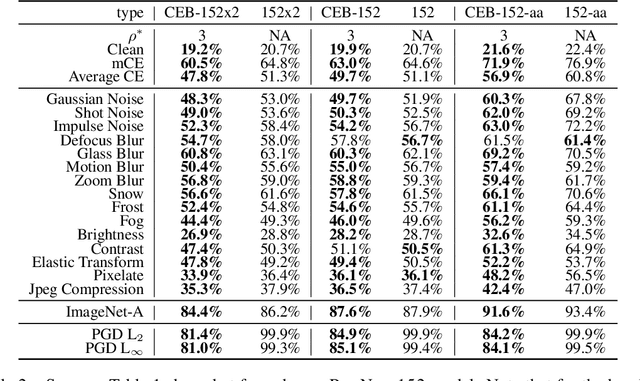
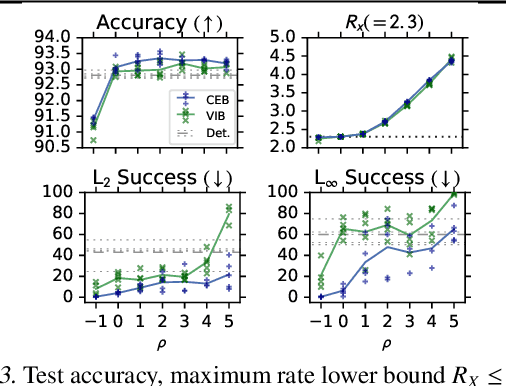
We demonstrate that the Conditional Entropy Bottleneck (CEB) can improve model robustness. CEB is an easy strategy to implement and works in tandem with data augmentation procedures. We report results of a large scale adversarial robustness study on CIFAR-10, as well as the ImageNet-C Common Corruptions Benchmark, ImageNet-A, and PGD attacks.
The Conditional Entropy Bottleneck
Feb 13, 2020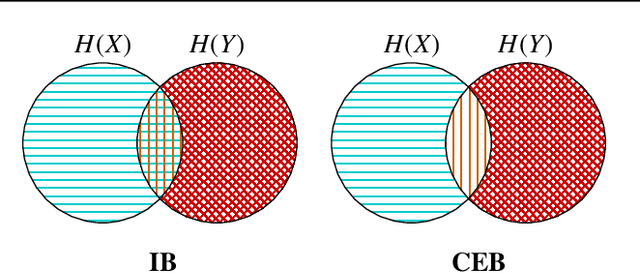
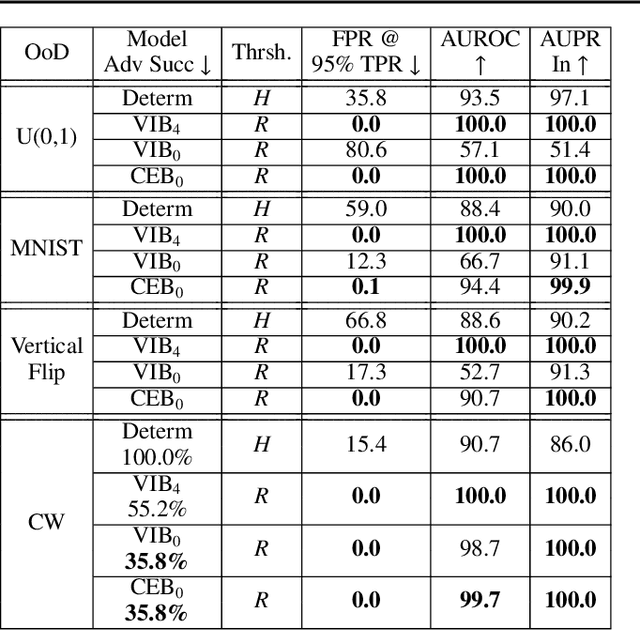
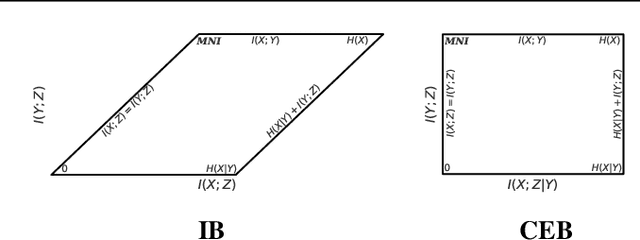
Much of the field of Machine Learning exhibits a prominent set of failure modes, including vulnerability to adversarial examples, poor out-of-distribution (OoD) detection, miscalibration, and willingness to memorize random labelings of datasets. We characterize these as failures of robust generalization, which extends the traditional measure of generalization as accuracy or related metrics on a held-out set. We hypothesize that these failures to robustly generalize are due to the learning systems retaining too much information about the training data. To test this hypothesis, we propose the Minimum Necessary Information (MNI) criterion for evaluating the quality of a model. In order to train models that perform well with respect to the MNI criterion, we present a new objective function, the Conditional Entropy Bottleneck (CEB), which is closely related to the Information Bottleneck (IB). We experimentally test our hypothesis by comparing the performance of CEB models with deterministic models and Variational Information Bottleneck (VIB) models on a variety of different datasets and robustness challenges. We find strong empirical evidence supporting our hypothesis that MNI models improve on these problems of robust generalization.
Phase Transitions for the Information Bottleneck in Representation Learning
Jan 07, 2020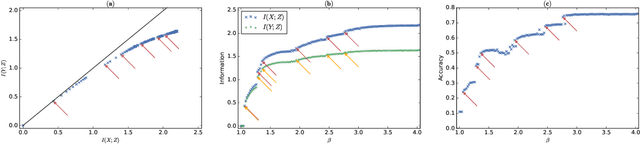
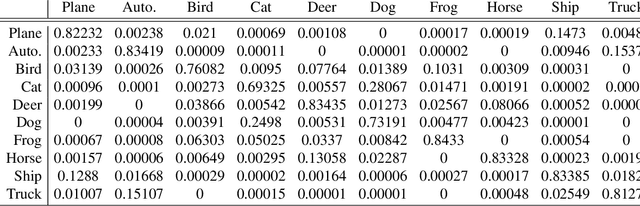
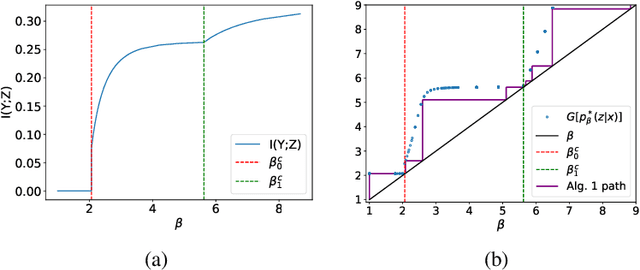
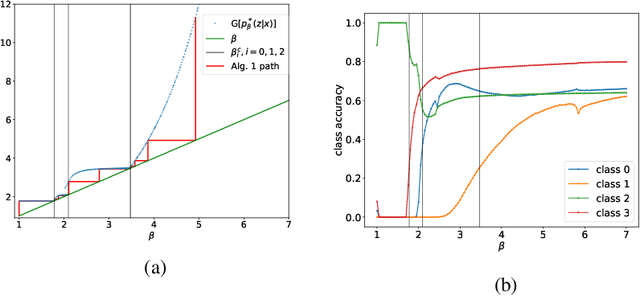
In the Information Bottleneck (IB), when tuning the relative strength between compression and prediction terms, how do the two terms behave, and what's their relationship with the dataset and the learned representation? In this paper, we set out to answer these questions by studying multiple phase transitions in the IB objective: $\text{IB}_\beta[p(z|x)] = I(X; Z) - \beta I(Y; Z)$ defined on the encoding distribution p(z|x) for input $X$, target $Y$ and representation $Z$, where sudden jumps of $dI(Y; Z)/d \beta$ and prediction accuracy are observed with increasing $\beta$. We introduce a definition for IB phase transitions as a qualitative change of the IB loss landscape, and show that the transitions correspond to the onset of learning new classes. Using second-order calculus of variations, we derive a formula that provides a practical condition for IB phase transitions, and draw its connection with the Fisher information matrix for parameterized models. We provide two perspectives to understand the formula, revealing that each IB phase transition is finding a component of maximum (nonlinear) correlation between $X$ and $Y$ orthogonal to the learned representation, in close analogy with canonical-correlation analysis (CCA) in linear settings. Based on the theory, we present an algorithm for discovering phase transition points. Finally, we verify that our theory and algorithm accurately predict phase transitions in categorical datasets, predict the onset of learning new classes and class difficulty in MNIST, and predict prominent phase transitions in CIFAR10.
Information-Bottleneck Approach to Salient Region Discovery
Jul 22, 2019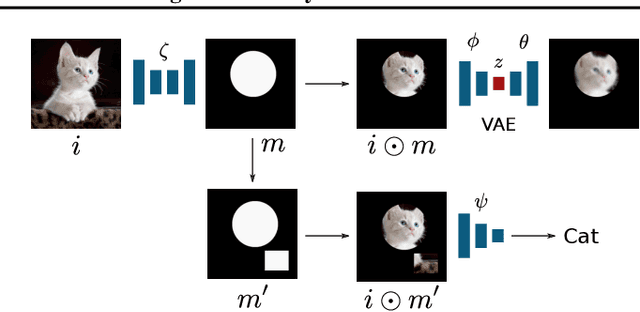



We propose a new method for learning image attention masks in a semi-supervised setting based on the Information Bottleneck principle. Provided with a set of labeled images, the mask generation model is minimizing mutual information between the input and the masked image while maximizing the mutual information between the same masked image and the image label. In contrast with other approaches, our attention model produces a Boolean rather than a continuous mask, entirely concealing the information in masked-out pixels. Using a set of synthetic datasets based on MNIST and CIFAR10 and the SVHN datasets, we demonstrate that our method can successfully attend to features known to define the image class.
Learnability for the Information Bottleneck
Jul 17, 2019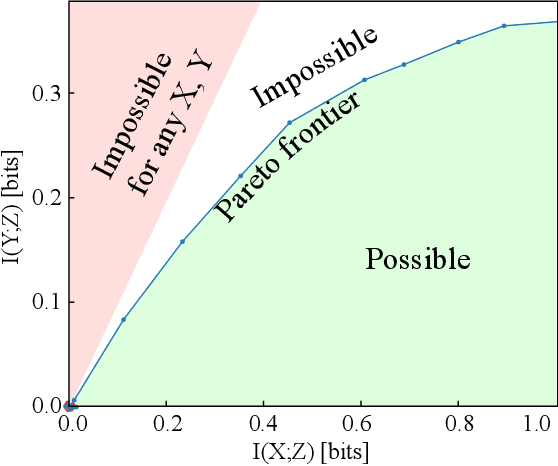
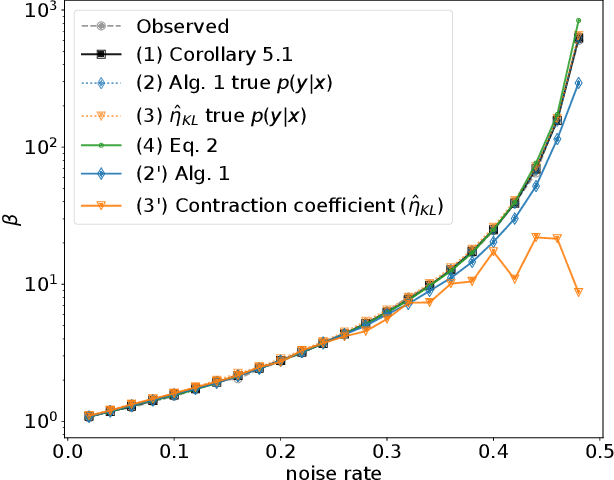
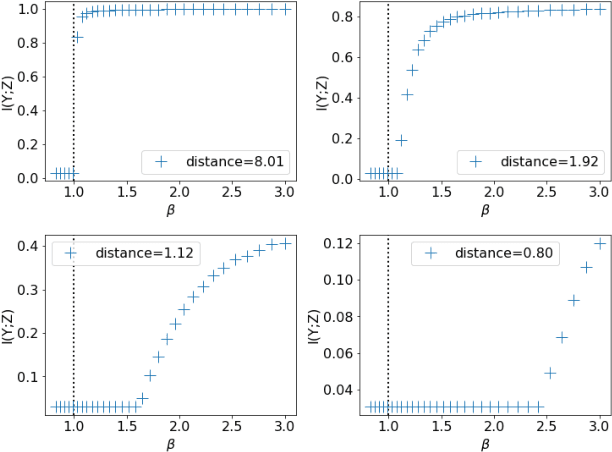
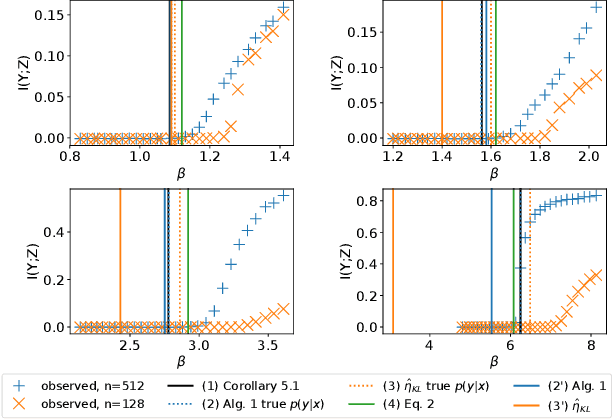
The Information Bottleneck (IB) method (\cite{tishby2000information}) provides an insightful and principled approach for balancing compression and prediction for representation learning. The IB objective $I(X;Z)-\beta I(Y;Z)$ employs a Lagrange multiplier $\beta$ to tune this trade-off. However, in practice, not only is $\beta$ chosen empirically without theoretical guidance, there is also a lack of theoretical understanding between $\beta$, learnability, the intrinsic nature of the dataset and model capacity. In this paper, we show that if $\beta$ is improperly chosen, learning cannot happen -- the trivial representation $P(Z|X)=P(Z)$ becomes the global minimum of the IB objective. We show how this can be avoided, by identifying a sharp phase transition between the unlearnable and the learnable which arises as $\beta$ is varied. This phase transition defines the concept of IB-Learnability. We prove several sufficient conditions for IB-Learnability, which provides theoretical guidance for choosing a good $\beta$. We further show that IB-learnability is determined by the largest confident, typical, and imbalanced subset of the examples (the conspicuous subset), and discuss its relation with model capacity. We give practical algorithms to estimate the minimum $\beta$ for a given dataset. We also empirically demonstrate our theoretical conditions with analyses of synthetic datasets, MNIST, and CIFAR10.
Dueling Decoders: Regularizing Variational Autoencoder Latent Spaces
May 17, 2019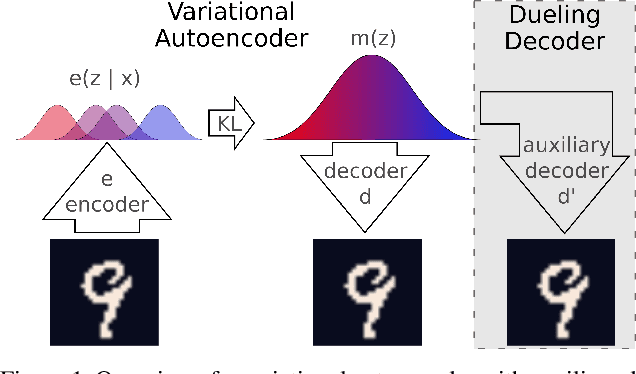
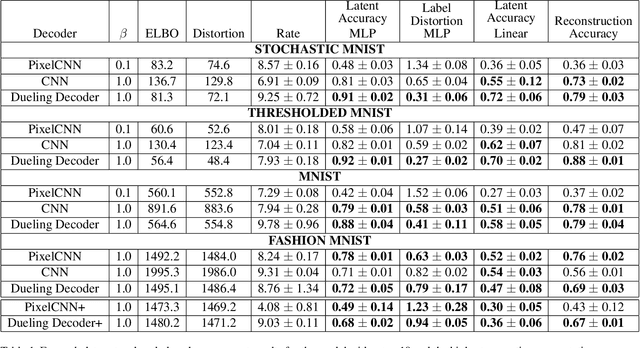

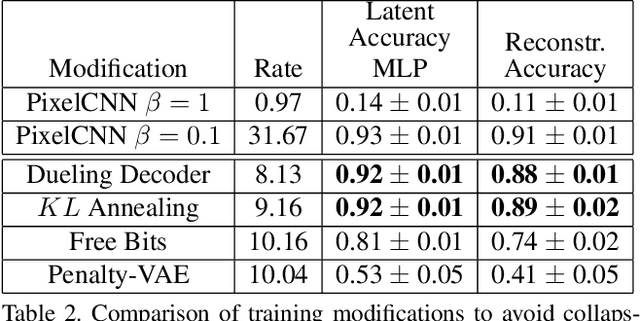
Variational autoencoders learn unsupervised data representations, but these models frequently converge to minima that fail to preserve meaningful semantic information. For example, variational autoencoders with autoregressive decoders often collapse into autodecoders, where they learn to ignore the encoder input. In this work, we demonstrate that adding an auxiliary decoder to regularize the latent space can prevent this collapse, but successful auxiliary decoding tasks are domain dependent. Auxiliary decoders can increase the amount of semantic information encoded in the latent space and visible in the reconstructions. The semantic information in the variational autoencoder's representation is only weakly correlated with its rate, distortion, or evidence lower bound. Compared to other popular strategies that modify the training objective, our regularization of the latent space generally increased the semantic information content.
Learning Latent Dynamics for Planning from Pixels
Dec 03, 2018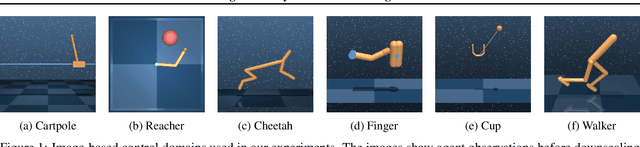
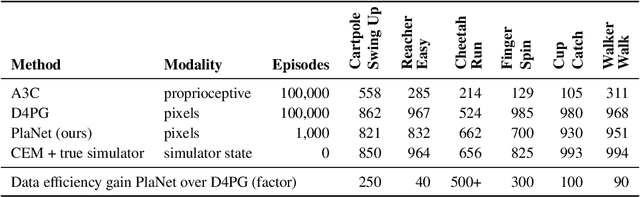
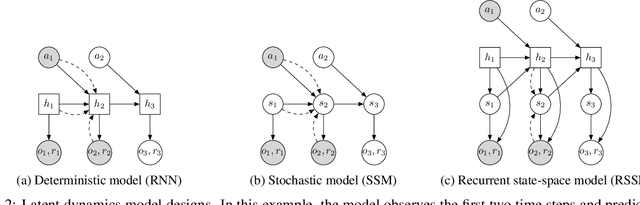
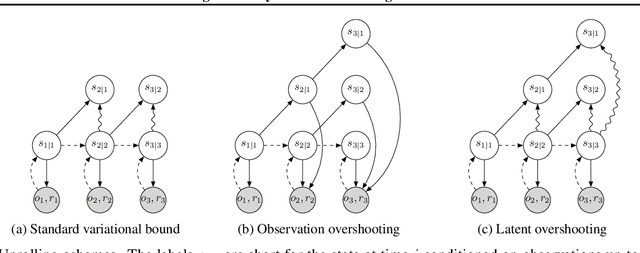
Planning has been very successful for control tasks with known environment dynamics. To leverage planning in unknown environments, the agent needs to learn the dynamics from interactions with the world. However, learning dynamics models that are accurate enough for planning has been a long-standing challenge, especially in image-based domains. We propose the Deep Planning Network (PlaNet), a purely model-based agent that learns the environment dynamics from pixels and chooses actions through online planning in latent space. To achieve high performance, the dynamics model must accurately predict the rewards ahead for multiple time steps. We approach this problem using a latent dynamics model with both deterministic and stochastic transition function and a generalized variational inference objective that we name latent overshooting. Using only pixel observations, our agent solves continuous control tasks with contact dynamics, partial observability, and sparse rewards. PlaNet uses significantly fewer episodes and reaches final performance close to and sometimes higher than top model-free algorithms.