 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDueling Decoders: Regularizing Variational Autoencoder Latent Spaces
Paper and Code
May 17, 2019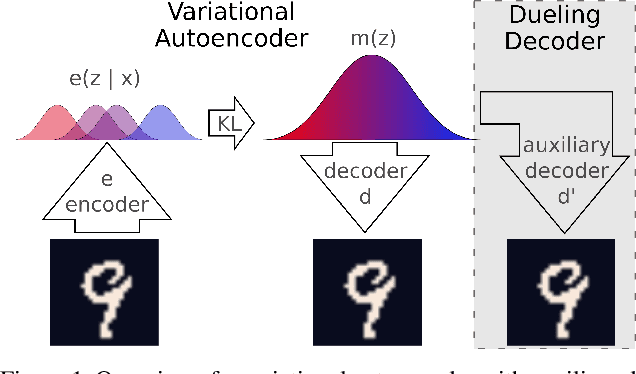
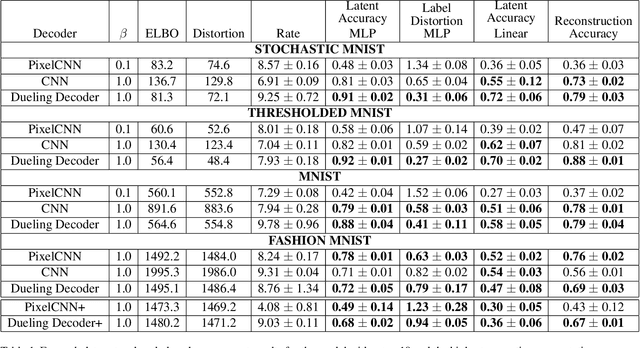

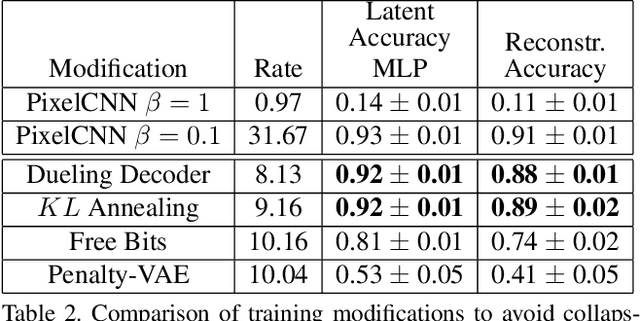
Variational autoencoders learn unsupervised data representations, but these models frequently converge to minima that fail to preserve meaningful semantic information. For example, variational autoencoders with autoregressive decoders often collapse into autodecoders, where they learn to ignore the encoder input. In this work, we demonstrate that adding an auxiliary decoder to regularize the latent space can prevent this collapse, but successful auxiliary decoding tasks are domain dependent. Auxiliary decoders can increase the amount of semantic information encoded in the latent space and visible in the reconstructions. The semantic information in the variational autoencoder's representation is only weakly correlated with its rate, distortion, or evidence lower bound. Compared to other popular strategies that modify the training objective, our regularization of the latent space generally increased the semantic information content.