 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-Augmented Masked Diffusion Models for Constrained Generation
Feb 02, 2026Discrete diffusion models generate sequences by iteratively denoising samples corrupted by categorical noise, offering an appealing alternative to autoregressive decoding for structured and symbolic generation. However, standard training targets a likelihood-based objective that primarily matches the data distribution and provides no native mechanism for enforcing hard constraints or optimizing non-differentiable properties at inference time. This work addresses this limitation and introduces Search-Augmented Masked Diffusion (SearchDiff), a training-free neurosymbolic inference framework that integrates informed search directly into the reverse denoising process. At each denoising step, the model predictions define a proposal set that is optimized under a user-specified property satisfaction, yielding a modified reverse transition that steers sampling toward probable and feasible solutions. Experiments in biological design and symbolic reasoning illustrate that SearchDiff substantially improves constraint satisfaction and property adherence, while consistently outperforming discrete diffusion and autoregressive baselines.
Selective Sinkhorn Routing for Improved Sparse Mixture of Experts
Nov 12, 2025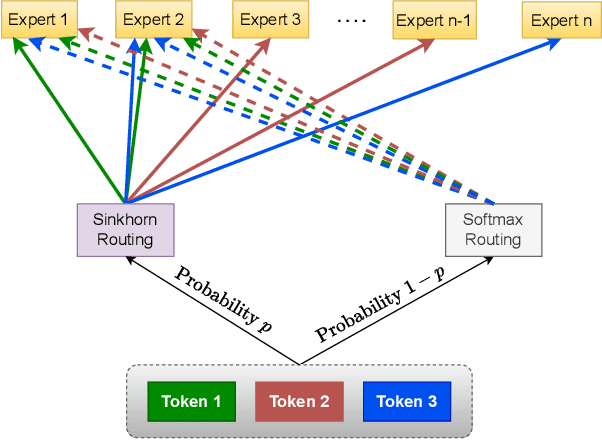
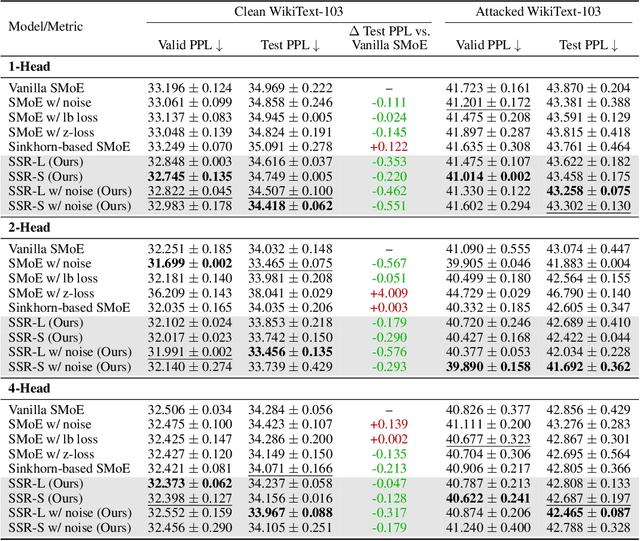
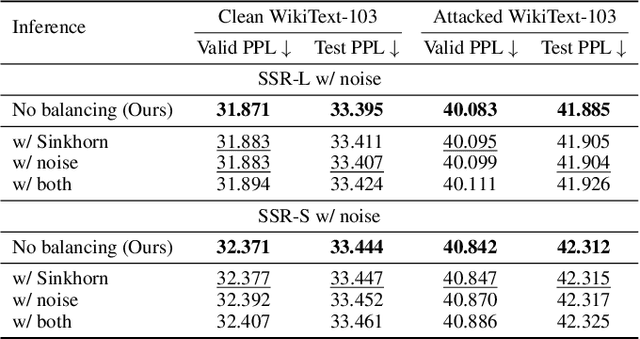
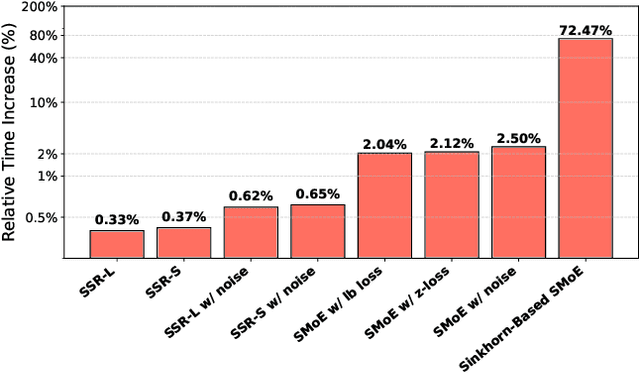
Sparse Mixture-of-Experts (SMoE) has gained prominence as a scalable and computationally efficient architecture, enabling significant growth in model capacity without incurring additional inference costs. However, existing SMoE models often rely on auxiliary losses (e.g., z-loss, load balancing) and additional trainable parameters (e.g., noisy gating) to encourage expert diversity, leading to objective misalignment and increased model complexity. Moreover, existing Sinkhorn-based methods suffer from significant training overhead due to their heavy reliance on the computationally expensive Sinkhorn algorithm. In this work, we formulate token-to-expert assignment as an optimal transport problem, incorporating constraints to ensure balanced expert utilization. We demonstrate that introducing a minimal degree of optimal transport-based routing enhances SMoE performance without requiring auxiliary balancing losses. Unlike previous methods, our approach derives gating scores directly from the transport map, enabling more effective token-to-expert balancing, supported by both theoretical analysis and empirical results. Building on these insights, we propose Selective Sinkhorn Routing (SSR), a routing mechanism that replaces auxiliary loss with lightweight Sinkhorn-based routing. SSR promotes balanced token assignments while preserving flexibility in expert selection. Across both language modeling and image classification tasks, SSR achieves faster training, higher accuracy, and greater robustness to input corruption.