 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletely Unsupervised Phoneme Recognition By A Generative Adversarial Network Harmonized With Iteratively Refined Hidden Markov Models
Apr 08, 2019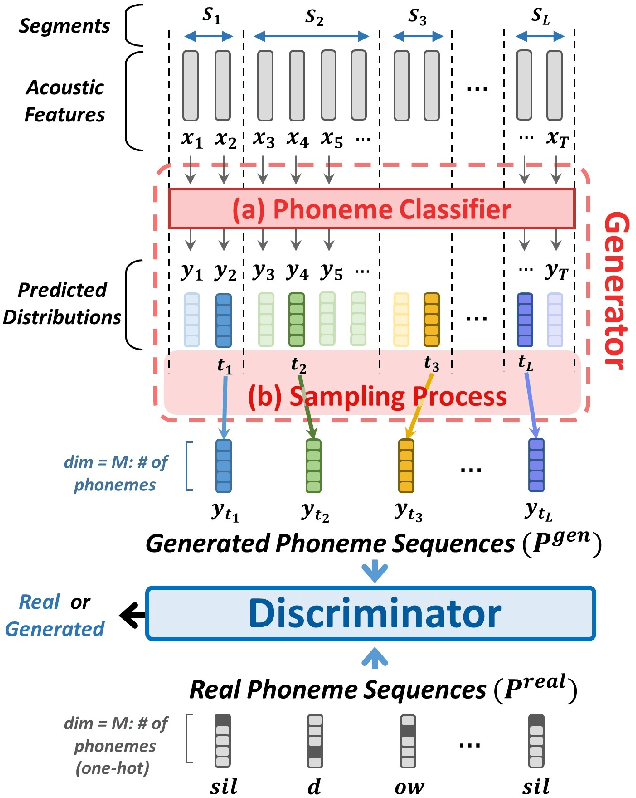
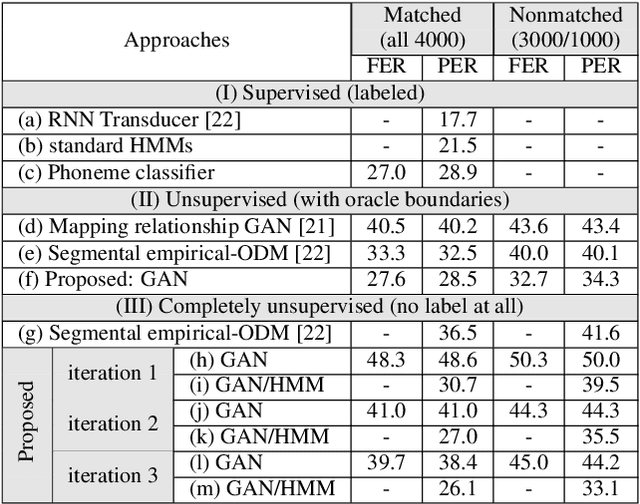
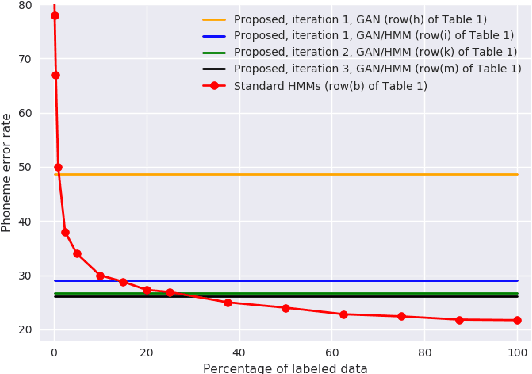
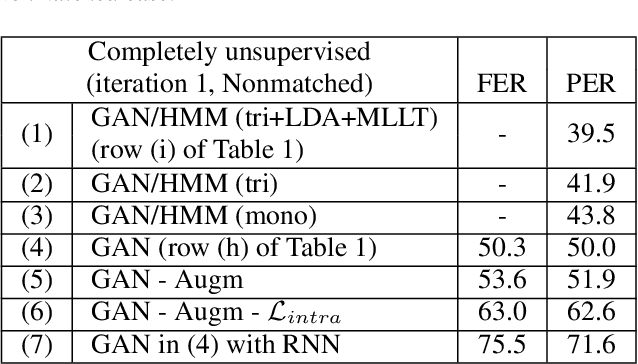
Producing a large annotated speech corpus for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced, but collecting a relatively big unlabeled data set for such languages is more achievable. This is why some initial effort have been reported on completely unsupervised speech recognition learned from unlabeled data only, although with relatively high error rates. In this paper, we develop a Generative Adversarial Network (GAN) to achieve this purpose, in which a Generator and a Discriminator learn from each other iteratively to improve the performance. We further use a set of Hidden Markov Models (HMMs) iteratively refined from the machine generated labels to work in harmony with the GAN. The initial experiments on TIMIT data set achieve an phone error rate of 33.1%, which is 8.5% lower than the previous state-of-the-art.
Code-switching Sentence Generation by Generative Adversarial Networks and its Application to Data Augmentation
Nov 19, 2018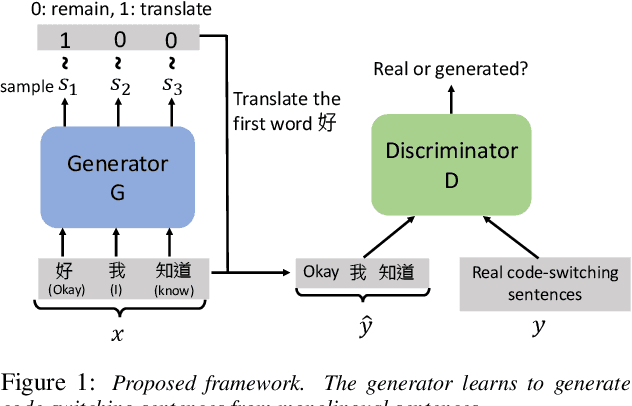
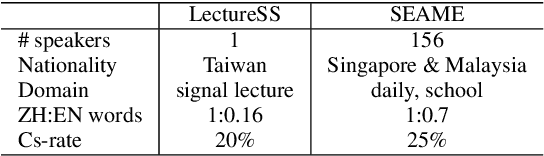
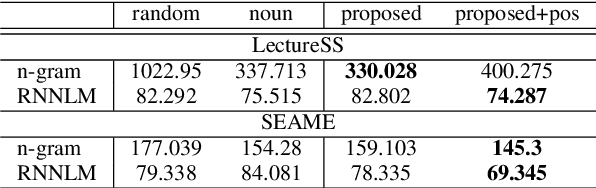

Code-switching is about dealing with alternative languages in speech or text. It is partially speaker-depend and domain-related, so completely explaining the phenomenon by linguistic rules is challenging. Compared to monolingual tasks, insufficient data is an issue for code-switching. To mitigate the issue without expensive human annotation, we proposed an unsupervised method for code-switching data augmentation. By utilizing a generative adversarial network, we can generate intra-sentential code-switching sentences from monolingual sentences. We applied proposed method on two corpora, and the result shows that the generated code-switching sentences improve the performance of code-switching language models.
Adversarial Learning of Label Dependency: A Novel Framework for Multi-class Classification
Nov 12, 2018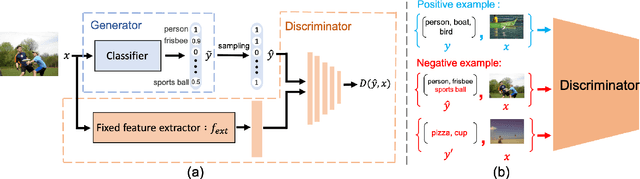
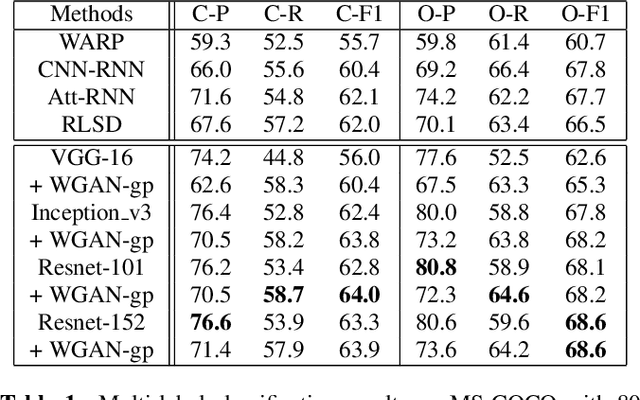
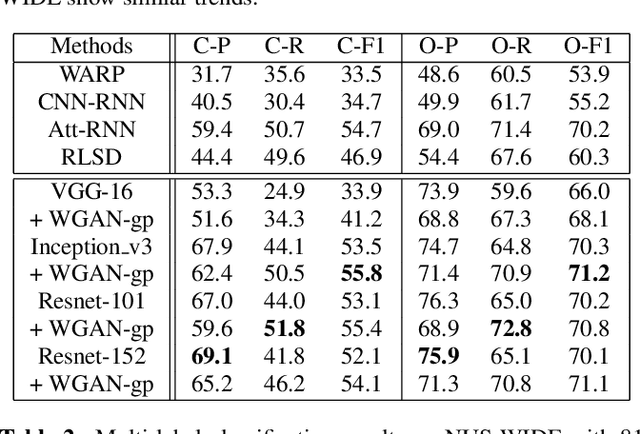

Recent work has shown that exploiting relations between labels improves the performance of multi-label classification. We propose a novel framework based on generative adversarial networks (GANs) to model label dependency. The discriminator learns to model label dependency by discriminating real and generated label sets. To fool the discriminator, the classifier, or generator, learns to generate label sets with dependencies close to real data. Extensive experiments and comparisons on two large-scale image classification benchmark datasets (MS-COCO and NUS-WIDE) show that the discriminator improves generalization ability for different kinds of models
Generative Adversarial Networks for Unpaired Voice Transformation on Impaired Speech
Oct 30, 2018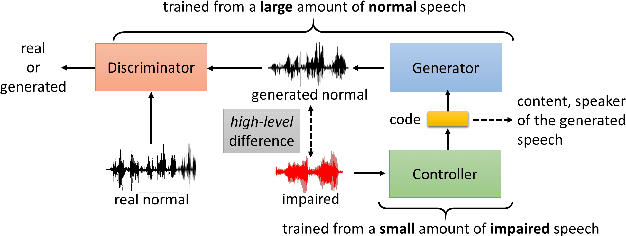
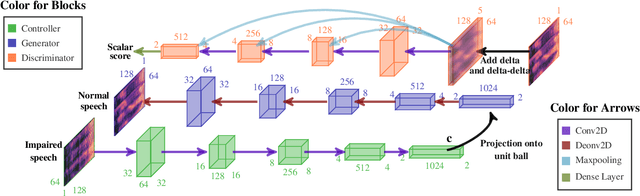

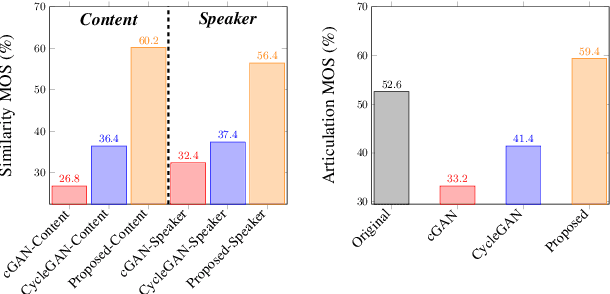
This paper focuses on using voice conversion (VC) to improve the speech intelligibility of surgical patients who have had parts of their articulators removed. Due to the difficulty of data collection, VC without parallel data is highly desired. Although techniques for unparallel VC, for example, CycleGAN, have been developed, they usually focus on transforming the speaker identity, and directly transforming the speech of one speaker to that of another speaker and as such do not address the task here. In this paper, we propose a new approach for unparallel VC. The proposed approach transforms impaired speech to normal speech while preserving the linguistic content and speaker characteristics. To our knowledge, this is the first end-to-end GAN-based unsupervised VC model applied to impaired speech. The experimental results show that the proposed approach outperforms CycleGAN.
Improving Conditional Sequence Generative Adversarial Networks by Stepwise Evaluation
Aug 16, 2018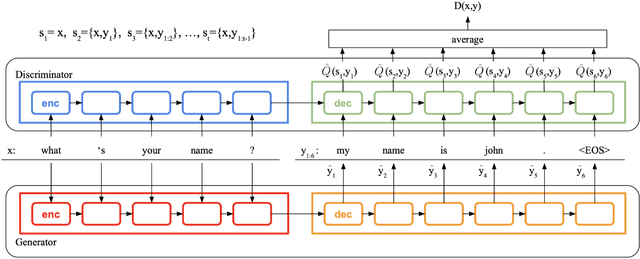
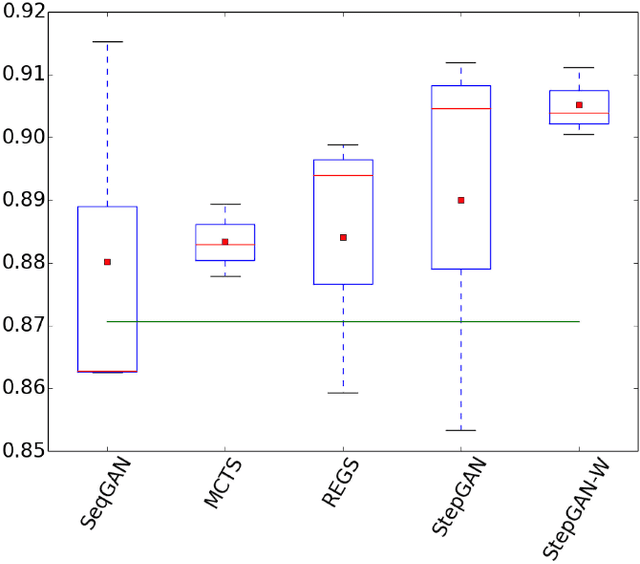
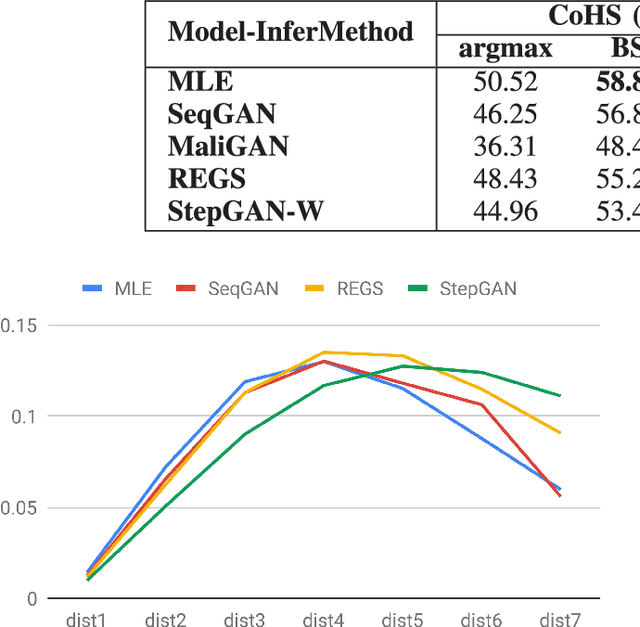
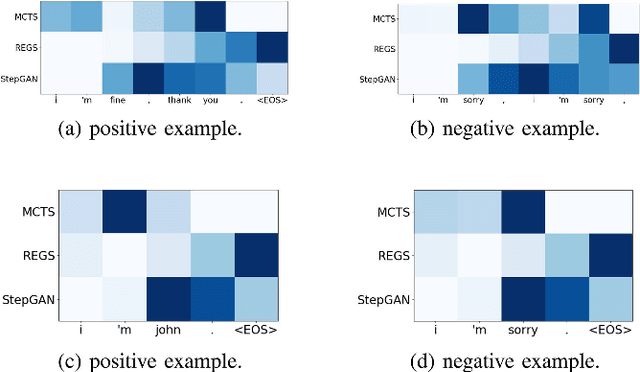
Sequence generative adversarial networks (SeqGAN) have been used to improve conditional sequence generation tasks, for example, chit-chat dialogue generation. To stabilize the training of SeqGAN, Monte Carlo tree search (MCTS) or reward at every generation step (REGS) is used to evaluate the goodness of a generated subsequence. MCTS is computationally intensive, but the performance of REGS is worse than MCTS. In this paper, we propose stepwise GAN (StepGAN), in which the discriminator is modified to automatically assign scores quantifying the goodness of each subsequence at every generation step. StepGAN has significantly less computational costs than MCTS. We demonstrate that StepGAN outperforms previous GAN-based methods on both synthetic experiment and chit-chat dialogue generation.
Towards Audio to Scene Image Synthesis using Generative Adversarial Network
Aug 13, 2018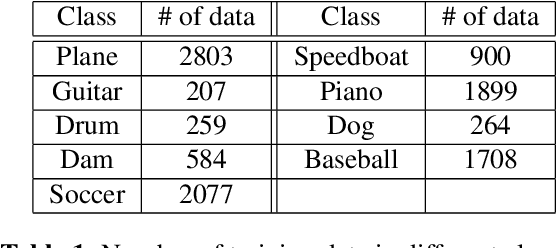
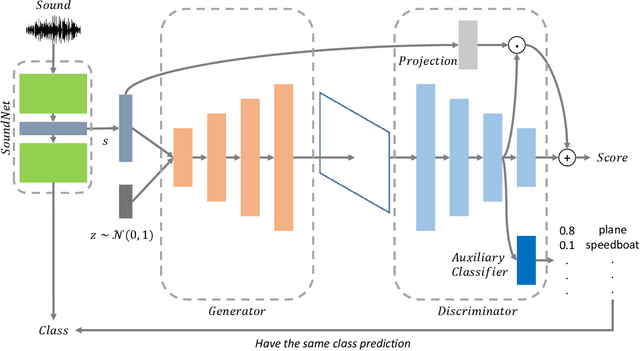
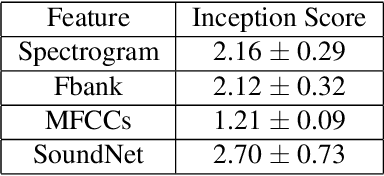

Humans can imagine a scene from a sound. We want machines to do so by using conditional generative adversarial networks (GANs). By applying the techniques including spectral norm, projection discriminator and auxiliary classifier, compared with naive conditional GAN, the model can generate images with better quality in terms of both subjective and objective evaluations. Almost three-fourth of people agree that our model have the ability to generate images related to sounds. By inputting different volumes of the same sound, our model output different scales of changes based on the volumes, showing that our model truly knows the relationship between sounds and images to some extent.
ODSQA: Open-domain Spoken Question Answering Dataset
Aug 07, 2018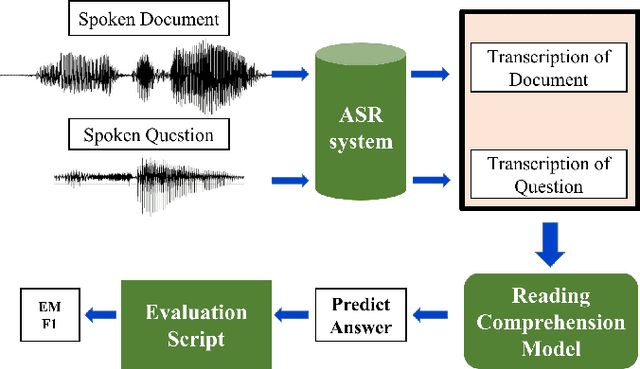


Reading comprehension by machine has been widely studied, but machine comprehension of spoken content is still a less investigated problem. In this paper, we release Open-Domain Spoken Question Answering Dataset (ODSQA) with more than three thousand questions. To the best of our knowledge, this is the largest real SQA dataset. On this dataset, we found that ASR errors have catastrophic impact on SQA. To mitigate the effect of ASR errors, subword units are involved, which brings consistent improvements over all the models. We further found that data augmentation on text-based QA training examples can improve SQA.
Supervised and Unsupervised Transfer Learning for Question Answering
Apr 21, 2018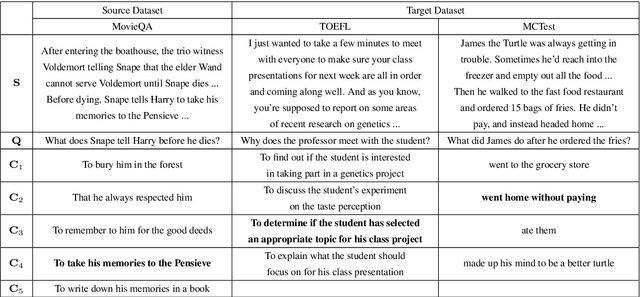
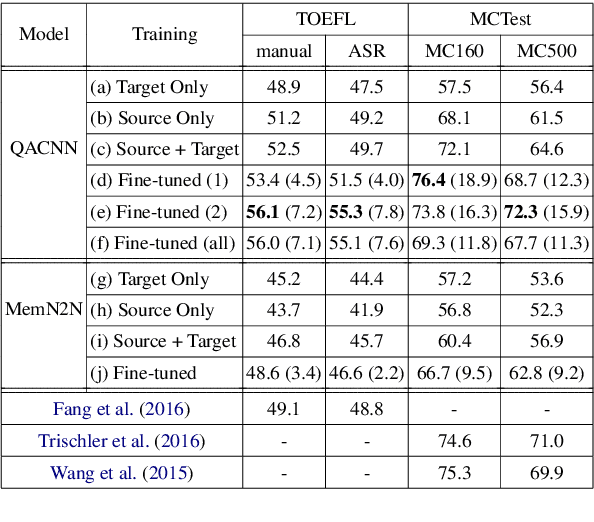
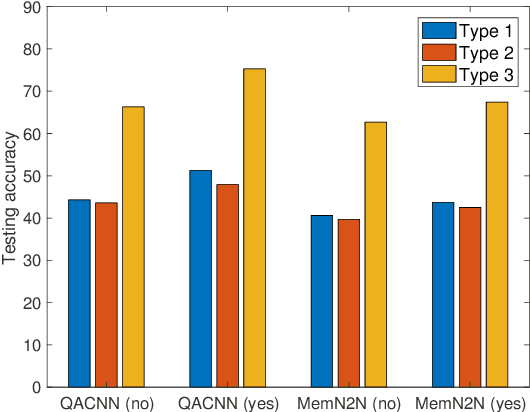
Although transfer learning has been shown to be successful for tasks like object and speech recognition, its applicability to question answering (QA) has yet to be well-studied. In this paper, we conduct extensive experiments to investigate the transferability of knowledge learned from a source QA dataset to a target dataset using two QA models. The performance of both models on a TOEFL listening comprehension test (Tseng et al., 2016) and MCTest (Richardson et al., 2013) is significantly improved via a simple transfer learning technique from MovieQA (Tapaswi et al., 2016). In particular, one of the models achieves the state-of-the-art on all target datasets; for the TOEFL listening comprehension test, it outperforms the previous best model by 7%. Finally, we show that transfer learning is helpful even in unsupervised scenarios when correct answers for target QA dataset examples are not available.
Scalable Sentiment for Sequence-to-sequence Chatbot Response with Performance Analysis
Apr 07, 2018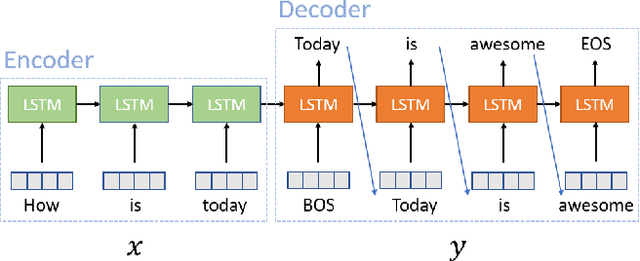
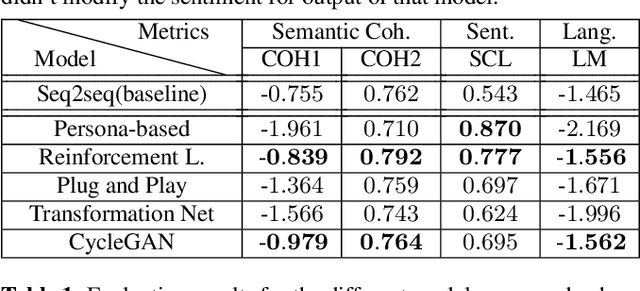
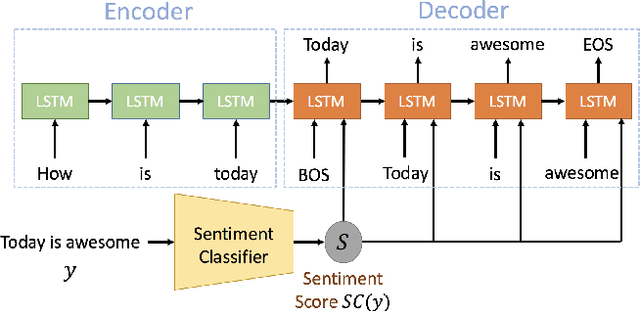
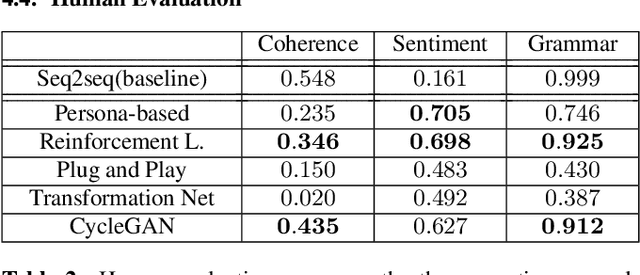
Conventional seq2seq chatbot models only try to find the sentences with the highest probabilities conditioned on the input sequences, without considering the sentiment of the output sentences. Some research works trying to modify the sentiment of the output sequences were reported. In this paper, we propose five models to scale or adjust the sentiment of the chatbot response: persona-based model, reinforcement learning, plug and play model, sentiment transformation network and cycleGAN, all based on the conventional seq2seq model. We also develop two evaluation metrics to estimate if the responses are reasonable given the input. These metrics together with other two popularly used metrics were used to analyze the performance of the five proposed models on different aspects, and reinforcement learning and cycleGAN were shown to be very attractive. The evaluation metrics were also found to be well correlated with human evaluation.
Joint Learning of Interactive Spoken Content Retrieval and Trainable User Simulator
Apr 01, 2018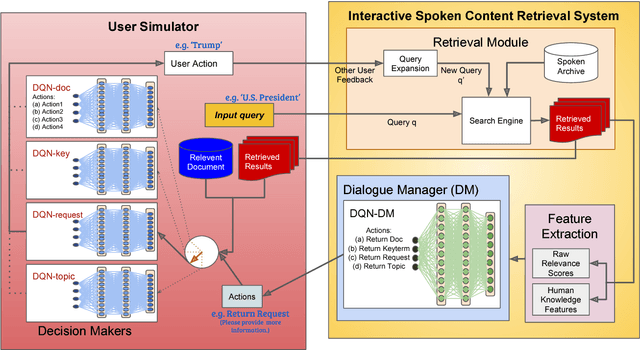
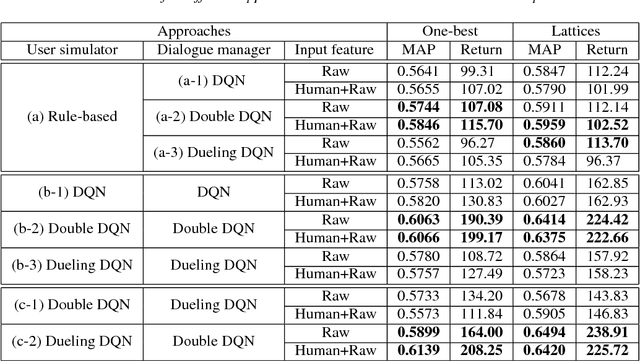
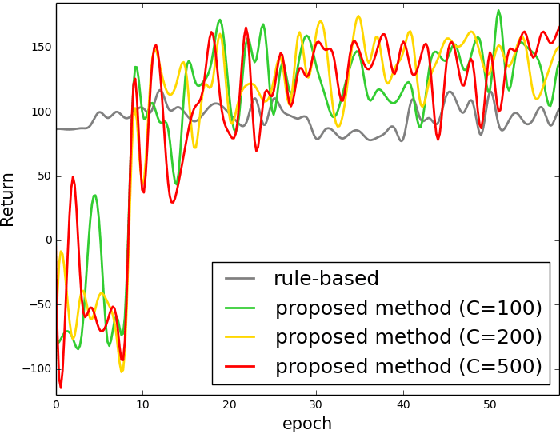

User-machine interaction is crucial for information retrieval, especially for spoken content retrieval, because spoken content is difficult to browse, and speech recognition has a high degree of uncertainty. In interactive retrieval, the machine takes different actions to interact with the user to obtain better retrieval results; here it is critical to select the most efficient action. In previous work, deep Q-learning techniques were proposed to train an interactive retrieval system but rely on a hand-crafted user simulator; building a reliable user simulator is difficult. In this paper, we further improve the interactive spoken content retrieval framework by proposing a learnable user simulator which is jointly trained with interactive retrieval system, making the hand-crafted user simulator unnecessary. The experimental results show that the learned simulated users not only achieve larger rewards than the hand-crafted ones but act more like real users.