 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Cognitive Domains for LLMs: Insights from Taiwanese Hakka Culture
Sep 03, 2024This study introduces a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) in understanding and processing cultural knowledge, with a specific focus on Hakka culture as a case study. Leveraging Bloom's Taxonomy, the study develops a multi-dimensional framework that systematically assesses LLMs across six cognitive domains: Remembering, Understanding, Applying, Analyzing, Evaluating, and Creating. This benchmark extends beyond traditional single-dimensional evaluations by providing a deeper analysis of LLMs' abilities to handle culturally specific content, ranging from basic recall of facts to higher-order cognitive tasks such as creative synthesis. Additionally, the study integrates Retrieval-Augmented Generation (RAG) technology to address the challenges of minority cultural knowledge representation in LLMs, demonstrating how RAG enhances the models' performance by dynamically incorporating relevant external information. The results highlight the effectiveness of RAG in improving accuracy across all cognitive domains, particularly in tasks requiring precise retrieval and application of cultural knowledge. However, the findings also reveal the limitations of RAG in creative tasks, underscoring the need for further optimization. This benchmark provides a robust tool for evaluating and comparing LLMs in culturally diverse contexts, offering valuable insights for future research and development in AI-driven cultural knowledge preservation and dissemination.
Effective Noise-aware Data Simulation for Domain-adaptive Speech Enhancement Leveraging Dynamic Stochastic Perturbation
Sep 03, 2024Cross-domain speech enhancement (SE) is often faced with severe challenges due to the scarcity of noise and background information in an unseen target domain, leading to a mismatch between training and test conditions. This study puts forward a novel data simulation method to address this issue, leveraging noise-extractive techniques and generative adversarial networks (GANs) with only limited target noisy speech data. Notably, our method employs a noise encoder to extract noise embeddings from target-domain data. These embeddings aptly guide the generator to synthesize utterances acoustically fitted to the target domain while authentically preserving the phonetic content of the input clean speech. Furthermore, we introduce the notion of dynamic stochastic perturbation, which can inject controlled perturbations into the noise embeddings during inference, thereby enabling the model to generalize well to unseen noise conditions. Experiments on the VoiceBank-DEMAND benchmark dataset demonstrate that our domain-adaptive SE method outperforms an existing strong baseline based on data simulation.
VoxHakka: A Dialectally Diverse Multi-speaker Text-to-Speech System for Taiwanese Hakka
Sep 03, 2024



This paper introduces VoxHakka, a text-to-speech (TTS) system designed for Taiwanese Hakka, a critically under-resourced language spoken in Taiwan. Leveraging the YourTTS framework, VoxHakka achieves high naturalness and accuracy and low real-time factor in speech synthesis while supporting six distinct Hakka dialects. This is achieved by training the model with dialect-specific data, allowing for the generation of speaker-aware Hakka speech. To address the scarcity of publicly available Hakka speech corpora, we employed a cost-effective approach utilizing a web scraping pipeline coupled with automatic speech recognition (ASR)-based data cleaning techniques. This process ensured the acquisition of a high-quality, multi-speaker, multi-dialect dataset suitable for TTS training. Subjective listening tests conducted using comparative mean opinion scores (CMOS) demonstrate that VoxHakka significantly outperforms existing publicly available Hakka TTS systems in terms of pronunciation accuracy, tone correctness, and overall naturalness. This work represents a significant advancement in Hakka language technology and provides a valuable resource for language preservation and revitalization efforts.
The North System for Formosa Speech Recognition Challenge 2023
Oct 06, 2023This report provides a concise overview of the proposed North system, which aims to achieve automatic word/syllable recognition for Taiwanese Hakka (Sixian). The report outlines three key components of the system: the acquisition, composition, and utilization of the training data; the architecture of the model; and the hardware specifications and operational statistics. The demonstration of the system has been made public at https://asrvm.iis.sinica.edu.tw/hakka_sixian.
A Teacher-student Framework for Unsupervised Speech Enhancement Using Noise Remixing Training and Two-stage Inference
Oct 27, 2022



The lack of clean speech is a practical challenge to the development of speech enhancement systems, which means that the training of neural network models must be done in an unsupervised manner, and there is an inevitable mismatch between their training criterion and evaluation metric. In response to this unfavorable situation, we propose a teacher-student training strategy that does not require any subjective/objective speech quality metrics as learning reference by improving the previously proposed noisy-target training (NyTT). Because homogeneity between in-domain noise and extraneous noise is the key to the effectiveness of NyTT, we train various student models by remixing the teacher model's estimated speech and noise for clean-target training or raw noisy speech and the teacher model's estimated noise for noisy-target training. We use the NyTT model as the initial teacher model. Experimental results show that our proposed method outperforms several baselines, especially with two-stage inference, where clean speech is derived successively through the bootstrap model and the final student model.
CasNet: Investigating Channel Robustness for Speech Separation
Oct 27, 2022Recording channel mismatch between training and testing conditions has been shown to be a serious problem for speech separation. This situation greatly reduces the separation performance, and cannot meet the requirement of daily use. In this study, inheriting the use of our previously constructed TAT-2mix corpus, we address the channel mismatch problem by proposing a channel-aware audio separation network (CasNet), a deep learning framework for end-to-end time-domain speech separation. CasNet is implemented on top of TasNet. Channel embedding (characterizing channel information in a mixture of multiple utterances) generated by Channel Encoder is introduced into the separation module by the FiLM technique. Through two training strategies, we explore two roles that channel embedding may play: 1) a real-life noise disturbance, making the model more robust, or 2) a guide, instructing the separation model to retain the desired channel information. Experimental results on TAT-2mix show that CasNet trained with both training strategies outperforms the TasNet baseline, which does not use channel embeddings.
Filter-based Discriminative Autoencoders for Children Speech Recognition
Apr 01, 2022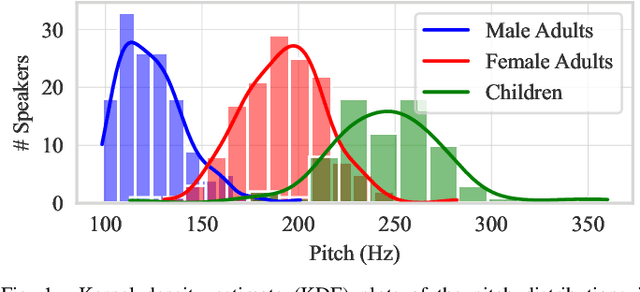
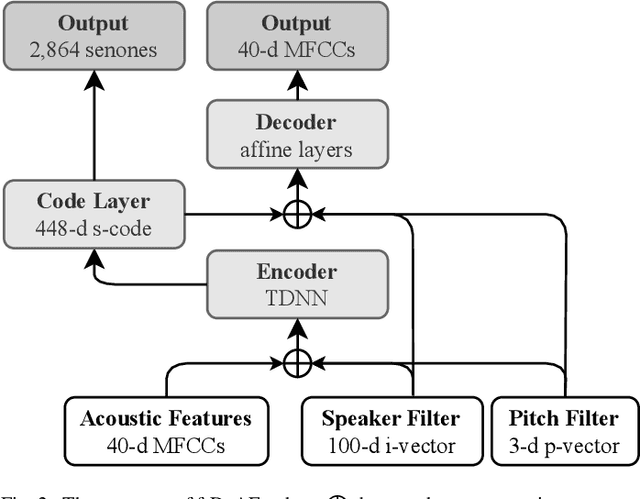
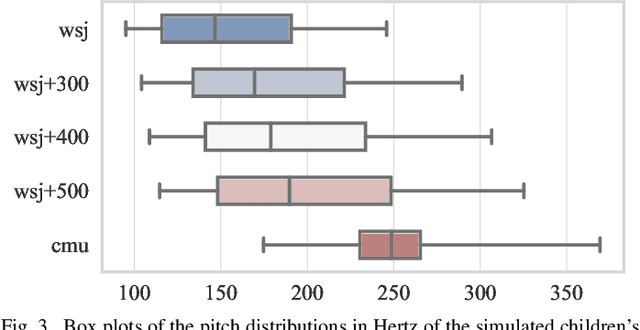
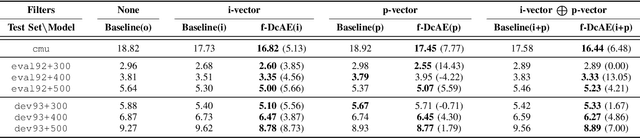
Children speech recognition is indispensable but challenging due to the diversity of children's speech. In this paper, we propose a filter-based discriminative autoencoder for acoustic modeling. To filter out the influence of various speaker types and pitches, auxiliary information of the speaker and pitch features is input into the encoder together with the acoustic features to generate phonetic embeddings. In the training phase, the decoder uses the auxiliary information and the phonetic embedding extracted by the encoder to reconstruct the input acoustic features. The autoencoder is trained by simultaneously minimizing the ASR loss and feature reconstruction error. The framework can make the phonetic embedding purer, resulting in more accurate senone (triphone-state) scores. Evaluated on the test set of the CMU Kids corpus, our system achieves a 7.8% relative WER reduction compared to the baseline system. In the domain adaptation experiment, our system also outperforms the baseline system on the British-accent PF-STAR task.
Generation of Speaker Representations Using Heterogeneous Training Batch Assembly
Mar 30, 2022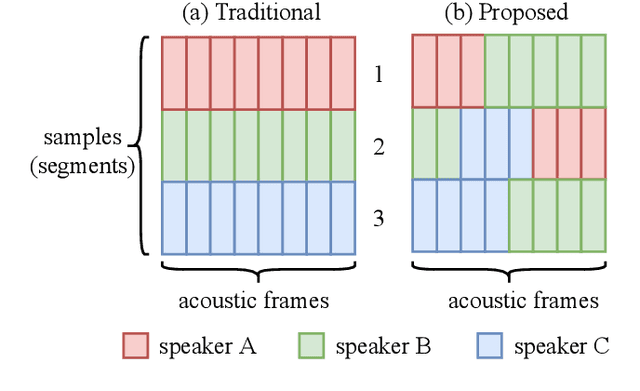
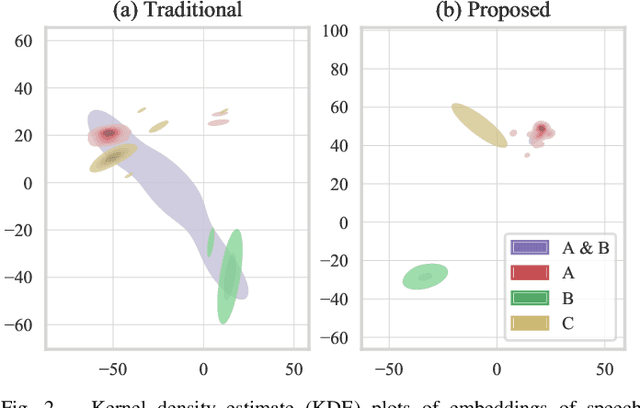
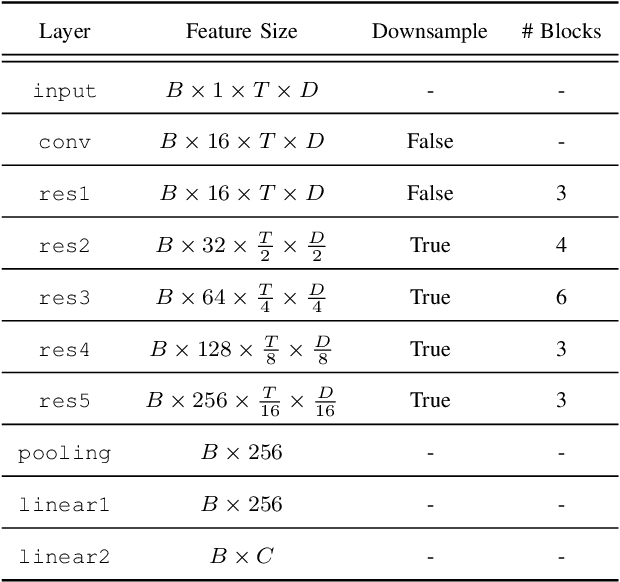
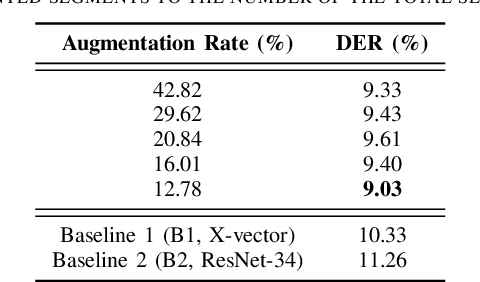
In traditional speaker diarization systems, a well-trained speaker model is a key component to extract representations from consecutive and partially overlapping segments in a long speech session. To be more consistent with the back-end segmentation and clustering, we propose a new CNN-based speaker modeling scheme, which takes into account the heterogeneity of the speakers in each training segment and batch. We randomly and synthetically augment the training data into a set of segments, each of which contains more than one speaker and some overlapping parts. A soft label is imposed on each segment based on its speaker occupation ratio, and the standard cross entropy loss is implemented in model training. In this way, the speaker model should have the ability to generate a geometrically meaningful embedding for each multi-speaker segment. Experimental results show that our system is superior to the baseline system using x-vectors in two speaker diarization tasks. In the CALLHOME task trained on the NIST SRE and Switchboard datasets, our system achieves a relative reduction of 12.93% in DER. In Track 2 of CHiME-6, our system provides 13.24%, 12.60%, and 5.65% relative reductions in DER, JER, and WER, respectively.
Disentangling the Impacts of Language and Channel Variability on Speech Separation Networks
Mar 30, 2022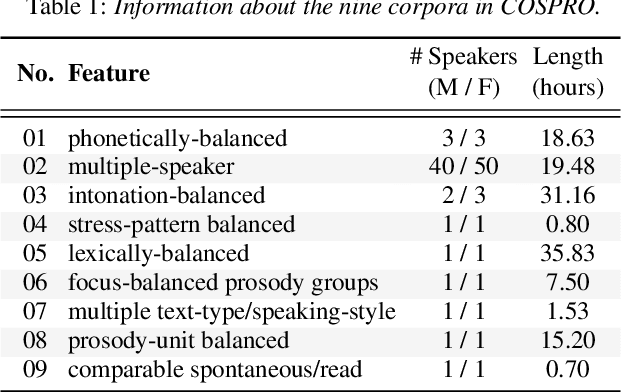
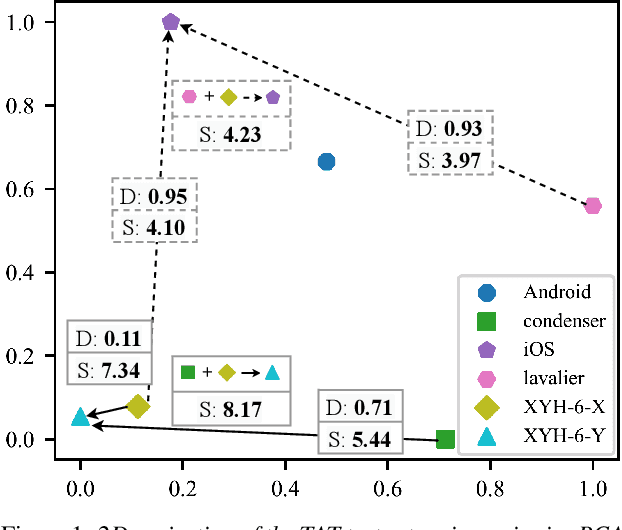
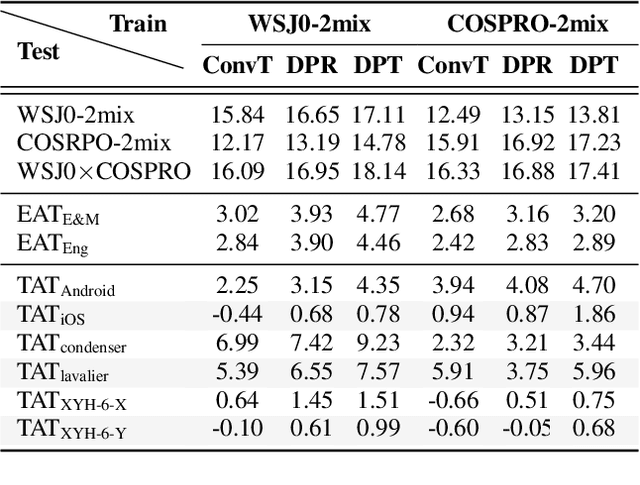
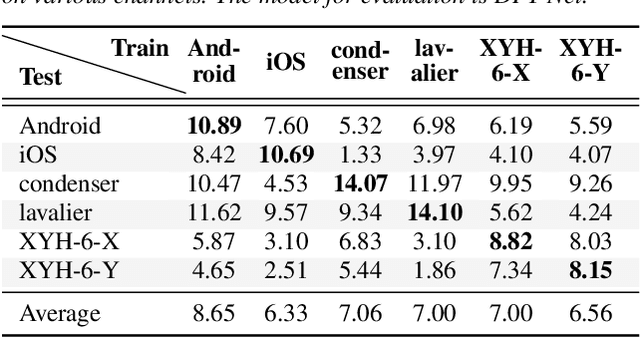
Because the performance of speech separation is excellent for speech in which two speakers completely overlap, research attention has been shifted to dealing with more realistic scenarios. However, domain mismatch between training/test situations due to factors, such as speaker, content, channel, and environment, remains a severe problem for speech separation. Speaker and environment mismatches have been studied in the existing literature. Nevertheless, there are few studies on speech content and channel mismatches. Moreover, the impacts of language and channel in these studies are mostly tangled. In this study, we create several datasets for various experiments. The results show that the impacts of different languages are small enough to be ignored compared to the impacts of different channels. In our experiments, training on data recorded by Android phones leads to the best generalizability. Moreover, we provide a new solution for channel mismatch by evaluating projection, where the channel similarity can be measured and used to effectively select additional training data to improve the performance of in-the-wild test data.
Multi-Target Filter and Detector for Speaker Diarization
Mar 30, 2022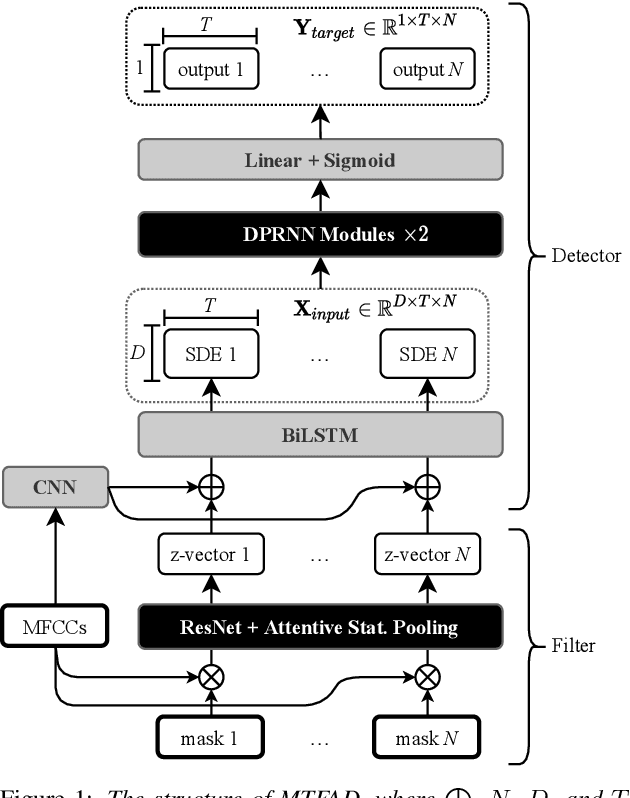
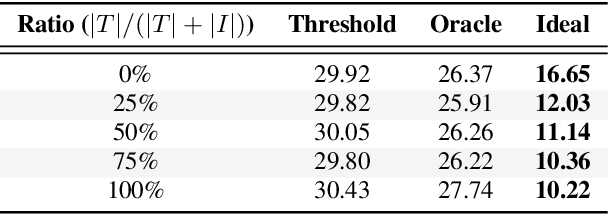
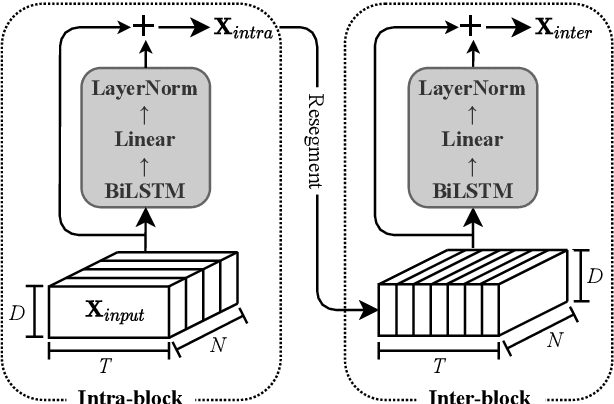
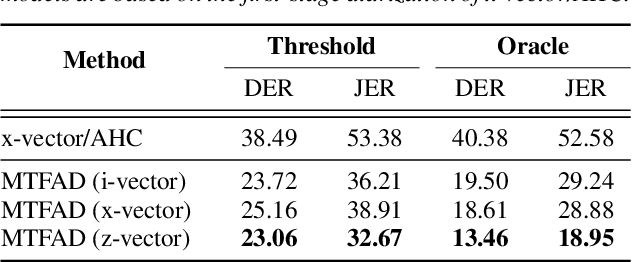
A good representation of a target speaker usually helps to extract important information about the speaker and detect the corresponding temporal regions in a multi-speaker conversation. In this paper, we propose a neural architecture that simultaneously extracts speaker embeddings consistent with the speaker diarization objective and detects the presence of each speaker frame by frame, regardless of the number of speakers in the conversation. To this end, a residual network (ResNet) and a dual-path recurrent neural network (DPRNN) are integrated into a unified structure. When tested on the 2-speaker CALLHOME corpus, our proposed model outperforms most methods published so far. Evaluated in a more challenging case of concurrent speakers ranging from two to seven, our system also achieves relative diarization error rate reductions of 26.35% and 6.4% over two typical baselines, namely the traditional x-vector clustering system and the attention-based system.