 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXR-VLM: Cross-Relationship Modeling with Multi-part Prompts and Visual Features for Fine-Grained Recognition
Mar 10, 2025



Vision-Language Models (VLMs) have demonstrated impressive performance on various visual tasks, yet they still require adaptation on downstream tasks to achieve optimal performance. Recently, various adaptation technologies have been proposed, but we observe they often underperform in fine-grained visual recognition, which requires models to capture subtle yet discriminative features to distinguish similar sub-categories. Current adaptation methods typically rely on an alignment-based prediction framework, \ie the visual feature is compared with each class prompt for similarity calculation as the final prediction, which lacks class interaction during the forward pass. Besides, learning single uni-modal feature further restricts the model's expressive capacity. Therefore, we propose a novel mechanism, XR-VLM, to discover subtle differences by modeling cross-relationships, which specifically excels in scenarios involving multiple features. Our method introduces a unified multi-part visual feature extraction module designed to seamlessly integrate with the diverse backbones inherent in VLMs. Additionally, we develop a multi-part prompt learning module to capture multi-perspective descriptions of sub-categories. To further enhance discriminative capability, we propose a cross relationship modeling pattern that combines visual feature with all class prompt features, enabling a deeper exploration of the relationships between these two modalities. Extensive experiments have been conducted on various fine-grained datasets, and the results demonstrate that our method achieves significant improvements compared to current state-of-the-art approaches. Code will be released.
Prompt-based Generative Approach towards Multi-Hierarchical Medical Dialogue State Tracking
Mar 18, 2022
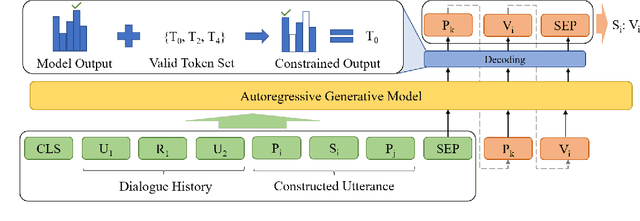


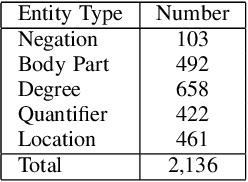
The medical dialogue system is a promising application that can provide great convenience for patients. The dialogue state tracking (DST) module in the medical dialogue system which interprets utterances into the machine-readable structure for downstream tasks is particularly challenging. Firstly, the states need to be able to represent compound entities such as symptoms with their body part or diseases with degrees of severity to provide enough information for decision support. Secondly, these named entities in the utterance might be discontinuous and scattered across sentences and speakers. These also make it difficult to annotate a large corpus which is essential for most methods. Therefore, we first define a multi-hierarchical state structure. We annotate and publish a medical dialogue dataset in Chinese. To the best of our knowledge, there are no publicly available ones before. Then we propose a Prompt-based Generative Approach which can generate slot values with multi-hierarchies incrementally using a top-down approach. A dialogue style prompt is also supplemented to utilize the large unlabeled dialogue corpus to alleviate the data scarcity problem. The experiments show that our approach outperforms other DST methods and is rather effective in the scenario with little data.
Enriching Medcial Terminology Knowledge Bases via Pre-trained Language Model and Graph Convolutional Network
Sep 02, 2019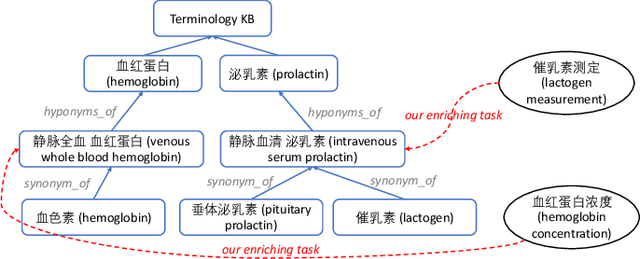
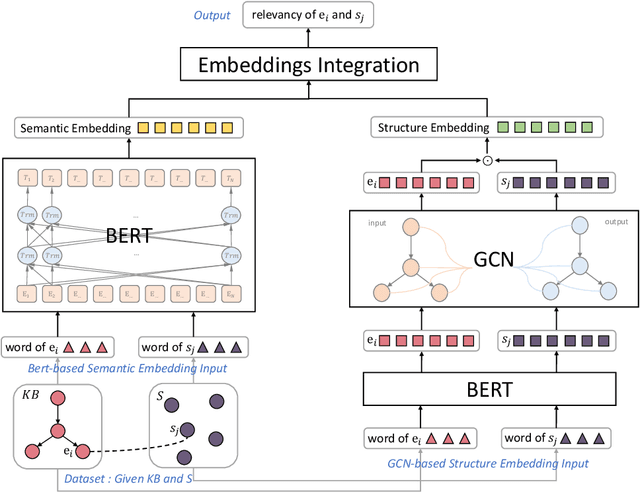
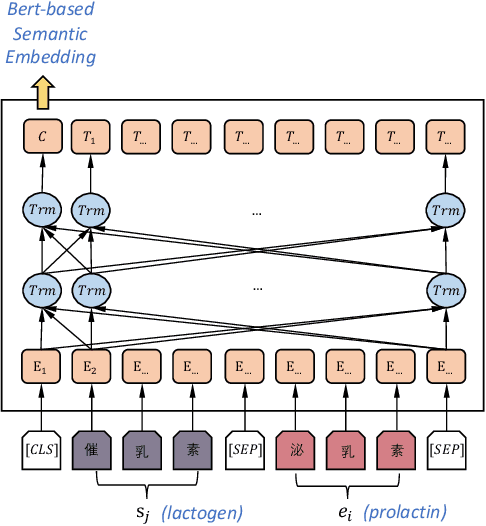
Enriching existing medical terminology knowledge bases (KBs) is an important and never-ending work for clinical research because new terminology alias may be continually added and standard terminologies may be newly renamed. In this paper, we propose a novel automatic terminology enriching approach to supplement a set of terminologies to KBs. Specifically, terminology and entity characters are first fed into pre-trained language model to obtain semantic embedding. The pre-trained model is used again to initialize the terminology and entity representations, then they are further embedded through graph convolutional network to gain structure embedding. Afterwards, both semantic and structure embeddings are combined to measure the relevancy between the terminology and the entity. Finally, the optimal alignment is achieved based on the order of relevancy between the terminology and all the entities in the KB. Experimental results on clinical indicator terminology KB, collected from 38 top-class hospitals of Shanghai Hospital Development Center, show that our proposed approach outperforms baseline methods and can effectively enrich the KB.
Fine-tuning BERT for Joint Entity and Relation Extraction in Chinese Medical Text
Aug 21, 2019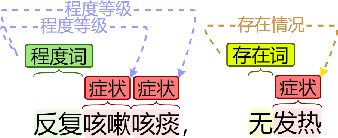
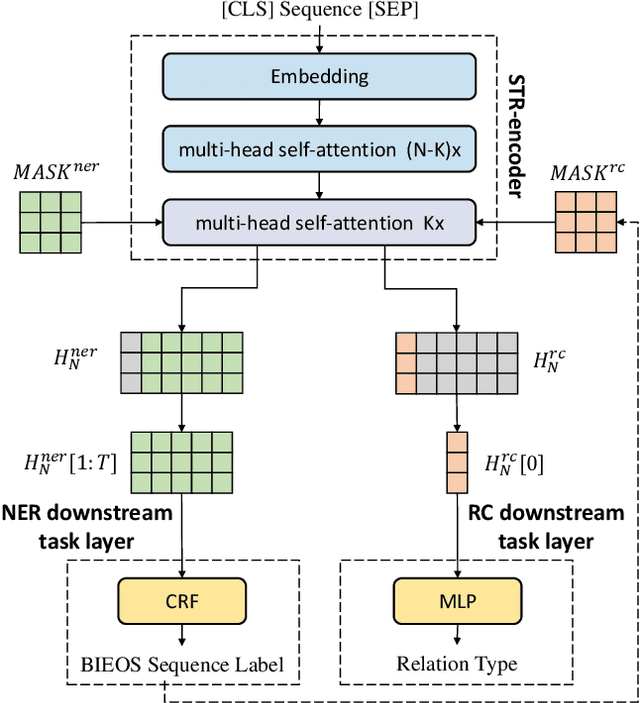
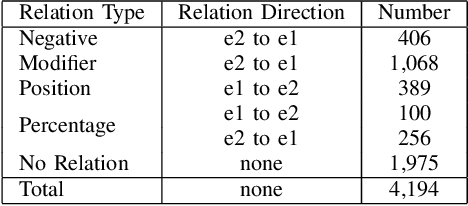
Entity and relation extraction is the necessary step in structuring medical text. However, the feature extraction ability of the bidirectional long short term memory network in the existing model does not achieve the best effect. At the same time, the language model has achieved excellent results in more and more natural language processing tasks. In this paper, we present a focused attention model for the joint entity and relation extraction task. Our model integrates well-known BERT language model into joint learning through dynamic range attention mechanism, thus improving the feature representation ability of shared parameter layer. Experimental results on coronary angiography texts collected from Shuguang Hospital show that the F1-score of named entity recognition and relation classification tasks reach 96.89% and 88.51%, which are better than state-of-the-art methods 1.65% and 1.22%, respectively.