 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMIT- Event-Based Masked Auto Encoding for Irregular Time Series
Sep 25, 2024Irregular time series, where data points are recorded at uneven intervals, are prevalent in healthcare settings, such as emergency wards where vital signs and laboratory results are captured at varying times. This variability, which reflects critical fluctuations in patient health, is essential for informed clinical decision-making. Existing self-supervised learning research on irregular time series often relies on generic pretext tasks like forecasting, which may not fully utilise the signal provided by irregular time series. There is a significant need for specialised pretext tasks designed for the characteristics of irregular time series to enhance model performance and robustness, especially in scenarios with limited data availability. This paper proposes a novel pretraining framework, EMIT, an event-based masking for irregular time series. EMIT focuses on masking-based reconstruction in the latent space, selecting masking points based on the rate of change in the data. This method preserves the natural variability and timing of measurements while enhancing the model's ability to process irregular intervals without losing essential information. Extensive experiments on the MIMIC-III and PhysioNet Challenge datasets demonstrate the superior performance of our event-based masking strategy. The code has been released at https://github.com/hrishi-ds/EMIT .
Estimating Gender Completeness in Wikipedia
Jan 17, 2024



Gender imbalance in Wikipedia content is a known challenge which the editor community is actively addressing. The aim of this paper is to provide the Wikipedia community with instruments to estimate the magnitude of the problem for different entity types (also known as classes) in Wikipedia. To this end, we apply class completeness estimation methods based on the gender attribute. Our results show not only which gender for different sub-classes of Person is more prevalent in Wikipedia, but also an idea of how complete the coverage is for difference genders and sub-classes of Person.
Tale of tails using rule augmented sequence labeling for event extraction
Aug 22, 2019
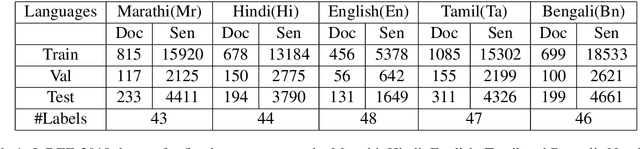
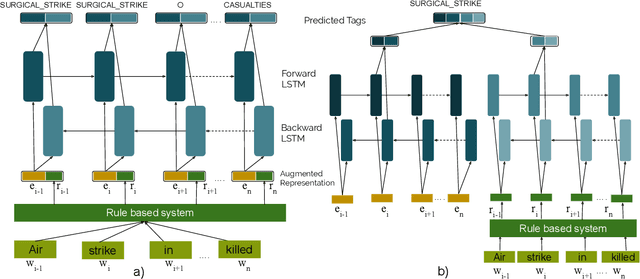
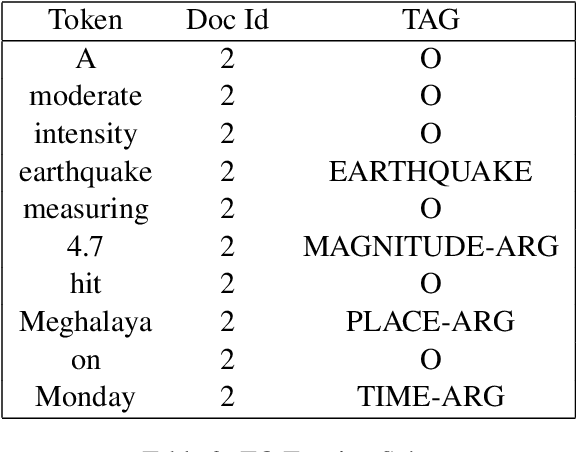
The problem of event extraction is a relatively difficult task for low resource languages due to the non-availability of sufficient annotated data. Moreover, the task becomes complex for tail (rarely occurring) labels wherein extremely less data is available. In this paper, we present a new dataset (InDEE-2019) in the disaster domain for multiple Indic languages, collected from news websites. Using this dataset, we evaluate several rule-based mechanisms to augment deep learning based models. We formulate our problem of event extraction as a sequence labeling task and perform extensive experiments to study and understand the effectiveness of different approaches. We further show that tail labels can be easily incorporated by creating new rules without the requirement of large annotated data.