 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure Modes of Domain Generalization Algorithms
Nov 26, 2021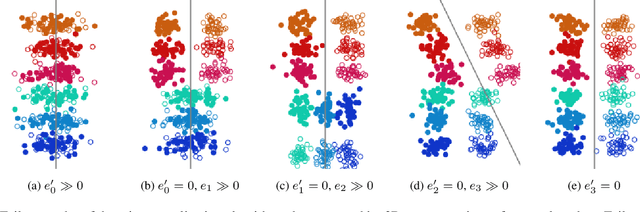

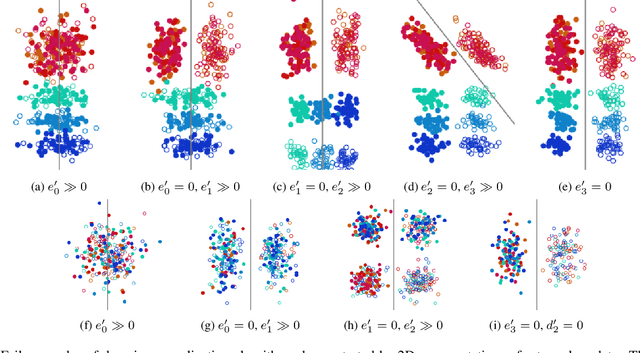
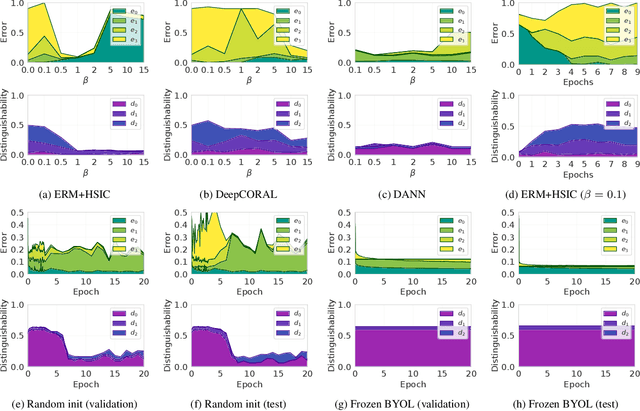
Domain generalization algorithms use training data from multiple domains to learn models that generalize well to unseen domains. While recently proposed benchmarks demonstrate that most of the existing algorithms do not outperform simple baselines, the established evaluation methods fail to expose the impact of various factors that contribute to the poor performance. In this paper we propose an evaluation framework for domain generalization algorithms that allows decomposition of the error into components capturing distinct aspects of generalization. Inspired by the prevalence of algorithms based on the idea of domain-invariant representation learning, we extend the evaluation framework to capture various types of failures in achieving invariance. We show that the largest contributor to the generalization error varies across methods, datasets, regularization strengths and even training lengths. We observe two problems associated with the strategy of learning domain-invariant representations. On Colored MNIST, most domain generalization algorithms fail because they reach domain-invariance only on the training domains. On Camelyon-17, domain-invariance degrades the quality of representations on unseen domains. We hypothesize that focusing instead on tuning the classifier on top of a rich representation can be a promising direction.
Information-theoretic generalization bounds for black-box learning algorithms
Oct 05, 2021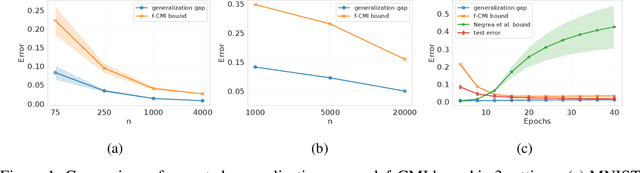

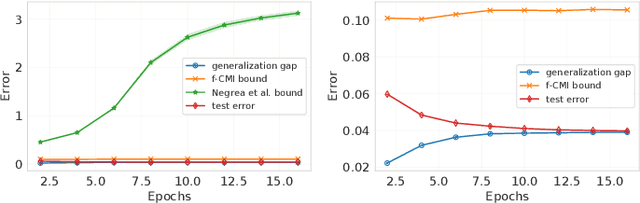

We derive information-theoretic generalization bounds for supervised learning algorithms based on the information contained in predictions rather than in the output of the training algorithm. These bounds improve over the existing information-theoretic bounds, are applicable to a wider range of algorithms, and solve two key challenges: (a) they give meaningful results for deterministic algorithms and (b) they are significantly easier to estimate. We show experimentally that the proposed bounds closely follow the generalization gap in practical scenarios for deep learning.
Estimating informativeness of samples with Smooth Unique Information
Jan 17, 2021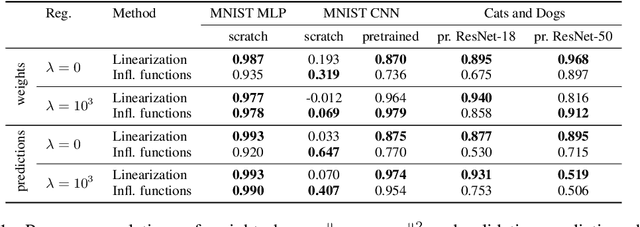

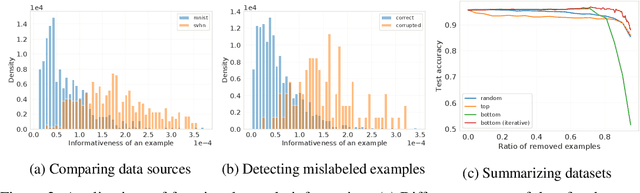
We define a notion of information that an individual sample provides to the training of a neural network, and we specialize it to measure both how much a sample informs the final weights and how much it informs the function computed by the weights. Though related, we show that these quantities have a qualitatively different behavior. We give efficient approximations of these quantities using a linearized network and demonstrate empirically that the approximation is accurate for real-world architectures, such as pre-trained ResNets. We apply these measures to several problems, such as dataset summarization, analysis of under-sampled classes, comparison of informativeness of different data sources, and detection of adversarial and corrupted examples. Our work generalizes existing frameworks but enjoys better computational properties for heavily over-parametrized models, which makes it possible to apply it to real-world networks.
Improving Generalization by Controlling Label-Noise Information in Neural Network Weights
Feb 19, 2020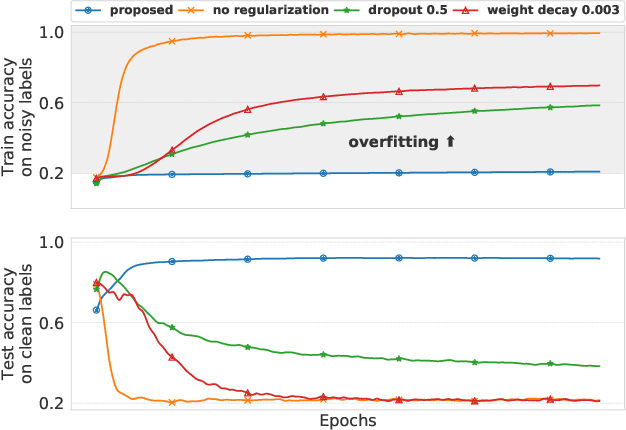
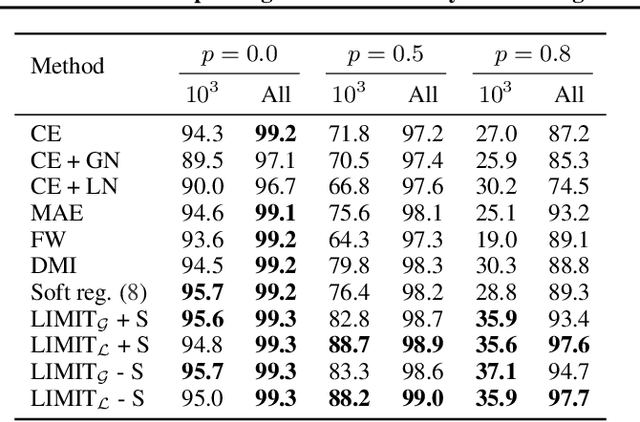
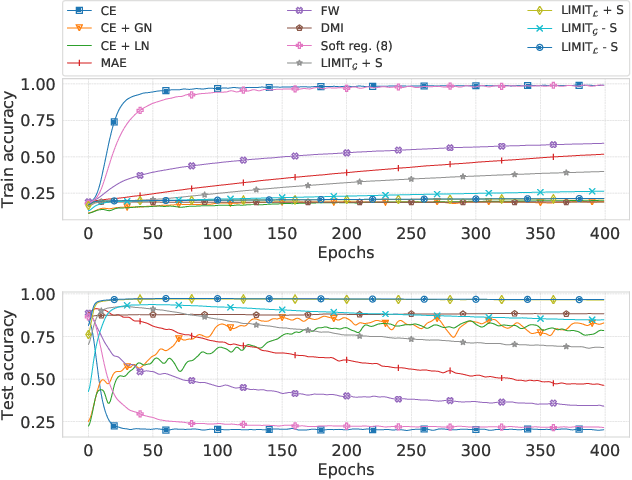
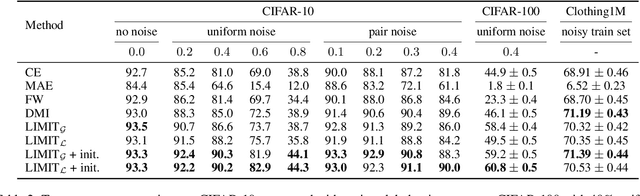
In the presence of noisy or incorrect labels, neural networks have the undesirable tendency to memorize information about the noise. Standard regularization techniques such as dropout, weight decay or data augmentation sometimes help, but do not prevent this behavior. If one considers neural network weights as random variables that depend on the data and stochasticity of training, the amount of memorized information can be quantified with the Shannon mutual information between weights and the vector of all training labels given inputs, $I(w : \mathbf{y} \mid \mathbf{x})$. We show that for any training algorithm, low values of this term correspond to reduction in memorization of label-noise and better generalization bounds. To obtain these low values, we propose training algorithms that employ an auxiliary network that predicts gradients in the final layers of a classifier without accessing labels. We illustrate the effectiveness of our approach on versions of MNIST, CIFAR-10, and CIFAR-100 corrupted with various noise models, and on a large-scale dataset Clothing1M that has noisy labels.
Efficient Covariance Estimation from Temporal Data
May 30, 2019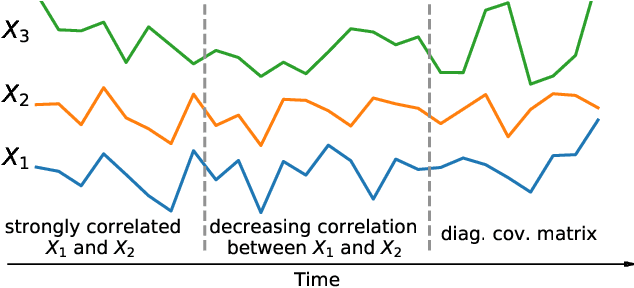
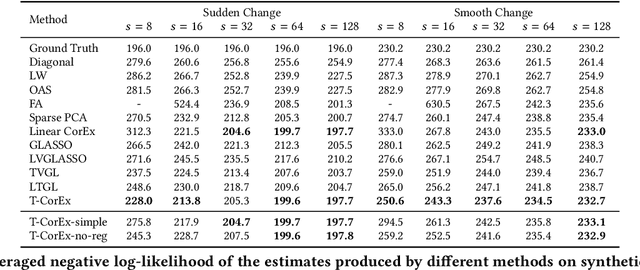
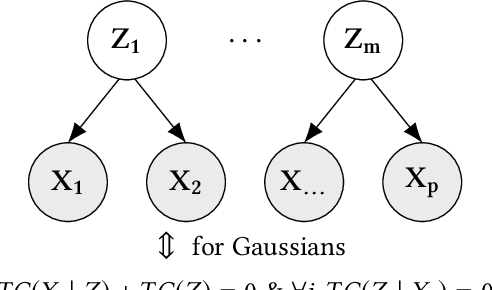
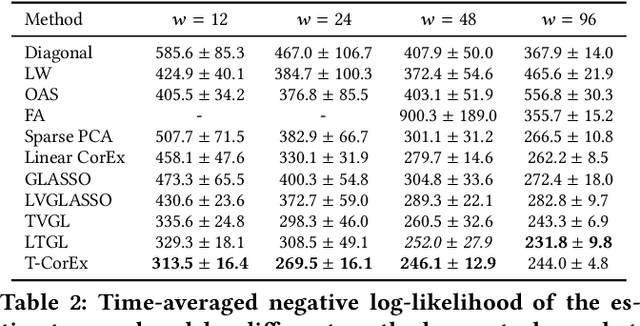
Estimating the covariance structure of multivariate time series is a fundamental problem with a wide-range of real-world applications -- from financial modeling to fMRI analysis. Despite significant recent advances, current state-of-the-art methods are still severely limited in terms of scalability, and do not work well in high-dimensional undersampled regimes. In this work we propose a novel method called Temporal Correlation Explanation, or T-CorEx, that (a) has linear time and memory complexity with respect to the number of variables, and can scale to very large temporal datasets that are not tractable with existing methods; (b) gives state-of-the-art results in highly undersampled regimes on both synthetic and real-world datasets; and (c) makes minimal assumptions about the character of the dynamics of the system. T-CorEx optimizes an information-theoretic objective function to learn a latent factor graphical model for each time period and applies two regularization techniques to induce temporal consistency of estimates. We perform extensive evaluation of T-Corex using both synthetic and real-world data and demonstrate that it can be used for detecting sudden changes in the underlying covariance matrix, capturing transient correlations and analyzing extremely high-dimensional complex multivariate time series such as high-resolution fMRI data.
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
May 28, 2019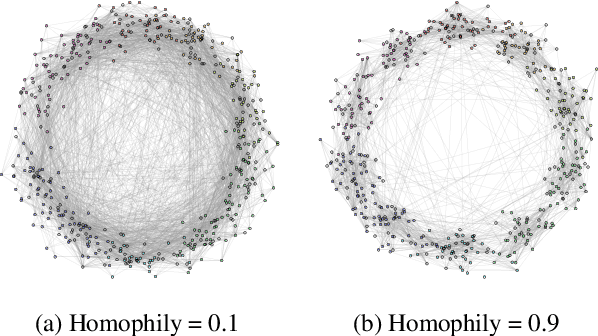
Existing popular methods for semi-supervised learning with Graph Neural Networks (such as the Graph Convolutional Network) provably cannot learn a general class of neighborhood mixing relationships. To address this weakness, we propose a new model, MixHop, that can learn these relationships, including difference operators, by repeatedly mixing feature representations of neighbors at various distances. Mixhop requires no additional memory or computational complexity, and outperforms on challenging baselines. In addition, we propose sparsity regularization that allows us to visualize how the network prioritizes neighborhood information across different graph datasets. Our analysis of the learned architectures reveals that neighborhood mixing varies per datasets.
Disentangled Representations via Synergy Minimization
Oct 10, 2017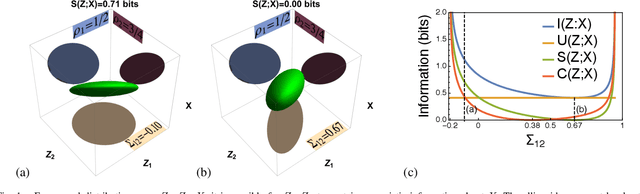

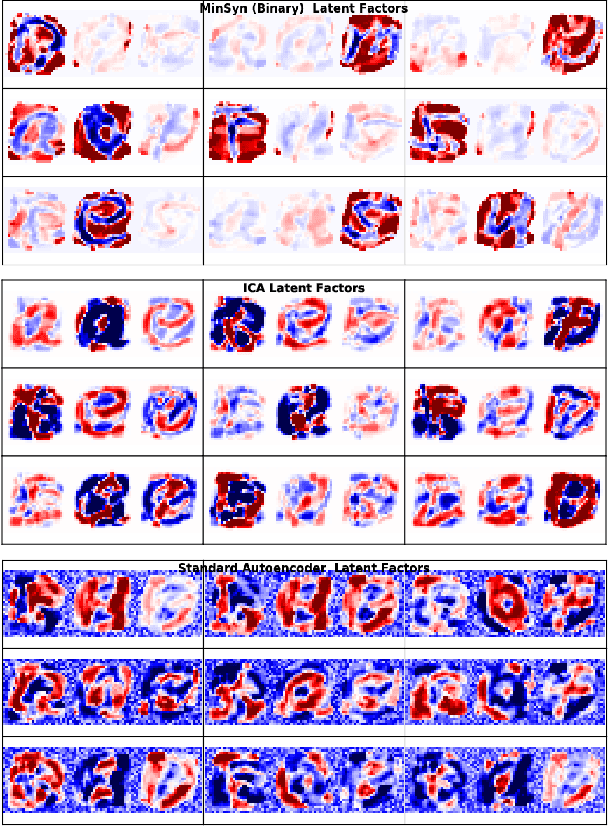

Scientists often seek simplified representations of complex systems to facilitate prediction and understanding. If the factors comprising a representation allow us to make accurate predictions about our system, but obscuring any subset of the factors destroys our ability to make predictions, we say that the representation exhibits informational synergy. We argue that synergy is an undesirable feature in learned representations and that explicitly minimizing synergy can help disentangle the true factors of variation underlying data. We explore different ways of quantifying synergy, deriving new closed-form expressions in some cases, and then show how to modify learning to produce representations that are minimally synergistic. We introduce a benchmark task to disentangle separate characters from images of words. We demonstrate that Minimally Synergistic (MinSyn) representations correctly disentangle characters while methods relying on statistical independence fail.
Multitask Learning and Benchmarking with Clinical Time Series Data
Mar 22, 2017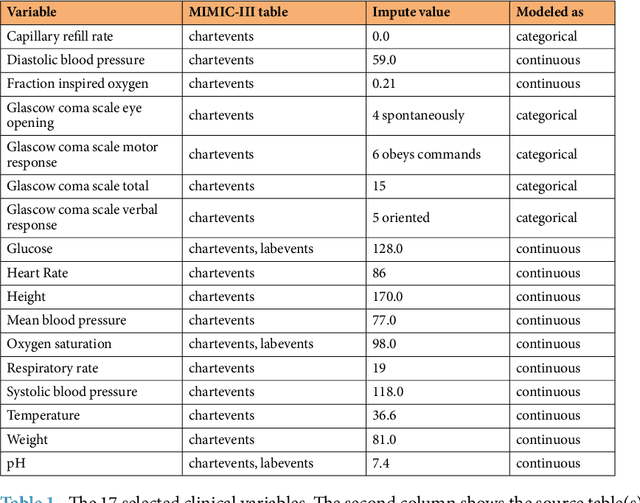
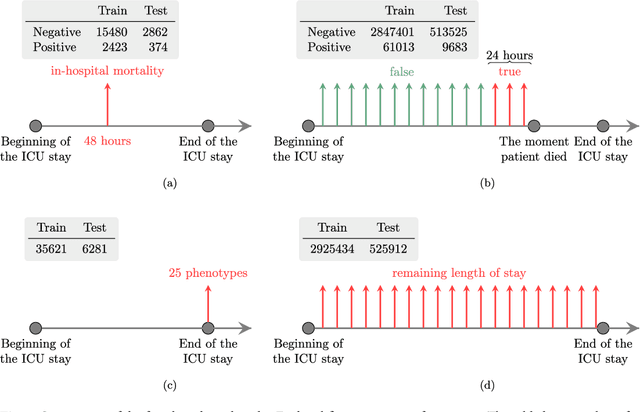
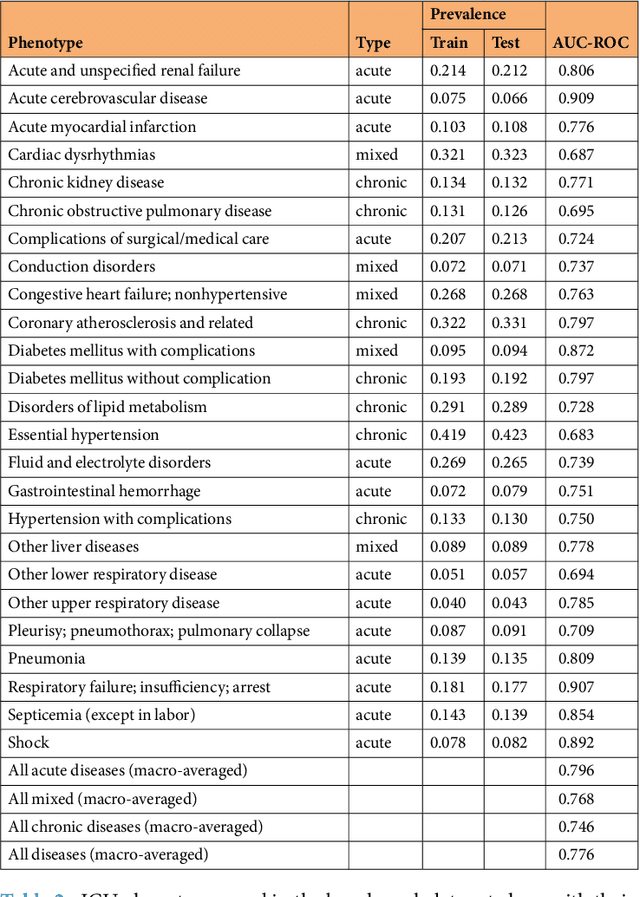
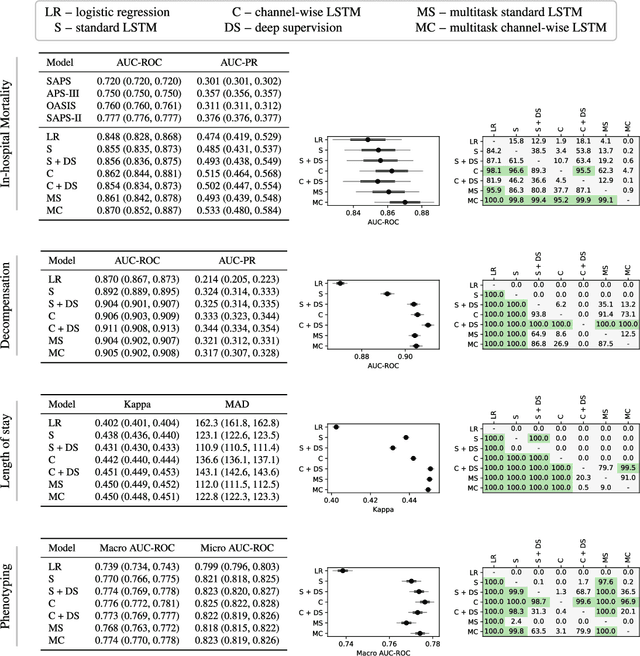
Health care is one of the most exciting frontiers in data mining and machine learning. Successful adoption of electronic health records (EHRs) created an explosion in digital clinical data available for analysis, but progress in machine learning for healthcare research has been difficult to measure because of the absence of publicly available benchmark data sets. To address this problem, we propose four clinical prediction benchmarks using data derived from the publicly available Medical Information Mart for Intensive Care (MIMIC-III) database. These tasks cover a range of clinical problems including modeling risk of mortality, forecasting length of stay, detecting physiologic decline, and phenotype classification. We formulate a heterogeneous multitask problem where the goal is to jointly learn multiple clinically relevant prediction tasks based on the same time series data. To address this problem, we propose a novel recurrent neural network (RNN) architecture that leverages the correlations between the various tasks to learn a better predictive model. We validate the proposed neural architecture on this benchmark, and demonstrate that it outperforms strong baselines, including single task RNNs.