 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Distillation: Geometry-Guided Cross-Modal Transfer for Robust 3D Object Detection
May 11, 2026Cross-modal knowledge distillation has emerged as an effective strategy for integrating point cloud and image features in 3D perception tasks. However, the modality heterogeneity, spatial misalignment, and the representation crisis of multiple modalities often limit the efficient of these cross-modal distillation methods. To address these limitations in existing approaches, we propose a hyperbolic constrained cross-modal distillation method for multimodal 3D object detection (HGC-Det). The proposed HGC-Det framework includes an image branch and a point cloud branch to extract semantic features from two different modalities. The point cloud branch comprises three core components: a 2D semantic-guided voxel optimization component (SGVO), a hyperbolic geometry constrained cross-modal feature transfer component (HFT), and a feature aggregation-based geometry optimization component (FAGO). Specifically, the SGVO component adaptively refines the spatial representation of the 3D branch by leveraging semantic cues from the image branch, thereby mitigating the issue of inadequate representation fusion. The HFT component exploits the intrinsic geometric properties of hyperbolic space to alleviate semantic loss during the fusion of high-dimensional image features and low-dimensional point cloud features. Finally, the FAGO compensates for potential spatial feature degradation introduced by the 2D semantic-guided voxel optimization component. Extensive experiments on indoor datasets (SUN RGB-D, ARKitScenes) and outdoor datasets (KITTI, nuScenes) demonstrate that our method achieves a better trade-off between detection accuracy and computational cost.
EM-RBR: a reinforced framework for knowledge graph completion from reasoning perspective
Oct 11, 2020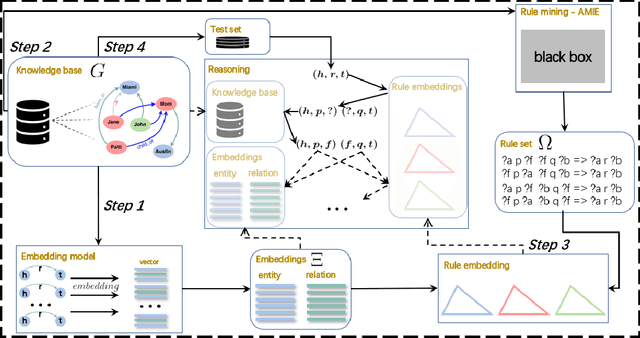
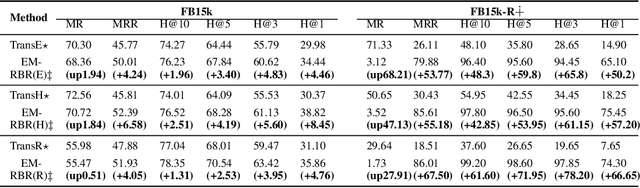
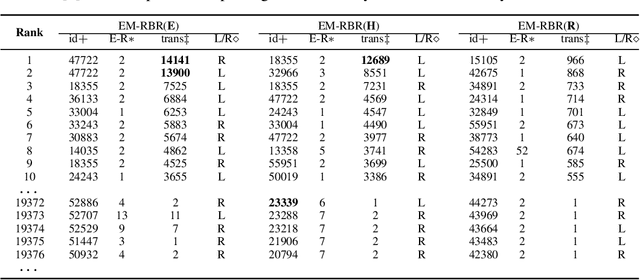
Knowledge graph completion aims to predict the new links in given entities among the knowledge graph (KG). Most mainstream embedding methods focus on fact triplets contained in the given KG, however, ignoring the rich background information provided by logic rules driven from knowledge base implicitly. To solve this problem, in this paper, we propose a general framework, named EM-RBR(embedding and rule-based reasoning), capable of combining the advantages of reasoning based on rules and the state-of-the-art models of embedding. EM-RBR aims to utilize relational background knowledge contained in rules to conduct multi-relation reasoning link prediction rather than superficial vector triangle linkage in embedding models. By this way, we can explore relation between two entities in deeper context to achieve higher accuracy. In experiments, we demonstrate that EM-RBR achieves better performance compared with previous models on FB15k, WN18 and our new dataset FB15k-R, especially the new dataset where our model perform futher better than those state-of-the-arts. We make the implementation of EM-RBR available at https://github.com/1173710224/link-prediction-with-rule-based-reasoning.