 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Metric Learning with Density Adaptivity
Sep 09, 2019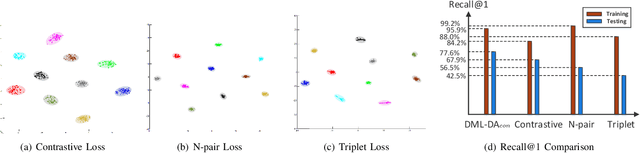
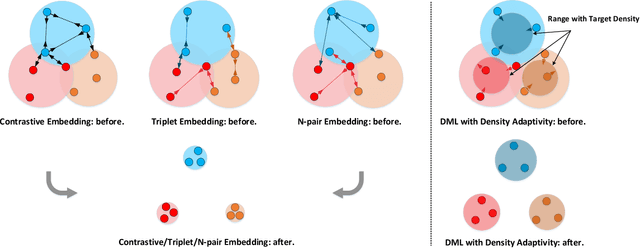
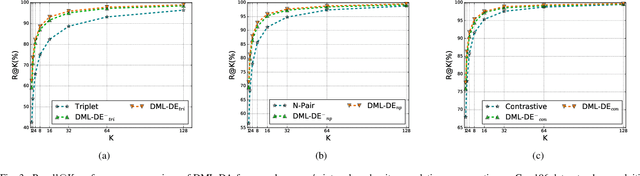
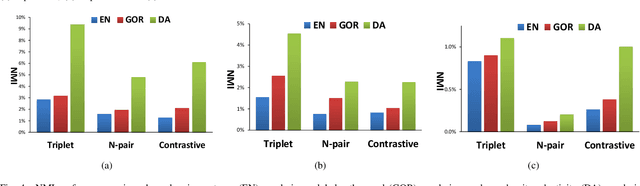
The problem of distance metric learning is mostly considered from the perspective of learning an embedding space, where the distances between pairs of examples are in correspondence with a similarity metric. With the rise and success of Convolutional Neural Networks (CNN), deep metric learning (DML) involves training a network to learn a nonlinear transformation to the embedding space. Existing DML approaches often express the supervision through maximizing inter-class distance and minimizing intra-class variation. However, the results can suffer from overfitting problem, especially when the training examples of each class are embedded together tightly and the density of each class is very high. In this paper, we integrate density, i.e., the measure of data concentration in the representation, into the optimization of DML frameworks to adaptively balance inter-class similarity and intra-class variation by training the architecture in an end-to-end manner. Technically, the knowledge of density is employed as a regularizer, which is pluggable to any DML architecture with different objective functions such as contrastive loss, N-pair loss and triplet loss. Extensive experiments on three public datasets consistently demonstrate clear improvements by amending three types of embedding with the density adaptivity. More remarkably, our proposal increases Recall@1 from 67.95% to 77.62%, from 52.01% to 55.64% and from 68.20% to 70.56% on Cars196, CUB-200-2011 and Stanford Online Products dataset, respectively.
Justlookup: One Millisecond Deep Feature Extraction for Point Clouds By Lookup Tables
Aug 14, 2019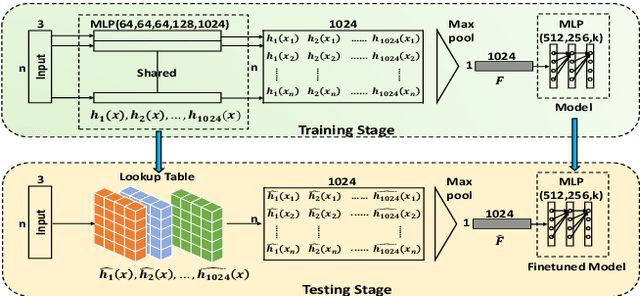
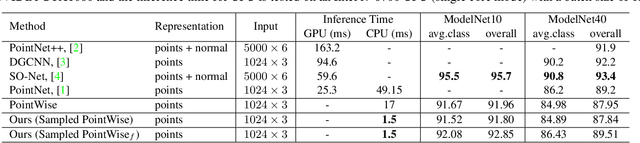
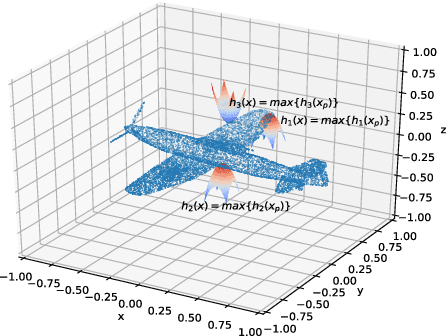
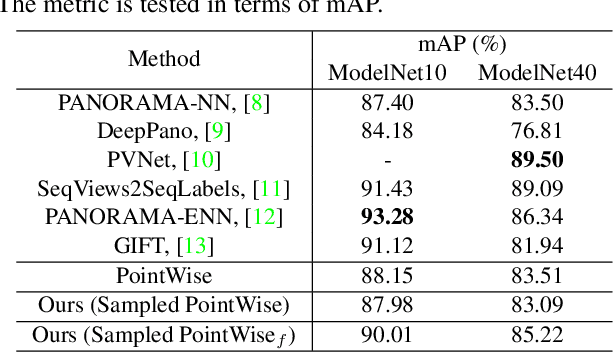
Deep models are capable of fitting complex high dimensional functions while usually yielding large computation load. There is no way to speed up the inference process by classical lookup tables due to the high-dimensional input and limited memory size. Recently, a novel architecture (PointNet) for point clouds has demonstrated that it is possible to obtain a complicated deep function from a set of 3-variable functions. In this paper, we exploit this property and apply a lookup table to encode these 3-variable functions. This method ensures that the inference time is only determined by the memory access no matter how complicated the deep function is. We conduct extensive experiments on ModelNet and ShapeNet datasets and demonstrate that we can complete the inference process in 1.5 ms on an Intel i7-8700 CPU (single core mode), 32x speedup over the PointNet architecture without any performance degradation.
Temporal Deformable Convolutional Encoder-Decoder Networks for Video Captioning
May 03, 2019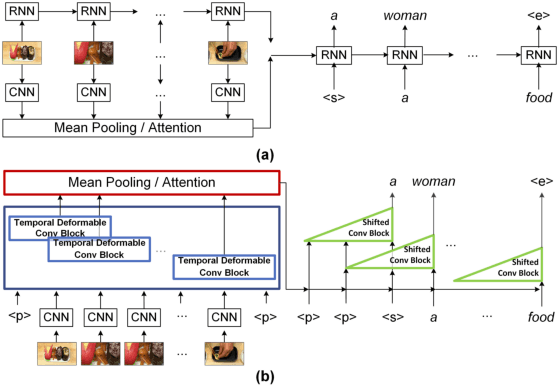
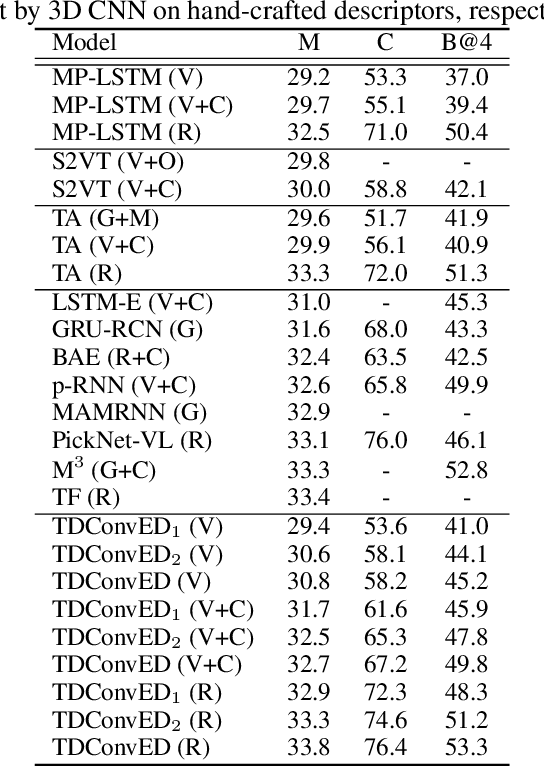
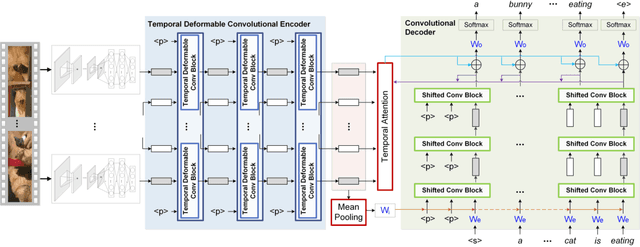
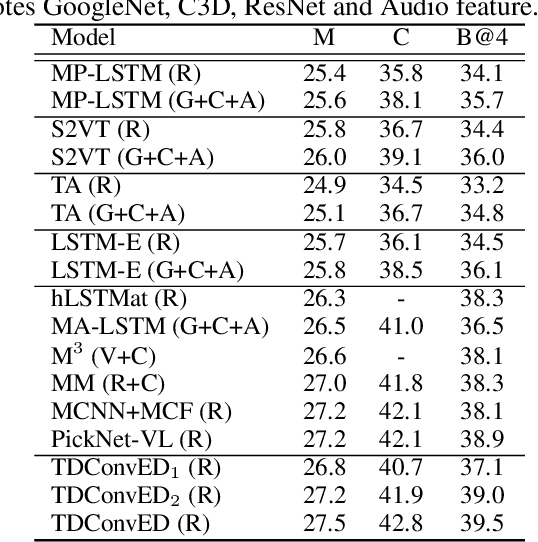
It is well believed that video captioning is a fundamental but challenging task in both computer vision and artificial intelligence fields. The prevalent approach is to map an input video to a variable-length output sentence in a sequence to sequence manner via Recurrent Neural Network (RNN). Nevertheless, the training of RNN still suffers to some degree from vanishing/exploding gradient problem, making the optimization difficult. Moreover, the inherently recurrent dependency in RNN prevents parallelization within a sequence during training and therefore limits the computations. In this paper, we present a novel design --- Temporal Deformable Convolutional Encoder-Decoder Networks (dubbed as TDConvED) that fully employ convolutions in both encoder and decoder networks for video captioning. Technically, we exploit convolutional block structures that compute intermediate states of a fixed number of inputs and stack several blocks to capture long-term relationships. The structure in encoder is further equipped with temporal deformable convolution to enable free-form deformation of temporal sampling. Our model also capitalizes on temporal attention mechanism for sentence generation. Extensive experiments are conducted on both MSVD and MSR-VTT video captioning datasets, and superior results are reported when comparing to conventional RNN-based encoder-decoder techniques. More remarkably, TDConvED increases CIDEr-D performance from 58.8% to 67.2% on MSVD.
Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting
Apr 30, 2019
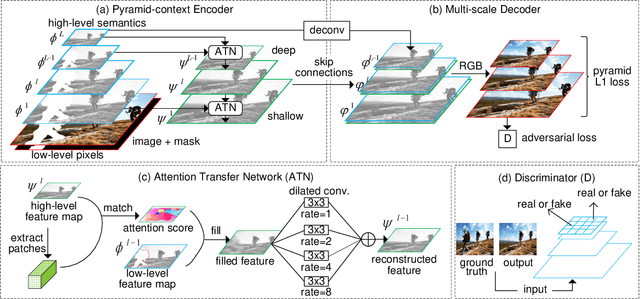

High-quality image inpainting requires filling missing regions in a damaged image with plausible content. Existing works either fill the regions by copying image patches or generating semantically-coherent patches from region context, while neglect the fact that both visual and semantic plausibility are highly-demanded. In this paper, we propose a Pyramid-context ENcoder Network (PEN-Net) for image inpainting by deep generative models. The PEN-Net is built upon a U-Net structure, which can restore an image by encoding contextual semantics from full resolution input, and decoding the learned semantic features back into images. Specifically, we propose a pyramid-context encoder, which progressively learns region affinity by attention from a high-level semantic feature map and transfers the learned attention to the previous low-level feature map. As the missing content can be filled by attention transfer from deep to shallow in a pyramid fashion, both visual and semantic coherence for image inpainting can be ensured. We further propose a multi-scale decoder with deeply-supervised pyramid losses and an adversarial loss. Such a design not only results in fast convergence in training, but more realistic results in testing. Extensive experiments on various datasets show the superior performance of the proposed network
Pointing Novel Objects in Image Captioning
Apr 25, 2019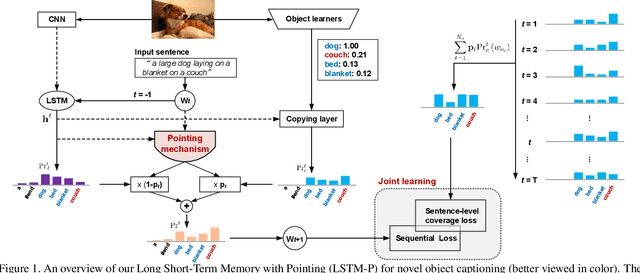
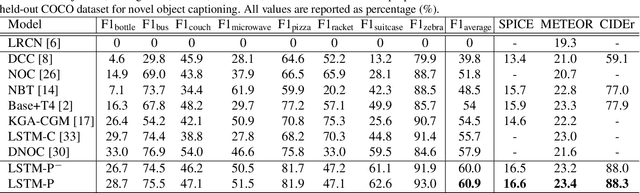

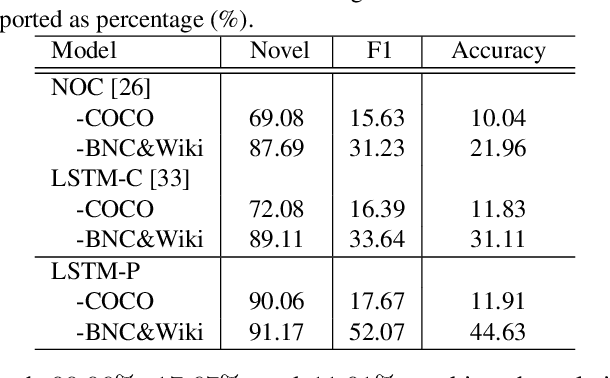
Image captioning has received significant attention with remarkable improvements in recent advances. Nevertheless, images in the wild encapsulate rich knowledge and cannot be sufficiently described with models built on image-caption pairs containing only in-domain objects. In this paper, we propose to address the problem by augmenting standard deep captioning architectures with object learners. Specifically, we present Long Short-Term Memory with Pointing (LSTM-P) --- a new architecture that facilitates vocabulary expansion and produces novel objects via pointing mechanism. Technically, object learners are initially pre-trained on available object recognition data. Pointing in LSTM-P then balances the probability between generating a word through LSTM and copying a word from the recognized objects at each time step in decoder stage. Furthermore, our captioning encourages global coverage of objects in the sentence. Extensive experiments are conducted on both held-out COCO image captioning and ImageNet datasets for describing novel objects, and superior results are reported when comparing to state-of-the-art approaches. More remarkably, we obtain an average of 60.9% in F1 score on held-out COCO~dataset.
Face Recognition from Sequential Sparse 3D data via Deep Registration
Oct 23, 2018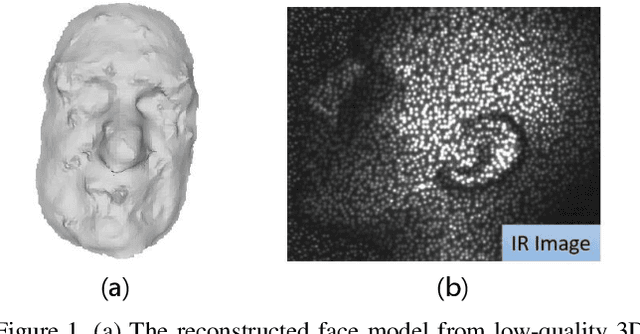

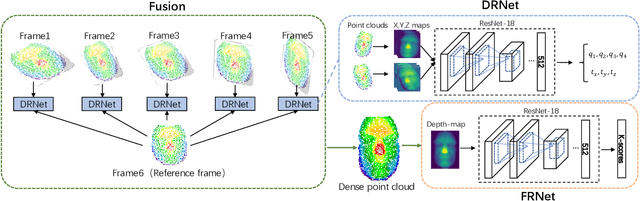
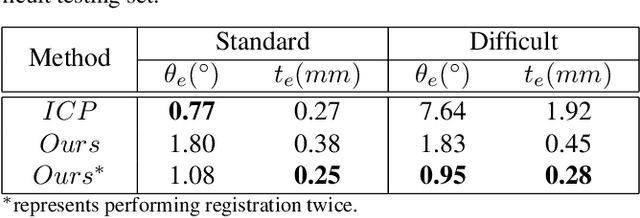
Previous works have shown that face recognition with high accuracy 3D data is more reliable and insensitive to pose and light variations. Recently, low-cost and portable 3D acquisition techniques like ToF(Time of Flight) and DoE based structured light enable us to access 3D data easily, e.g. via a mobile phone. However, these devices can only provide sparse(limited speckles in structured light system) and noisy 3D data which can not support face recognition directly. In this paper, we aim at achieving high performance face recognition for devices equipped with such modules which is very meaningful in practice as such devices will be very popular. We propose a framework to perform face recognition by fusing a sequence of low-quality 3D data. As 3D data are sparse and noisy which can not be well handled by conventional methods like the ICP algorithm, we design a PointNet-like Deep Registration Network(DRNet) which works with ordered 3D point coordinates while preserving the ability of mining local structures via convolution. Meanwhile we develop a novel loss function to optimize our DRNet based on the quaternion expression which obviously outperforms other widely used functions. For face recognition, we design a deep convolutional network which takes the fused 3D depth-map as input based on AMSoftmax model. Experiments show that our DRNet can achieve rotation error 0.95 degrees and translation error 0.28mm for registration. The face recognition on fused data also achieves rank-1 accuracy 99.2%, FAR-0.001 97.5% on Bosphorus dataset which is comparable with state-of-the-art high-quality data based recognition performance.
Jointly Localizing and Describing Events for Dense Video Captioning
Apr 23, 2018
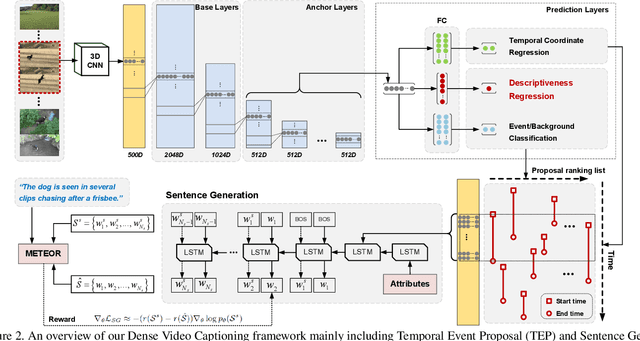
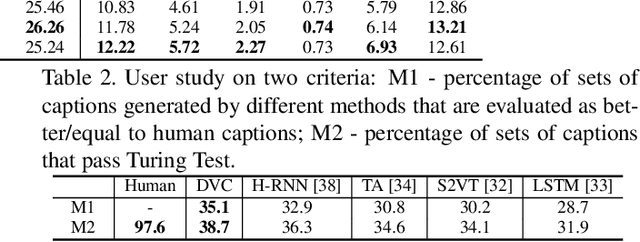
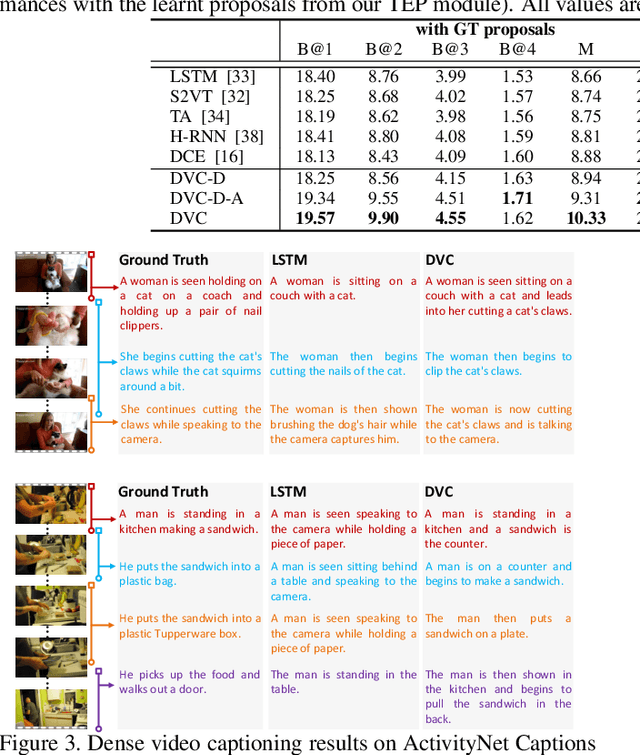
Automatically describing a video with natural language is regarded as a fundamental challenge in computer vision. The problem nevertheless is not trivial especially when a video contains multiple events to be worthy of mention, which often happens in real videos. A valid question is how to temporally localize and then describe events, which is known as "dense video captioning." In this paper, we present a novel framework for dense video captioning that unifies the localization of temporal event proposals and sentence generation of each proposal, by jointly training them in an end-to-end manner. To combine these two worlds, we integrate a new design, namely descriptiveness regression, into a single shot detection structure to infer the descriptive complexity of each detected proposal via sentence generation. This in turn adjusts the temporal locations of each event proposal. Our model differs from existing dense video captioning methods since we propose a joint and global optimization of detection and captioning, and the framework uniquely capitalizes on an attribute-augmented video captioning architecture. Extensive experiments are conducted on ActivityNet Captions dataset and our framework shows clear improvements when compared to the state-of-the-art techniques. More remarkably, we obtain a new record: METEOR of 12.96% on ActivityNet Captions official test set.
One-to-Many Network for Visually Pleasing Compression Artifacts Reduction
Apr 11, 2017

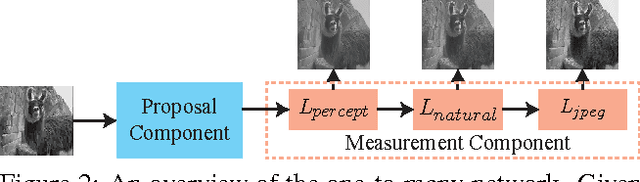
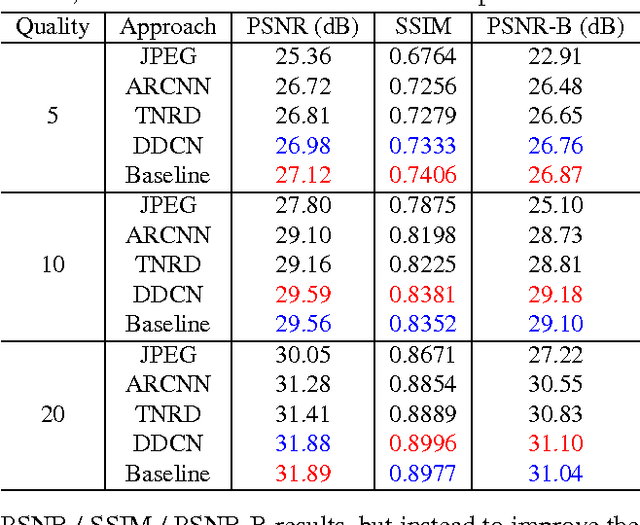
We consider the compression artifacts reduction problem, where a compressed image is transformed into an artifact-free image. Recent approaches for this problem typically train a one-to-one mapping using a per-pixel $L_2$ loss between the outputs and the ground-truths. We point out that these approaches used to produce overly smooth results, and PSNR doesn't reflect their real performance. In this paper, we propose a one-to-many network, which measures output quality using a perceptual loss, a naturalness loss, and a JPEG loss. We also avoid grid-like artifacts during deconvolution using a "shift-and-average" strategy. Extensive experimental results demonstrate the dramatic visual improvement of our approach over the state of the arts.
Automatically Building Face Datasets of New Domains from Weakly Labeled Data with Pretrained Models
Nov 24, 2016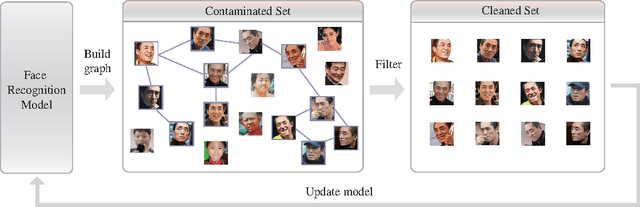
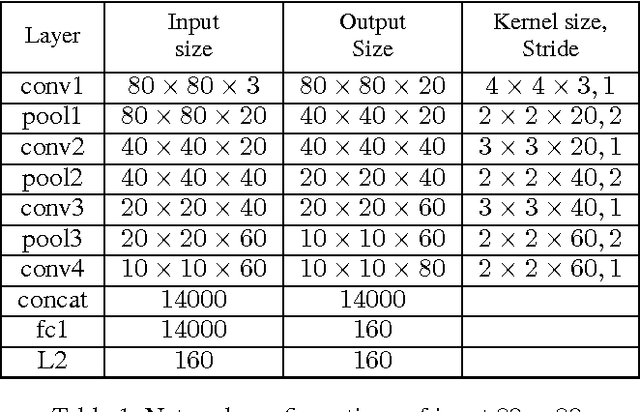
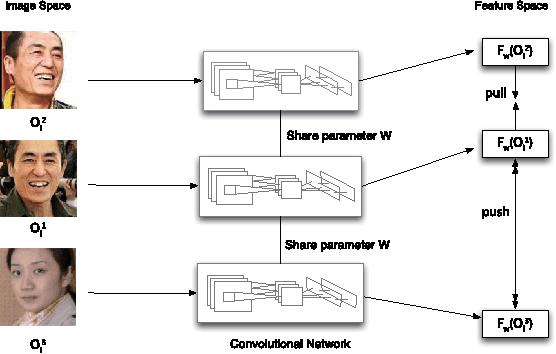
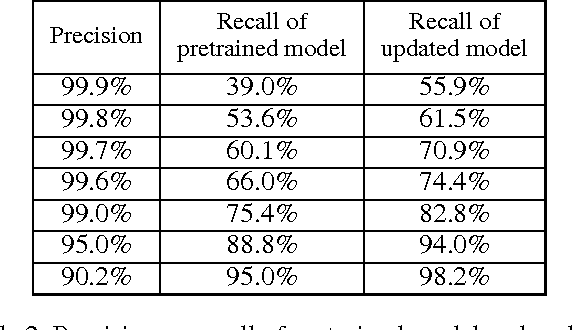
Training data are critical in face recognition systems. However, labeling a large scale face data for a particular domain is very tedious. In this paper, we propose a method to automatically and incrementally construct datasets from massive weakly labeled data of the target domain which are readily available on the Internet under the help of a pretrained face model. More specifically, given a large scale weakly labeled dataset in which each face image is associated with a label, i.e. the name of an identity, we create a graph for each identity with edges linking matched faces verified by the existing model under a tight threshold. Then we use the maximal subgraph as the cleaned data for that identity. With the cleaned dataset, we update the existing face model and use the new model to filter the original dataset to get a larger cleaned dataset. We collect a large weakly labeled dataset containing 530,560 Asian face images of 7,962 identities from the Internet, which will be published for the study of face recognition. By running the filtering process, we obtain a cleaned datasets (99.7+% purity) of size 223,767 (recall 70.9%). On our testing dataset of Asian faces, the model trained by the cleaned dataset achieves recognition rate 93.1%, which obviously outperforms the model trained by the public dataset CASIA whose recognition rate is 85.9%.
Deep Joint Face Hallucination and Recognition
Nov 24, 2016

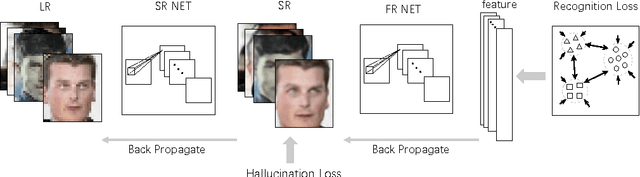
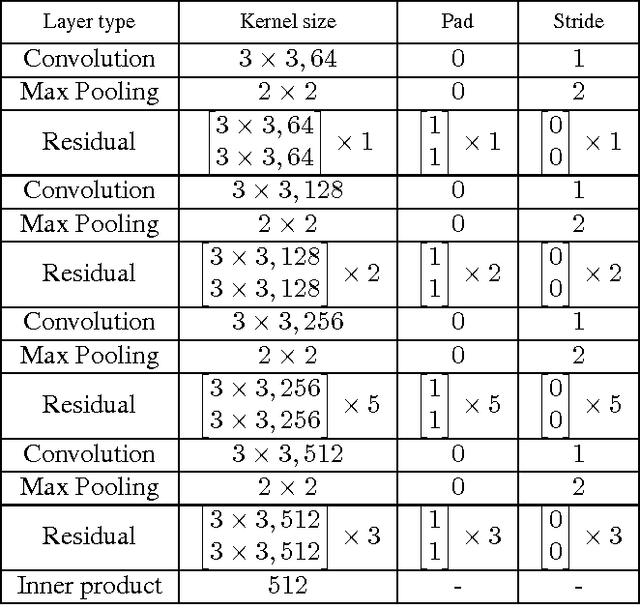
Deep models have achieved impressive performance for face hallucination tasks. However, we observe that directly feeding the hallucinated facial images into recog- nition models can even degrade the recognition performance despite the much better visualization quality. In this paper, we address this problem by jointly learning a deep model for two tasks, i.e. face hallucination and recognition. In particular, we design an end-to-end deep convolution network with hallucination sub-network cascaded by recognition sub-network. The recognition sub- network are responsible for producing discriminative feature representations using the hallucinated images as inputs generated by hallucination sub-network. During training, we feed LR facial images into the network and optimize the parameters by minimizing two loss items, i.e. 1) face hallucination loss measured by the pixel wise difference between the ground truth HR images and network-generated images; and 2) verification loss which is measured by the classification error and intra-class distance. We extensively evaluate our method on LFW and YTF datasets. The experimental results show that our method can achieve recognition accuracy 97.95% on 4x down-sampled LFW testing set, outperforming the accuracy 96.35% of conventional face recognition model. And on the more challenging YTF dataset, we achieve recognition accuracy 90.65%, a margin over the recognition accuracy 89.45% obtained by conventional face recognition model on the 4x down-sampled version.