 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Autoencoders with Relational Regularization
Feb 27, 2020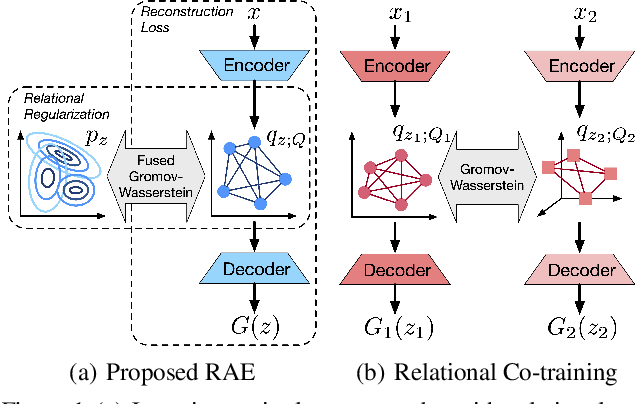

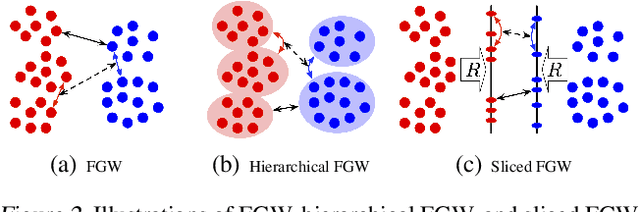
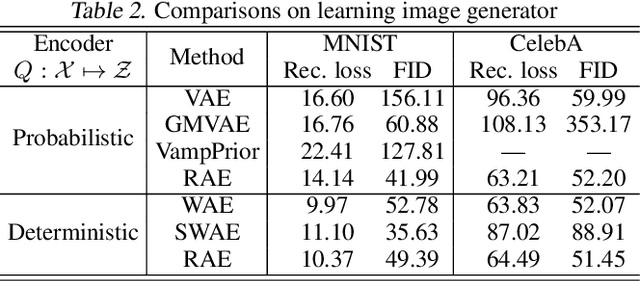
A new algorithmic framework is proposed for learning autoencoders of data distributions. We minimize the discrepancy between the model and target distributions, with a \emph{relational regularization} on the learnable latent prior. This regularization penalizes the fused Gromov-Wasserstein (FGW) distance between the latent prior and its corresponding posterior, allowing one to flexibly learn a structured prior distribution associated with the generative model. Moreover, it helps co-training of multiple autoencoders even if they have heterogeneous architectures and incomparable latent spaces. We implement the framework with two scalable algorithms, making it applicable for both probabilistic and deterministic autoencoders. Our relational regularized autoencoder (RAE) outperforms existing methods, $e.g.$, the variational autoencoder, Wasserstein autoencoder, and their variants, on generating images. Additionally, our relational co-training strategy for autoencoders achieves encouraging results in both synthesis and real-world multi-view learning tasks.
Quaternion Product Units for Deep Learning on 3D Rotation Groups
Dec 17, 2019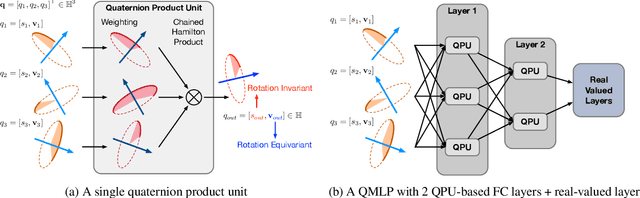
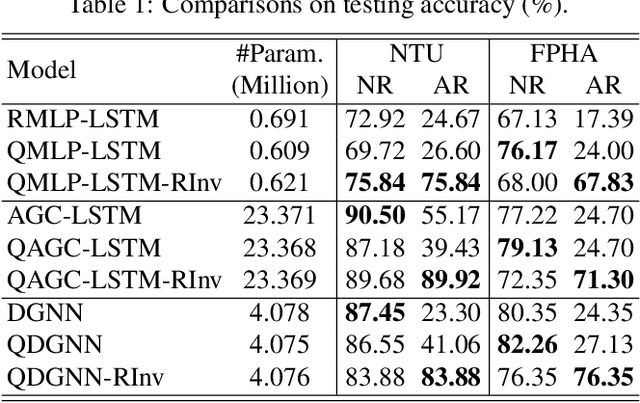
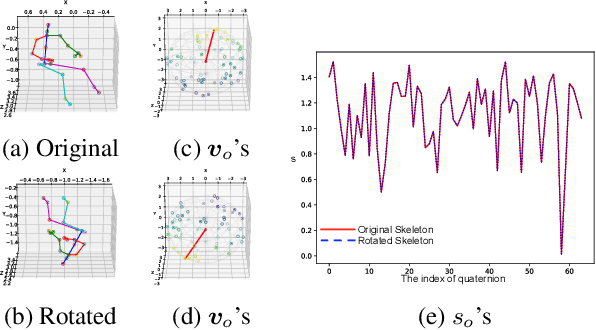

We propose a novel quaternion product unit (QPU) to represent data on 3D rotation groups. The QPU leverages quaternion algebra and the law of 3D rotation group, representing 3D rotation data as quaternions and merging them via a weighted chain of Hamilton products. We prove that the representations derived by the proposed QPU can be disentangled into "rotation-invariant" features and "rotation-equivariant" features, respectively, which supports the rationality and the efficiency of the QPU in theory. We design quaternion neural networks based on our QPUs and make our models compatible with existing deep learning models. Experiments on both synthetic and real-world data show that the proposed QPU is beneficial for the learning tasks requiring rotation robustness.
Graph-Driven Generative Models for Heterogeneous Multi-Task Learning
Nov 20, 2019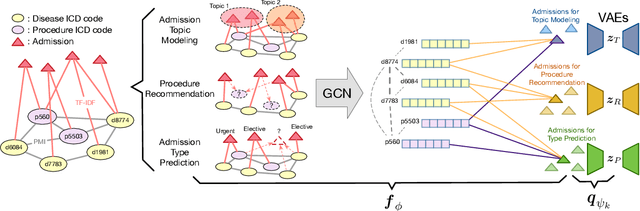

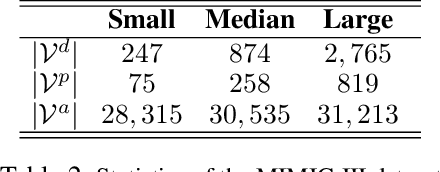

We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.
Gromov-Wasserstein Factorization Models for Graph Clustering
Nov 19, 2019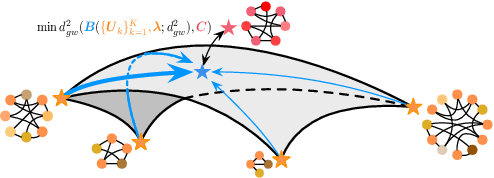
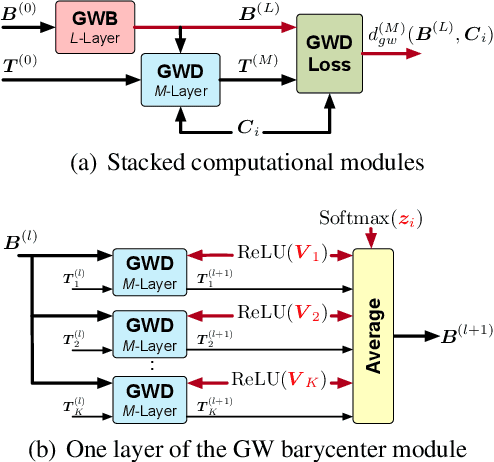
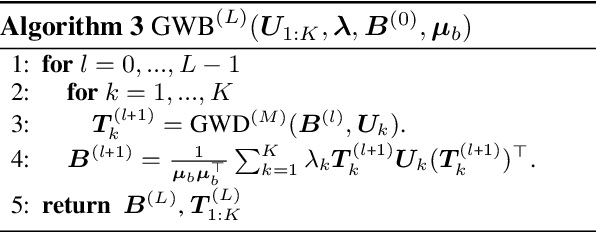
We propose a new nonlinear factorization model for graphs that are with topological structures, and optionally, node attributes. This model is based on a pseudometric called Gromov-Wasserstein (GW) discrepancy, which compares graphs in a relational way. It estimates observed graphs as GW barycenters constructed by a set of atoms with different weights. By minimizing the GW discrepancy between each observed graph and its GW barycenter-based estimation, we learn the atoms and their weights associated with the observed graphs. The model achieves a novel and flexible factorization mechanism under GW discrepancy, in which both the observed graphs and the learnable atoms can be unaligned and with different sizes. We design an effective approximate algorithm for learning this Gromov-Wasserstein factorization (GWF) model, unrolling loopy computations as stacked modules and computing gradients with backpropagation. The stacked modules can be with two different architectures, which correspond to the proximal point algorithm (PPA) and Bregman alternating direction method of multipliers (BADMM), respectively. Experiments show that our model obtains encouraging results on clustering graphs.
Collaborative Filtering with A Synthetic Feedback Loop
Oct 21, 2019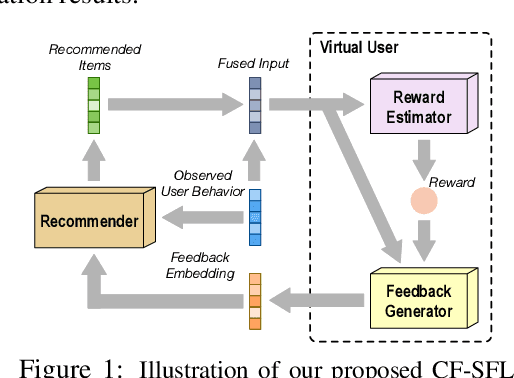
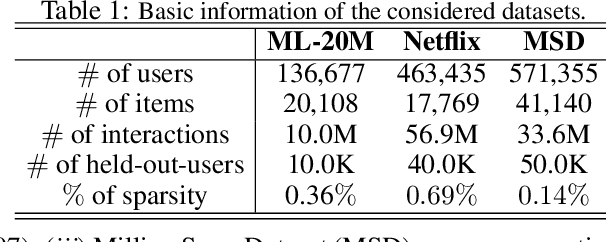
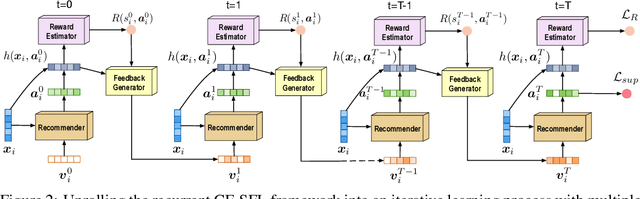

We propose a novel learning framework for recommendation systems, assisting collaborative filtering with a synthetic feedback loop. The proposed framework consists of a "recommender" and a "virtual user." The recommender is formulizd as a collaborative-filtering method, recommending items according to observed user behavior. The virtual user estimates rewards from the recommended items and generates the influence of the rewards on observed user behavior. The recommender connected with the virtual user constructs a closed loop, that recommends users with items and imitates the unobserved feedback of the users to the recommended items. The synthetic feedback is used to augment observed user behavior and improve recommendation results. Such a model can be interpreted as the inverse reinforcement learning, which can be learned effectively via rollout (simulation). Experimental results show that the proposed framework is able to boost the performance of existing collaborative filtering methods on multiple datasets.
An Optimal Transport Framework for Zero-Shot Learning
Oct 20, 2019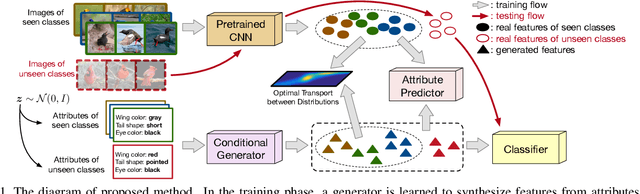
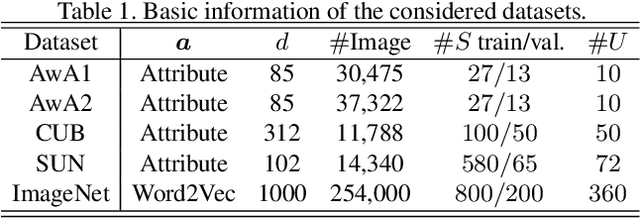
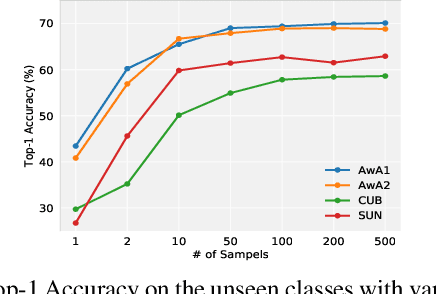
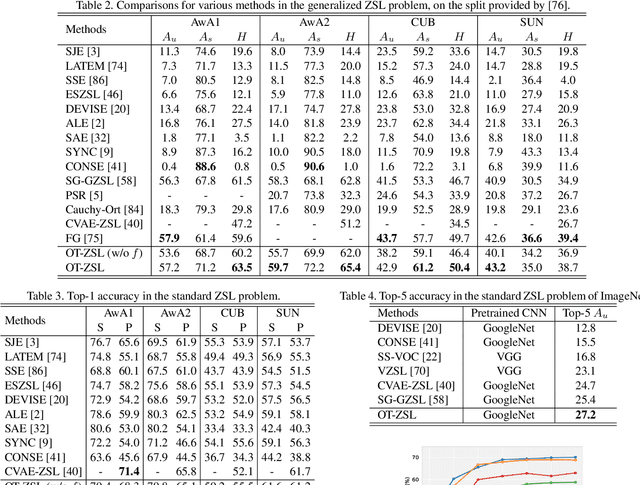
We present an optimal transport (OT) framework for generalized zero-shot learning (GZSL) of imaging data, seeking to distinguish samples for both seen and unseen classes, with the help of auxiliary attributes. The discrepancy between features and attributes is minimized by solving an optimal transport problem. {Specifically, we build a conditional generative model to generate features from seen-class attributes, and establish an optimal transport between the distribution of the generated features and that of the real features.} The generative model and the optimal transport are optimized iteratively with an attribute-based regularizer, that further enhances the discriminative power of the generated features. A classifier is learned based on the features generated for both the seen and unseen classes. In addition to generalized zero-shot learning, our framework is also applicable to standard and transductive ZSL problems. Experiments show that our optimal transport-based method outperforms state-of-the-art methods on several benchmark datasets.
Fused Gromov-Wasserstein Alignment for Hawkes Processes
Oct 04, 2019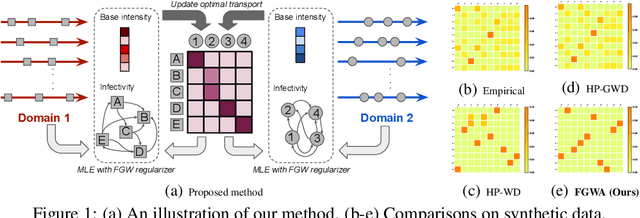
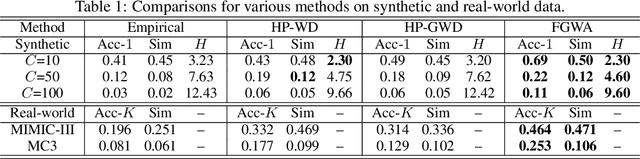
We propose a novel fused Gromov-Wasserstein alignment method to jointly learn the Hawkes processes in different event spaces, and align their event types. Given two Hawkes processes, we use fused Gromov-Wasserstein discrepancy to measure their dissimilarity, which considers both the Wasserstein discrepancy based on their base intensities and the Gromov-Wasserstein discrepancy based on their infectivity matrices. Accordingly, the learned optimal transport reflects the correspondence between the event types of these two Hawkes processes. The Hawkes processes and their optimal transport are learned jointly via maximum likelihood estimation, with a fused Gromov-Wasserstein regularizer. Experimental results show that the proposed method works well on synthetic and real-world data.
Adversarial Self-Paced Learning for Mixture Models of Hawkes Processes
Jun 20, 2019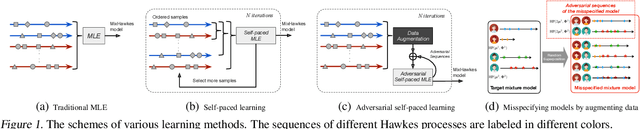

We propose a novel adversarial learning strategy for mixture models of Hawkes processes, leveraging data augmentation techniques of Hawkes process in the framework of self-paced learning. Instead of learning a mixture model directly from a set of event sequences drawn from different Hawkes processes, the proposed method learns the target model iteratively, which generates "easy" sequences and uses them in an adversarial and self-paced manner. In each iteration, we first generate a set of augmented sequences from original observed sequences. Based on the fact that an easy sample of the target model can be an adversarial sample of a misspecified model, we apply a maximum likelihood estimation with an adversarial self-paced mechanism. In this manner the target model is updated, and the augmented sequences that obey it are employed for the next learning iteration. Experimental results show that the proposed method outperforms traditional methods consistently.
Interpretable ICD Code Embeddings with Self- and Mutual-Attention Mechanisms
Jun 13, 2019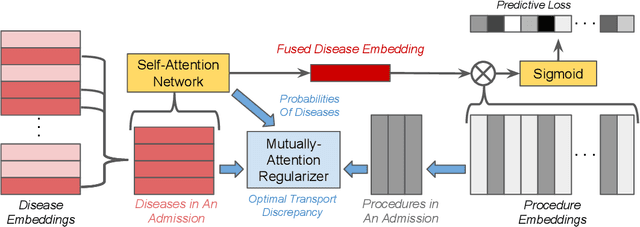
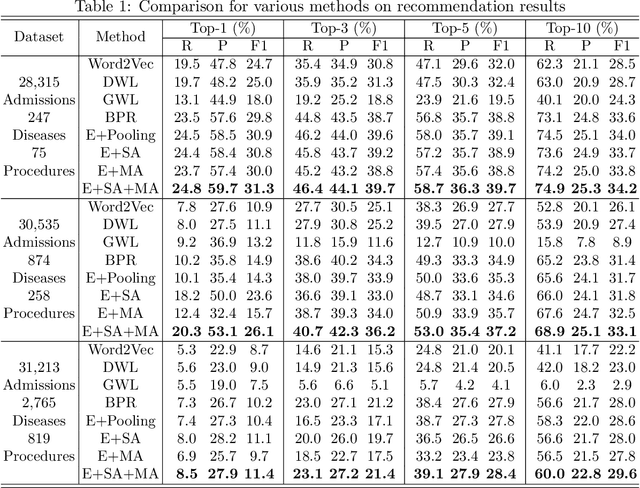
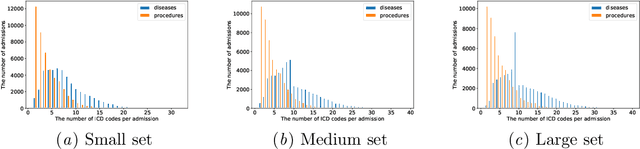
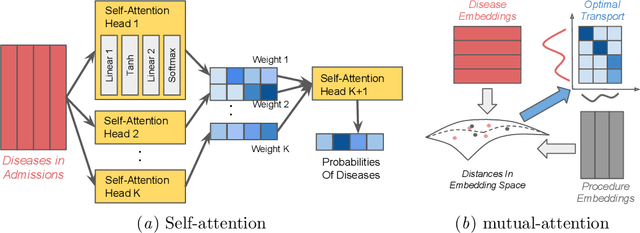
We propose a novel and interpretable embedding method to represent the international statistical classification codes of diseases and related health problems (i.e., ICD codes). This method considers a self-attention mechanism within the disease domain and a mutual-attention mechanism jointly between diseases and procedures. This framework captures the clinical relationships between the disease codes and procedures associated with hospital admissions, and it predicts procedures according to diagnosed diseases. A self-attention network is learned to fuse the embeddings of the diseases for each admission. The similarities between the fused disease embedding and the procedure embeddings indicate which procedure should potentially be recommended. Additionally, when learning the embeddings of the ICD codes, the optimal transport between the diseases and the procedures within each admission is calculated as a regularizer of the embeddings. The optimal transport provides a mutual-attention map between diseases and the procedures, which suppresses the ambiguity within their clinical relationships. The proposed method achieves clinically-interpretable embeddings of ICD codes, and outperforms state-of-the-art embedding methods in procedure recommendation.
Scalable Gromov-Wasserstein Learning for Graph Partitioning and Matching
May 22, 2019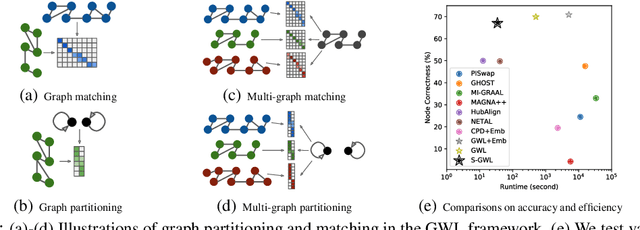
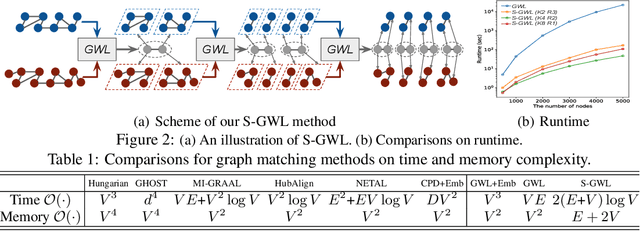
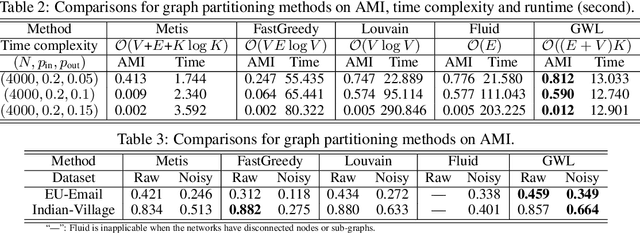
We propose a scalable Gromov-Wasserstein learning (S-GWL) method and establish a novel and theoretically-supported paradigm for large-scale graph analysis. The proposed method is based on the fact that Gromov-Wasserstein discrepancy is a pseudometric on graphs. Given two graphs, the optimal transport associated with their Gromov-Wasserstein discrepancy provides the correspondence between their nodes and achieves graph matching. When one of the graphs has isolated but self-connected nodes ($i.e.$, a disconnected graph), the optimal transport indicates the clustering structure of the other graph and achieves graph partitioning. Using this concept, we extend our method to multi-graph partitioning and matching by learning a Gromov-Wasserstein barycenter graph for multiple observed graphs; the barycenter graph plays the role of the disconnected graph, and since it is learned, so is the clustering. Our method combines a recursive $K$-partition mechanism with a regularized proximal gradient algorithm, whose time complexity is $\mathcal{O}(K(E+V)\log_K V)$ for graphs with $V$ nodes and $E$ edges. To our knowledge, our method is the first attempt to make Gromov-Wasserstein discrepancy applicable to large-scale graph analysis and unify graph partitioning and matching into the same framework. It outperforms state-of-the-art graph partitioning and matching methods, achieving a trade-off between accuracy and efficiency.