 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Arithmetic for Text-driven Image Transformation
Dec 06, 2021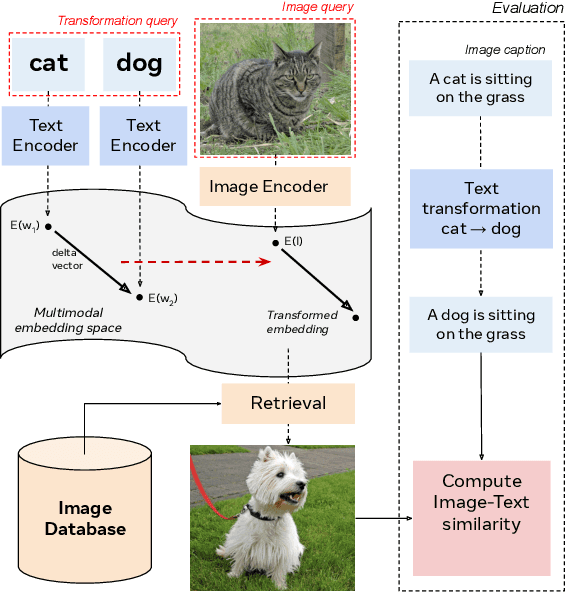

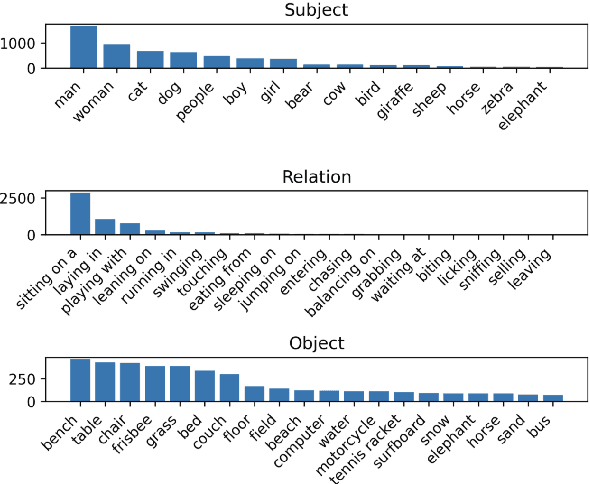
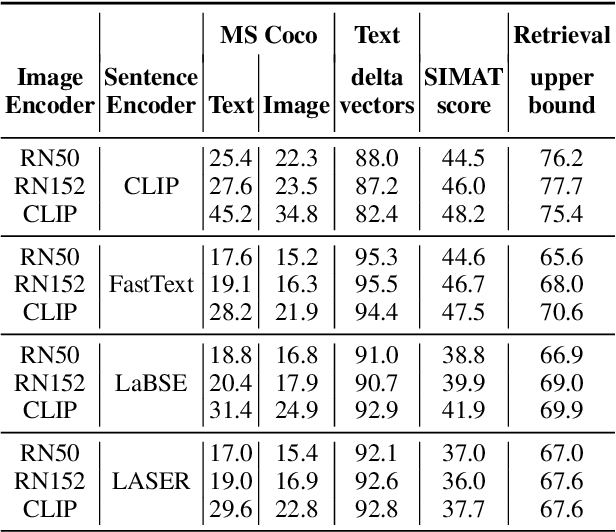
Latent text representations exhibit geometric regularities, such as the famous analogy: queen is to king what woman is to man. Such structured semantic relations were not demonstrated on image representations. Recent works aiming at bridging this semantic gap embed images and text into a multimodal space, enabling the transfer of text-defined transformations to the image modality. We introduce the SIMAT dataset to evaluate the task of text-driven image transformation. SIMAT contains 6k images and 18k "transformation queries" that aim at either replacing scene elements or changing their pairwise relationships. The goal is to retrieve an image consistent with the (source image, transformation) query. We use an image/text matching oracle (OSCAR) to assess whether the image transformation is successful. The SIMAT dataset will be publicly available. We use SIMAT to show that vanilla CLIP multimodal embeddings are not very well suited for text-driven image transformation, but that a simple finetuning on the COCO dataset can bring dramatic improvements. We also study whether it is beneficial to leverage the geometric properties of pretrained universal sentence encoders (FastText, LASER and LaBSE).
FST: the FAIR Speech Translation System for the IWSLT21 Multilingual Shared Task
Aug 14, 2021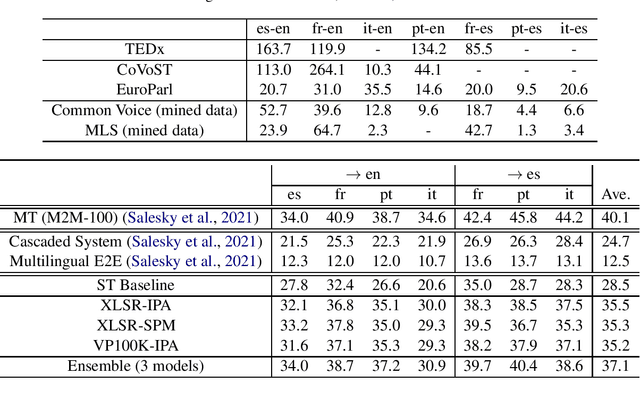
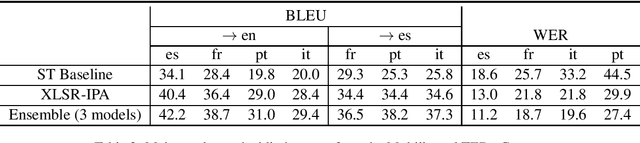
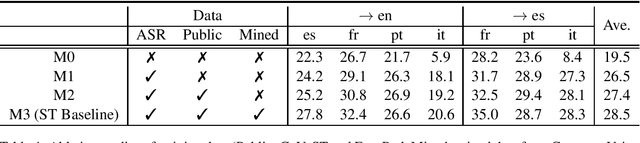
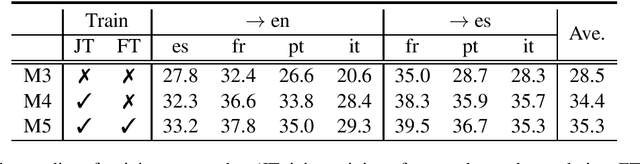
In this paper, we describe our end-to-end multilingual speech translation system submitted to the IWSLT 2021 evaluation campaign on the Multilingual Speech Translation shared task. Our system is built by leveraging transfer learning across modalities, tasks and languages. First, we leverage general-purpose multilingual modules pretrained with large amounts of unlabelled and labelled data. We further enable knowledge transfer from the text task to the speech task by training two tasks jointly. Finally, our multilingual model is finetuned on speech translation task-specific data to achieve the best translation results. Experimental results show our system outperforms the reported systems, including both end-to-end and cascaded based approaches, by a large margin. In some translation directions, our speech translation results evaluated on the public Multilingual TEDx test set are even comparable with the ones from a strong text-to-text translation system, which uses the oracle speech transcripts as input.
Beyond English-Centric Multilingual Machine Translation
Oct 21, 2020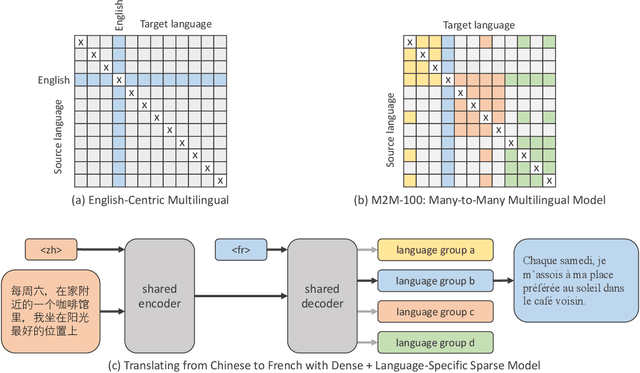
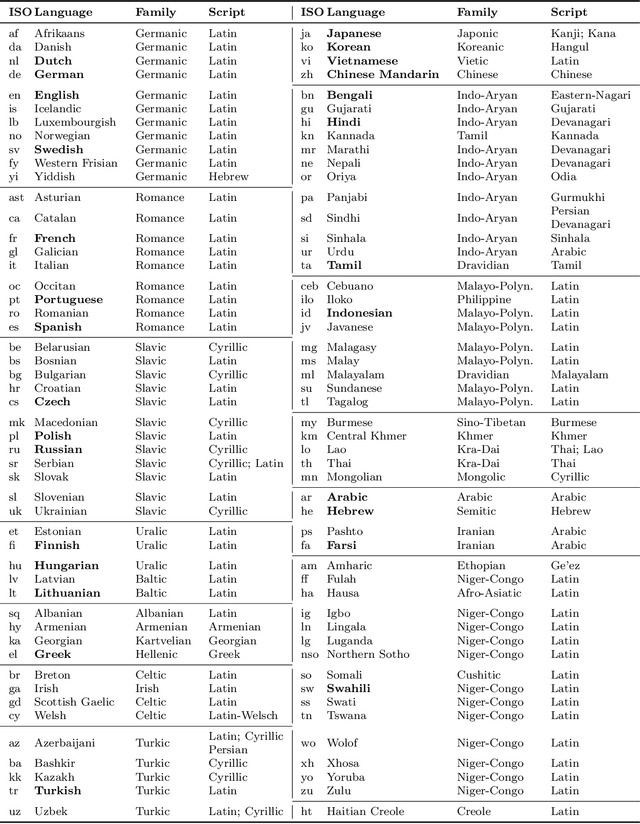
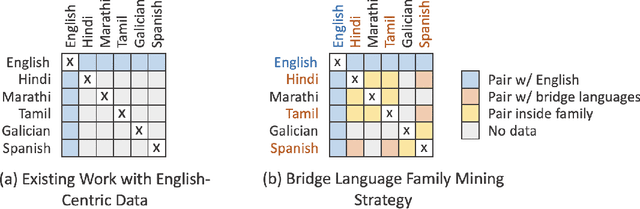

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB
Nov 10, 2019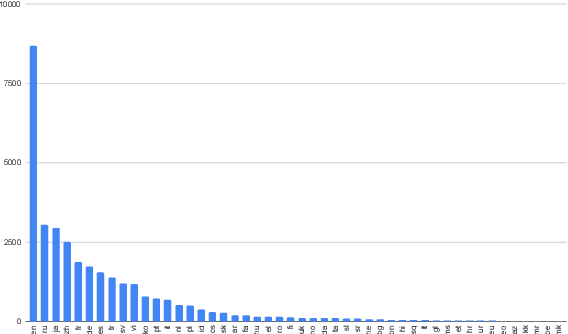
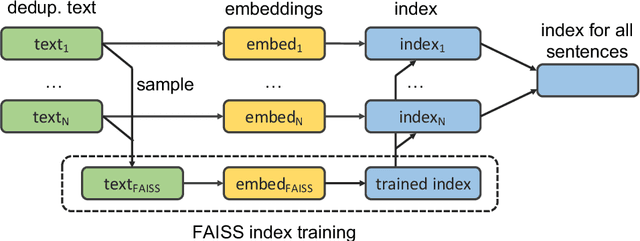
We show that margin-based bitext mining in a multilingual sentence space can be applied to monolingual corpora of billions of sentences. We are using ten snapshots of a curated common crawl corpus (Wenzek et al., 2019) totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, we were able to mine 3.5 billions parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more then 30 million parallel sentences, 82 more then 10 million, and most more than one million, including direct alignments between many European or Asian languages. To evaluate the quality of the mined bitexts, we train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Using our mined bitexts only and no human translated parallel data, we achieve a new state-of-the-art for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French. In particular, our English/German system outperforms the best single one by close to 4 BLEU points and is almost on pair with best WMT'19 evaluation system which uses system combination and back-translation. We also achieve excellent results for distant languages pairs like Russian/Japanese, outperforming the best submission at the 2019 workshop on Asian Translation (WAT).
MLQA: Evaluating Cross-lingual Extractive Question Answering
Nov 07, 2019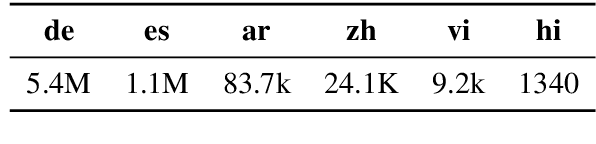
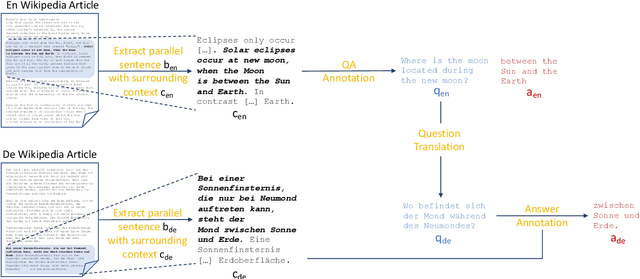
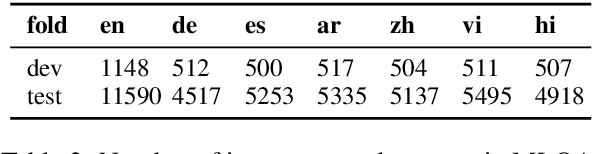
Question answering (QA) models have shown rapid progress enabled by the availability of large, high-quality benchmark datasets. Such annotated datasets are difficult and costly to collect, and rarely exist in languages other than English, making training QA systems in other languages challenging. An alternative to building large monolingual training datasets is to develop cross-lingual systems which can transfer to a target language without requiring training data in that language. In order to develop such systems, it is crucial to invest in high quality multilingual evaluation benchmarks to measure progress. We present MLQA, a multi-way aligned extractive QA evaluation benchmark intended to spur research in this area. MLQA contains QA instances in 7 languages, namely English, Arabic, German, Spanish, Hindi, Vietnamese and Simplified Chinese. It consists of over 12K QA instances in English and 5K in each other language, with each QA instance being parallel between 4 languages on average. MLQA is built using a novel alignment context strategy on Wikipedia articles, and serves as a cross-lingual extension to existing extractive QA datasets. We evaluate current state-of-the-art cross-lingual representations on MLQA, and also provide machine-translation-based baselines. In all cases, transfer results are shown to be significantly behind training-language performance.
WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia
Jul 16, 2019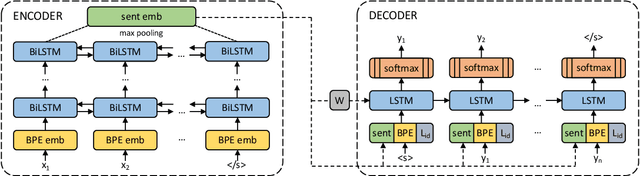

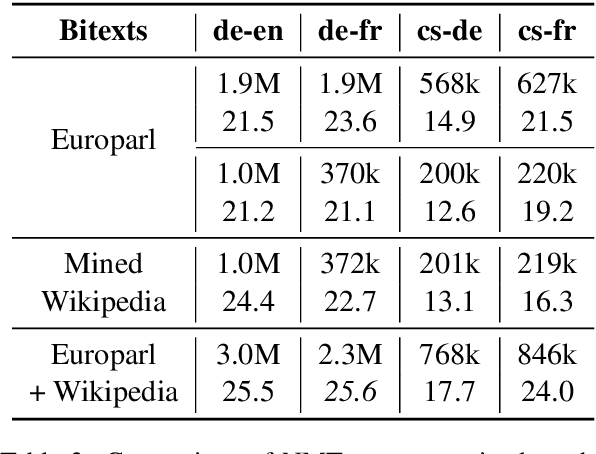
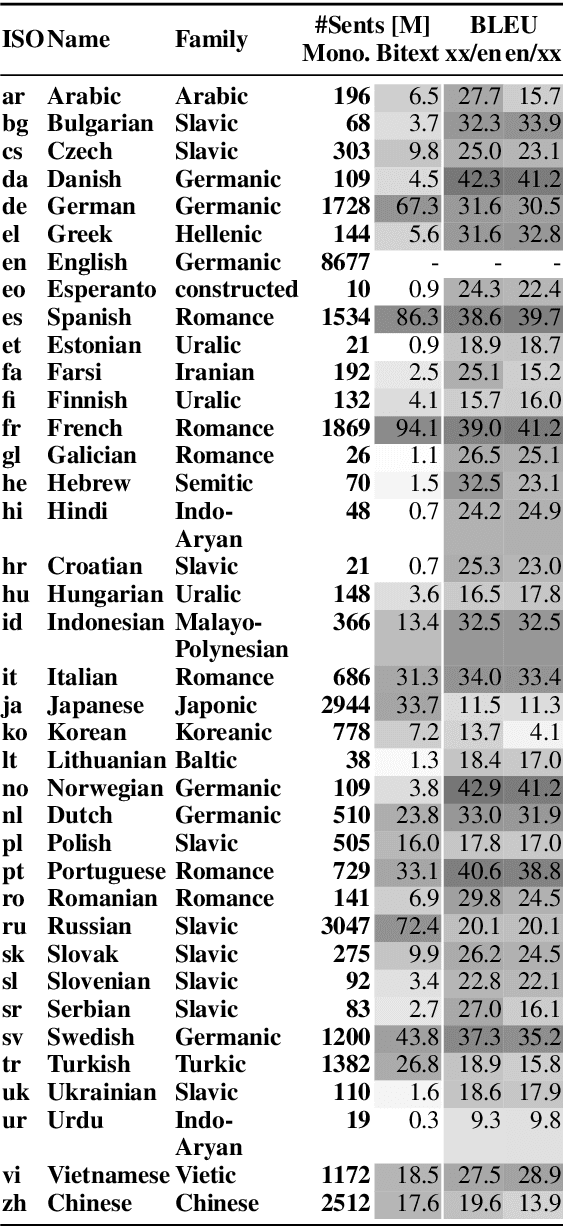
We present an approach based on multilingual sentence embeddings to automatically extract parallel sentences from the content of Wikipedia articles in 85 languages, including several dialects or low-resource languages. We do not limit the the extraction process to alignments with English, but systematically consider all possible language pairs. In total, we are able to extract 135M parallel sentences for 1620 different language pairs, out of which only 34M are aligned with English. This corpus of parallel sentences is freely available at https://github.com/facebookresearch/LASER/tree/master/tasks/WikiMatrix. To get an indication on the quality of the extracted bitexts, we train neural MT baseline systems on the mined data only for 1886 languages pairs, and evaluate them on the TED corpus, achieving strong BLEU scores for many language pairs. The WikiMatrix bitexts seem to be particularly interesting to train MT systems between distant languages without the need to pivot through English.
Low-Resource Corpus Filtering using Multilingual Sentence Embeddings
Jun 20, 2019
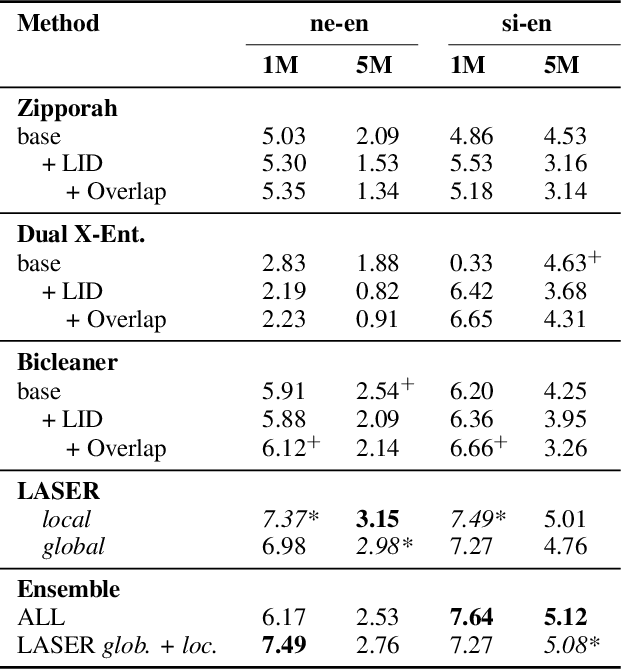
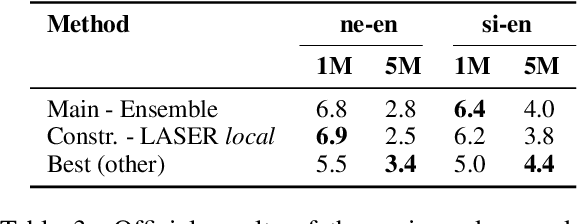
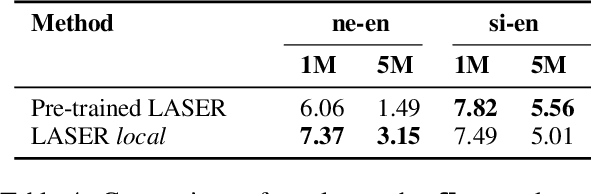
In this paper, we describe our submission to the WMT19 low-resource parallel corpus filtering shared task. Our main approach is based on the LASER toolkit (Language-Agnostic SEntence Representations), which uses an encoder-decoder architecture trained on a parallel corpus to obtain multilingual sentence representations. We then use the representations directly to score and filter the noisy parallel sentences without additionally training a scoring function. We contrast our approach to other promising methods and show that LASER yields strong results. Finally, we produce an ensemble of different scoring methods and obtain additional gains. Our submission achieved the best overall performance for both the Nepali-English and Sinhala-English 1M tasks by a margin of 1.3 and 1.4 BLEU respectively, as compared to the second best systems. Moreover, our experiments show that this technique is promising for low and even no-resource scenarios.
* 6 pages, WMT 2019
Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond
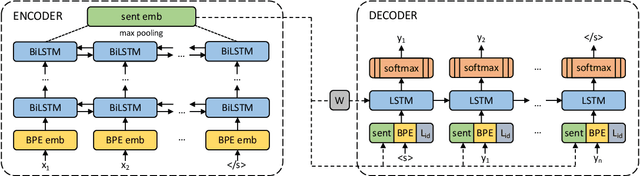
Dec 26, 2018We introduce an architecture to learn joint multilingual sentence representations for 93 languages, belonging to more than 30 different language families and written in 28 different scripts. Our system uses a single BiLSTM encoder with a shared BPE vocabulary for all languages, which is coupled with an auxiliary decoder and trained on publicly available parallel corpora. This enables us to learn a classifier on top of the resulting sentence embeddings using English annotated data only, and transfer it to any of the 93 languages without any modification. Our approach sets a new state-of-the-art on zero-shot cross-lingual natural language inference for all the 14 languages in the XNLI dataset but one. We also achieve very competitive results in cross-lingual document classification (MLDoc dataset). Our sentence embeddings are also strong at parallel corpus mining, establishing a new state-of-the-art in the BUCC shared task for 3 of its 4 language pairs. Finally, we introduce a new test set of aligned sentences in 122 languages based on the Tatoeba corpus, and show that our sentence embeddings obtain strong results in multilingual similarity search even for low-resource languages. Our PyTorch implementation, pre-trained encoder and the multilingual test set will be freely available.
Margin-based Parallel Corpus Mining with Multilingual Sentence Embeddings
Nov 03, 2018
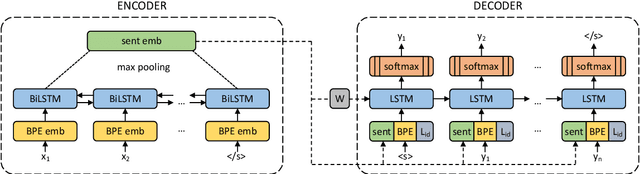
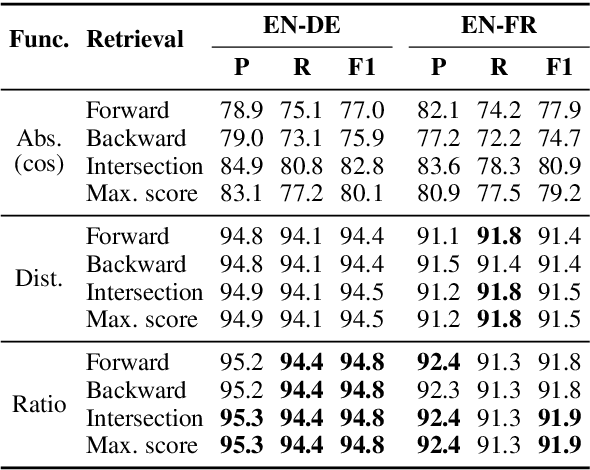
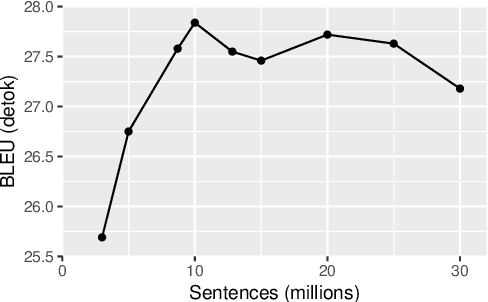
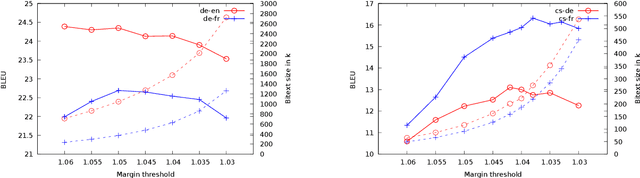
Machine translation is highly sensitive to the size and quality of the training data, which has led to an increasing interest in collecting and filtering large parallel corpora. In this paper, we propose a new method for this task based on multilingual sentence embeddings. Our approach uses an encoder-decoder trained over an initial parallel corpus to build multilingual sentence representations, which are then incorporated into a new margin-based method to score, mine and filter parallel sentences. In contrast to previous approaches, which rely on nearest neighbor retrieval with a hard threshold over cosine similarity, our proposed method accounts for the scale inconsistencies of this measure, considering the margin between a given sentence pair and its closest candidates instead. Our experiments show large improvements over existing methods. We outperform the best published results on the BUCC shared task on parallel corpus mining by more than 10 F1 points. We also improve the precision from 48.9 to 83.3 on the reconstruction of 11.3M English-French sentence pairs of the UN corpus. Finally, filtering the English-German ParaCrawl corpus with our approach, we obtain 31.2 BLEU points on newstest2014, an improvement of more than one point over the best official filtered version.
XNLI: Evaluating Cross-lingual Sentence Representations
Sep 13, 2018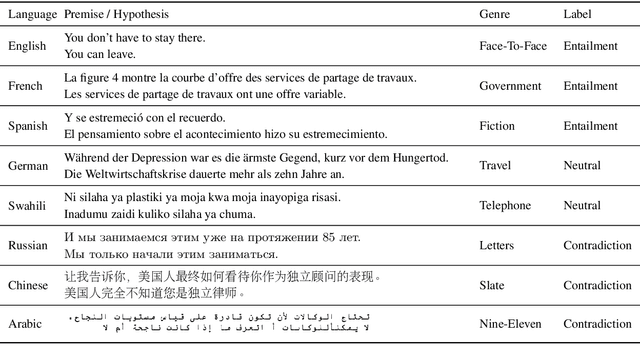
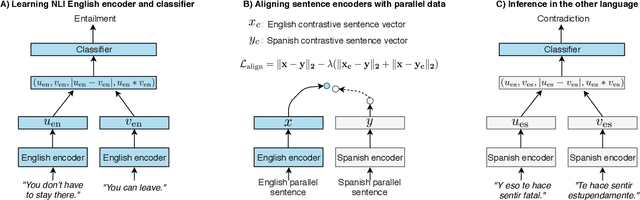

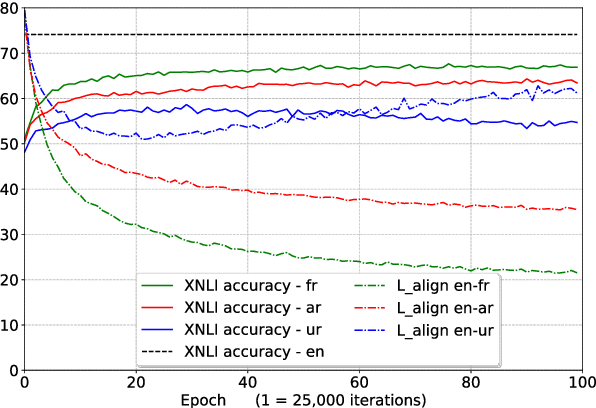
State-of-the-art natural language processing systems rely on supervision in the form of annotated data to learn competent models. These models are generally trained on data in a single language (usually English), and cannot be directly used beyond that language. Since collecting data in every language is not realistic, there has been a growing interest in cross-lingual language understanding (XLU) and low-resource cross-language transfer. In this work, we construct an evaluation set for XLU by extending the development and test sets of the Multi-Genre Natural Language Inference Corpus (MultiNLI) to 15 languages, including low-resource languages such as Swahili and Urdu. We hope that our dataset, dubbed XNLI, will catalyze research in cross-lingual sentence understanding by providing an informative standard evaluation task. In addition, we provide several baselines for multilingual sentence understanding, including two based on machine translation systems, and two that use parallel data to train aligned multilingual bag-of-words and LSTM encoders. We find that XNLI represents a practical and challenging evaluation suite, and that directly translating the test data yields the best performance among available baselines.