 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Modeling for End-to-End Empathetic Dialogue Speech Synthesis Using Linguistic and Prosodic Contexts of Dialogue History
Jun 16, 2022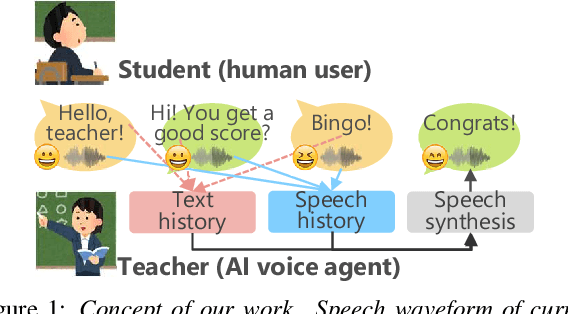
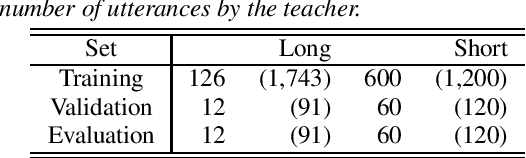
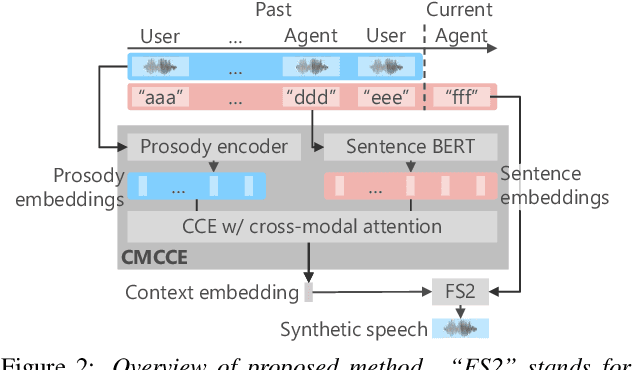
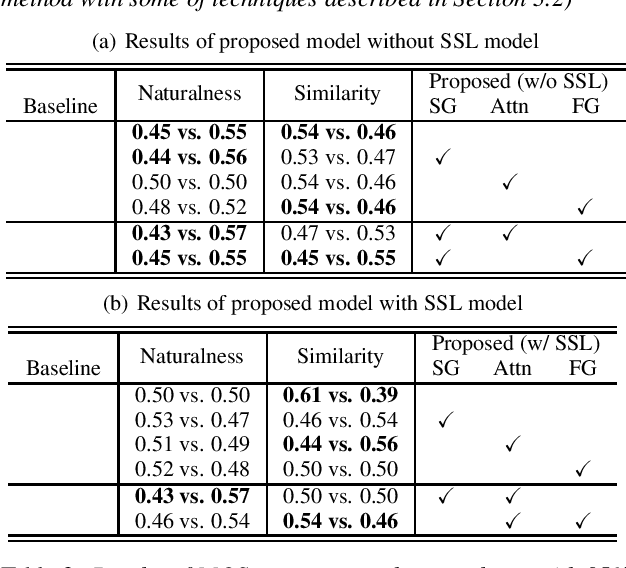
We propose an end-to-end empathetic dialogue speech synthesis (DSS) model that considers both the linguistic and prosodic contexts of dialogue history. Empathy is the active attempt by humans to get inside the interlocutor in dialogue, and empathetic DSS is a technology to implement this act in spoken dialogue systems. Our model is conditioned by the history of linguistic and prosody features for predicting appropriate dialogue context. As such, it can be regarded as an extension of the conventional linguistic-feature-based dialogue history modeling. To train the empathetic DSS model effectively, we investigate 1) a self-supervised learning model pretrained with large speech corpora, 2) a style-guided training using a prosody embedding of the current utterance to be predicted by the dialogue context embedding, 3) a cross-modal attention to combine text and speech modalities, and 4) a sentence-wise embedding to achieve fine-grained prosody modeling rather than utterance-wise modeling. The evaluation results demonstrate that 1) simply considering prosodic contexts of the dialogue history does not improve the quality of speech in empathetic DSS and 2) introducing style-guided training and sentence-wise embedding modeling achieves higher speech quality than that by the conventional method.
Region-to-region kernel interpolation of acoustic transfer function with directional weighting
May 05, 2022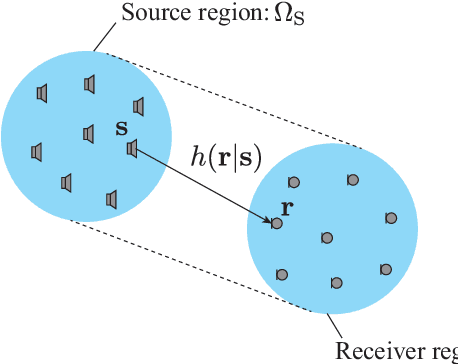
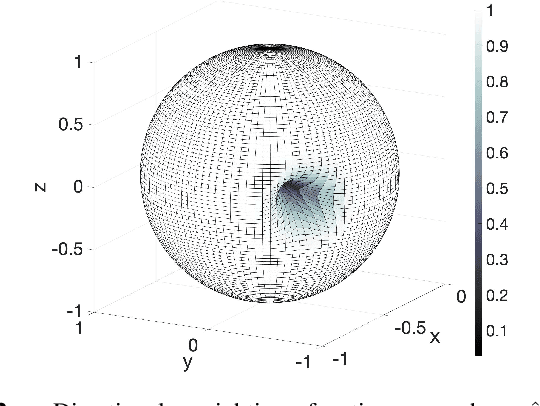
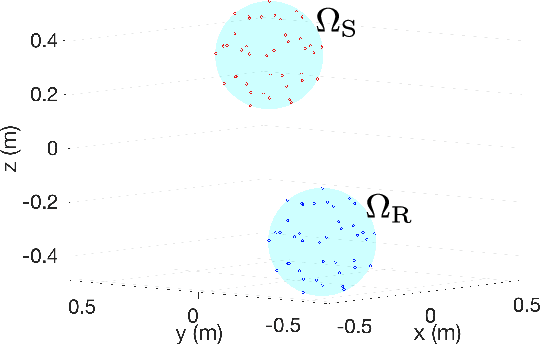
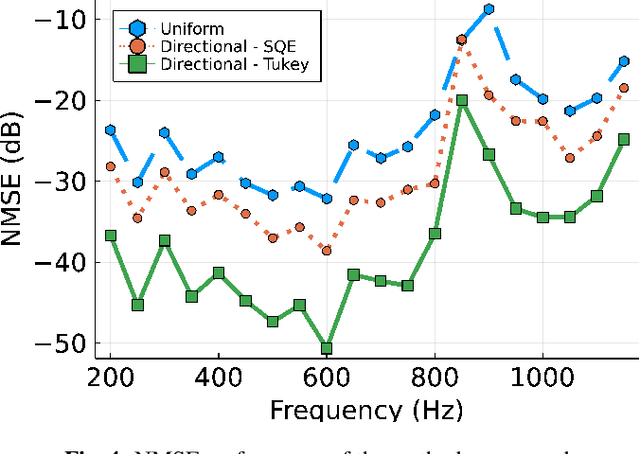
A method of interpolating the acoustic transfer function (ATF) between regions that takes into account both the physical properties of the ATF and the directionality of region configurations is proposed. Most spatial ATF interpolation methods are limited to estimation in the region of receivers. A kernel method for region-to-region ATF interpolation makes it possible to estimate the ATFs for both source and receiver regions from a discrete set of ATF measurements. We newly formulate the reproducing kernel Hilbert space and associated kernel function incorporating directional weight to enhance the interpolation accuracy. We also investigate hyperparameter optimization methods for this kernel function. Numerical experiments indicate that the proposed method outperforms the method without the use of directional weighting.
* To appear in ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Speaking-Rate-Controllable HiFi-GAN Using Feature Interpolation
Apr 22, 2022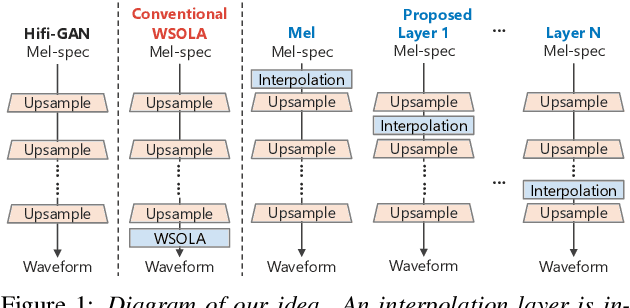

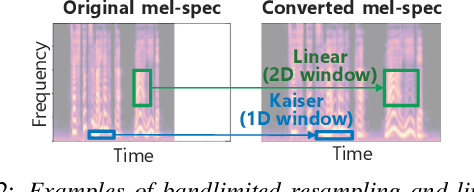
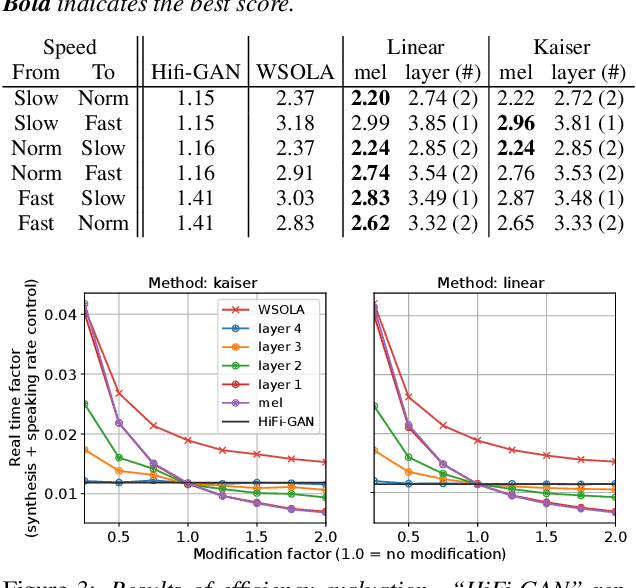
This paper presents a speaking-rate-controllable HiFi-GAN neural vocoder. Original HiFi-GAN is a high-fidelity, computationally efficient, and tiny-footprint neural vocoder. We attempt to incorporate a speaking rate control function into HiFi-GAN for improving the accessibility of synthetic speech. The proposed method inserts a differentiable interpolation layer into the HiFi-GAN architecture. A signal resampling method and an image scaling method are implemented in the proposed method to warp the mel-spectrograms or hidden features of the neural vocoder. We also design and open-source a Japanese speech corpus containing three kinds of speaking rates to evaluate the proposed speaking rate control method. Experimental results of comprehensive objective and subjective evaluations demonstrate that 1) the proposed method outperforms a baseline time-scale modification algorithm in speech naturalness, 2) warping mel-spectrograms by image scaling obtained the best performance among all proposed methods, and 3) the proposed speaking rate control method can be incorporated into HiFi-GAN without losing computational efficiency.
UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022
Apr 05, 2022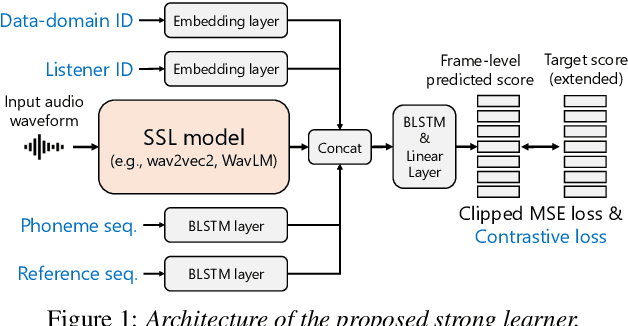
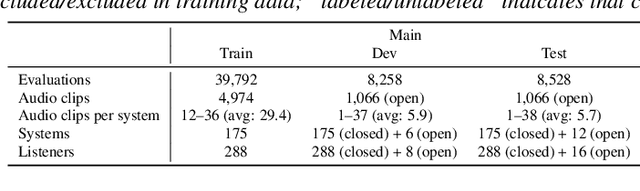
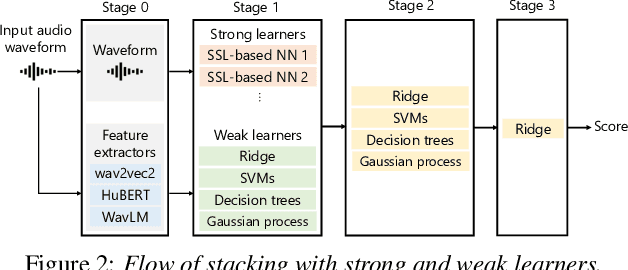
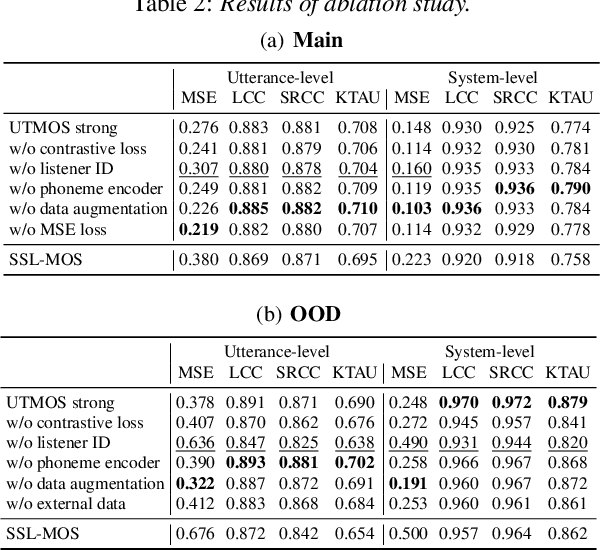
We present the UTokyo-SaruLab mean opinion score (MOS) prediction system submitted to VoiceMOS Challenge 2022. The challenge is to predict the MOS values of speech samples collected from previous Blizzard Challenges and Voice Conversion Challenges for two tracks: a main track for in-domain prediction and an out-of-domain (OOD) track for which there is less labeled data from different listening tests. Our system is based on ensemble learning of strong and weak learners. Strong learners incorporate several improvements to the previous fine-tuning models of self-supervised learning (SSL) models, while weak learners use basic machine-learning methods to predict scores from SSL features. In the Challenge, our system had the highest score on several metrics for both the main and OOD tracks. In addition, we conducted ablation studies to investigate the effectiveness of our proposed methods.
STUDIES: Corpus of Japanese Empathetic Dialogue Speech Towards Friendly Voice Agent
Mar 28, 2022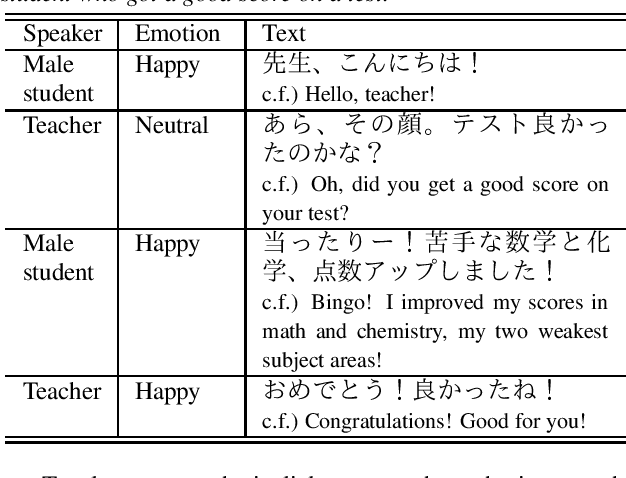
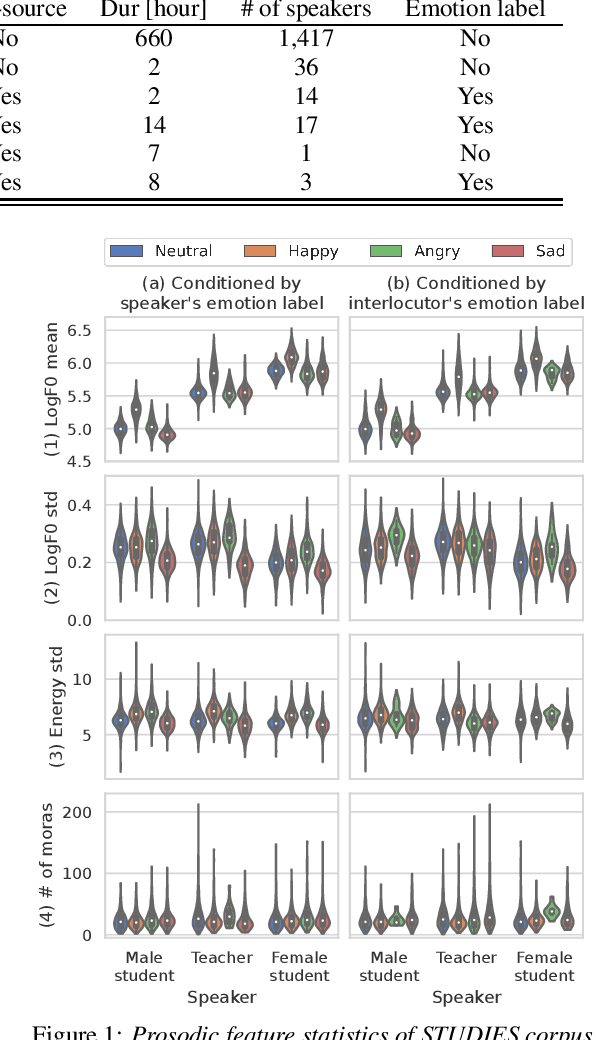
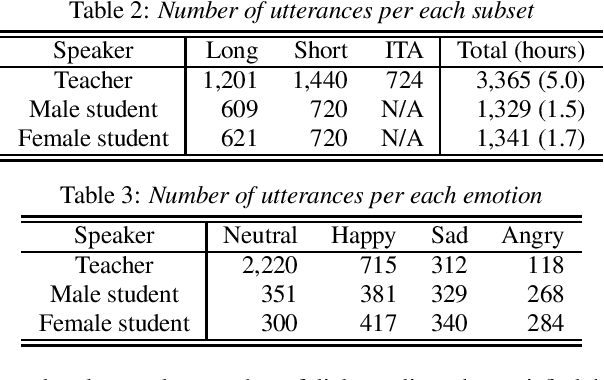
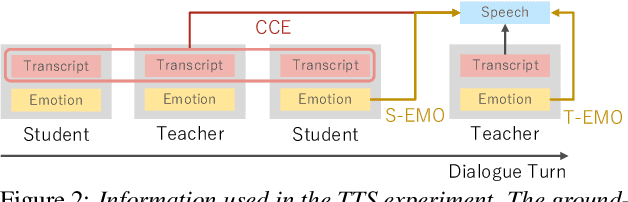
We present STUDIES, a new speech corpus for developing a voice agent that can speak in a friendly manner. Humans naturally control their speech prosody to empathize with each other. By incorporating this "empathetic dialogue" behavior into a spoken dialogue system, we can develop a voice agent that can respond to a user more naturally. We designed the STUDIES corpus to include a speaker who speaks with empathy for the interlocutor's emotion explicitly. We describe our methodology to construct an empathetic dialogue speech corpus and report the analysis results of the STUDIES corpus. We conducted a text-to-speech experiment to initially investigate how we can develop more natural voice agent that can tune its speaking style corresponding to the interlocutor's emotion. The results show that the use of interlocutor's emotion label and conversational context embedding can produce speech with the same degree of naturalness as that synthesized by using the agent's emotion label. Our project page of the STUDIES corpus is http://sython.org/Corpus/STUDIES.
SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesis Approach Using Channel Modeling
Mar 24, 2022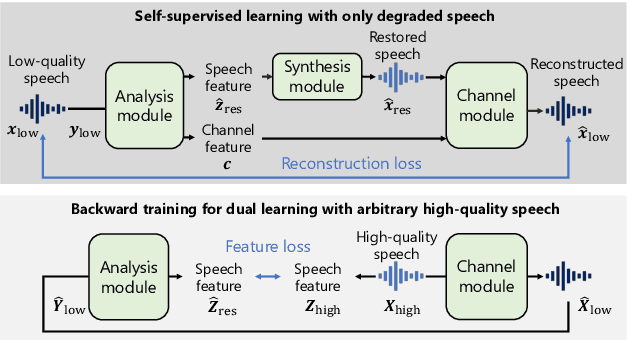
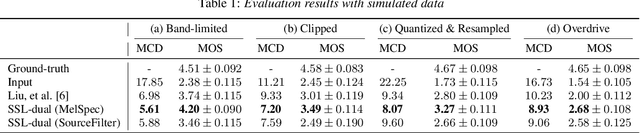
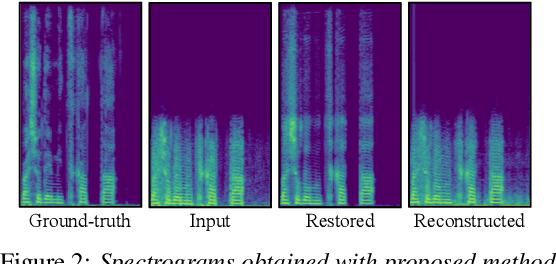
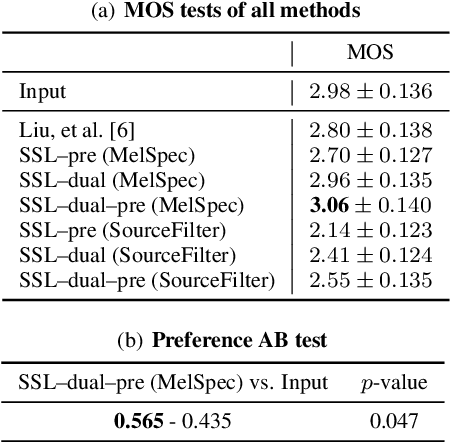
We present a self-supervised speech restoration method without paired speech corpora. Because the previous general speech restoration method uses artificial paired data created by applying various distortions to high-quality speech corpora, it cannot sufficiently represent acoustic distortions of real data, limiting the applicability. Our model consists of analysis, synthesis, and channel modules that simulate the recording process of degraded speech and is trained with real degraded speech data in a self-supervised manner. The analysis module extracts distortionless speech features and distortion features from degraded speech, while the synthesis module synthesizes the restored speech waveform, and the channel module adds distortions to the speech waveform. Our model also enables audio effect transfer, in which only acoustic distortions are extracted from degraded speech and added to arbitrary high-quality audio. Experimental evaluations with both simulated and real data show that our method achieves significantly higher-quality speech restoration than the previous supervised method, suggesting its applicability to real degraded speech materials.
Personalized filled-pause generation with group-wise prediction models
Mar 18, 2022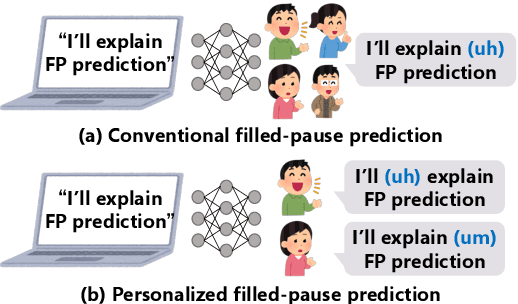
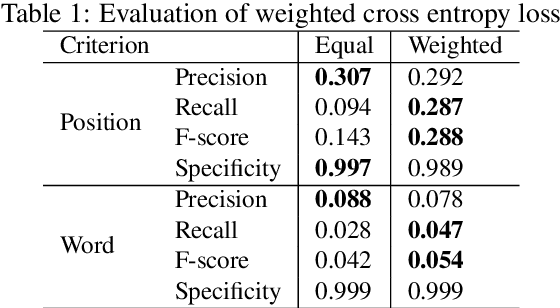
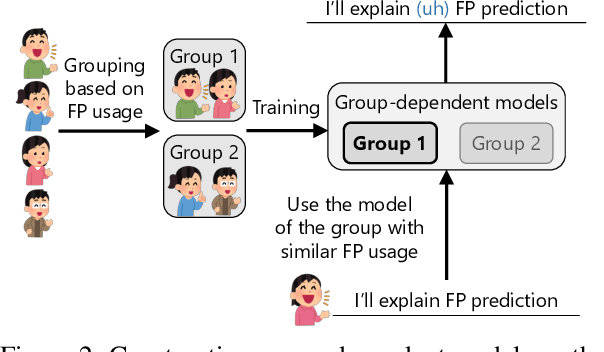
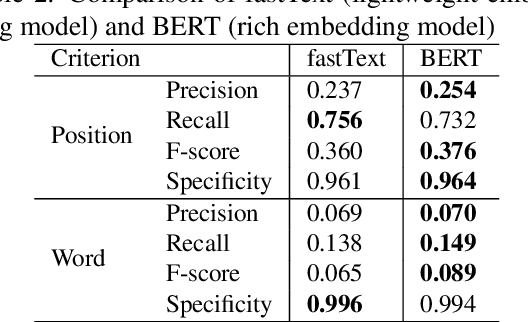
In this paper, we propose a method to generate personalized filled pauses (FPs) with group-wise prediction models. Compared with fluent text generation, disfluent text generation has not been widely explored. To generate more human-like texts, we addressed disfluent text generation. The usage of disfluency, such as FPs, rephrases, and word fragments, differs from speaker to speaker, and thus, the generation of personalized FPs is required. However, it is difficult to predict them because of the sparsity of position and the frequency difference between more and less frequently used FPs. Moreover, it is sometimes difficult to adapt FP prediction models to each speaker because of the large variation of the tendency within each speaker. To address these issues, we propose a method to build group-dependent prediction models by grouping speakers on the basis of their tendency to use FPs. This method does not require a large amount of data and time to train each speaker model. We further introduce a loss function and a word embedding model suitable for FP prediction. Our experimental results demonstrate that group-dependent models can predict FPs with higher scores than a non-personalized one and the introduced loss function and word embedding model improve the prediction performance.
Spatial active noise control based on individual kernel interpolation of primary and secondary sound fields
Feb 10, 2022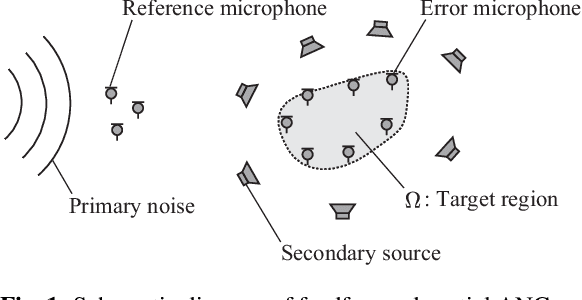
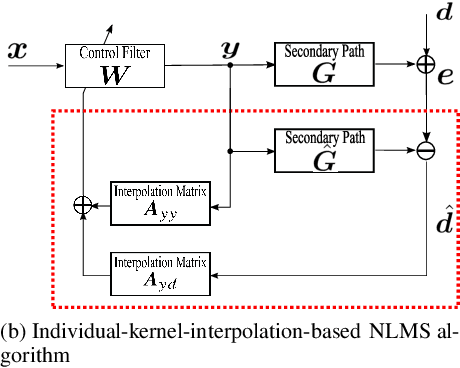
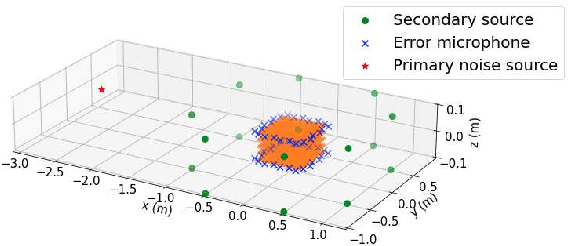
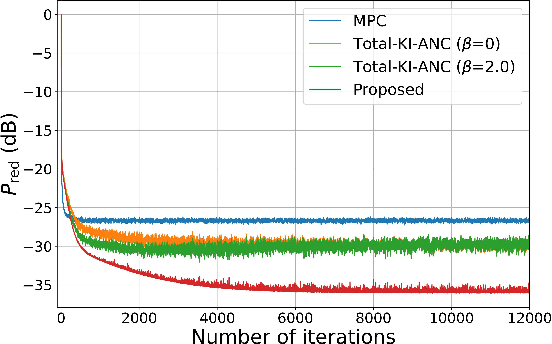
A spatial active noise control (ANC) method based on the individual kernel interpolation of primary and secondary sound fields is proposed. Spatial ANC is aimed at cancelling unwanted primary noise within a continuous region by using multiple secondary sources and microphones. A method based on the kernel interpolation of a sound field makes it possible to attenuate noise over the target region with flexible array geometry. Furthermore, by using the kernel function with directional weighting, prior information on primary noise source directions can be taken into consideration. However, whereas the sound field to be interpolated is a superposition of primary and secondary sound fields, the directional weight for the primary noise source was applied to the total sound field in previous work; therefore, the performance improvement was limited. We propose a method of individually interpolating the primary and secondary sound fields and formulate a normalized least-mean-square algorithm based on this interpolation method. Experimental results indicate that the proposed method outperforms the method based on total kernel interpolation.
Differentiable Digital Signal Processing Mixture Model for Synthesis Parameter Extraction from Mixture of Harmonic Sounds
Feb 01, 2022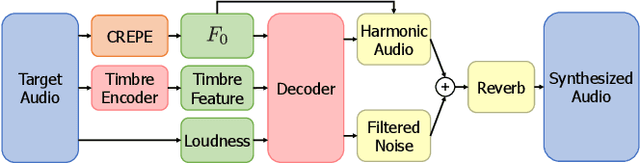
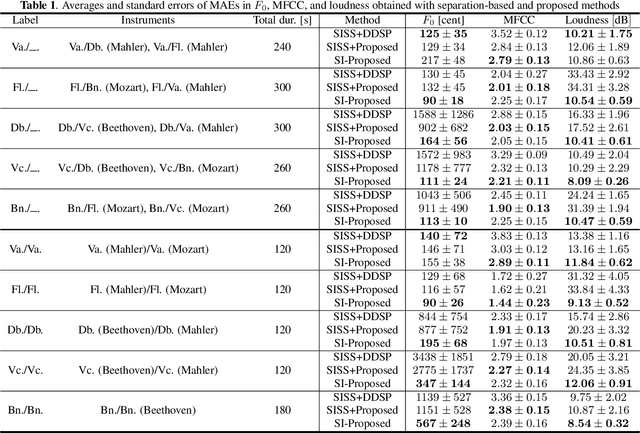
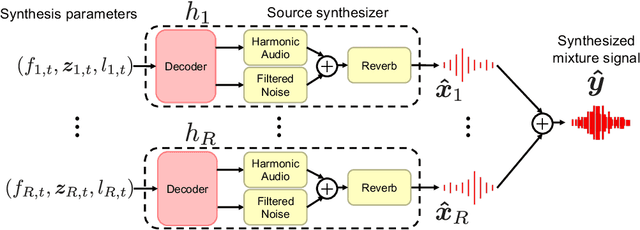
A differentiable digital signal processing (DDSP) autoencoder is a musical sound synthesizer that combines a deep neural network (DNN) and spectral modeling synthesis. It allows us to flexibly edit sounds by changing the fundamental frequency, timbre feature, and loudness (synthesis parameters) extracted from an input sound. However, it is designed for a monophonic harmonic sound and cannot handle mixtures of harmonic sounds. In this paper, we propose a model (DDSP mixture model) that represents a mixture as the sum of the outputs of multiple pretrained DDSP autoencoders. By fitting the output of the proposed model to the observed mixture, we can directly estimate the synthesis parameters of each source. Through synthesis parameter extraction experiments, we show that the proposed method has high and stable performance compared with a straightforward method that applies the DDSP autoencoder to the signals separated by an audio source separation method.
J-MAC: Japanese multi-speaker audiobook corpus for speech synthesis
Jan 26, 2022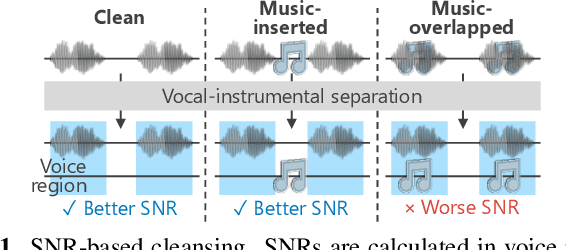

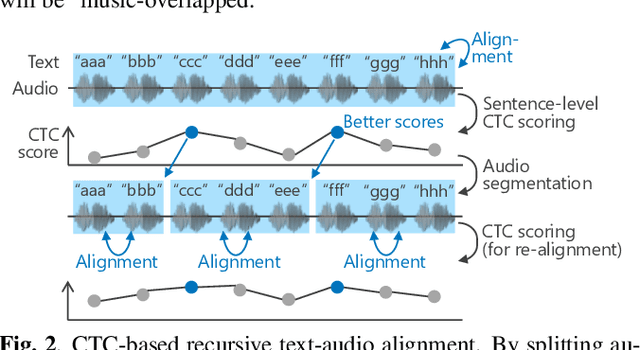
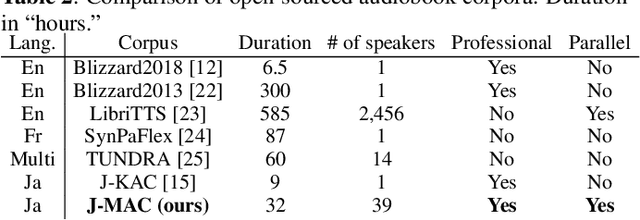
In this paper, we construct a Japanese audiobook speech corpus called "J-MAC" for speech synthesis research. With the success of reading-style speech synthesis, the research target is shifting to tasks that use complicated contexts. Audiobook speech synthesis is a good example that requires cross-sentence, expressiveness, etc. Unlike reading-style speech, speaker-specific expressiveness in audiobook speech also becomes the context. To enhance this research, we propose a method of constructing a corpus from audiobooks read by professional speakers. From many audiobooks and their texts, our method can automatically extract and refine the data without any language dependency. Specifically, we use vocal-instrumental separation to extract clean data, connectionist temporal classification to roughly align text and audio, and voice activity detection to refine the alignment. J-MAC is open-sourced in our project page. We also conduct audiobook speech synthesis evaluations, and the results give insights into audiobook speech synthesis.