 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREADME: Bridging Medical Jargon and Lay Understanding for Patient Education through Data-Centric NLP
Dec 24, 2023The advancement in healthcare has shifted focus toward patient-centric approaches, particularly in self-care and patient education, facilitated by access to Electronic Health Records (EHR). However, medical jargon in EHRs poses significant challenges in patient comprehension. To address this, we introduce a new task of automatically generating lay definitions, aiming to simplify complex medical terms into patient-friendly lay language. We first created the README dataset, an extensive collection of over 20,000 unique medical terms and 300,000 mentions, each offering context-aware lay definitions manually annotated by domain experts. We have also engineered a data-centric Human-AI pipeline that synergizes data filtering, augmentation, and selection to improve data quality. We then used README as the training data for models and leveraged a Retrieval-Augmented Generation (RAG) method to reduce hallucinations and improve the quality of model outputs. Our extensive automatic and human evaluations demonstrate that open-source mobile-friendly models, when fine-tuned with high-quality data, are capable of matching or even surpassing the performance of state-of-the-art closed-source large language models like ChatGPT. This research represents a significant stride in closing the knowledge gap in patient education and advancing patient-centric healthcare solutions
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Nov 06, 2023



To enhance the performance of large language models (LLMs) in biomedical natural language processing (BioNLP) by introducing a domain-specific instruction dataset and examining its impact when combined with multi-task learning principles. We created the BioInstruct, comprising 25,005 instructions to instruction-tune LLMs(LLaMA 1 & 2, 7B & 13B version). The instructions were created by prompting the GPT-4 language model with three-seed samples randomly drawn from an 80 human curated instructions. We employed Low-Rank Adaptation(LoRA) for parameter-efficient fine-tuning. We then evaluated these instruction-tuned LLMs on several BioNLP tasks, which can be grouped into three major categories: question answering(QA), information extraction(IE), and text generation(GEN). We also examined whether categories(e.g., QA, IE, and generation) of instructions impact model performance. Comparing with LLMs without instruction-tuned, our instruction-tuned LLMs demonstrated marked performance gains: 17.3% in QA, 5.7% in IE, and 96% in Generation tasks. Our 7B-parameter instruction-tuned LLaMA 1 model was competitive or even surpassed other LLMs in the biomedical domain that were also fine-tuned from LLaMA 1 with vast domain-specific data or a variety of tasks. Our results also show that the performance gain is significantly higher when instruction fine-tuning is conducted with closely related tasks. Our findings align with the observations of multi-task learning, suggesting the synergies between two tasks. The BioInstruct dataset serves as a valuable resource and instruction tuned LLMs lead to the best performing BioNLP applications.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023



As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
MTet: Multi-domain Translation for English and Vietnamese
Oct 19, 2022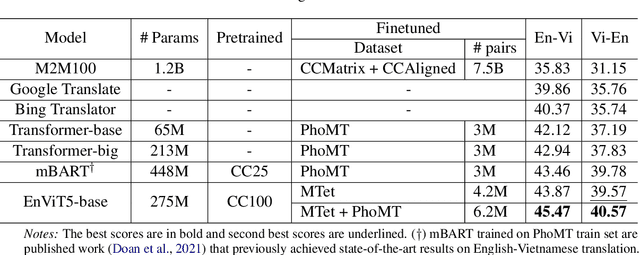
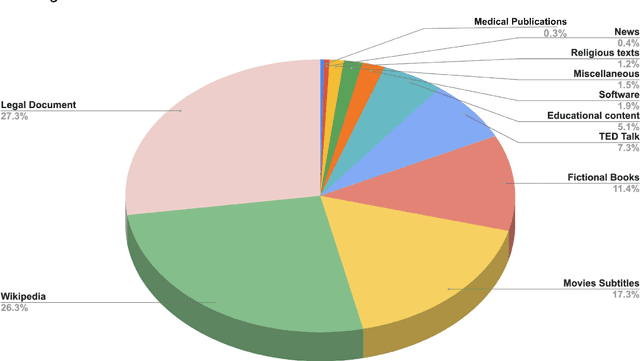

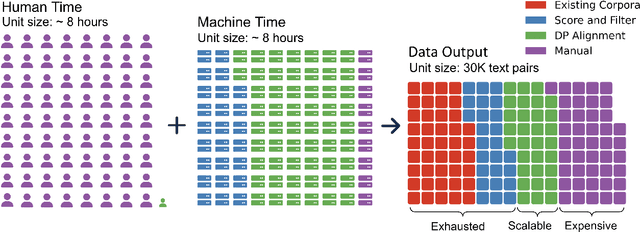
We introduce MTet, the largest publicly available parallel corpus for English-Vietnamese translation. MTet consists of 4.2M high-quality training sentence pairs and a multi-domain test set refined by the Vietnamese research community. Combining with previous works on English-Vietnamese translation, we grow the existing parallel dataset to 6.2M sentence pairs. We also release the first pretrained model EnViT5 for English and Vietnamese languages. Combining both resources, our model significantly outperforms previous state-of-the-art results by up to 2 points in translation BLEU score, while being 1.6 times smaller.
Enriching Biomedical Knowledge for Low-resource Language Through Translation
Oct 11, 2022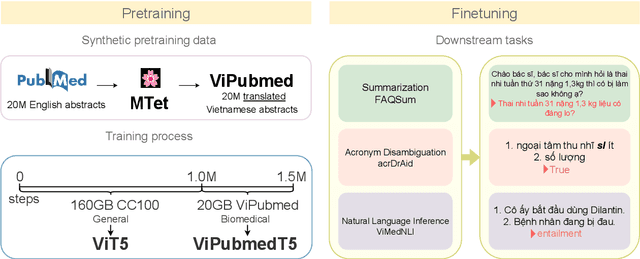
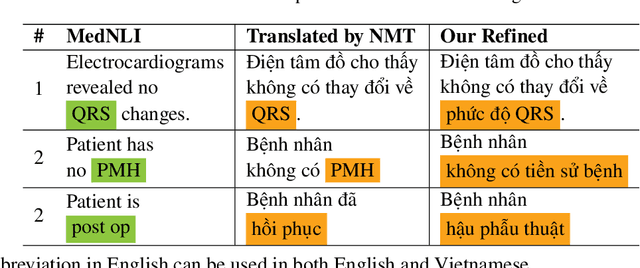

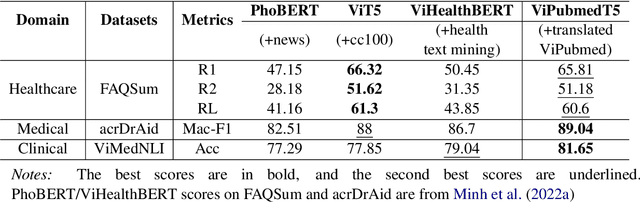
Biomedical data and benchmarks are highly valuable yet very limited in low-resource languages other than English such as Vietnamese. In this paper, we make use of a state-of-the-art translation model in English-Vietnamese to translate and produce both pretrained as well as supervised data in the biomedical domains. Thanks to such large-scale translation, we introduce ViPubmedT5, a pretrained Encoder-Decoder Transformer model trained on 20 million translated abstracts from the high-quality public PubMed corpus. ViPubMedT5 demonstrates state-of-the-art results on two different biomedical benchmarks in summarization and acronym disambiguation. Further, we release ViMedNLI - a new NLP task in Vietnamese translated from MedNLI using the recently public En-vi translation model and carefully refined by human experts, with evaluations of existing methods against ViPubmedT5.
TLETA: Deep Transfer Learning and Integrated Cellular Knowledge for Estimated Time of Arrival Prediction
Jun 17, 2022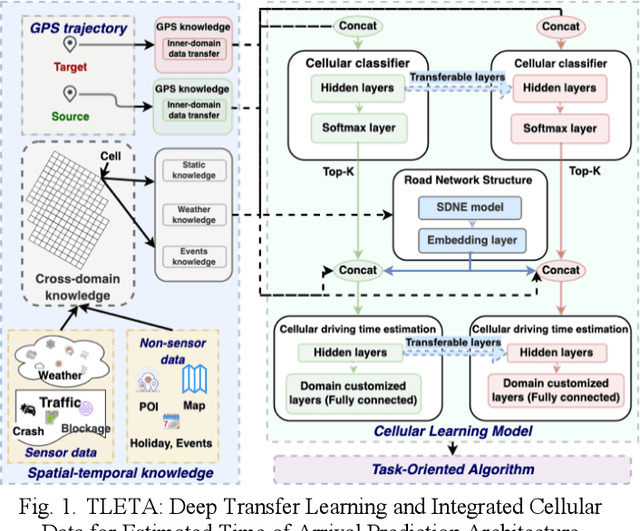
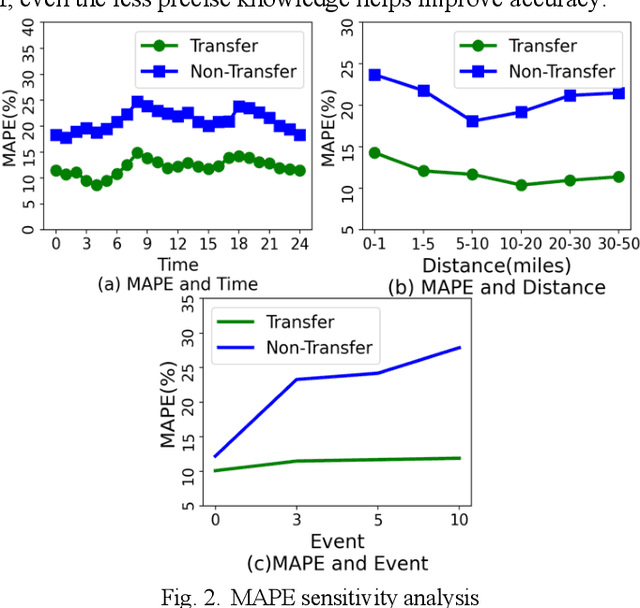
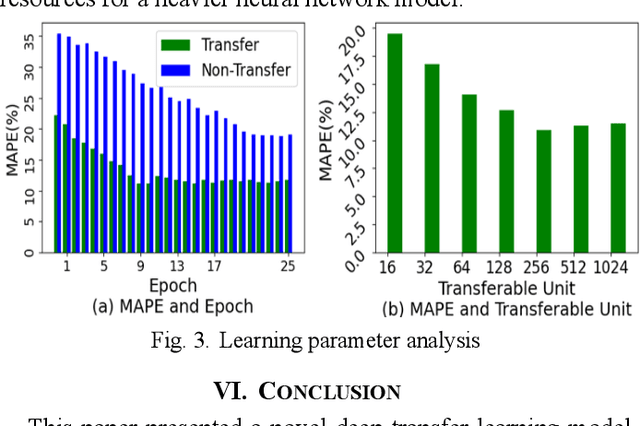
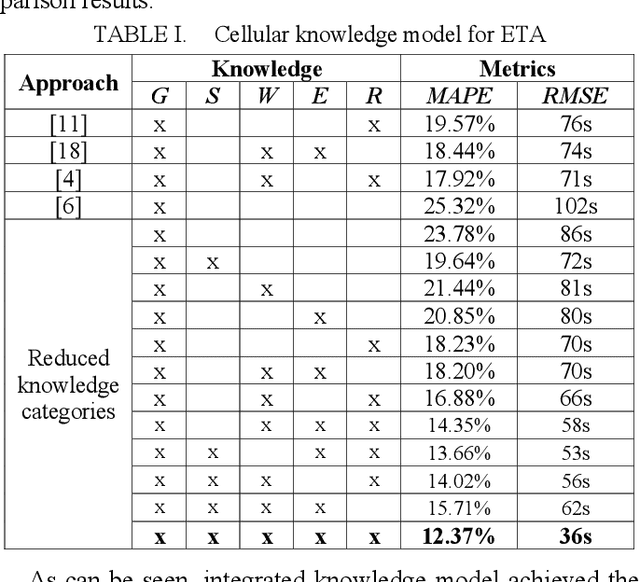
Vehicle arrival time prediction has been studied widely. With the emergence of IoT devices and deep learning techniques, estimated time of arrival (ETA) has become a critical component in intelligent transportation systems. Though many tools exist for ETA, ETA for special vehicles, such as ambulances, fire engines, etc., is still challenging due to the limited amount of traffic data for special vehicles. Existing works use one model for all types of vehicles, which can lead to low accuracy. To tackle this, as the first in the field, we propose a deep transfer learning framework TLETA for the driving time prediction. TLETA constructs cellular spatial-temporal knowledge grids for extracting driving patterns, combined with the road network structure embedding to build a deep neural network for ETA. TLETA contains transferable layers to support knowledge transfer between different categories of vehicles. Importantly, our transfer models only train the last layers to map the transferred knowledge, that reduces the training time significantly. The experimental studies show that our model predicts travel time with high accuracy and outperforms many state-of-the-art approaches.
ViT5: Pretrained Text-to-Text Transformer for Vietnamese Language Generation
May 13, 2022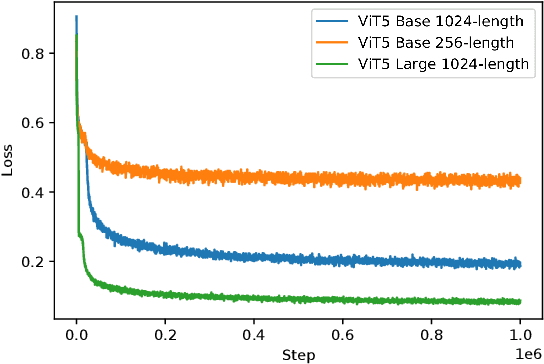

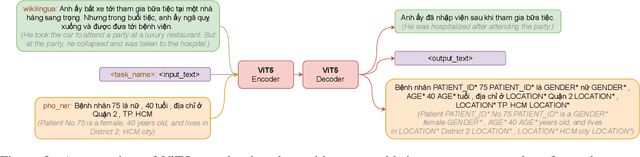
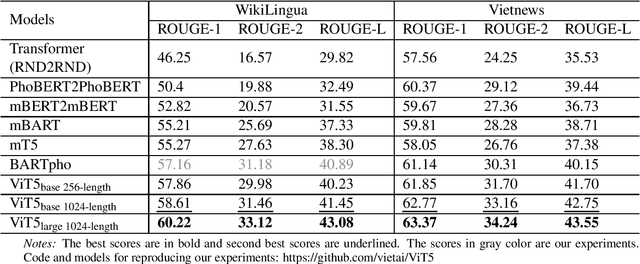
We present ViT5, a pretrained Transformer-based encoder-decoder model for the Vietnamese language. With T5-style self-supervised pretraining, ViT5 is trained on a large corpus of high-quality and diverse Vietnamese texts. We benchmark ViT5 on two downstream text generation tasks, Abstractive Text Summarization and Named Entity Recognition. Although Abstractive Text Summarization has been widely studied for the English language thanks to its rich and large source of data, there has been minimal research into the same task in Vietnamese, a much lower resource language. In this work, we perform exhaustive experiments on both Vietnamese Abstractive Summarization and Named Entity Recognition, validating the performance of ViT5 against many other pretrained Transformer-based encoder-decoder models. Our experiments show that ViT5 significantly outperforms existing models and achieves state-of-the-art results on Vietnamese Text Summarization. On the task of Named Entity Recognition, ViT5 is competitive against previous best results from pretrained encoder-based Transformer models. Further analysis shows the importance of context length during the self-supervised pretraining on downstream performance across different settings.
IoT Data Discovery: Routing Table and Summarization Techniques
Mar 21, 2022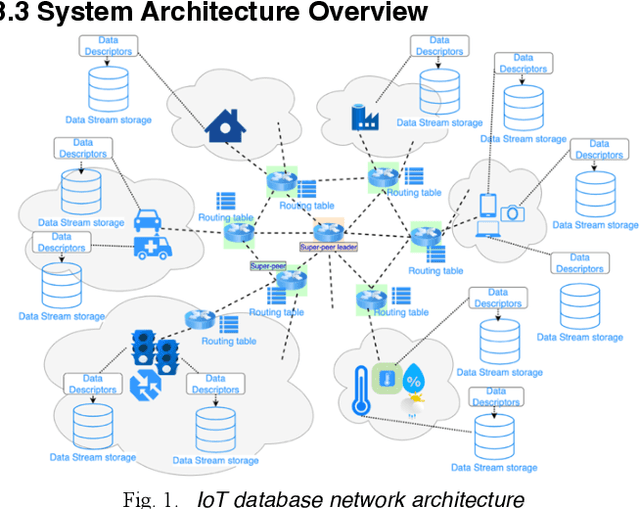
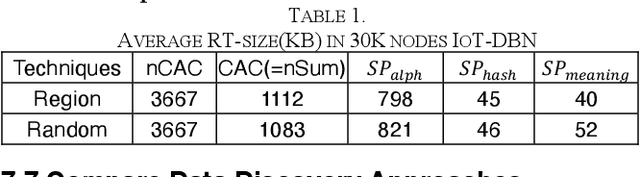
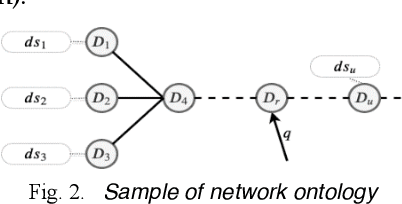
In this paper, we consider the IoT data discovery problem in very large and growing scale networks. Through analysis, examples, and experimental studies, we show the importance of peer-to-peer, unstructured routing for IoT data discovery and point out the space efficiency issue that has been overlooked in keyword-based routing algorithms in unstructured networks. Specifically, as the first in the field, this paper investigates routing table designs and various compression techniques to support effective and space-efficient IoT data discovery routing. Novel summarization algorithms, including alphabetical, hash, and meaning-based summarization and their corresponding coding schemes, are proposed. We also consider routing table design to support summarization without degrading lookup efficiency for discovery query routing. The issue of potentially misleading routing due to summarization is also investigated. Subsequently, we analyze the strategy of when to summarize to balance the tradeoff between the routing table compression rate and the chance of causing misleading routing. For the experimental study, we have collected 100K IoT data streams from various IoT databases as the input dataset. Experimental results show that our summarization solution can reduce the routing table size by 20 to 30 folds with a 2-5% increase in latency compared with similar peer-to-peer discovery routing algorithms without summarization. Also, our approach outperforms DHT-based approaches by 2 to 6 folds in terms of latency and traffic.
Transfer Reinforcement Learning for Differing Action Spaces via Q-Network Representations
Feb 15, 2022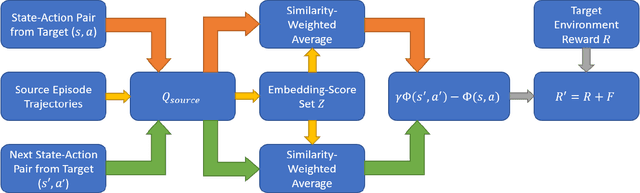

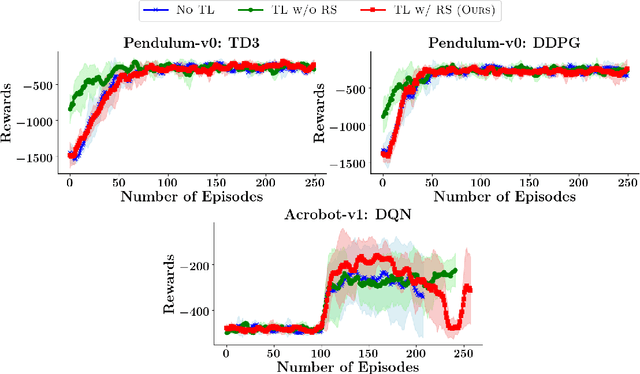
Transfer learning approaches in reinforcement learning aim to assist agents in learning their target domains by leveraging the knowledge learned from other agents that have been trained on similar source domains. For example, recent research focus within this space has been placed on knowledge transfer between tasks that have different transition dynamics and reward functions; however, little focus has been placed on knowledge transfer between tasks that have different action spaces. In this paper, we approach the task of transfer learning between domains that differ in action spaces. We present a reward shaping method based on source embedding similarity that is applicable to domains with both discrete and continuous action spaces. The efficacy of our approach is evaluated on transfer to restricted action spaces in the Acrobot-v1 and Pendulum-v0 domains. A comparison with two baselines shows that our method does not outperform these baselines in these continuous action spaces but does show an improvement in these discrete action spaces. We conclude our analysis with future directions for this work.