 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity 4D Hand-Object Capture via Multi-View Spatiotemporal Tracking and Physics-Aware Gaussians
Jun 18, 2026The growing demand for high-fidelity 4D hand-object interaction (HOI) data in embodied AI and spatial computing is currently bottlenecked by the reliance on pre-scanned object templates and physical markers. While recent methods have demonstrated promising results in reconstructing 4D hand-object interaction from videos, they are highly sensitive to initial estimates of hand and object poses. Yet, estimating these poses from images is challenging, in particular under severe occlusion which is inherent in hand-object interaction scenarios. We propose a novel system for the robust and accurate reconstruction of hands and objects from synchronized and calibrated multi-view videos without requiring any templates or markers. Our system consists of two main components with key innovations: (1) a multi-view feed-forward transformer model that aggregates cross-view geometry and temporal cues to provide a reliable, metric-consistent initialization for both poses and dense object geometry, and (2) a hand-object physics-aware Gaussian-based optimization framework to refine the initial estimates, integrating tetrahedral constraints, collision refinement, and appearance decomposition to produce physically plausible and visually accurate reconstruction. Validated on public benchmarks and an extensive internal dataset, our pipeline achieves highly robust, artifact-free reconstruction, providing an efficient foundation for automated 4D asset generation. Our project page are available at https://zyshen021.github.io/HOSTPG/.
DynaTok: Token-Based 4D Reconstruction from Partial Point Clouds
Jun 10, 2026We address 4D reconstruction from partial point cloud sequences, where depth-sensor observations are incomplete, unordered, and lack explicit temporal correspondences. This geometry-only setting is challenging due to missing observations and ambiguous dynamics. While recent progress has largely relied on image-based methods, existing point-based approaches typically focus on single objects, assume relatively complete inputs, or require explicit correspondences. To address these limitations, we propose DynaTok, a point-based framework for correspondence-free 4D reconstruction from partial point cloud sequences without images. DynaTok encodes frames into compact latent tokens, aggregates incomplete observations over time with a Transformer-based spatiotemporal encoder, and decouples geometry and motion through residual tokens in a unified model. A flow-matching decoder then reconstructs complete, temporally consistent 4D point-cloud sequences conditioned on the latent tokens. Experiments on object- and scene-level benchmarks demonstrate improved reconstruction quality and temporal coherence from partial point cloud observations. Project page: https://wrchen530.github.io/dynatok/.
Unified Semantic Transformer for 3D Scene Understanding
Dec 18, 2025



Holistic 3D scene understanding involves capturing and parsing unstructured 3D environments. Due to the inherent complexity of the real world, existing models have predominantly been developed and limited to be task-specific. We introduce UNITE, a Unified Semantic Transformer for 3D scene understanding, a novel feed-forward neural network that unifies a diverse set of 3D semantic tasks within a single model. Our model operates on unseen scenes in a fully end-to-end manner and only takes a few seconds to infer the full 3D semantic geometry. Our approach is capable of directly predicting multiple semantic attributes, including 3D scene segmentation, instance embeddings, open-vocabulary features, as well as affordance and articulations, solely from RGB images. The method is trained using a combination of 2D distillation, heavily relying on self-supervision and leverages novel multi-view losses designed to ensure 3D view consistency. We demonstrate that UNITE achieves state-of-the-art performance on several different semantic tasks and even outperforms task-specific models, in many cases, surpassing methods that operate on ground truth 3D geometry. See the project website at unite-page.github.io
4DTAM: Non-Rigid Tracking and Mapping via Dynamic Surface Gaussians
May 28, 2025We propose the first 4D tracking and mapping method that jointly performs camera localization and non-rigid surface reconstruction via differentiable rendering. Our approach captures 4D scenes from an online stream of color images with depth measurements or predictions by jointly optimizing scene geometry, appearance, dynamics, and camera ego-motion. Although natural environments exhibit complex non-rigid motions, 4D-SLAM remains relatively underexplored due to its inherent challenges; even with 2.5D signals, the problem is ill-posed because of the high dimensionality of the optimization space. To overcome these challenges, we first introduce a SLAM method based on Gaussian surface primitives that leverages depth signals more effectively than 3D Gaussians, thereby achieving accurate surface reconstruction. To further model non-rigid deformations, we employ a warp-field represented by a multi-layer perceptron (MLP) and introduce a novel camera pose estimation technique along with surface regularization terms that facilitate spatio-temporal reconstruction. In addition to these algorithmic challenges, a significant hurdle in 4D SLAM research is the lack of reliable ground truth and evaluation protocols, primarily due to the difficulty of 4D capture using commodity sensors. To address this, we present a novel open synthetic dataset of everyday objects with diverse motions, leveraging large-scale object models and animation modeling. In summary, we open up the modern 4D-SLAM research by introducing a novel method and evaluation protocols grounded in modern vision and rendering techniques.
Gaussian Splatting SLAM
Dec 11, 2023



We present the first application of 3D Gaussian Splatting to incremental 3D reconstruction using a single moving monocular or RGB-D camera. Our Simultaneous Localisation and Mapping (SLAM) method, which runs live at 3fps, utilises Gaussians as the only 3D representation, unifying the required representation for accurate, efficient tracking, mapping, and high-quality rendering. Several innovations are required to continuously reconstruct 3D scenes with high fidelity from a live camera. First, to move beyond the original 3DGS algorithm, which requires accurate poses from an offline Structure from Motion (SfM) system, we formulate camera tracking for 3DGS using direct optimisation against the 3D Gaussians, and show that this enables fast and robust tracking with a wide basin of convergence. Second, by utilising the explicit nature of the Gaussians, we introduce geometric verification and regularisation to handle the ambiguities occurring in incremental 3D dense reconstruction. Finally, we introduce a full SLAM system which not only achieves state-of-the-art results in novel view synthesis and trajectory estimation, but also reconstruction of tiny and even transparent objects.
NEWTON: Neural View-Centric Mapping for On-the-Fly Large-Scale SLAM
Mar 29, 2023



Neural field-based 3D representations have recently been adopted in many areas including SLAM systems. Current neural SLAM or online mapping systems lead to impressive results in the presence of simple captures, but they rely on a world-centric map representation as only a single neural field model is used. To define such a world-centric representation, accurate and static prior information about the scene, such as its boundaries and initial camera poses, are required. However, in real-time and on-the-fly scene capture applications, this prior knowledge cannot be assumed as fixed or static, since it dynamically changes and it is subject to significant updates based on run-time observations. Particularly in the context of large-scale mapping, significant camera pose drift is inevitable, necessitating the correction via loop closure. To overcome this limitation, we propose NEWTON, a view-centric mapping method that dynamically constructs neural fields based on run-time observation. In contrast to prior works, our method enables camera pose updates using loop closures and scene boundary updates by representing the scene with multiple neural fields, where each is defined in a local coordinate system of a selected keyframe. The experimental results demonstrate the superior performance of our method over existing world-centric neural field-based SLAM systems, in particular for large-scale scenes subject to camera pose updates.
CodeMapping: Real-Time Dense Mapping for Sparse SLAM using Compact Scene Representations
Jul 19, 2021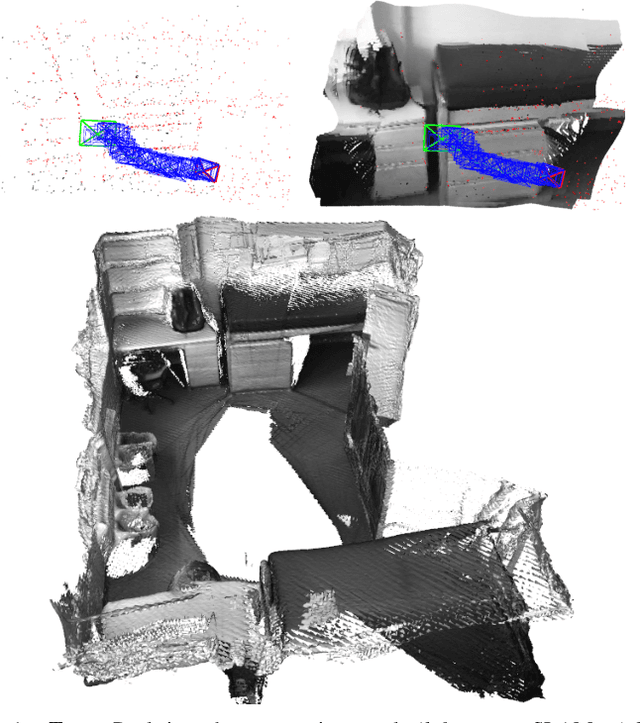

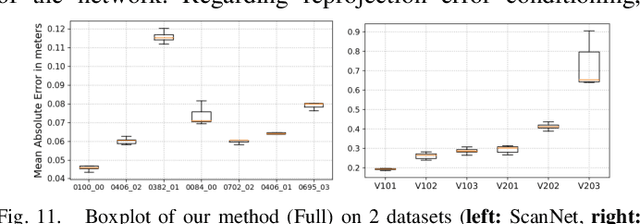

We propose a novel dense mapping framework for sparse visual SLAM systems which leverages a compact scene representation. State-of-the-art sparse visual SLAM systems provide accurate and reliable estimates of the camera trajectory and locations of landmarks. While these sparse maps are useful for localization, they cannot be used for other tasks such as obstacle avoidance or scene understanding. In this paper we propose a dense mapping framework to complement sparse visual SLAM systems which takes as input the camera poses, keyframes and sparse points produced by the SLAM system and predicts a dense depth image for every keyframe. We build on CodeSLAM and use a variational autoencoder (VAE) which is conditioned on intensity, sparse depth and reprojection error images from sparse SLAM to predict an uncertainty-aware dense depth map. The use of a VAE then enables us to refine the dense depth images through multi-view optimization which improves the consistency of overlapping frames. Our mapper runs in a separate thread in parallel to the SLAM system in a loosely coupled manner. This flexible design allows for integration with arbitrary metric sparse SLAM systems without delaying the main SLAM process. Our dense mapper can be used not only for local mapping but also globally consistent dense 3D reconstruction through TSDF fusion. We demonstrate our system running with ORB-SLAM3 and show accurate dense depth estimation which could enable applications such as robotics and augmented reality.
Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras
Aug 08, 2018
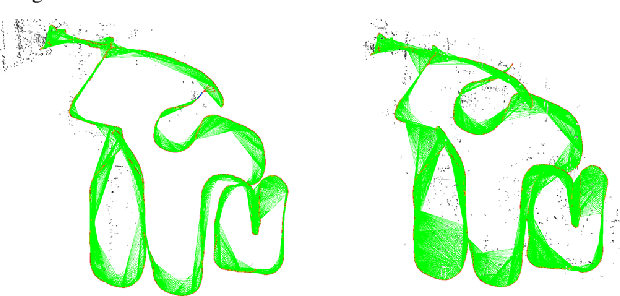
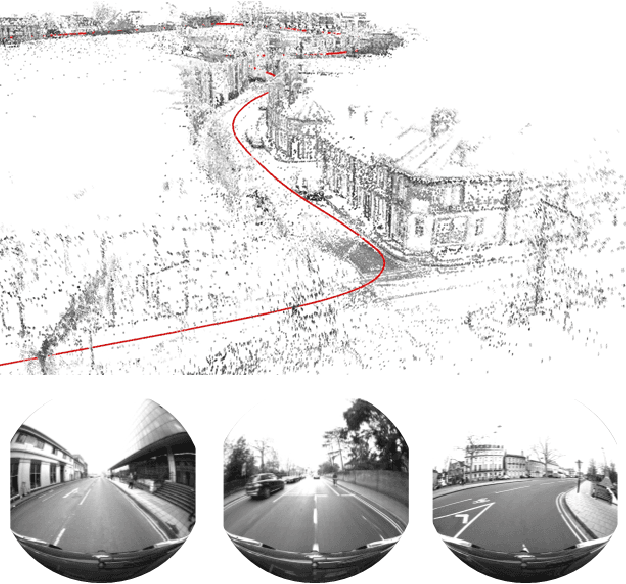
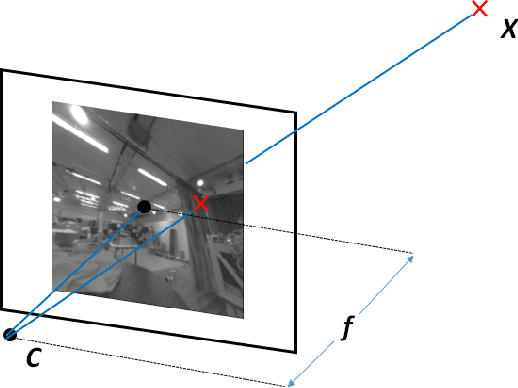
We propose a novel real-time direct monocular visual odometry for omnidirectional cameras. Our method extends direct sparse odometry (DSO) by using the unified omnidirectional model as a projection function, which can be applied to fisheye cameras with a field-of-view (FoV) well above 180 degrees. This formulation allows for using the full area of the input image even with strong distortion, while most existing visual odometry methods can only use a rectified and cropped part of it. Model parameters within an active keyframe window are jointly optimized, including the intrinsic/extrinsic camera parameters, 3D position of points, and affine brightness parameters. Thanks to the wide FoV, image overlap between frames becomes bigger and points are more spatially distributed. Our results demonstrate that our method provides increased accuracy and robustness over state-of-the-art visual odometry algorithms.