 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hierarchical Graph-Based Segmentation of RGBD Videos
Jan 26, 2018
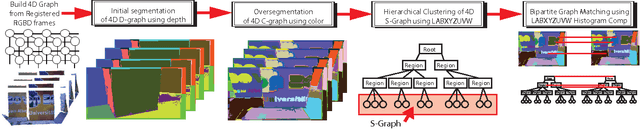

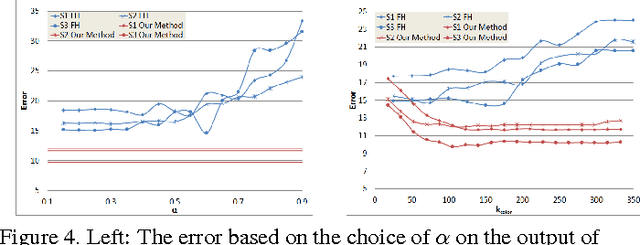
We present an efficient and scalable algorithm for segmenting 3D RGBD point clouds by combining depth, color, and temporal information using a multistage, hierarchical graph-based approach. Our algorithm processes a moving window over several point clouds to group similar regions over a graph, resulting in an initial over-segmentation. These regions are then merged to yield a dendrogram using agglomerative clustering via a minimum spanning tree algorithm. Bipartite graph matching at a given level of the hierarchical tree yields the final segmentation of the point clouds by maintaining region identities over arbitrarily long periods of time. We show that a multistage segmentation with depth then color yields better results than a linear combination of depth and color. Due to its incremental processing, our algorithm can process videos of any length and in a streaming pipeline. The algorithm's ability to produce robust, efficient segmentation is demonstrated with numerous experimental results on challenging sequences from our own as well as public RGBD data sets.
Semantic Instance Labeling Leveraging Hierarchical Segmentation
Aug 02, 2017
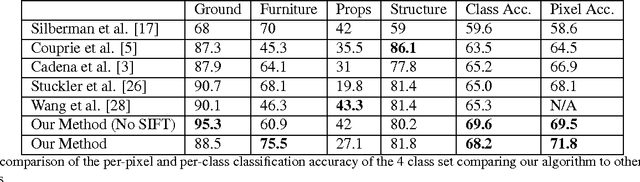
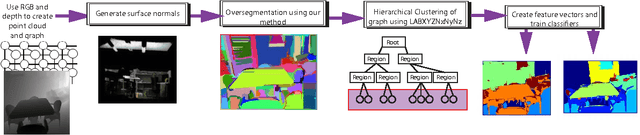
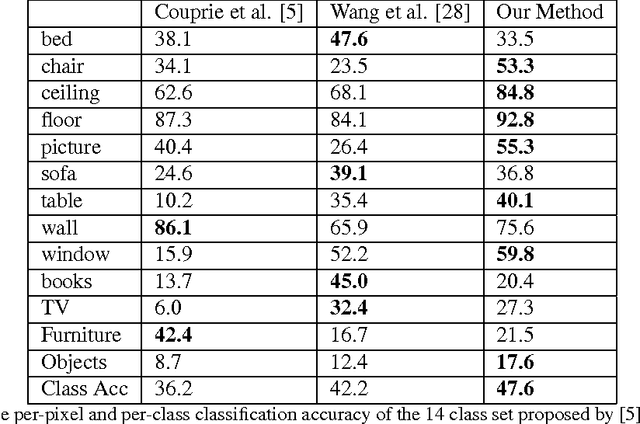
Most of the approaches for indoor RGBD semantic la- beling focus on using pixels or superpixels to train a classi- fier. In this paper, we implement a higher level segmentation using a hierarchy of superpixels to obtain a better segmen- tation for training our classifier. By focusing on meaningful segments that conform more directly to objects, regardless of size, we train a random forest of decision trees as a clas- sifier using simple features such as the 3D size, LAB color histogram, width, height, and shape as specified by a his- togram of surface normals. We test our method on the NYU V2 depth dataset, a challenging dataset of cluttered indoor environments. Our experiments using the NYU V2 depth dataset show that our method achieves state of the art re- sults on both a general semantic labeling introduced by the dataset (floor, structure, furniture, and objects) and a more object specific semantic labeling. We show that training a classifier on a segmentation from a hierarchy of super pixels yields better results than training directly on super pixels, patches, or pixels as in previous work.
Grasping for a Purpose: Using Task Goals for Efficient Manipulation Planning
Mar 14, 2016
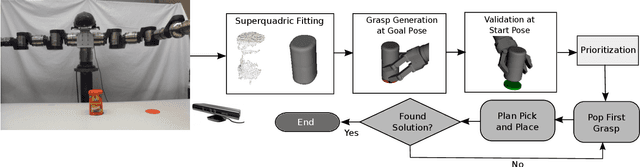
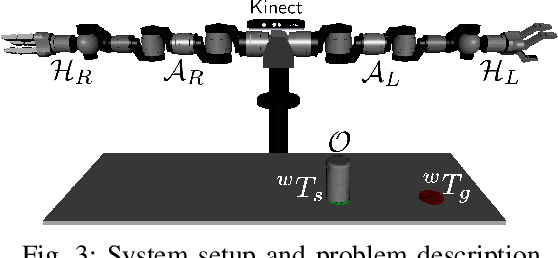
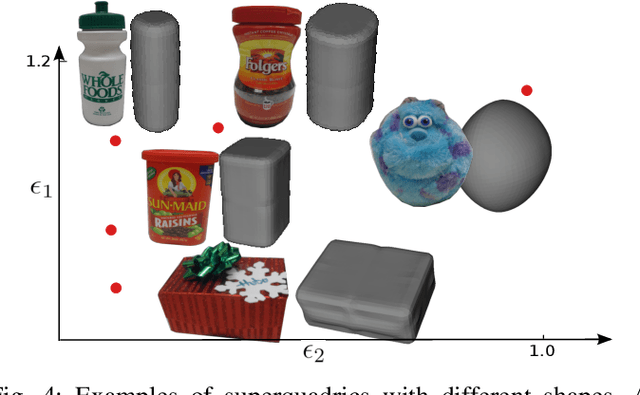
In this paper we propose an approach for efficient grasp selection for manipulation tasks of unknown objects. Even for simple tasks such as pick-and-place, a unique solution is rare to occur. Rather, multiple candidate grasps must be considered and (potentially) tested till a successful, kinematically feasible path is found. To make this process efficient, the grasps should be ordered such that those more likely to succeed are tested first. We propose to use grasp manipulability as a metric to prioritize grasps. We present results of simulation experiments which demonstrate the usefulness of our metric. Additionally, we present experiments with our physical robot performing simple manipulation tasks with a small set of different household objects.
Multi-modal Tracking for Object based SLAM
Mar 14, 2016
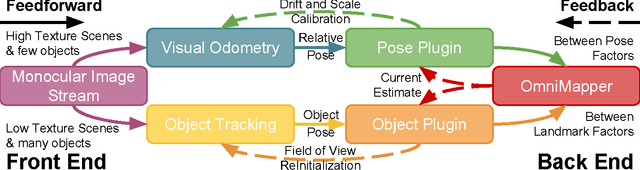
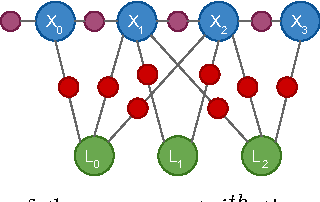
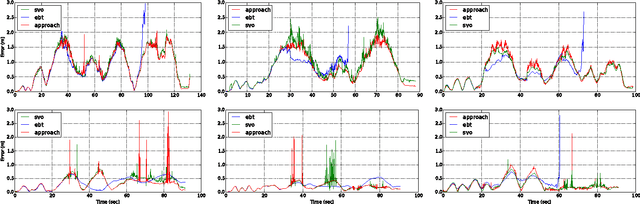
We present an on-line 3D visual object tracking framework for monocular cameras by incorporating spatial knowledge and uncertainty from semantic mapping along with high frequency measurements from visual odometry. Using a combination of vision and odometry that are tightly integrated we can increase the overall performance of object based tracking for semantic mapping. We present a framework for integration of the two data-sources into a coherent framework through information based fusion/arbitration. We demonstrate the framework in the context of OmniMapper[1] and present results on 6 challenging sequences over multiple objects compared to data obtained from a motion capture systems. We are able to achieve a mean error of 0.23m for per frame tracking showing 9% relative error less than state of the art tracker.
Predicting Daily Activities From Egocentric Images Using Deep Learning
Oct 06, 2015
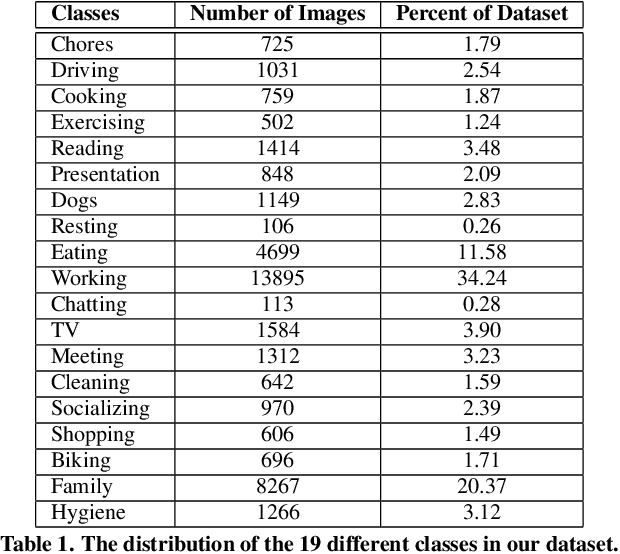

We present a method to analyze images taken from a passive egocentric wearable camera along with the contextual information, such as time and day of week, to learn and predict everyday activities of an individual. We collected a dataset of 40,103 egocentric images over a 6 month period with 19 activity classes and demonstrate the benefit of state-of-the-art deep learning techniques for learning and predicting daily activities. Classification is conducted using a Convolutional Neural Network (CNN) with a classification method we introduce called a late fusion ensemble. This late fusion ensemble incorporates relevant contextual information and increases our classification accuracy. Our technique achieves an overall accuracy of 83.07% in predicting a person's activity across the 19 activity classes. We also demonstrate some promising results from two additional users by fine-tuning the classifier with one day of training data.
* 8 pages
Occlusion-Aware Object Localization, Segmentation and Pose Estimation
Jul 27, 2015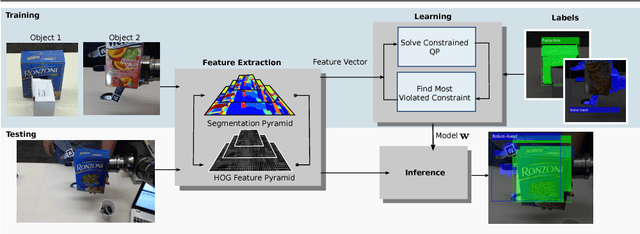
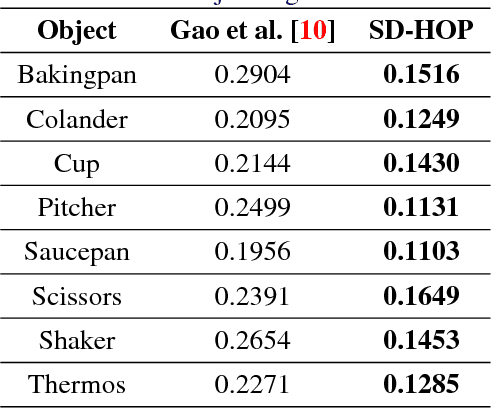
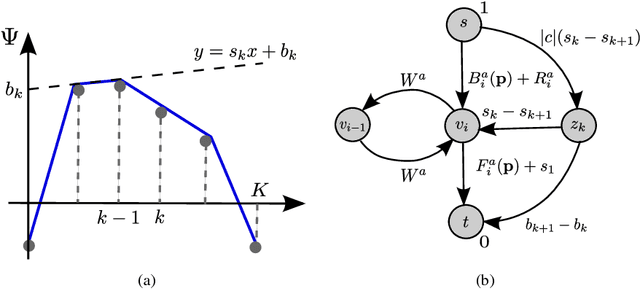
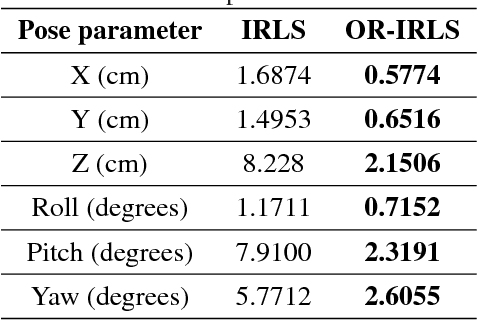
We present a learning approach for localization and segmentation of objects in an image in a manner that is robust to partial occlusion. Our algorithm produces a bounding box around the full extent of the object and labels pixels in the interior that belong to the object. Like existing segmentation aware detection approaches, we learn an appearance model of the object and consider regions that do not fit this model as potential occlusions. However, in addition to the established use of pairwise potentials for encouraging local consistency, we use higher order potentials which capture information at the level of im- age segments. We also propose an efficient loss function that targets both localization and segmentation performance. Our algorithm achieves 13.52% segmentation error and 0.81 area under the false-positive per image vs. recall curve on average over the challenging CMU Kitchen Occlusion Dataset. This is a 42.44% decrease in segmentation error and a 16.13% increase in localization performance compared to the state-of-the-art. Finally, we show that the visibility labelling produced by our algorithm can make full 3D pose estimation from a single image robust to occlusion.