 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Convolutional Neural Networks in the Frequency Domain
Apr 28, 2022
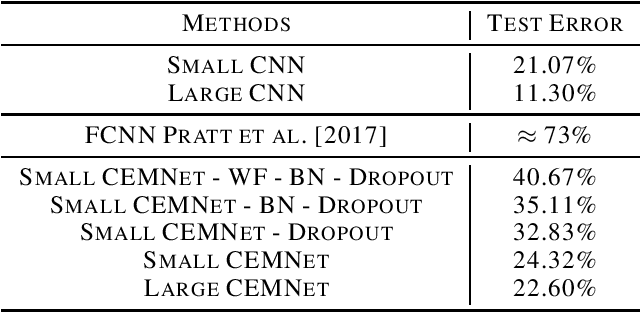
Convolutional neural network (CNN) has achieved impressive success in computer vision during the past few decades. The image convolution operation helps CNNs to get good performance on image-related tasks. However, the image convolution has high computation complexity and hard to be implemented. This paper proposes the CEMNet, which can be trained in the frequency domain. The most important motivation of this research is that we can use the straightforward element-wise multiplication operation to replace the image convolution in the frequency domain based on the Cross-Correlation Theorem, which obviously reduces the computation complexity. We further introduce a Weight Fixation mechanism to alleviate the problem of over-fitting, and analyze the working behavior of Batch Normalization, Leaky ReLU, and Dropout in the frequency domain to design their counterparts for CEMNet. Also, to deal with complex inputs brought by Discrete Fourier Transform, we design a two-branches network structure for CEMNet. Experimental results imply that CEMNet achieves good performance on MNIST and CIFAR-10 databases.
UENAS: A Unified Evolution-based NAS Framework
Mar 08, 2022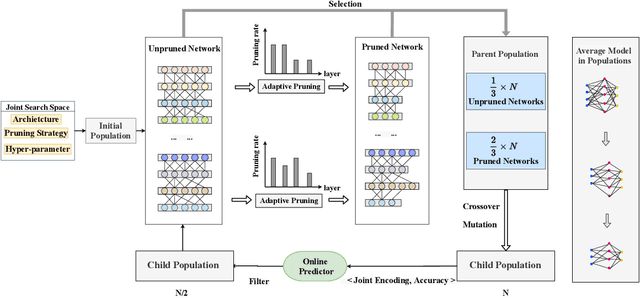
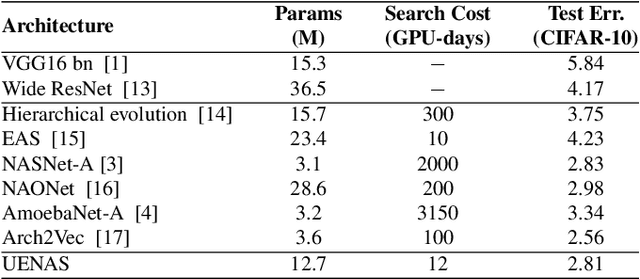
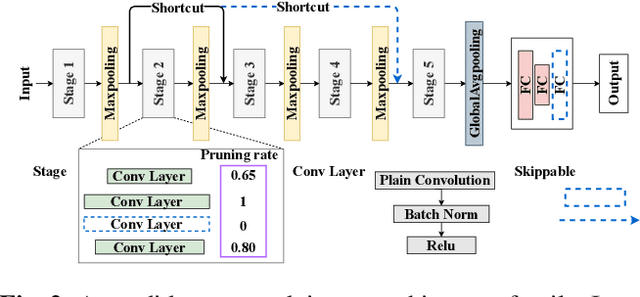
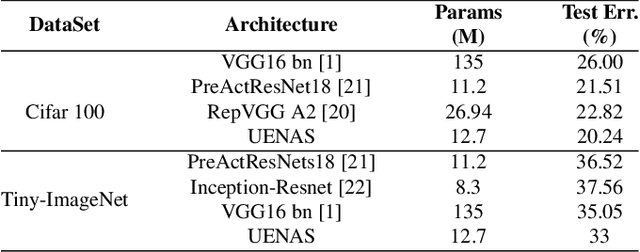
Neural architecture search (NAS) has gained significant attention for automatic network design in recent years. Previous NAS methods suffer from limited search spaces, which may lead to sub-optimal results. In this paper, we propose UENAS, an evolution-based NAS framework with a broader search space that supports optimizing network architectures, pruning strategies, and hyperparameters simultaneously. To alleviate the huge search cost caused by the expanded search space, three strategies are adopted: First, an adaptive pruning strategy that iteratively trims the average model size in the population without compromising performance. Second, child networks share weights of overlapping layers with pre-trained parent networks to reduce the training epochs. Third, an online predictor scores the joint representations of architecture, pruning strategy, and hyperparameters to filter out inferior combos. By the proposed three strategies, the search efficiency is significantly improved and more well-performed compact networks with tailored hyper-parameters are derived. In experiments, UENAS achieves error rates of 2.81% on CIFAR-10, 20.24% on CIFAR-100, and 33% on Tiny-ImageNet, which shows the effectiveness of our method.
Inertial Proximal Deep Learning Alternating Minimization for Efficient Neutral Network Training
Jan 30, 2021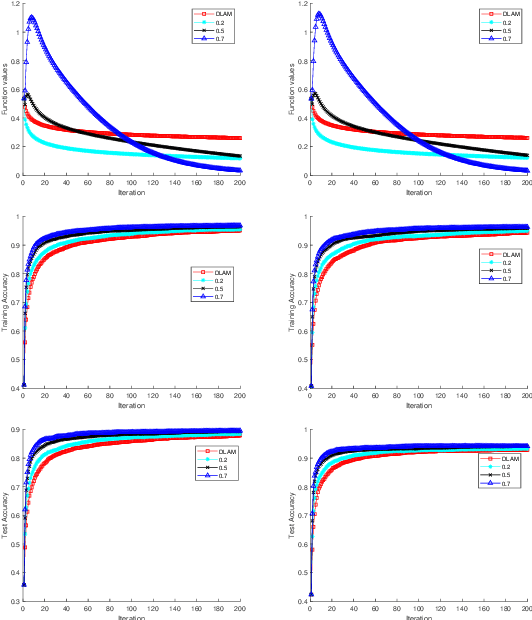
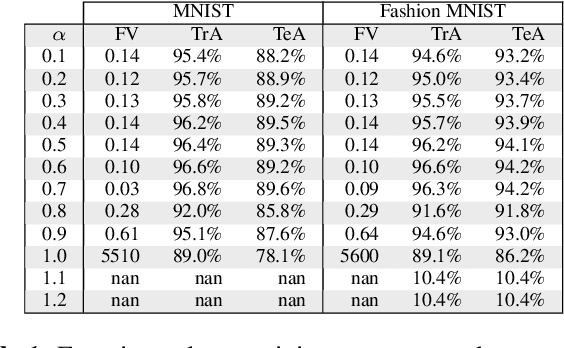
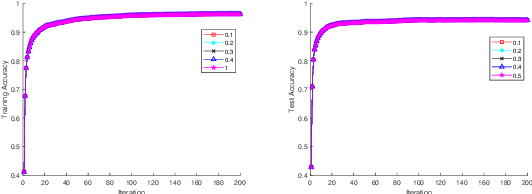
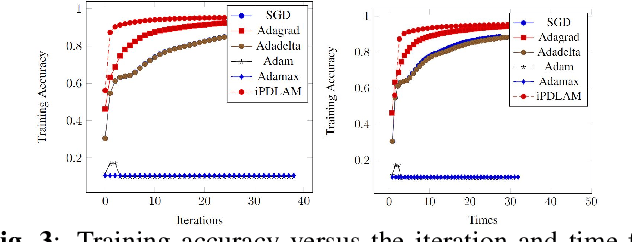
In recent years, the Deep Learning Alternating Minimization (DLAM), which is actually the alternating minimization applied to the penalty form of the deep neutral networks training, has been developed as an alternative algorithm to overcome several drawbacks of Stochastic Gradient Descent (SGD) algorithms. This work develops an improved DLAM by the well-known inertial technique, namely iPDLAM, which predicts a point by linearization of current and last iterates. To obtain further training speed, we apply a warm-up technique to the penalty parameter, that is, starting with a small initial one and increasing it in the iterations. Numerical results on real-world datasets are reported to demonstrate the efficiency of our proposed algorithm.
Fixed-size Objects Encoding for Visual Relationship Detection
May 29, 2020
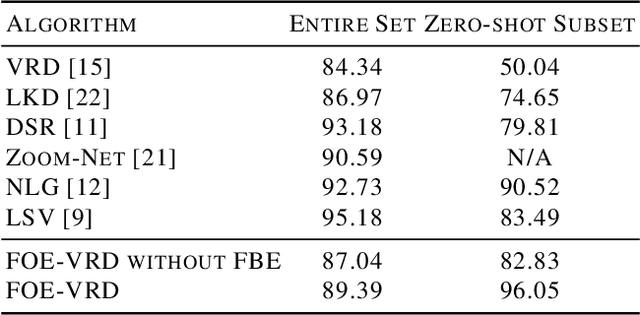
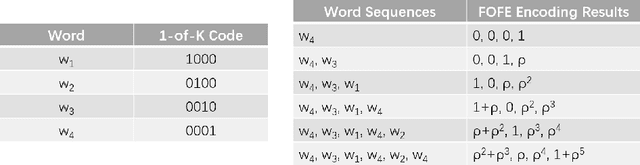
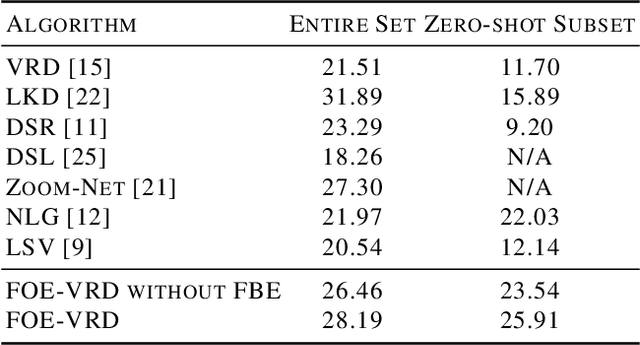
In this paper, we propose a fixed-size object encoding method (FOE-VRD) to improve performance of visual relationship detection tasks. Comparing with previous methods, FOE-VRD has an important feature, i.e., it uses one fixed-size vector to encoding all objects in each input image to assist the process of relationship detection. Firstly, we use a regular convolution neural network as a feature extractor to generate high-level features of input images. Then, for each relationship triplet in input images, i.e., $<$subject-predicate-object$>$, we apply ROI-pooling to get feature vectors of two regions on the feature maps that corresponding to bounding boxes of the subject and object. Besides the subject and object, our analysis implies that the results of predicate classification may also related to the rest objects in input images (we call them background objects). Due to the variable number of background objects in different images and computational costs, we cannot generate feature vectors for them one-by-one by using ROI pooling technique. Instead, we propose a novel method to encode all background objects in each image by using one fixed-size vector (i.e., FBE vector). By concatenating the 3 vectors we generate above, we successfully encode the objects using one fixed-size vector. The generated feature vector is then feed into a fully connected neural network to get predicate classification results. Experimental results on VRD database (entire set and zero-shot tests) show that the proposed method works well on both predicate classification and relationship detection.
DropFilter: A Novel Regularization Method for Learning Convolutional Neural Networks
Nov 19, 2018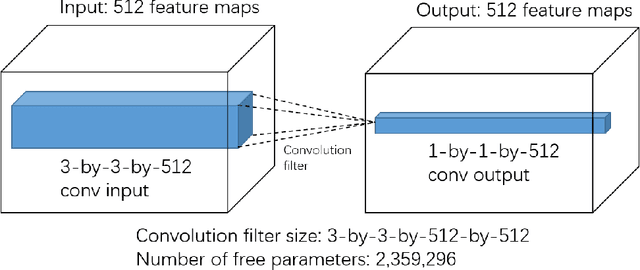
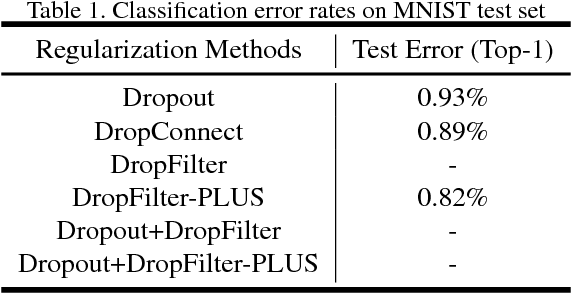
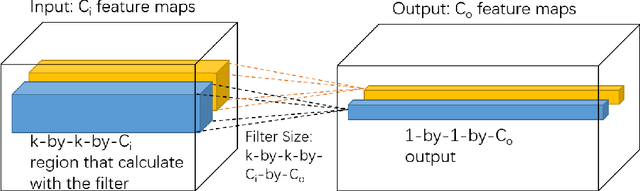
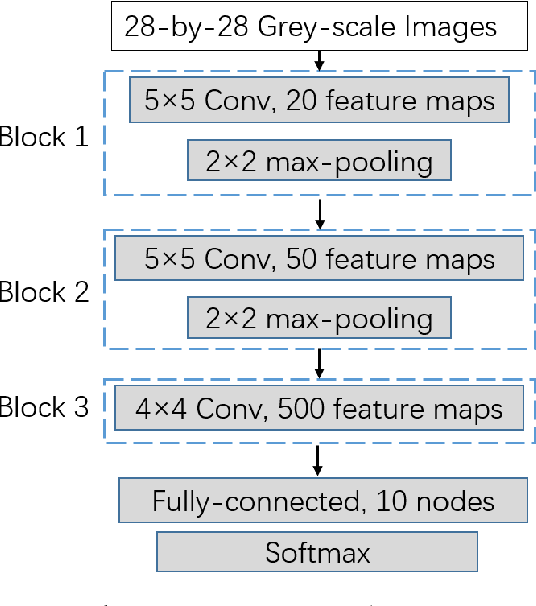
The past few years have witnessed the fast development of different regularization methods for deep learning models such as fully-connected deep neural networks (DNNs) and Convolutional Neural Networks (CNNs). Most of previous methods mainly consider to drop features from input data and hidden layers, such as Dropout, Cutout and DropBlocks. DropConnect select to drop connections between fully-connected layers. By randomly discard some features or connections, the above mentioned methods control the overfitting problem and improve the performance of neural networks. In this paper, we proposed two novel regularization methods, namely DropFilter and DropFilter-PLUS, for the learning of CNNs. Different from the previous methods, DropFilter and DropFilter-PLUS selects to modify the convolution filters. For DropFilter-PLUS, we find a suitable way to accelerate the learning process based on theoretical analysis. Experimental results on MNIST show that using DropFilter and DropFilter-PLUS may improve performance on image classification tasks.
Supervised Adversarial Networks for Image Saliency Detection
Apr 26, 2017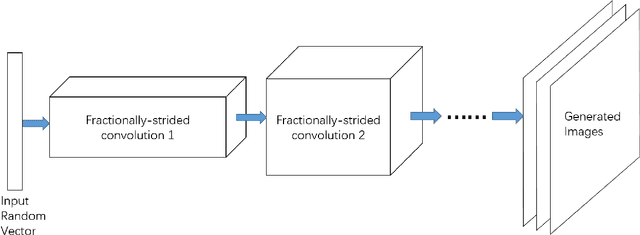

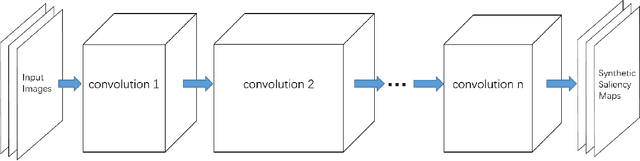
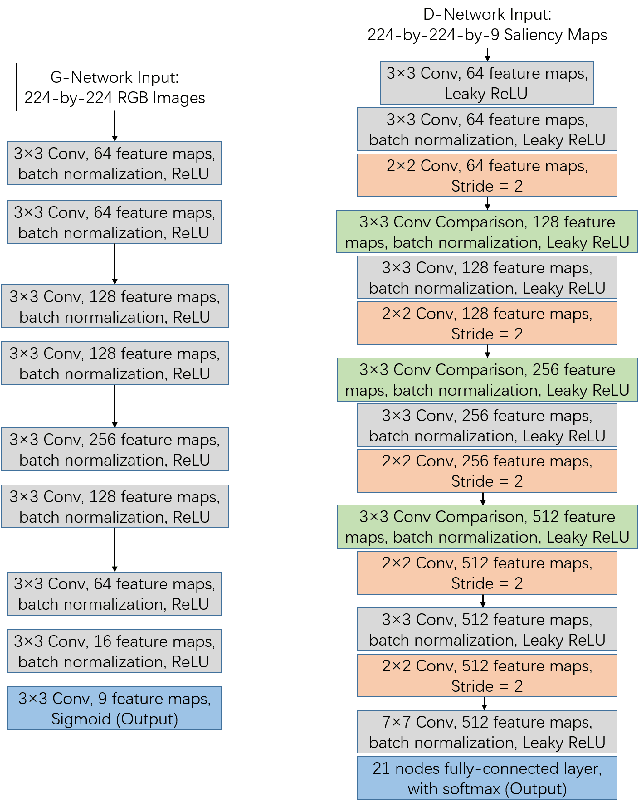
In the past few years, Generative Adversarial Network (GAN) became a prevalent research topic. By defining two convolutional neural networks (G-Network and D-Network) and introducing an adversarial procedure between them during the training process, GAN has ability to generate good quality images that look like natural images from a random vector. Besides image generation, GAN may have potential to deal with wide range of real world problems. In this paper, we follow the basic idea of GAN and propose a novel model for image saliency detection, which is called Supervised Adversarial Networks (SAN). Specifically, SAN also trains two models simultaneously: the G-Network takes natural images as inputs and generates corresponding saliency maps (synthetic saliency maps), and the D-Network is trained to determine whether one sample is a synthetic saliency map or ground-truth saliency map. However, different from GAN, the proposed method uses fully supervised learning to learn both G-Network and D-Network by applying class labels of the training set. Moreover, a novel kind of layer call conv-comparison layer is introduced into the D-Network to further improve the saliency performance by forcing the high-level feature of synthetic saliency maps and ground-truthes as similar as possible. Experimental results on Pascal VOC 2012 database show that the SAN model can generate high quality saliency maps for many complicate natural images.
Learning Convolutional Neural Networks using Hybrid Orthogonal Projection and Estimation
Sep 11, 2016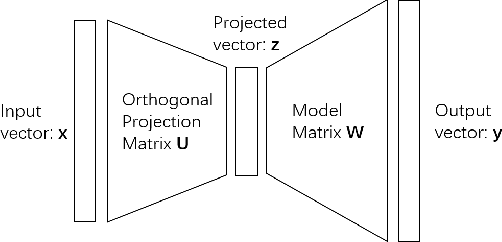

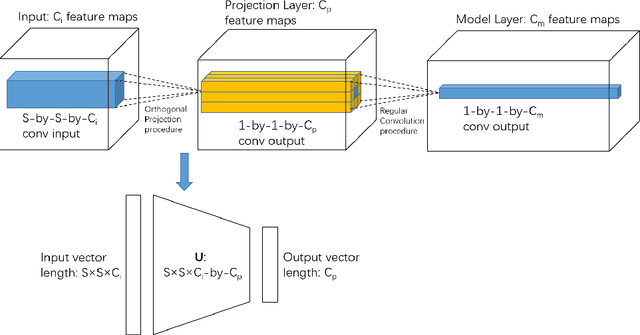
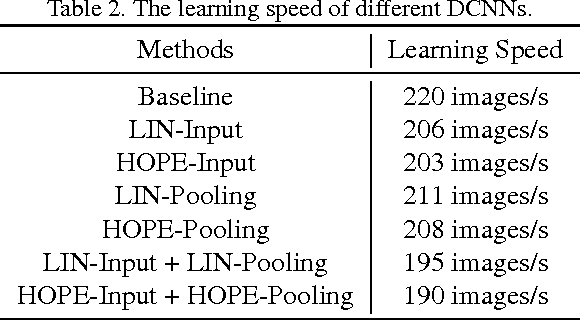
Convolutional neural networks (CNNs) have yielded the excellent performance in a variety of computer vision tasks, where CNNs typically adopt a similar structure consisting of convolution layers, pooling layers and fully connected layers. In this paper, we propose to apply a novel method, namely Hybrid Orthogonal Projection and Estimation (HOPE), to CNNs in order to introduce orthogonality into the CNN structure. The HOPE model can be viewed as a hybrid model to combine feature extraction using orthogonal linear projection with mixture models. It is an effective model to extract useful information from the original high-dimension feature vectors and meanwhile filter out irrelevant noises. In this work, we present three different ways to apply the HOPE models to CNNs, i.e., {\em HOPE-Input}, {\em single-HOPE-Block} and {\em multi-HOPE-Blocks}. For {\em HOPE-Input} CNNs, a HOPE layer is directly used right after the input to de-correlate high-dimension input feature vectors. Alternatively, in {\em single-HOPE-Block} and {\em multi-HOPE-Blocks} CNNs, we consider to use HOPE layers to replace one or more blocks in the CNNs, where one block may include several convolutional layers and one pooling layer. The experimental results on both Cifar-10 and Cifar-100 data sets have shown that the orthogonal constraints imposed by the HOPE layers can significantly improve the performance of CNNs in these image classification tasks (we have achieved one of the best performance when image augmentation has not been applied, and top 5 performance with image augmentation).
A Deep Learning Based Fast Image Saliency Detection Algorithm
Feb 01, 2016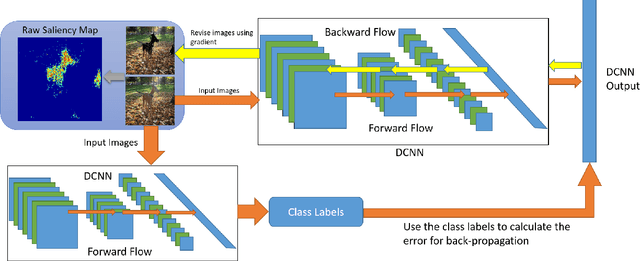

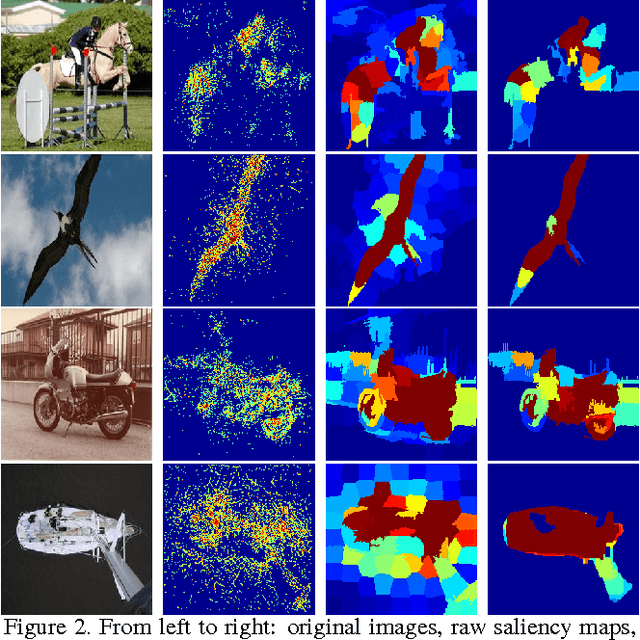

In this paper, we propose a fast deep learning method for object saliency detection using convolutional neural networks. In our approach, we use a gradient descent method to iteratively modify the input images based on the pixel-wise gradients to reduce a pre-defined cost function, which is defined to measure the class-specific objectness and clamp the class-irrelevant outputs to maintain image background. The pixel-wise gradients can be efficiently computed using the back-propagation algorithm. We further apply SLIC superpixels and LAB color based low level saliency features to smooth and refine the gradients. Our methods are quite computationally efficient, much faster than other deep learning based saliency methods. Experimental results on two benchmark tasks, namely Pascal VOC 2012 and MSRA10k, have shown that our proposed methods can generate high-quality salience maps, at least comparable with many slow and complicated deep learning methods. Comparing with the pure low-level methods, our approach excels in handling many difficult images, which contain complex background, highly-variable salient objects, multiple objects, and/or very small salient objects.
Deep Learning for Object Saliency Detection and Image Segmentation
May 05, 2015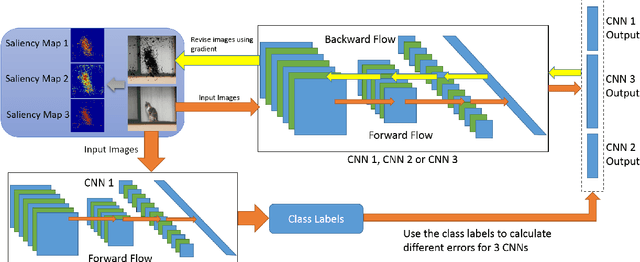
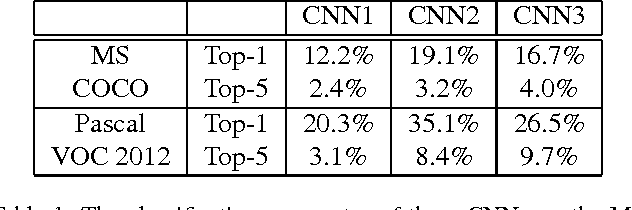
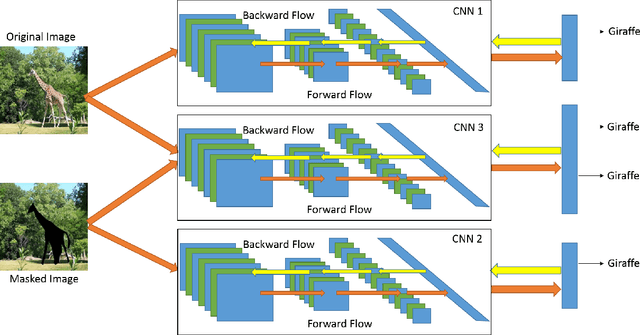
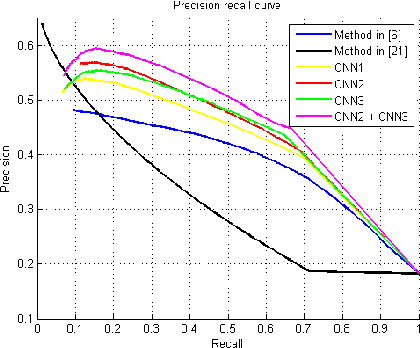
In this paper, we propose several novel deep learning methods for object saliency detection based on the powerful convolutional neural networks. In our approach, we use a gradient descent method to iteratively modify an input image based on the pixel-wise gradients to reduce a cost function measuring the class-specific objectness of the image. The pixel-wise gradients can be efficiently computed using the back-propagation algorithm. The discrepancy between the modified image and the original one may be used as a saliency map for the image. Moreover, we have further proposed several new training methods to learn saliency-specific convolutional nets for object saliency detection, in order to leverage the available pixel-wise segmentation information. Our methods are extremely computationally efficient (processing 20-40 images per second in one GPU). In this work, we use the computed saliency maps for image segmentation. Experimental results on two benchmark tasks, namely Microsoft COCO and Pascal VOC 2012, have shown that our proposed methods can generate high-quality salience maps, clearly outperforming many existing methods. In particular, our approaches excel in handling many difficult images, which contain complex background, highly-variable salient objects, multiple objects, and/or very small salient objects.