 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPD: Guided Progressive Distillation for Fast and High-Quality Video Generation
Feb 02, 2026Diffusion models have achieved remarkable success in video generation; however, the high computational cost of the denoising process remains a major bottleneck. Existing approaches have shown promise in reducing the number of diffusion steps, but they often suffer from significant quality degradation when applied to video generation. We propose Guided Progressive Distillation (GPD), a framework that accelerates the diffusion process for fast and high-quality video generation. GPD introduces a novel training strategy in which a teacher model progressively guides a student model to operate with larger step sizes. The framework consists of two key components: (1) an online-generated training target that reduces optimization difficulty while improving computational efficiency, and (2) frequency-domain constraints in the latent space that promote the preservation of fine-grained details and temporal dynamics. Applied to the Wan2.1 model, GPD reduces the number of sampling steps from 48 to 6 while maintaining competitive visual quality on VBench. Compared with existing distillation methods, GPD demonstrates clear advantages in both pipeline simplicity and quality preservation.
MVP: Multiple View Prediction Improves GUI Grounding
Dec 09, 2025



GUI grounding, which translates natural language instructions into precise pixel coordinates, is essential for developing practical GUI agents. However, we observe that existing grounding models exhibit significant coordinate prediction instability, minor visual perturbations (e.g. cropping a few pixels) can drastically alter predictions, flipping results between correct and incorrect. This instability severely undermines model performance, especially for samples with high-resolution and small UI elements. To address this issue, we propose Multi-View Prediction (MVP), a training-free framework that enhances grounding performance through multi-view inference. Our key insight is that while single-view predictions may be unstable, aggregating predictions from multiple carefully cropped views can effectively distinguish correct coordinates from outliers. MVP comprises two components: (1) Attention-Guided View Proposal, which derives diverse views guided by instruction-to-image attention scores, and (2) Multi-Coordinates Clustering, which ensembles predictions by selecting the centroid of the densest spatial cluster. Extensive experiments demonstrate MVP's effectiveness across various models and benchmarks. Notably, on ScreenSpot-Pro, MVP boosts UI-TARS-1.5-7B to 56.1%, GTA1-7B to 61.7%, Qwen3VL-8B-Instruct to 65.3%, and Qwen3VL-32B-Instruct to 74.0%. The code is available at https://github.com/ZJUSCL/MVP.
WaveFuzz: A Clean-Label Poisoning Attack to Protect Your Voice
Mar 25, 2022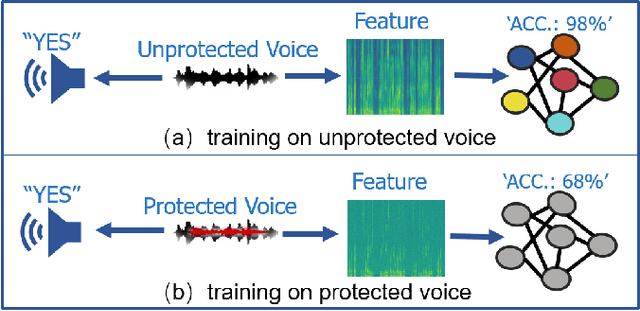
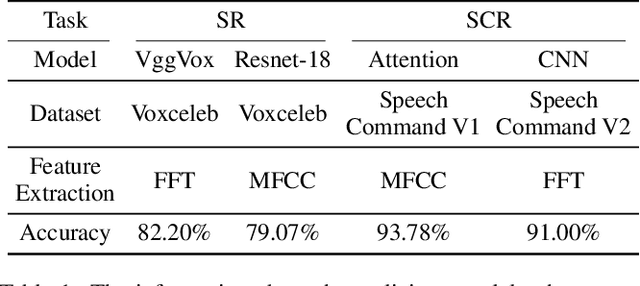
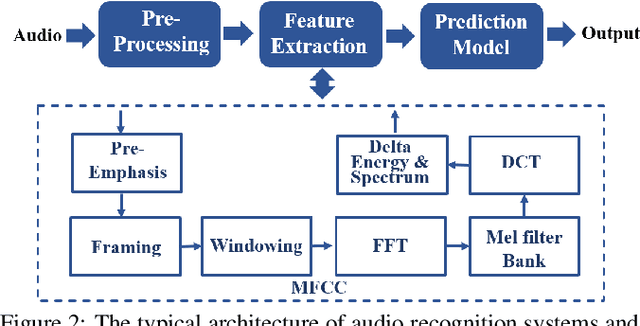
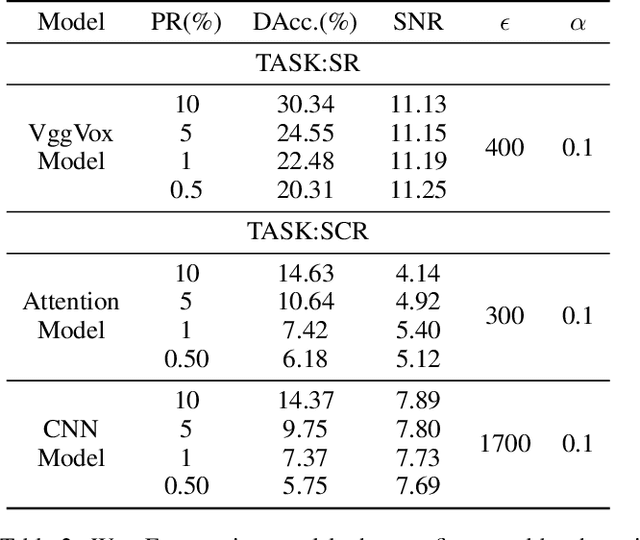
People are not always receptive to their voice data being collected and misused. Training the audio intelligence systems needs these data to build useful features, but the cost for getting permissions or purchasing data is very high, which inevitably encourages hackers to collect these voice data without people's awareness. To discourage the hackers from proactively collecting people's voice data, we are the first to propose a clean-label poisoning attack, called WaveFuzz, which can prevent intelligence audio models from building useful features from protected (poisoned) voice data but still preserve the semantic information to the humans. Specifically, WaveFuzz perturbs the voice data to cause Mel Frequency Cepstral Coefficients (MFCC) (typical representations of audio signals) to generate the poisoned frequency features. These poisoned features are then fed to audio prediction models, which degrades the performance of audio intelligence systems. Empirically, we show the efficacy of WaveFuzz by attacking two representative types of intelligent audio systems, i.e., speaker recognition system (SR) and speech command recognition system (SCR). For example, the accuracies of models are declined by $19.78\%$ when only $10\%$ of the poisoned voice data is to fine-tune models, and the accuracies of models declined by $6.07\%$ when only $10\%$ of the training voice data is poisoned. Consequently, WaveFuzz is an effective technique that enables people to fight back to protect their own voice data, which sheds new light on ameliorating privacy issues.