 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning on Monocular Videos for 3D Human Pose Estimation
Dec 02, 2020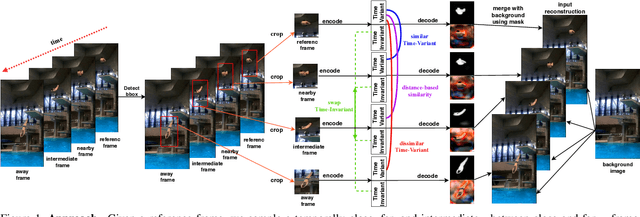
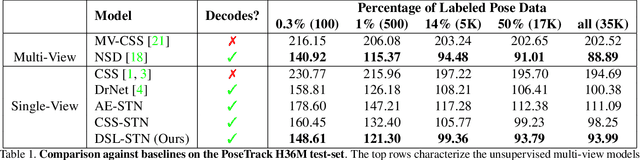
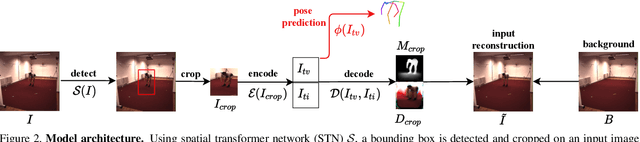
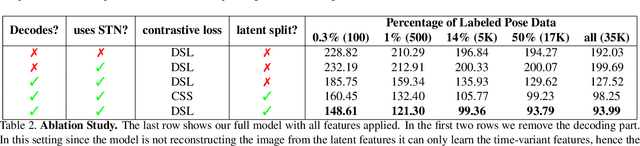
In this paper, we introduce an unsupervised feature extraction method that exploits contrastive self-supervised (CSS) learning to extract rich latent vectors from single-view videos. Instead of simply treating the latent features of nearby frames as positive pairs and those of temporally-distant ones as negative pairs as in other CSS approaches, we explicitly separate each latent vector into a time-variant component and a time-invariant one. We then show that applying CSS only to the time-variant features, while also reconstructing the input and encouraging a gradual transition between nearby and away features yields a rich latent space, well-suited for human pose estimation. Our approach outperforms other unsupervised single-view methods and match the performance of multi-view techniques.
CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild
Nov 30, 2020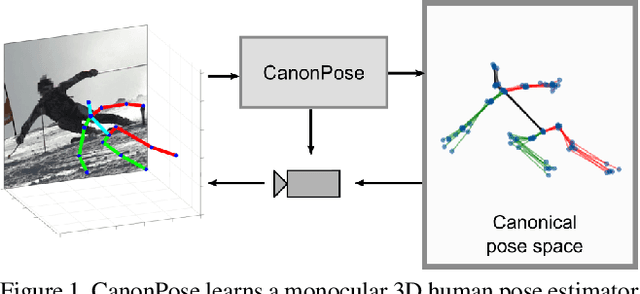
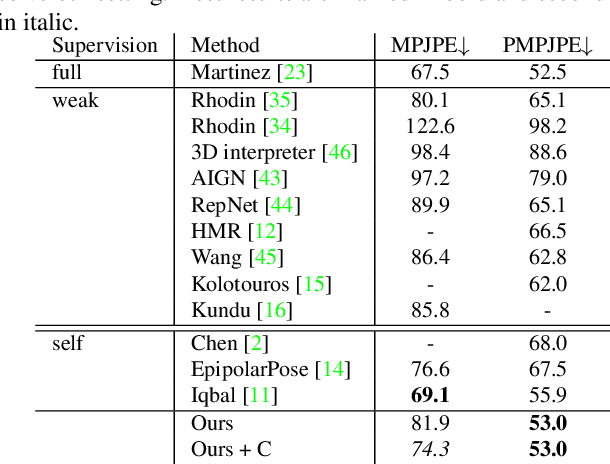
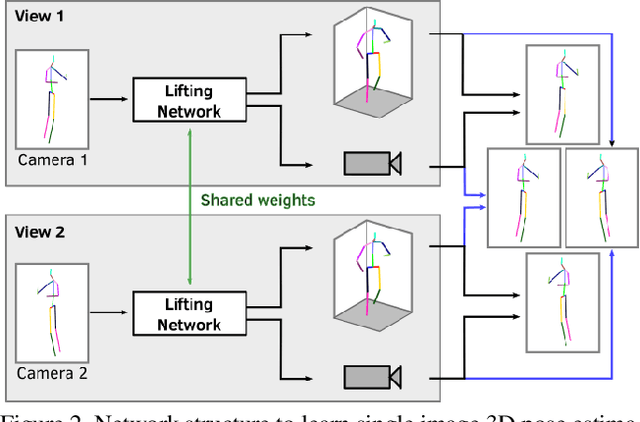
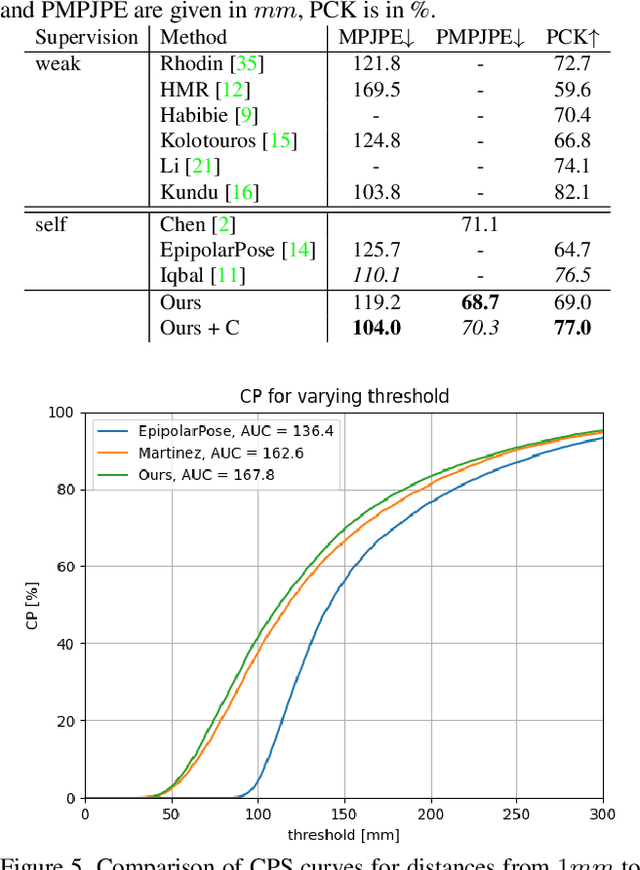
Human pose estimation from single images is a challenging problem in computer vision that requires large amounts of labeled training data to be solved accurately. Unfortunately, for many human activities (\eg outdoor sports) such training data does not exist and is hard or even impossible to acquire with traditional motion capture systems. We propose a self-supervised approach that learns a single image 3D pose estimator from unlabeled multi-view data. To this end, we exploit multi-view consistency constraints to disentangle the observed 2D pose into the underlying 3D pose and camera rotation. In contrast to most existing methods, we do not require calibrated cameras and can therefore learn from moving cameras. Nevertheless, in the case of a static camera setup, we present an optional extension to include constant relative camera rotations over multiple views into our framework. Key to the success are new, unbiased reconstruction objectives that mix information across views and training samples. The proposed approach is evaluated on two benchmark datasets (Human3.6M and MPII-INF-3DHP) and on the in-the-wild SkiPose dataset.
PCLs: Geometry-aware Neural Reconstruction of 3D Pose with Perspective Crop Layers
Nov 27, 2020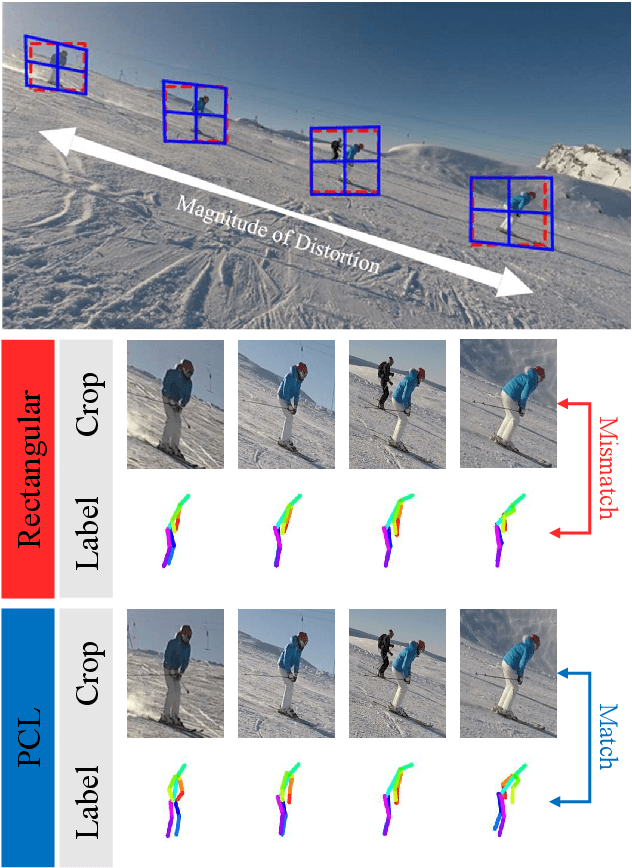
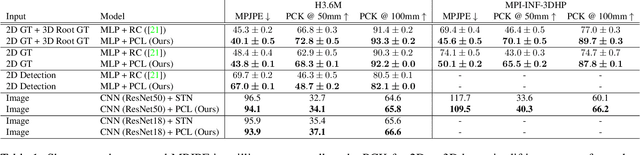
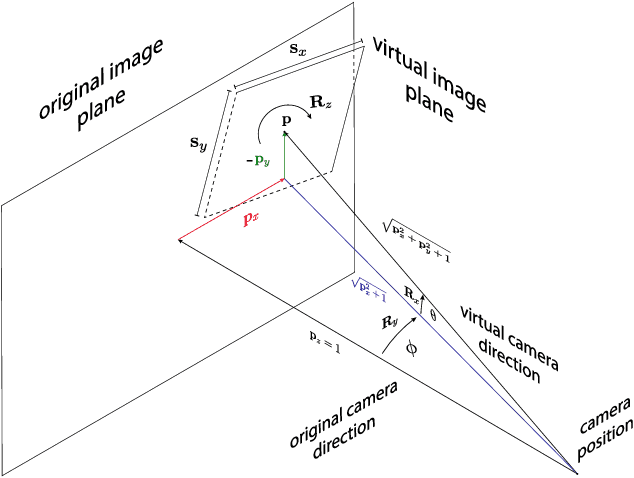

Local processing is an essential feature of CNNs and other neural network architectures - it is one of the reasons why they work so well on images where relevant information is, to a large extent, local. However, perspective effects stemming from the projection in a conventional camera vary for different global positions in the image. We introduce Perspective Crop Layers (PCLs) - a form of perspective crop of the region of interest based on the camera geometry - and show that accounting for the perspective consistently improves the accuracy of state-of-the-art 3D pose reconstruction methods. PCLs are modular neural network layers, which, when inserted into existing CNN and MLP architectures, deterministically remove the location-dependent perspective effects while leaving end-to-end training and the number of parameters of the underlying neural network unchanged. We demonstrate that PCL leads to improved 3D human pose reconstruction accuracy for CNN architectures that use cropping operations, such as spatial transformer networks (STN), and, somewhat surprisingly, MLPs used for 2D-to-3D keypoint lifting. Our conclusion is that it is important to utilize camera calibration information when available, for classical and deep-learning-based computer vision alike. PCL offers an easy way to improve the accuracy of existing 3D reconstruction networks by making them geometry-aware.
Self-supervised Segmentation via Background Inpainting
Nov 11, 2020
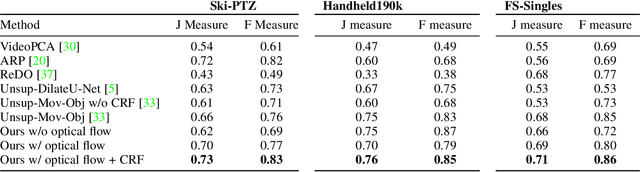
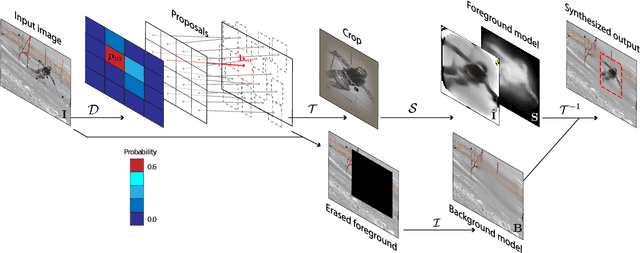

While supervised object detection and segmentation methods achieve impressive accuracy, they generalize poorly to images whose appearance significantly differs from the data they have been trained on. To address this when annotating data is prohibitively expensive, we introduce a self-supervised detection and segmentation approach that can work with single images captured by a potentially moving camera. At the heart of our approach lies the observation that object segmentation and background reconstruction are linked tasks, and that, for structured scenes, background regions can be re-synthesized from their surroundings, whereas regions depicting the moving object cannot. We encode this intuition into a self-supervised loss function that we exploit to train a proposal-based segmentation network. To account for the discrete nature of the proposals, we develop a Monte Carlo-based training strategy that allows the algorithm to explore the large space of object proposals. We apply our method to human detection and segmentation in images that visually depart from those of standard benchmarks and outperform existing self-supervised methods.
Ellipse Detection and Localization with Applications to Knots in Sawn Lumber Images
Nov 10, 2020
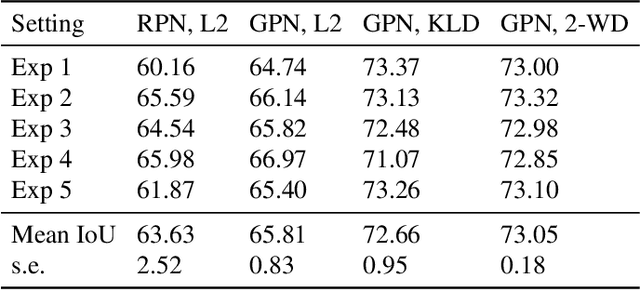
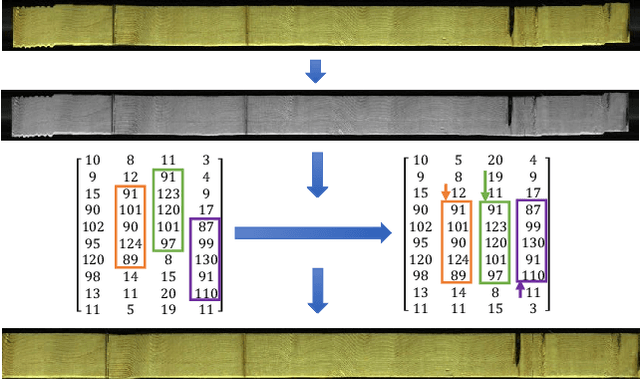

While general object detection has seen tremendous progress, localization of elliptical objects has received little attention in the literature. Our motivating application is the detection of knots in sawn timber images, which is an important problem since the number and types of knots are visual characteristics that adversely affect the quality of sawn timber. We demonstrate how models can be tailored to the elliptical shape and thereby improve on general purpose detectors; more generally, elliptical defects are common in industrial production, such as enclosed air bubbles when casting glass or plastic. In this paper, we adapt the Faster R-CNN with its Region Proposal Network (RPN) to model elliptical objects with a Gaussian function, and extend the existing Gaussian Proposal Network (GPN) architecture by adding the region-of-interest pooling and regression branches, as well as using the Wasserstein distance as the loss function to predict the precise locations of elliptical objects. Our proposed method has promising results on the lumber knot dataset: knots are detected with an average intersection over union of 73.05%, compared to 63.63% for general purpose detectors. Specific to the lumber application, we also propose an algorithm to correct any misalignment in the raw timber images during scanning, and contribute the first open-source lumber knot dataset by labeling the elliptical knots in the preprocessed images.
Front2Back: Single View 3D Shape Reconstruction via Front to Back Prediction
Jan 31, 2020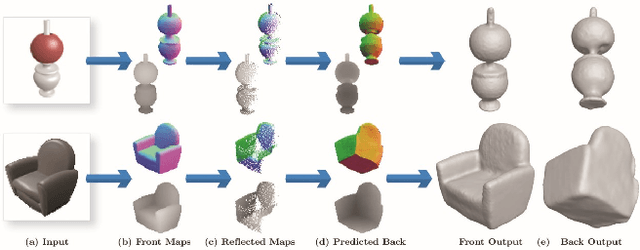



Reconstruction of a 3D shape from a single 2D image is a classical computer vision problem, whose difficulty stems from the inherent ambiguity of recovering occluded or only partially observed surfaces. Recent methods address this challenge through the use of largely unstructured neural networks that effectively distill conditional mapping and priors over 3D shape. In this work, we induce structure and geometric constraints by leveraging three core observations: (1) the surface of most everyday objects is often almost entirely exposed from pairs of typical opposite views; (2) everyday objects often exhibit global reflective symmetries which can be accurately predicted from single views; (3) opposite orthographic views of a 3D shape share consistent silhouettes. Following these observations, we first predict orthographic 2.5D visible surface maps (depth, normal and silhouette) from perspective 2D images, and detect global reflective symmetries in this data; second, we predict the back facing depth and normal maps using as input the front maps and, when available, the symmetric reflections of these maps; and finally, we reconstruct a 3D mesh from the union of these maps using a surface reconstruction method best suited for this data. Our experiments demonstrate that our framework outperforms state-of-the art approaches for 3D shape reconstructions from 2D and 2.5D data in terms of input fidelity and details preservation. Specifically, we achieve 12% better performance on average in ShapeNet benchmark dataset, and up to 19% for certain classes of objects (e.g., chairs and vessels).
Deformation-aware Unpaired Image Translation for Pose Estimation on Laboratory Animals
Jan 23, 2020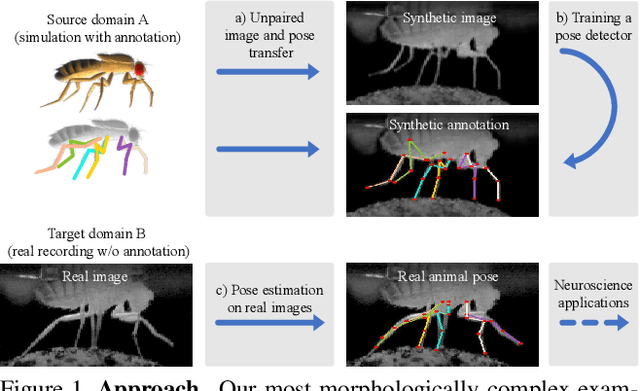
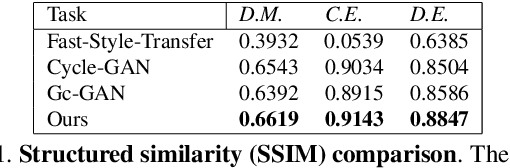

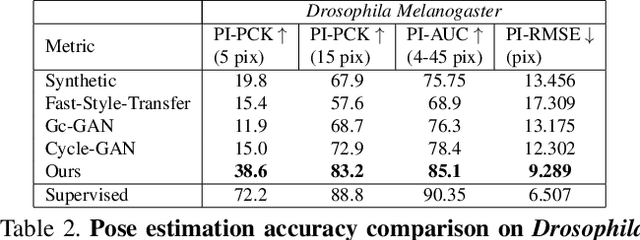
Our goal is to capture the pose of neuroscience model organisms, without using any manual supervision, to be able to study how neural circuits orchestrate behaviour. Human pose estimation attains remarkable accuracy when trained on real or simulated datasets consisting of millions of frames. However, for many applications simulated models are unrealistic and real training datasets with comprehensive annotations do not exist. We address this problem with a new sim2real domain transfer method. Our key contribution is the explicit and independent modeling of appearance, shape and poses in an unpaired image translation framework. Our model lets us train a pose estimator on the target domain by transferring readily available body keypoint locations from the source domain to generated target images. We compare our approach with existing domain transfer methods and demonstrate improved pose estimation accuracy on Drosophila melanogaster (fruit fly), Caenorhabditis elegans (worm) and Danio rerio (zebrafish), without requiring any manual annotation on the target domain and despite using simplistic off-the-shelf animal characters for simulation, or simple geometric shapes as models. Our new datasets, code, and trained models will be published to support future neuroscientific studies.
ActiveMoCap: Optimized Drone Flight for Active Human Motion Capture
Dec 18, 2019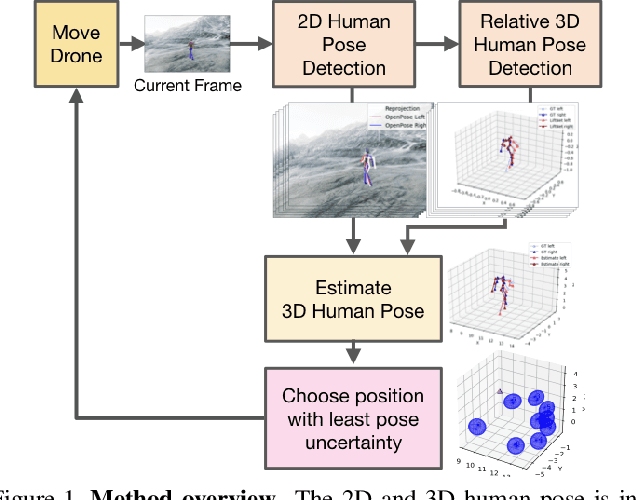

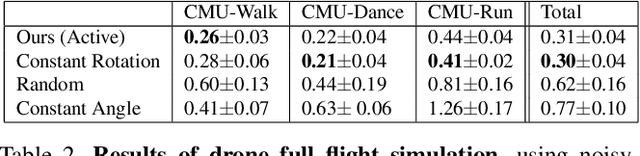
The accuracy of monocular 3D human pose estimation depends on the viewpoint from which the image is captured. While camera-equipped drones provide control over this viewpoint, automatically positioning them at the location which will yield the highest accuracy remains an open problem. This is the problem that we address in this paper. Specifically, given a short video sequence, we introduce an algorithm that predicts the where a drone should go in the future frame so as to maximize 3D human pose estimation accuracy. A key idea underlying our approach is a method to estimate the uncertainty of the 3D body pose estimates. We integrate several sources of uncertainty, originating from a deep learning based regressors and temporal smoothness. The resulting motion planner leads to improved 3D body pose estimates and outperforms or matches existing planners that are based on person following and orbiting.
Gravity as a Reference for Estimating a Person's Height from Video
Oct 16, 2019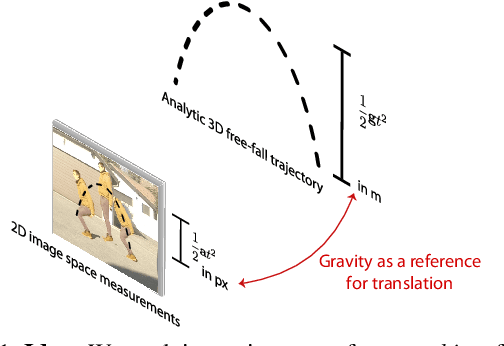
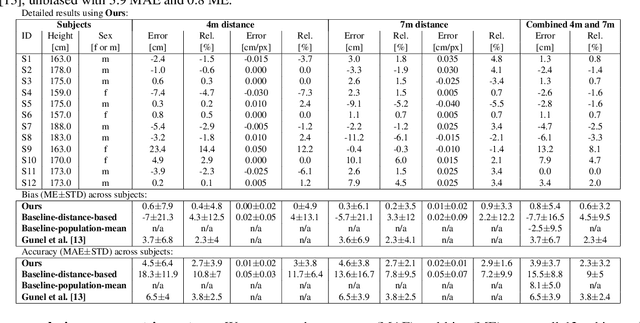
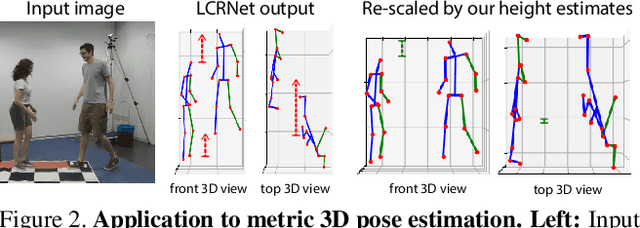

Estimating the metric height of a person from monocular imagery without additional assumptions is ill-posed. Existing solutions either require manual calibration of ground plane and camera geometry, special cameras, or reference objects of known size. We focus on motion cues and exploit gravity on earth as an omnipresent reference 'object' to translate acceleration, and subsequently height, measured in image-pixels to values in meters. We require videos of motion as input, where gravity is the only external force. This limitation is different to those of existing solutions that recover a person's height and, therefore, our method opens up new application fields. We show theoretically and empirically that a simple motion trajectory analysis suffices to translate from pixel measurements to the person's metric height, reaching a MAE of up to 3.9 cm on jumping motions, and that this works without camera and ground plane calibration.
Motion Capture from Pan-Tilt Cameras with Unknown Orientation
Aug 30, 2019
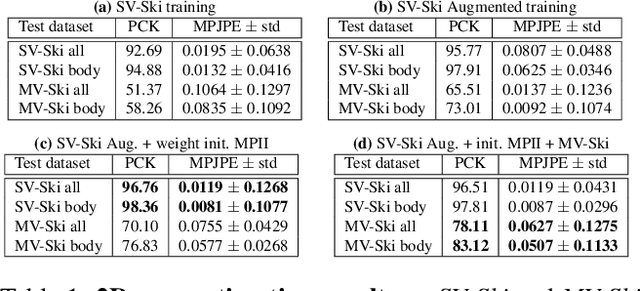
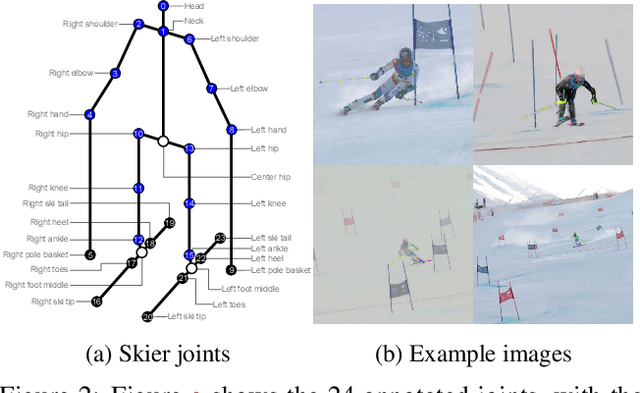
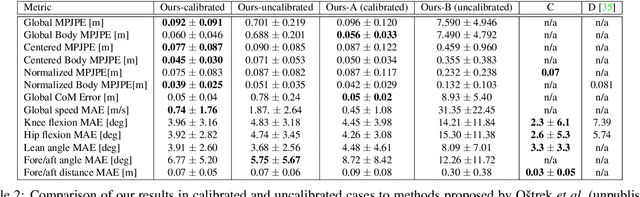
In sports, such as alpine skiing, coaches would like to know the speed and various biomechanical variables of their athletes and competitors. Existing methods use either body-worn sensors, which are cumbersome to setup, or manual image annotation, which is time consuming. We propose a method for estimating an athlete's global 3D position and articulated pose using multiple cameras. By contrast to classical markerless motion capture solutions, we allow cameras to rotate freely so that large capture volumes can be covered. In a first step, tight crops around the skier are predicted and fed to a 2D pose estimator network. The 3D pose is then reconstructed using a bundle adjustment method. Key to our solution is the rotation estimation of Pan-Tilt cameras in a joint optimization with the athlete pose and conditioning on relative background motion computed with feature tracking. Furthermore, we created a new alpine skiing dataset and annotated it with 2D pose labels, to overcome shortcomings of existing ones. Our method estimates accurate global 3D poses from images only and provides coaches with an automatic and fast tool for measuring and improving an athlete's performance.