 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComDefend: An Efficient Image Compression Model to Defend Adversarial Examples
Nov 30, 2018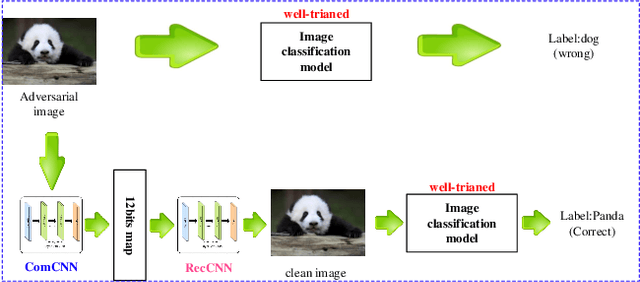
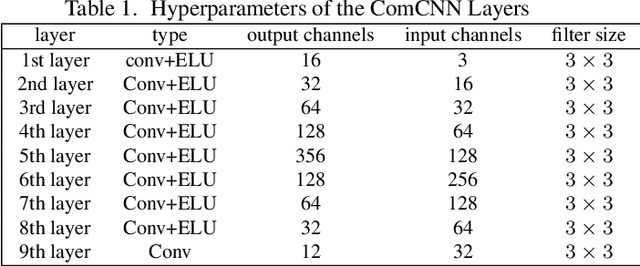
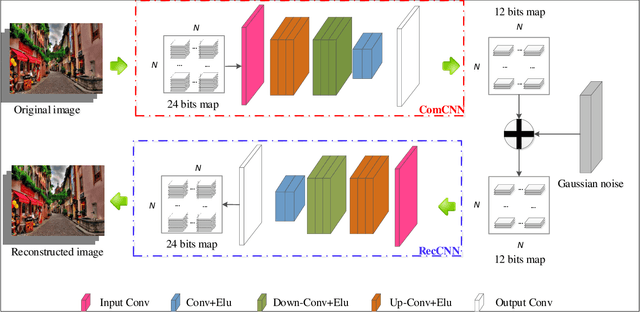
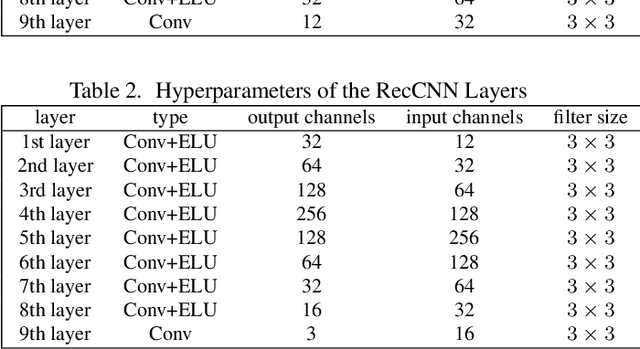
Deep neural networks (DNNs) have been demonstrated to be vulnerable to adversarial examples. Specifically, adding imperceptible perturbations to clean images can fool the well trained deep neural networks. In this paper, we propose an end-to-end image compression model to defend adversarial examples: \textbf{ComDefend}. The proposed model consists of a compression convolutional neural network (ComCNN) and a reconstruction convolutional neural network (ResCNN). The ComCNN is used to maintain the structure information of the original image and purify adversarial perturbations. And the ResCNN is used to reconstruct the original image with high quality. In other words, ComDefend can transform the adversarial image to its clean version, which is then fed to the trained classifier. Our method is a pre-processing module, and does not modify the classifier's structure during the whole process. Therefore, it can be combined with other model-specific defense models to jointly improve the classifier's robustness. A series of experiments conducted on MNIST, CIFAR10 and ImageNet show that the proposed method outperforms the state-of-the-art defense methods, and is consistently effective to protect classifiers against adversarial attacks.
Curriculum Domain Adaptation for Semantic Segmentation of Urban Scenes
Oct 19, 2018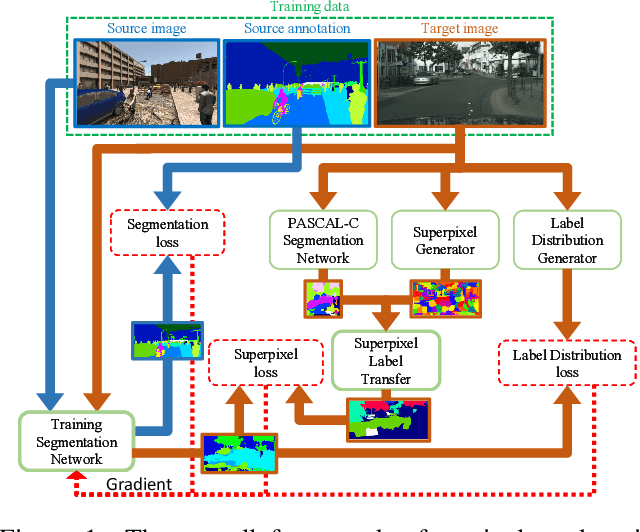

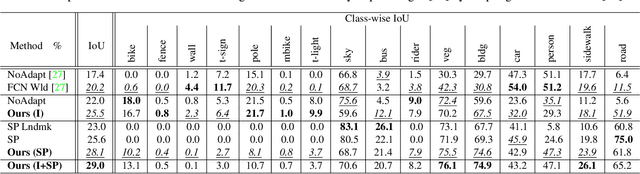
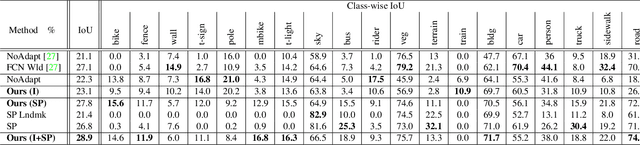
During the last half decade, convolutional neural networks (CNNs) have triumphed over semantic segmentation, which is one of the core tasks in many applications such as autonomous driving. However, to train CNNs requires a considerable amount of data, which is difficult to collect and laborious to annotate. Recent advances in computer graphics make it possible to train CNNs on photo-realistic synthetic imagery with computer-generated annotations. Despite this, the domain mismatch between the real images and the synthetic data cripples the models' performance. Hence, we propose a curriculum-style learning approach to minimize the domain gap in urban scenery semantic segmentation. The curriculum domain adaptation solves easy tasks first to infer necessary properties about the target domain; in particular, the first task is to learn global label distributions over images and local distributions over landmark superpixels. These are easy to estimate because images of urban scenes have strong idiosyncrasies (e.g., the size and spatial relations of buildings, streets, cars, etc.). We then train a segmentation network while regularizing its predictions in the target domain to follow those inferred properties. In experiments, our method outperforms the baselines on two datasets and two backbone networks. We also report extensive ablation studies about our approach.
Rediscovering Deep Neural Networks in Finite-State Distributions
Sep 26, 2018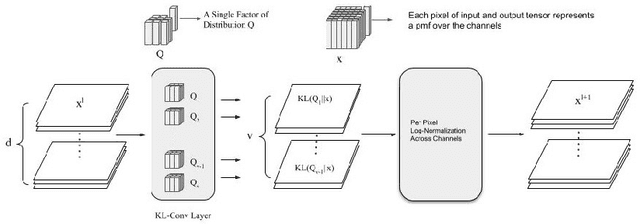
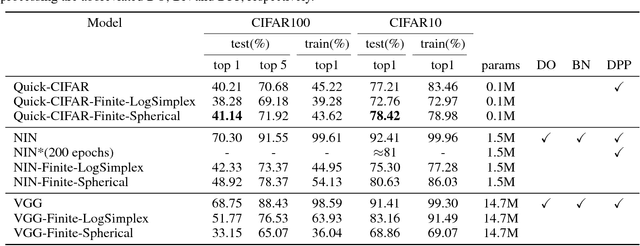
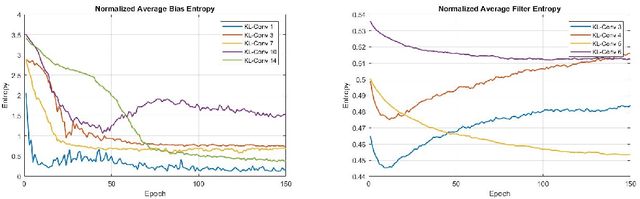
We propose a new way of thinking about deep neural networks, in which the linear and non-linear components of the network are naturally derived and justified in terms of principles in probability theory. In particular, the models constructed in our framework assign probabilities to uncertain realizations, leading to Kullback-Leibler Divergence (KLD) as the linear layer. In our model construction, we also arrive at a structure similar to ReLU activation supported with Bayes' theorem. The non-linearities in our framework are normalization layers with ReLU and Sigmoid as element-wise approximations. Additionally, the pooling function is derived as a marginalization of spatial random variables according to the mechanics of the framework. As such, Max Pooling is an approximation to the aforementioned marginalization process. Since our models are comprised of finite state distributions (FSD) as variables and parameters, exact computation of information-theoretic quantities such as entropy and KLD is possible, thereby providing more objective measures to analyze networks. Unlike existing designs that rely on heuristics, the proposed framework restricts subjective interpretations of CNNs and sheds light on the functionality of neural networks from a completely new perspective.
Probabilistic Sparse Subspace Clustering Using Delayed Association
Aug 28, 2018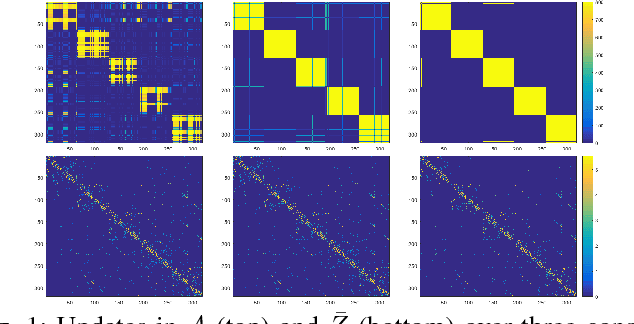
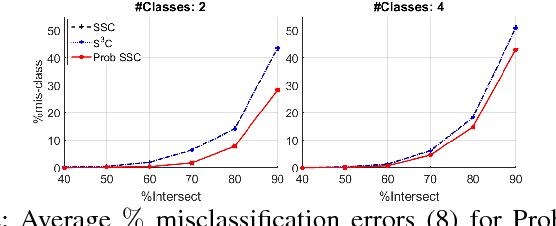
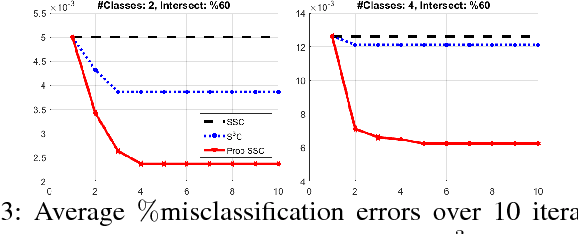
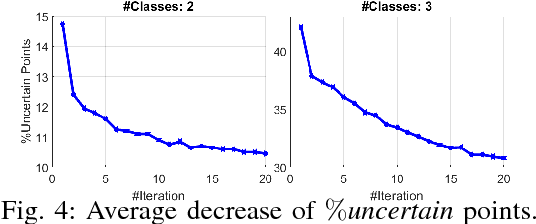
Discovering and clustering subspaces in high-dimensional data is a fundamental problem of machine learning with a wide range of applications in data mining, computer vision, and pattern recognition. Earlier methods divided the problem into two separate stages of finding the similarity matrix and finding clusters. Similar to some recent works, we integrate these two steps using a joint optimization approach. We make the following contributions: (i) we estimate the reliability of the cluster assignment for each point before assigning a point to a subspace. We group the data points into two groups of "certain" and "uncertain", with the assignment of latter group delayed until their subspace association certainty improves. (ii) We demonstrate that delayed association is better suited for clustering subspaces that have ambiguities, i.e. when subspaces intersect or data are contaminated with outliers/noise. (iii) We demonstrate experimentally that such delayed probabilistic association leads to a more accurate self-representation and final clusters. The proposed method has higher accuracy both for points that exclusively lie in one subspace, and those that are on the intersection of subspaces. (iv) We show that delayed association leads to huge reduction of computational cost, since it allows for incremental spectral clustering.
Simultaneous Detection and Quantification of Retinal Fluid with Deep Learning
Aug 17, 2017
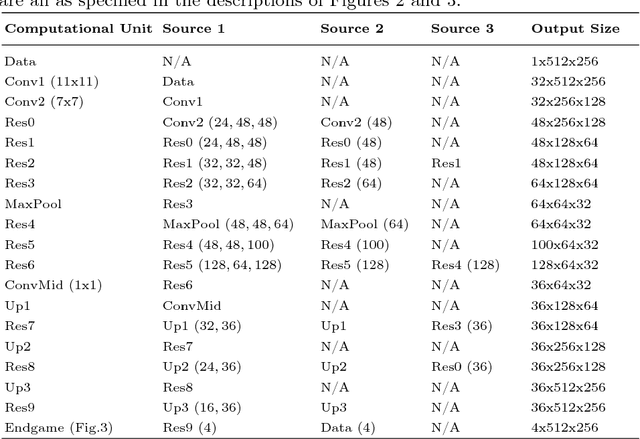
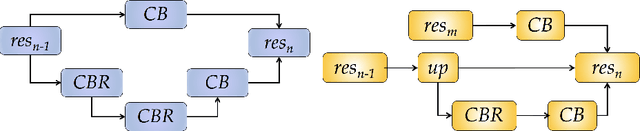
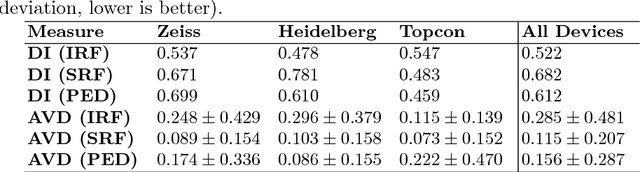
We propose a new deep learning approach for automatic detection and segmentation of fluid within retinal OCT images. The proposed framework utilizes both ResNet and Encoder-Decoder neural network architectures. When training the network, we apply a novel data augmentation method called myopic warping together with standard rotation-based augmentation to increase the training set size to 45 times the original amount. Finally, the network output is post-processed with an energy minimization algorithm (graph cut) along with a few other knowledge guided morphological operations to finalize the segmentation process. Based on OCT imaging data and its ground truth from the RETOUCH challenge, the proposed system achieves dice indices of 0.522, 0.682, and 0.612, and average absolute volume differences of 0.285, 0.115, and 0.156 mm$^3$ for intaretinal fluid, subretinal fluid, and pigment epithelial detachment respectively.
View-Invariant Recognition of Action Style Self-Dissimilarity
May 22, 2017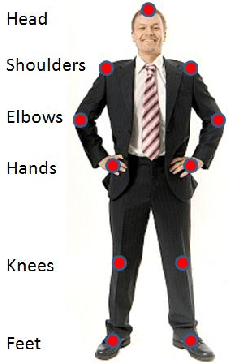

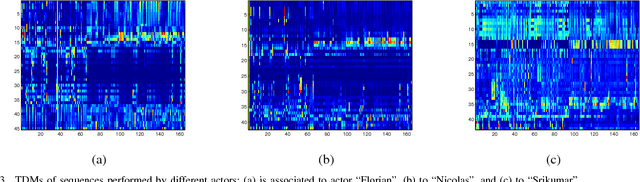
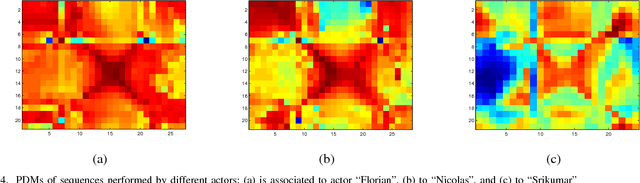
Self-similarity was recently introduced as a measure of inter-class congruence for classification of actions. Herein, we investigate the dual problem of intra-class dissimilarity for classification of action styles. We introduce self-dissimilarity matrices that discriminate between same actions performed by different subjects regardless of viewing direction and camera parameters. We investigate two frameworks using these invariant style dissimilarity measures based on Principal Component Analysis (PCA) and Fisher Discriminant Analysis (FDA). Extensive experiments performed on IXMAS dataset indicate remarkably good discriminant characteristics for the proposed invariant measures for gender recognition from video data.
An Invariant Model of the Significance of Different Body Parts in Recognizing Different Actions
May 22, 2017

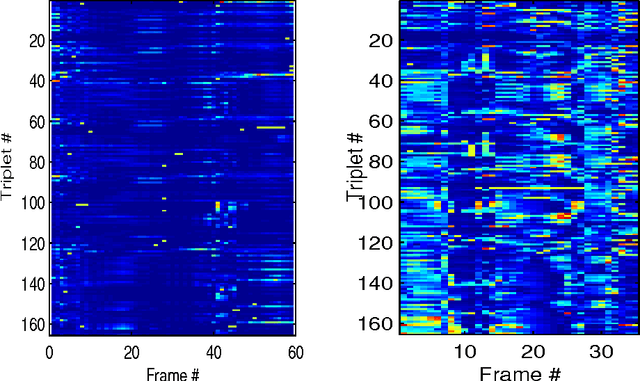
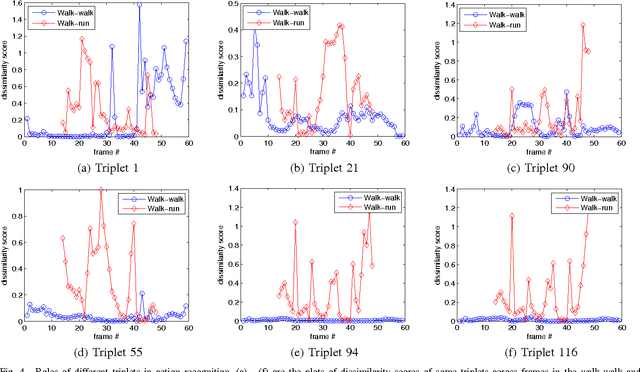
In this paper, we show that different body parts do not play equally important roles in recognizing a human action in video data. We investigate to what extent a body part plays a role in recognition of different actions and hence propose a generic method of assigning weights to different body points. The approach is inspired by the strong evidence in the applied perception community that humans perform recognition in a foveated manner, that is they recognize events or objects by only focusing on visually significant aspects. An important contribution of our method is that the computation of the weights assigned to body parts is invariant to viewing directions and camera parameters in the input data. We have performed extensive experiments to validate the proposed approach and demonstrate its significance. In particular, results show that considerable improvement in performance is gained by taking into account the relative importance of different body parts as defined by our approach.
Phase-Shifting Separable Haar Wavelets and Applications
May 20, 2017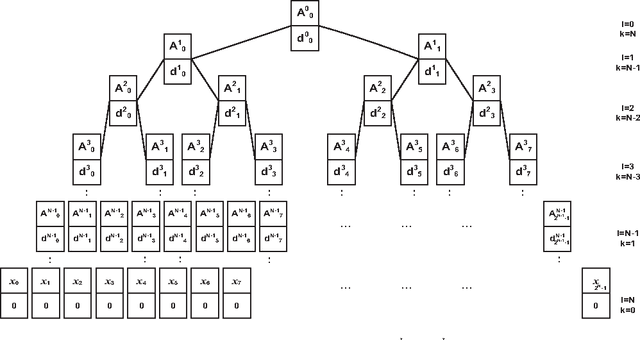



This paper presents a new approach for tackling the shift-invariance problem in the discrete Haar domain, without trading off any of its desirable properties, such as compression, separability, orthogonality, and symmetry. The paper presents several key theoretical contributions. First, we derive closed form expressions for phase shifting in the Haar domain both in partially decimated and fully decimated transforms. Second, it is shown that the wavelet coefficients of the shifted signal can be computed solely by using the coefficients of the original transformed signal. Third, we derive closed-form expressions for non-integer shifts, which have not been previously reported in the literature. Fourth, we establish the complexity of the proposed phase shifting approach using the derived analytic expressions. As an application example of these results, we apply the new formulae to image rotation and interpolation, and evaluate its performance against standard methods.
Non-Linear Phase-Shifting of Haar Wavelets for Run-Time All-Frequency Lighting
May 20, 2017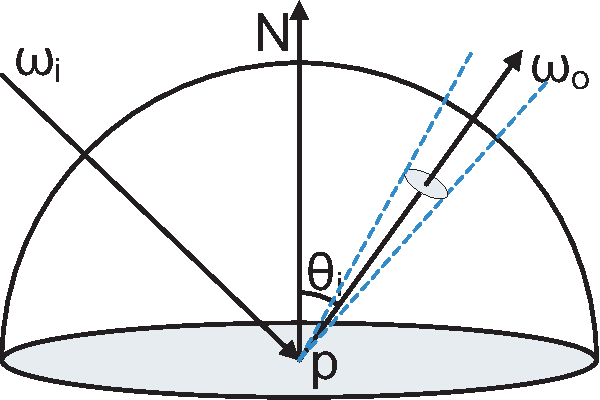

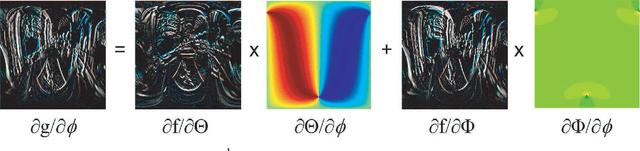
This paper focuses on real-time all-frequency image-based rendering using an innovative solution for run-time computation of light transport. The approach is based on new results derived for non-linear phase shifting in the Haar wavelet domain. Although image-based methods for real-time rendering of dynamic glossy objects have been proposed, they do not truly scale to all possible frequencies and high sampling rates without trading storage, glossiness, or computational time, while varying both lighting and viewpoint. This is due to the fact that current approaches are limited to precomputed radiance transfer (PRT), which is prohibitively expensive in terms of memory requirements and real-time rendering when both varying light and viewpoint changes are required together with high sampling rates for high frequency lighting of glossy material. On the other hand, current methods cannot handle object rotation, which is one of the paramount issues for all PRT methods using wavelets. This latter problem arises because the precomputed data are defined in a global coordinate system and encoded in the wavelet domain, while the object is rotated in a local coordinate system. At the root of all the above problems is the lack of efficient run-time solution to the nontrivial problem of rotating wavelets (a non-linear phase-shift), which we solve in this paper.
Learning Semantics for Image Annotation
May 15, 2017



Image search and retrieval engines rely heavily on textual annotation in order to match word queries to a set of candidate images. A system that can automatically annotate images with meaningful text can be highly beneficial for such engines. Currently, the approaches to develop such systems try to establish relationships between keywords and visual features of images. In this paper, We make three main contributions to this area: (i) We transform this problem from the low-level keyword space to the high-level semantics space that we refer to as the "{\em image theme}", (ii) Instead of treating each possible keyword independently, we use latent Dirichlet allocation to learn image themes from the associated texts in a training phase. Images are then annotated with image themes rather than keywords, using a modified continuous relevance model, which takes into account the spatial coherence and the visual continuity among images of common theme. (iii) To achieve more coherent annotations among images of common theme, we have integrated ConceptNet in learning the semantics of images, and hence augment image descriptions beyond annotations provided by humans. Images are thus further annotated by a few most significant words of the prominent image theme. Our extensive experiments show that a coherent theme-based image annotation using high-level semantics results in improved precision and recall as compared with equivalent classical keyword annotation systems.