 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-Med3D: Bridging Dimension and Domain Gaps in Volumetric Segmentation via Progressive Adaptation
Jun 17, 2026Although DINOv3 has demonstrated remarkable semantic discrimination in natural imagery, its direct application to volumetric medical segmentation is hindered by inherent dimension and domain disparities. To resolve these issues, we propose DINO-Med3D, a two-stage progressive framework that repurpose the pre-trained DINOv3 encoder for 3D medical tasks. In the first stage, we mitigate the dimension gap by introducing a multi-slice embedding module that incorporates pseudo-3D context, while simultaneously employing a segmentation proxy task to adapt representations learned from natural scenes to the medical domain. Subsequently, we further enhance volumetric understanding by adding lightweight 3D adapters into the frozen backbone to enforce global inter-slice continuity. Finally, to compensate for the spatial information loss inherent in the embedding process, we design a parallel detail recovery stream to explicitly preserve high-frequency boundary cues. Extensive experiments on five public datasets demonstrate that our approach successfully adapts DINOv3 to the medical domain and significantly outperforms state-of-the-art baselines.
Can a Teenager Fool an AI? Evaluating Low-Cost Cosmetic Attacks on Age Estimation Systems
Feb 23, 2026Age estimation systems are increasingly deployed as gatekeepers for age-restricted online content, yet their robustness to cosmetic modifications has not been systematically evaluated. We investigate whether simple, household-accessible cosmetic changes, including beards, grey hair, makeup, and simulated wrinkles, can cause AI age estimators to classify minors as adults. To study this threat at scale without ethical concerns, we simulate these physical attacks on 329 facial images of individuals aged 10 to 21 using a VLM image editor (Gemini 2.5 Flash Image). We then evaluate eight models from our prior benchmark: five specialized architectures (MiVOLO, Custom-Best, Herosan, MiViaLab, DEX) and three vision-language models (Gemini 3 Flash, Gemini 2.5 Flash, GPT-5-Nano). We introduce the Attack Conversion Rate (ACR), defined as the fraction of images predicted as minor at baseline that flip to adult after attack, a population-agnostic metric that does not depend on the ratio of minors to adults in the test set. Our results reveal that a synthetic beard alone achieves 28 to 69 percent ACR across all eight models; combining all four attacks shifts predicted age by +7.7 years on average across all 329 subjects and reaches up to 83 percent ACR; and vision-language models exhibit lower ACR (59 to 71 percent) than specialized models (63 to 83 percent) under the full attack, although the ACR ranges overlap and the difference is not statistically tested. These findings highlight a critical vulnerability in deployed age-verification pipelines and call for adversarial robustness evaluation as a mandatory criterion for model selection.
Why Human Guidance Matters in Collaborative Vibe Coding
Feb 11, 2026Writing code has been one of the most transformative ways for human societies to translate abstract ideas into tangible technologies. Modern AI is transforming this process by enabling experts and non-experts alike to generate code without actually writing code, but instead, through natural language instructions, or "vibe coding". While increasingly popular, the cumulative impact of vibe coding on productivity and collaboration, as well as the role of humans in this process, remains unclear. Here, we introduce a controlled experimental framework for studying collaborative vibe coding and use it to compare human-led, AI-led, and hybrid groups. Across 16 experiments involving 604 human participants, we show that people provide uniquely effective high-level instructions for vibe coding across iterations, whereas AI-provided instructions often result in performance collapse. We further demonstrate that hybrid systems perform best when humans retain directional control (providing the instructions), while evaluation is delegated to AI.
Explainable AI as a Double-Edged Sword in Dermatology: The Impact on Clinicians versus The Public
Dec 14, 2025Artificial intelligence (AI) is increasingly permeating healthcare, from physician assistants to consumer applications. Since AI algorithm's opacity challenges human interaction, explainable AI (XAI) addresses this by providing AI decision-making insight, but evidence suggests XAI can paradoxically induce over-reliance or bias. We present results from two large-scale experiments (623 lay people; 153 primary care physicians, PCPs) combining a fairness-based diagnosis AI model and different XAI explanations to examine how XAI assistance, particularly multimodal large language models (LLMs), influences diagnostic performance. AI assistance balanced across skin tones improved accuracy and reduced diagnostic disparities. However, LLM explanations yielded divergent effects: lay users showed higher automation bias - accuracy boosted when AI was correct, reduced when AI erred - while experienced PCPs remained resilient, benefiting irrespective of AI accuracy. Presenting AI suggestions first also led to worse outcomes when the AI was incorrect for both groups. These findings highlight XAI's varying impact based on expertise and timing, underscoring LLMs as a "double-edged sword" in medical AI and informing future human-AI collaborative system design.
Towards Privacy-Preserving and Heterogeneity-aware Split Federated Learning via Probabilistic Masking
Sep 18, 2025Split Federated Learning (SFL) has emerged as an efficient alternative to traditional Federated Learning (FL) by reducing client-side computation through model partitioning. However, exchanging of intermediate activations and model updates introduces significant privacy risks, especially from data reconstruction attacks that recover original inputs from intermediate representations. Existing defenses using noise injection often degrade model performance. To overcome these challenges, we present PM-SFL, a scalable and privacy-preserving SFL framework that incorporates Probabilistic Mask training to add structured randomness without relying on explicit noise. This mitigates data reconstruction risks while maintaining model utility. To address data heterogeneity, PM-SFL employs personalized mask learning that tailors submodel structures to each client's local data. For system heterogeneity, we introduce a layer-wise knowledge compensation mechanism, enabling clients with varying resources to participate effectively under adaptive model splitting. Theoretical analysis confirms its privacy protection, and experiments on image and wireless sensing tasks demonstrate that PM-SFL consistently improves accuracy, communication efficiency, and robustness to privacy attacks, with particularly strong performance under data and system heterogeneity.
D-CoRP: Differentiable Connectivity Refinement for Functional Brain Networks
May 28, 2024Brain network is an important tool for understanding the brain, offering insights for scientific research and clinical diagnosis. Existing models for brain networks typically primarily focus on brain regions or overlook the complexity of brain connectivities. MRI-derived brain network data is commonly susceptible to connectivity noise, underscoring the necessity of incorporating connectivities into the modeling of brain networks. To address this gap, we introduce a differentiable module for refining brain connectivity. We develop the multivariate optimization based on information bottleneck theory to address the complexity of the brain network and filter noisy or redundant connections. Also, our method functions as a flexible plugin that is adaptable to most graph neural networks. Our extensive experimental results show that the proposed method can significantly improve the performance of various baseline models and outperform other state-of-the-art methods, indicating the effectiveness and generalizability of the proposed method in refining brain network connectivity. The code will be released for public availability.
Hand-Object Interaction Controller (HOIC): Deep Reinforcement Learning for Reconstructing Interactions with Physics
May 04, 2024



Hand manipulating objects is an important interaction motion in our daily activities. We faithfully reconstruct this motion with a single RGBD camera by a novel deep reinforcement learning method to leverage physics. Firstly, we propose object compensation control which establishes direct object control to make the network training more stable. Meanwhile, by leveraging the compensation force and torque, we seamlessly upgrade the simple point contact model to a more physical-plausible surface contact model, further improving the reconstruction accuracy and physical correctness. Experiments indicate that without involving any heuristic physical rules, this work still successfully involves physics in the reconstruction of hand-object interactions which are complex motions hard to imitate with deep reinforcement learning. Our code and data are available at https://github.com/hu-hy17/HOIC.
Physical Interaction: Reconstructing Hand-object Interactions with Physics
Sep 22, 2022

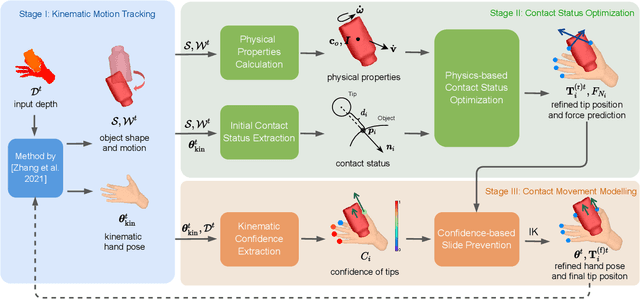

Single view-based reconstruction of hand-object interaction is challenging due to the severe observation missing caused by occlusions. This paper proposes a physics-based method to better solve the ambiguities in the reconstruction. It first proposes a force-based dynamic model of the in-hand object, which not only recovers the unobserved contacts but also solves for plausible contact forces. Next, a confidence-based slide prevention scheme is proposed, which combines both the kinematic confidences and the contact forces to jointly model static and sliding contact motion. Qualitative and quantitative experiments show that the proposed technique reconstructs both physically plausible and more accurate hand-object interaction and estimates plausible contact forces in real-time with a single RGBD sensor.