 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Language Acquisition with One-shot Visual Concept Learning through a Conversational Game
Apr 26, 2018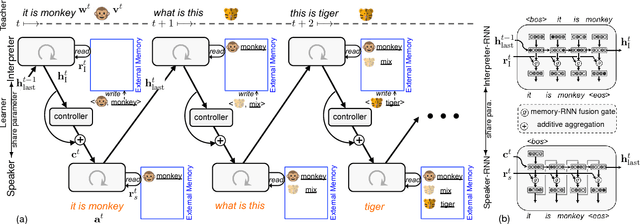
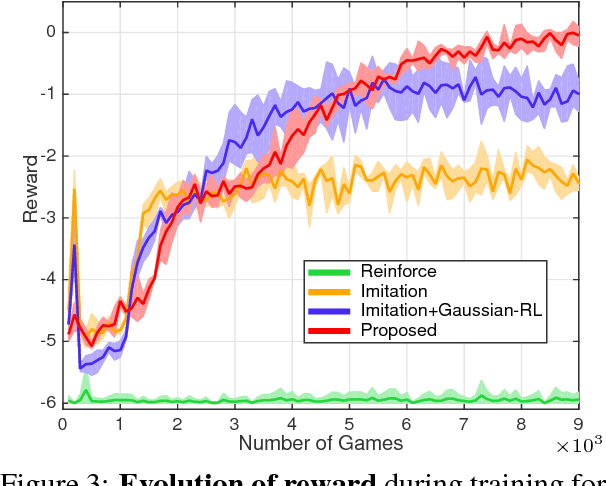
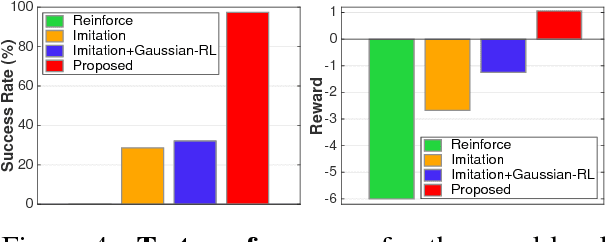
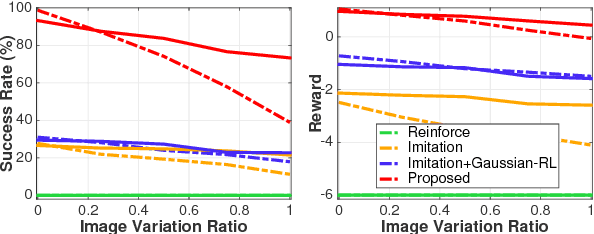
Building intelligent agents that can communicate with and learn from humans in natural language is of great value. Supervised language learning is limited by the ability of capturing mainly the statistics of training data, and is hardly adaptive to new scenarios or flexible for acquiring new knowledge without inefficient retraining or catastrophic forgetting. We highlight the perspective that conversational interaction serves as a natural interface both for language learning and for novel knowledge acquisition and propose a joint imitation and reinforcement approach for grounded language learning through an interactive conversational game. The agent trained with this approach is able to actively acquire information by asking questions about novel objects and use the just-learned knowledge in subsequent conversations in a one-shot fashion. Results compared with other methods verified the effectiveness of the proposed approach.
Listen, Interact and Talk: Learning to Speak via Interaction
May 28, 2017
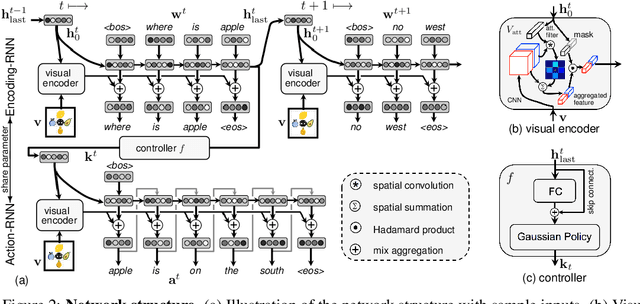

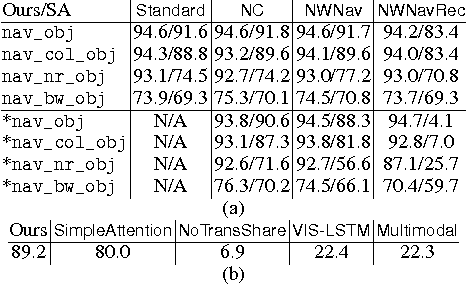
One of the long-term goals of artificial intelligence is to build an agent that can communicate intelligently with human in natural language. Most existing work on natural language learning relies heavily on training over a pre-collected dataset with annotated labels, leading to an agent that essentially captures the statistics of the fixed external training data. As the training data is essentially a static snapshot representation of the knowledge from the annotator, the agent trained this way is limited in adaptiveness and generalization of its behavior. Moreover, this is very different from the language learning process of humans, where language is acquired during communication by taking speaking action and learning from the consequences of speaking action in an interactive manner. This paper presents an interactive setting for grounded natural language learning, where an agent learns natural language by interacting with a teacher and learning from feedback, thus learning and improving language skills while taking part in the conversation. To achieve this goal, we propose a model which incorporates both imitation and reinforcement by leveraging jointly sentence and reward feedbacks from the teacher. Experiments are conducted to validate the effectiveness of the proposed approach.
A Deep Compositional Framework for Human-like Language Acquisition in Virtual Environment
May 19, 2017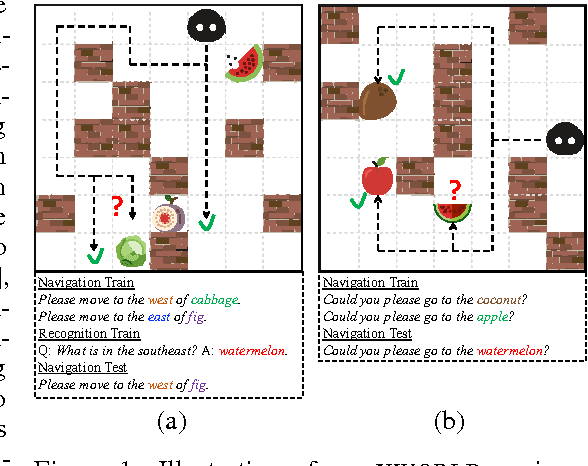
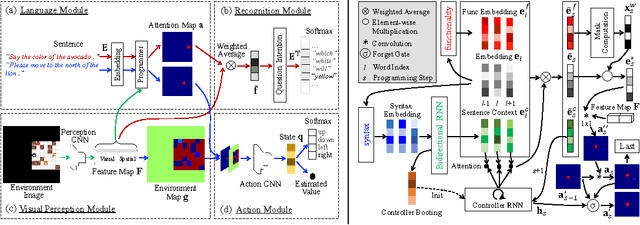
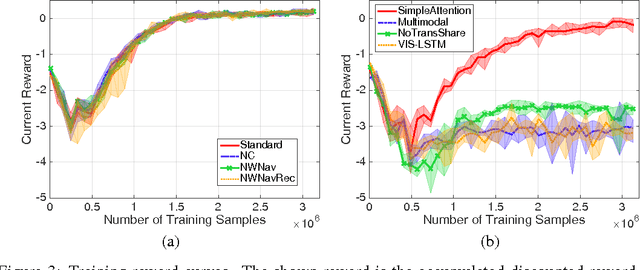
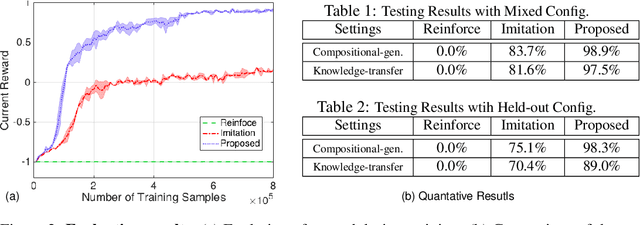
We tackle a task where an agent learns to navigate in a 2D maze-like environment called XWORLD. In each session, the agent perceives a sequence of raw-pixel frames, a natural language command issued by a teacher, and a set of rewards. The agent learns the teacher's language from scratch in a grounded and compositional manner, such that after training it is able to correctly execute zero-shot commands: 1) the combination of words in the command never appeared before, and/or 2) the command contains new object concepts that are learned from another task but never learned from navigation. Our deep framework for the agent is trained end to end: it learns simultaneously the visual representations of the environment, the syntax and semantics of the language, and the action module that outputs actions. The zero-shot learning capability of our framework results from its compositionality and modularity with parameter tying. We visualize the intermediate outputs of the framework, demonstrating that the agent truly understands how to solve the problem. We believe that our results provide some preliminary insights on how to train an agent with similar abilities in a 3D environment.
Video Paragraph Captioning Using Hierarchical Recurrent Neural Networks
Apr 06, 2016
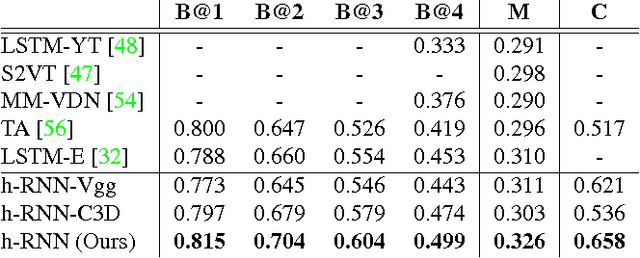
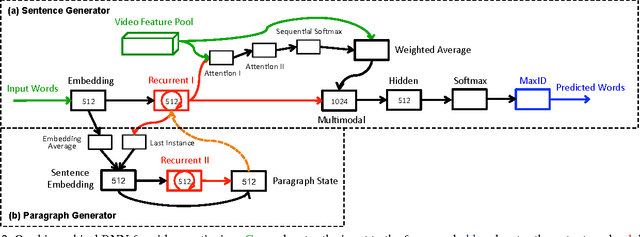
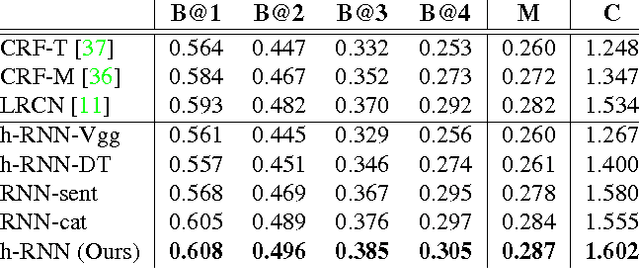
We present an approach that exploits hierarchical Recurrent Neural Networks (RNNs) to tackle the video captioning problem, i.e., generating one or multiple sentences to describe a realistic video. Our hierarchical framework contains a sentence generator and a paragraph generator. The sentence generator produces one simple short sentence that describes a specific short video interval. It exploits both temporal- and spatial-attention mechanisms to selectively focus on visual elements during generation. The paragraph generator captures the inter-sentence dependency by taking as input the sentential embedding produced by the sentence generator, combining it with the paragraph history, and outputting the new initial state for the sentence generator. We evaluate our approach on two large-scale benchmark datasets: YouTubeClips and TACoS-MultiLevel. The experiments demonstrate that our approach significantly outperforms the current state-of-the-art methods with BLEU@4 scores 0.499 and 0.305 respectively.
Sentence Directed Video Object Codetection
Jan 26, 2016

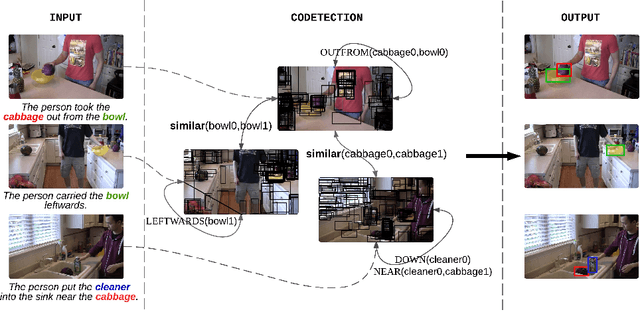
We tackle the problem of video object codetection by leveraging the weak semantic constraint implied by sentences that describe the video content. Unlike most existing work that focuses on codetecting large objects which are usually salient both in size and appearance, we can codetect objects that are small or medium sized. Our method assumes no human pose or depth information such as is required by the most recent state-of-the-art method. We employ weak semantic constraint on the codetection process by pairing the video with sentences. Although the semantic information is usually simple and weak, it can greatly boost the performance of our codetection framework by reducing the search space of the hypothesized object detections. Our experiment demonstrates an average IoU score of 0.423 on a new challenging dataset which contains 15 object classes and 150 videos with 12,509 frames in total, and an average IoU score of 0.373 on a subset of an existing dataset, originally intended for activity recognition, which contains 5 object classes and 75 videos with 8,854 frames in total.
Collecting and Annotating the Large Continuous Action Dataset
Nov 18, 2015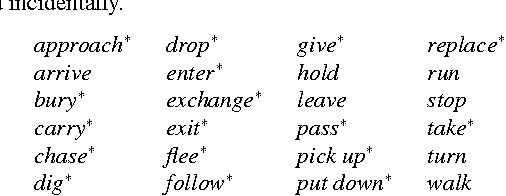

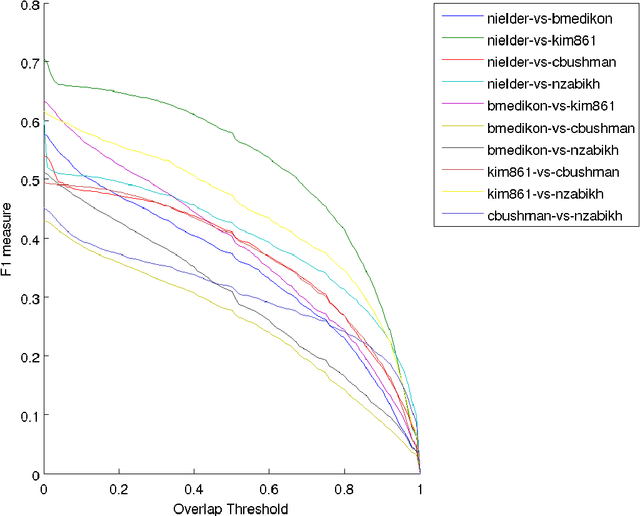

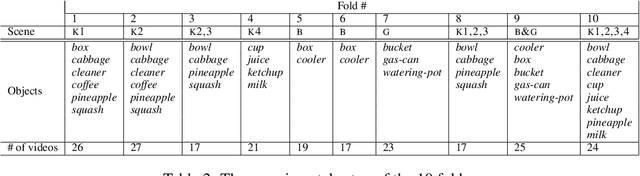
We make available to the community a new dataset to support action-recognition research. This dataset is different from prior datasets in several key ways. It is significantly larger. It contains streaming video with long segments containing multiple action occurrences that often overlap in space and/or time. All actions were filmed in the same collection of backgrounds so that background gives little clue as to action class. We had five humans replicate the annotation of temporal extent of action occurrences labeled with their class and measured a surprisingly low level of intercoder agreement. A baseline experiment shows that recent state-of-the-art methods perform poorly on this dataset. This suggests that this will be a challenging dataset to foster advances in action-recognition research. This manuscript serves to describe the novel content and characteristics of the LCA dataset, present the design decisions made when filming the dataset, and document the novel methods employed to annotate the dataset.
Robot Language Learning, Generation, and Comprehension
Aug 25, 2015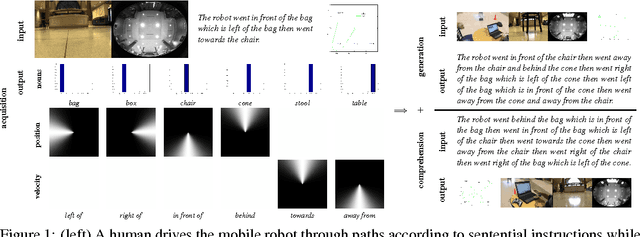



We present a unified framework which supports grounding natural-language semantics in robotic driving. This framework supports acquisition (learning grounded meanings of nouns and prepositions from human annotation of robotic driving paths), generation (using such acquired meanings to generate sentential description of new robotic driving paths), and comprehension (using such acquired meanings to support automated driving to accomplish navigational goals specified in natural language). We evaluate the performance of these three tasks by having independent human judges rate the semantic fidelity of the sentences associated with paths, achieving overall average correctness of 94.6% and overall average completeness of 85.6%.
A Faster Method for Tracking and Scoring Videos Corresponding to Sentences
Nov 14, 2014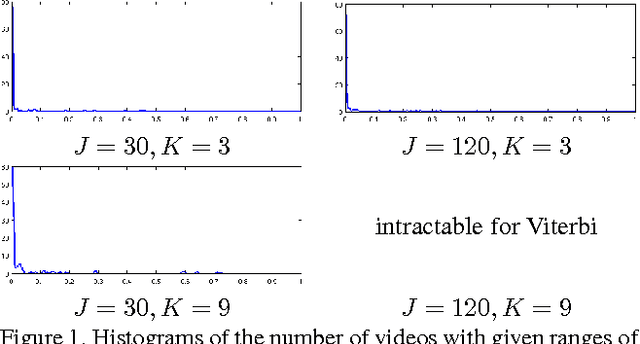

Prior work presented the sentence tracker, a method for scoring how well a sentence describes a video clip or alternatively how well a video clip depicts a sentence. We present an improved method for optimizing the same cost function employed by this prior work, reducing the space complexity from exponential in the sentence length to polynomial, as well as producing a qualitatively identical result in time polynomial in the sentence length instead of exponential. Since this new method is plug-compatible with the prior method, it can be used for the same applications: video retrieval with sentential queries, generating sentential descriptions of video clips, and focusing the attention of a tracker with a sentence, while allowing these applications to scale with significantly larger numbers of object detections, word meanings modeled with HMMs with significantly larger numbers of states, and significantly longer sentences, with no appreciable degradation in quality of results.
Discriminative Training: Learning to Describe Video with Sentences, from Video Described with Sentences
Jun 21, 2013
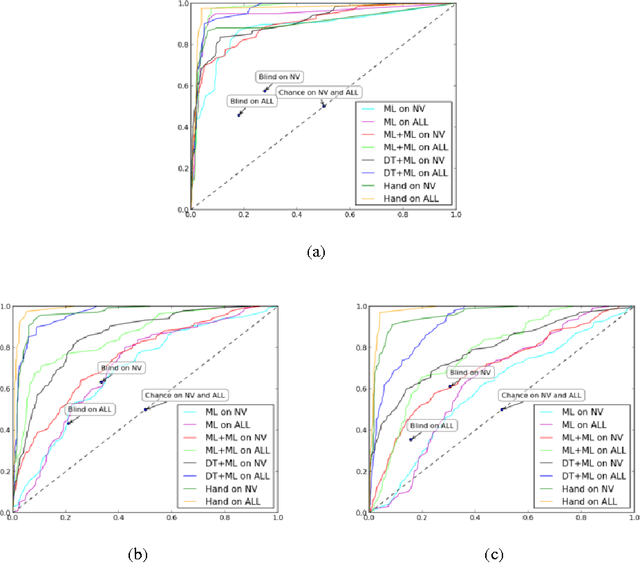
We present a method for learning word meanings from complex and realistic video clips by discriminatively training (DT) positive sentential labels against negative ones, and then use the trained word models to generate sentential descriptions for new video. This new work is inspired by recent work which adopts a maximum likelihood (ML) framework to address the same problem using only positive sentential labels. The new method, like the ML-based one, is able to automatically determine which words in the sentence correspond to which concepts in the video (i.e., ground words to meanings) in a weakly supervised fashion. While both DT and ML yield comparable results with sufficient training data, DT outperforms ML significantly with smaller training sets because it can exploit negative training labels to better constrain the learning problem.