 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Reinforcement Learning for Stochastic Hybrid Systems
Nov 11, 2021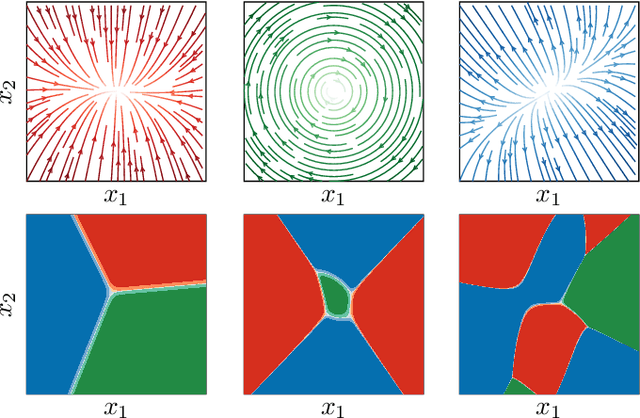
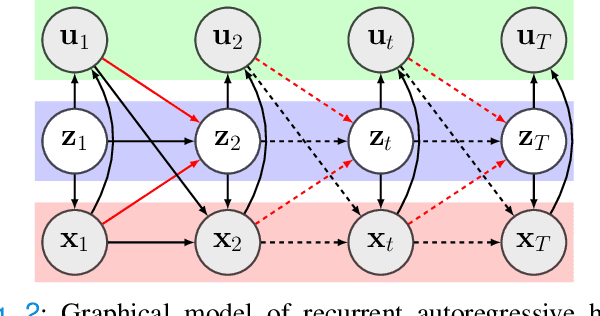
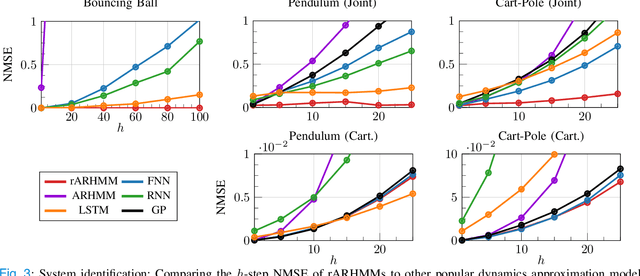
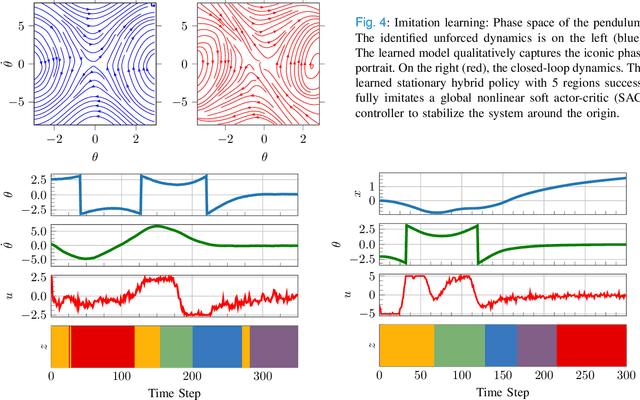
Optimal control of general nonlinear systems is a central challenge in automation. Data-driven approaches to control, enabled by powerful function approximators, have recently had great success in tackling challenging robotic applications. However, such methods often obscure the structure of dynamics and control behind black-box over-parameterized representations, thus limiting our ability to understand the closed-loop behavior. This paper adopts a hybrid-system view of nonlinear modeling and control that lends an explicit hierarchical structure to the problem and breaks down complex dynamics into simpler localized units. Therefore, we consider a sequence modeling paradigm that captures the temporal structure of the data and derive an expecation-maximization (EM) algorithm that automatically decomposes nonlinear dynamics into stochastic piecewise affine dynamical systems with nonlinear boundaries. Furthermore, we show that these time-series models naturally admit a closed-loop extension that we use to extract locally linear or polynomial feedback controllers from nonlinear experts via imitation learning. Finally, we introduce a novel hybrid realtive entropy policy search (Hb-REPS) technique that incorporates the hierarchical nature of hybrid systems and optimizes a set of time-invariant local feedback controllers derived from a locally polynomial approximation of a global value function.
Stochastic Control through Approximate Bayesian Input Inference
May 17, 2021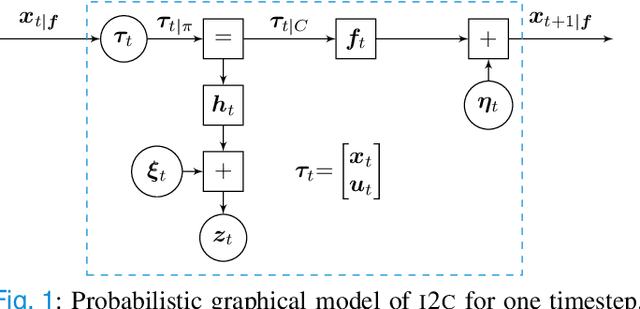
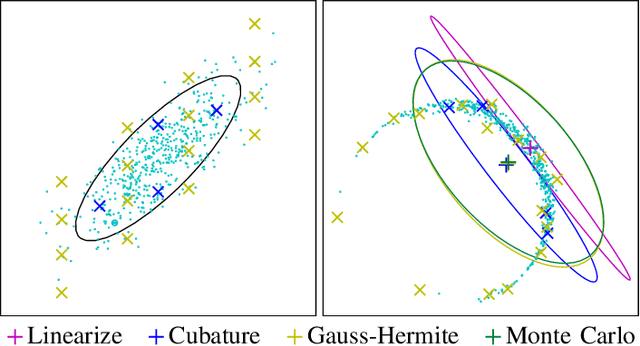
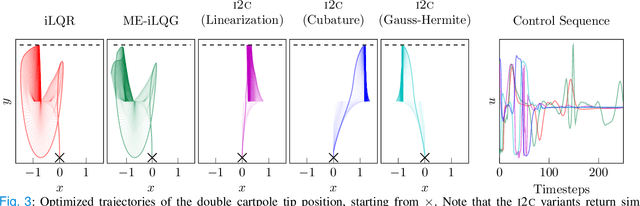
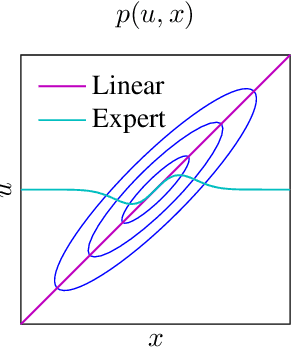
Optimal control under uncertainty is a prevailing challenge in control, due to the difficulty in producing tractable solutions for the stochastic optimization problem. By framing the control problem as one of input estimation, advanced approximate inference techniques can be used to handle the statistical approximations in a principled and practical manner. Analyzing the Gaussian setting, we present a solver capable of several stochastic control methods, and was found to be superior to popular baselines on nonlinear simulated tasks. We draw connections that relate this inference formulation to previous approaches for stochastic optimal control, and outline several advantages that this inference view brings due to its statistical nature.
Distributionally Robust Trajectory Optimization Under Uncertain Dynamics via Relative-Entropy Trust Regions
Mar 29, 2021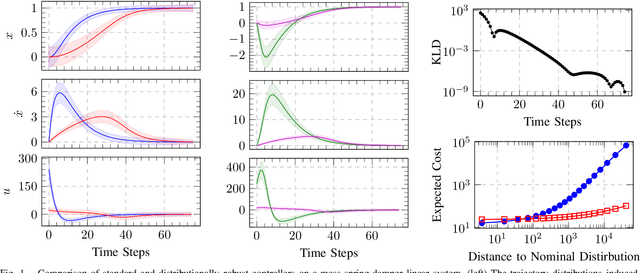
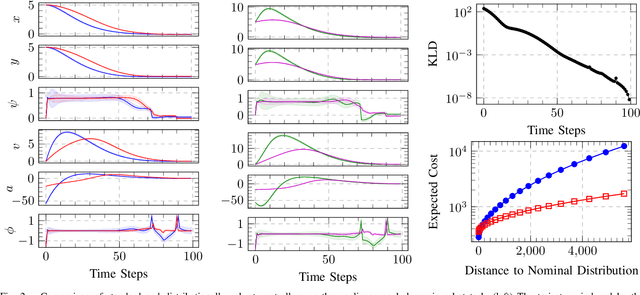
Trajectory optimization and model predictive control are essential techniques underpinning advanced robotic applications, ranging from autonomous driving to full-body humanoid control. State-of-the-art algorithms have focused on data-driven approaches that infer the system dynamics online and incorporate posterior uncertainty during planning and control. Despite their success, such approaches are still susceptible to catastrophic errors that may arise due to statistical learning biases, unmodeled disturbances or even directed adversarial attacks. In this paper, we tackle the problem of dynamics mismatch and propose a distributionally robust optimal control formulation that alternates between two relative-entropy trust region optimization problems. Our method finds the worst-case maximum-entropy Gaussian posterior over the dynamics parameters and the corresponding robust optimal policy. We show that our approach admits a closed-form backward-pass for a certain class of systems and demonstrate the resulting robustness on linear and nonlinear numerical examples.
A Probabilistic Interpretation of Self-Paced Learning with Applications to Reinforcement Learning
Feb 25, 2021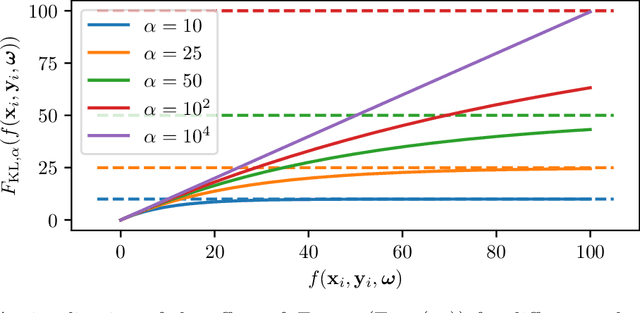
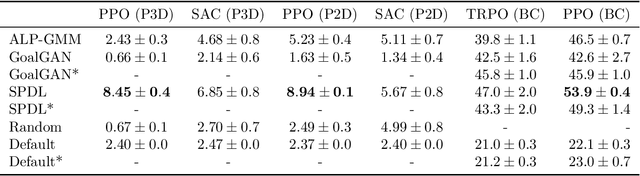
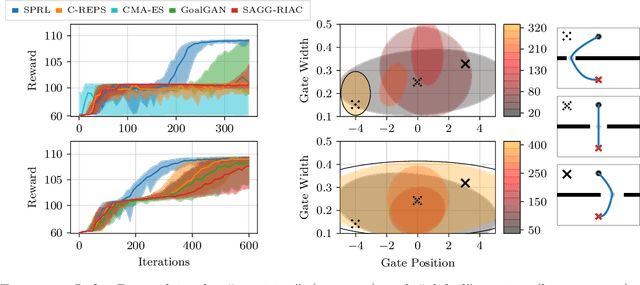
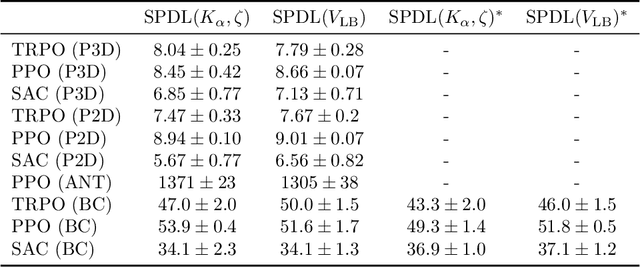
Across machine learning, the use of curricula has shown strong empirical potential to improve learning from data by avoiding local optima of training objectives. For reinforcement learning (RL), curricula are especially interesting, as the underlying optimization has a strong tendency to get stuck in local optima due to the exploration-exploitation trade-off. Recently, a number of approaches for an automatic generation of curricula for RL have been shown to increase performance while requiring less expert knowledge compared to manually designed curricula. However, these approaches are seldomly investigated from a theoretical perspective, preventing a deeper understanding of their mechanics. In this paper, we present an approach for automated curriculum generation in RL with a clear theoretical underpinning. More precisely, we formalize the well-known self-paced learning paradigm as inducing a distribution over training tasks, which trades off between task complexity and the objective to match a desired task distribution. Experiments show that training on this induced distribution helps to avoid poor local optima across RL algorithms in different tasks with uninformative rewards and challenging exploration requirements.
A Variational Infinite Mixture for Probabilistic Inverse Dynamics Learning
Nov 10, 2020
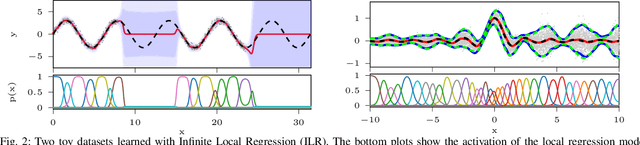
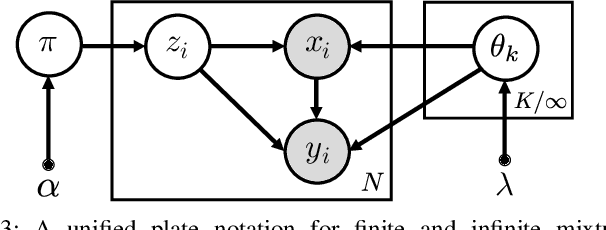
Probabilistic regression techniques in control and robotics applications have to fulfill different criteria of data-driven adaptability, computational efficiency, scalability to high dimensions, and the capacity to deal with different modalities in the data. Classical regressors usually fulfill only a subset of these properties. In this work, we extend seminal work on Bayesian nonparametric mixtures and derive an efficient variational Bayes inference technique for infinite mixtures of probabilistic local polynomial models with well-calibrated certainty quantification. We highlight the model's power in combining data-driven complexity adaptation, fast prediction and the ability to deal with discontinuous functions and heteroscedastic noise. We benchmark this technique on a range of large real inverse dynamics datasets, showing that the infinite mixture formulation is competitive with classical Local Learning methods and regularizes model complexity by adapting the number of components based on data and without relying on heuristics. Moreover, to showcase the practicality of the approach, we use the learned models for online inverse dynamics control of a Barret-WAM manipulator, significantly improving the trajectory tracking performance.
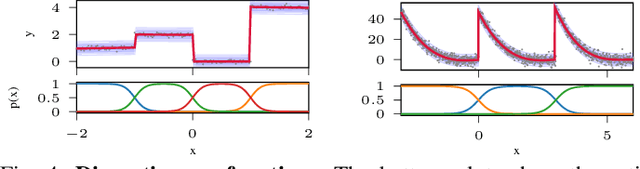
Hierarchical Decomposition of Nonlinear Dynamics and Control for System Identification and Policy Distillation
May 12, 2020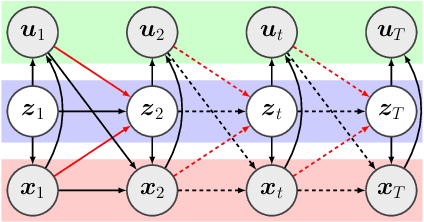
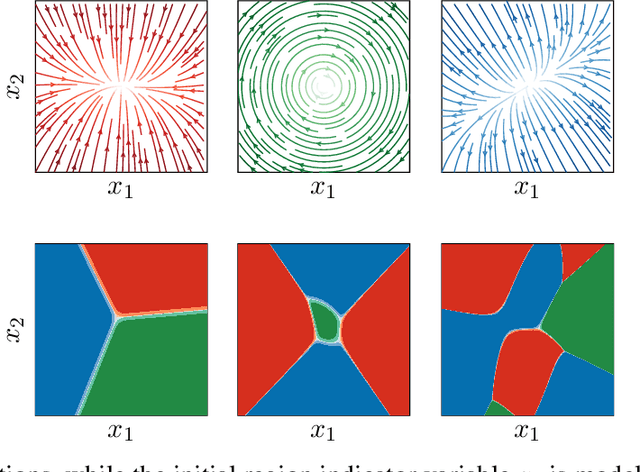
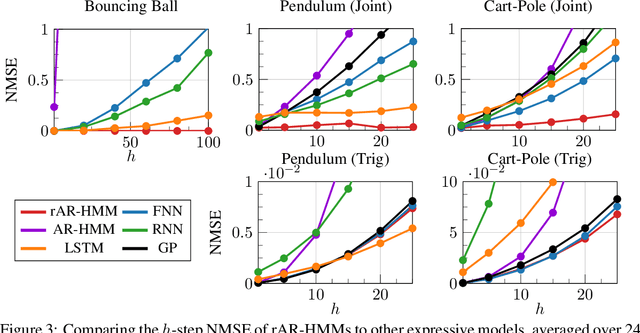
The control of nonlinear dynamical systems remains a major challenge for autonomous agents. Current trends in reinforcement learning (RL) focus on complex representations of dynamics and policies, which have yielded impressive results in solving a variety of hard control tasks. However, this new sophistication and extremely over-parameterized models have come with the cost of an overall reduction in our ability to interpret the resulting policies. In this paper, we take inspiration from the control community and apply the principles of hybrid switching systems in order to break down complex dynamics into simpler components. We exploit the rich representational power of probabilistic graphical models and derive an expectation-maximization (EM) algorithm for learning a sequence model to capture the temporal structure of the data and automatically decompose nonlinear dynamics into stochastic switching linear dynamical systems. Moreover, we show how this framework of switching models enables extracting hierarchies of Markovian and auto-regressive locally linear controllers from nonlinear experts in an imitation learning scenario.
A Nonparametric Off-Policy Policy Gradient
Feb 11, 2020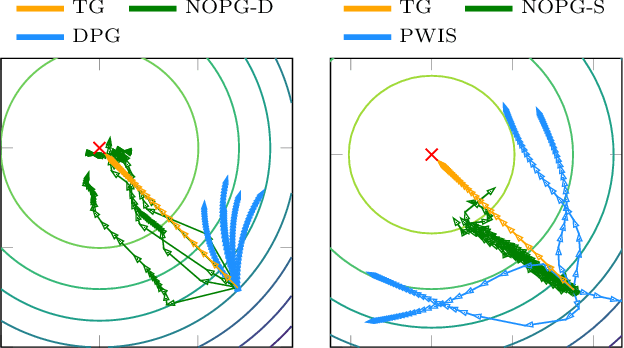

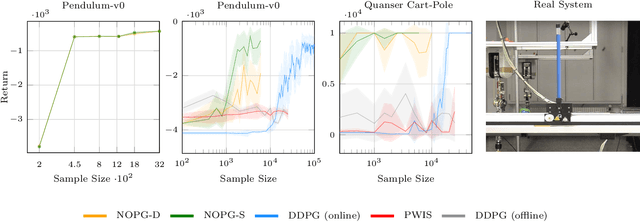
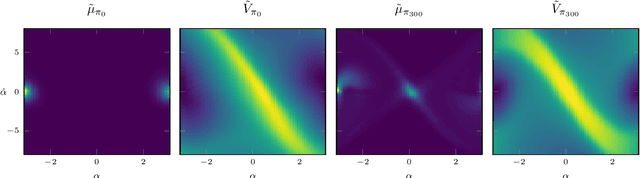
Reinforcement learning (RL) algorithms still suffer from high sample complexity despite outstanding recent successes. The need for intensive interactions with the environment is especially observed in many widely popular policy gradient algorithms that perform updates using on-policy samples. The price of such inefficiency becomes evident in real-world scenarios such as interaction-driven robot learning, where the success of RL has been rather limited. We address this issue by building on the general sample efficiency of off-policy algorithms. With nonparametric regression and density estimation methods we construct a nonparametric Bellman equation in a principled manner, which allows us to obtain closed-form estimates of the value function, and to analytically express the full policy gradient. We provide a theoretical analysis of our estimate to show that it is consistent under mild smoothness assumptions and empirically show that our approach has better sample efficiency than state-of-the-art policy gradient methods.
Receding Horizon Curiosity
Oct 08, 2019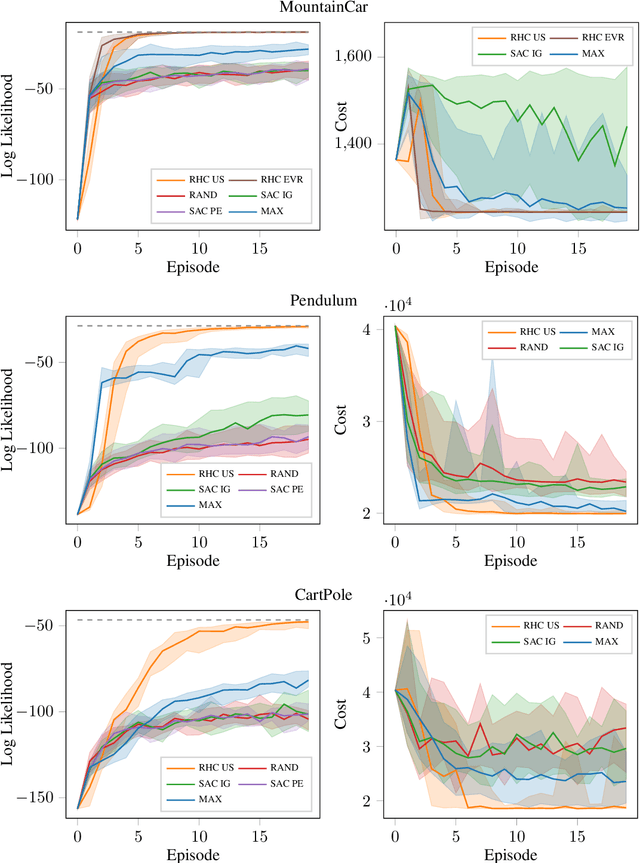
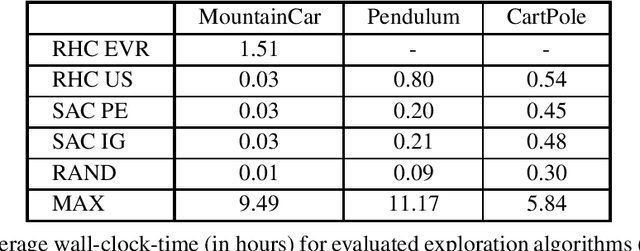
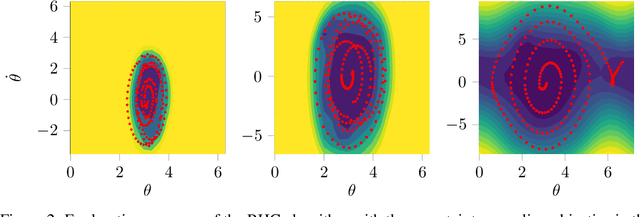
Sample-efficient exploration is crucial not only for discovering rewarding experiences but also for adapting to environment changes in a task-agnostic fashion. A principled treatment of the problem of optimal input synthesis for system identification is provided within the framework of sequential Bayesian experimental design. In this paper, we present an effective trajectory-optimization-based approximate solution of this otherwise intractable problem that models optimal exploration in an unknown Markov decision process (MDP). By interleaving episodic exploration with Bayesian nonlinear system identification, our algorithm takes advantage of the inductive bias to explore in a directed manner, without assuming prior knowledge of the MDP. Empirical evaluations indicate a clear advantage of the proposed algorithm in terms of the rate of convergence and the final model fidelity when compared to intrinsic-motivation-based algorithms employing exploration bonuses such as prediction error and information gain. Moreover, our method maintains a computational advantage over a recent model-based active exploration (MAX) algorithm, by focusing on the information gain along trajectories instead of seeking a global exploration policy. A reference implementation of our algorithm and the conducted experiments is publicly available.
Stochastic Optimal Control as Approximate Input Inference
Oct 07, 2019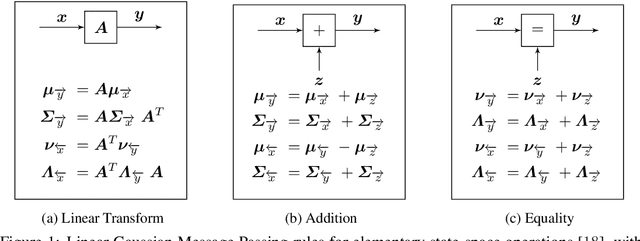

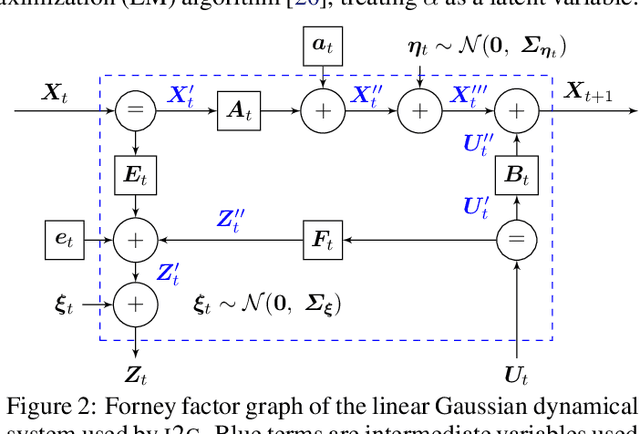
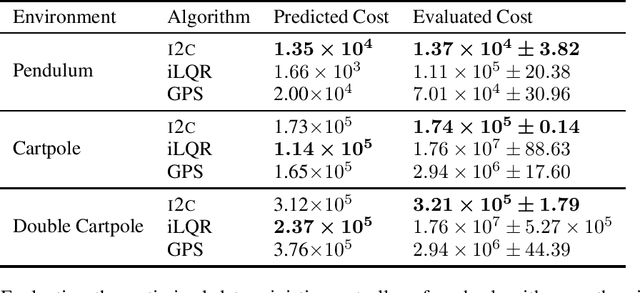
Optimal control of stochastic nonlinear dynamical systems is a major challenge in the domain of robot learning. Given the intractability of the global control problem, state-of-the-art algorithms focus on approximate sequential optimization techniques, that heavily rely on heuristics for regularization in order to achieve stable convergence. By building upon the duality between inference and control, we develop the view of Optimal Control as Input Estimation, devising a probabilistic stochastic optimal control formulation that iteratively infers the optimal input distributions by minimizing an upper bound of the control cost. Inference is performed through Expectation Maximization and message passing on a probabilistic graphical model of the dynamical system, and time-varying linear Gaussian feedback controllers are extracted from the joint state-action distribution. This perspective incorporates uncertainty quantification, effective initialization through priors, and the principled regularization inherent to the Bayesian treatment. Moreover, it can be shown that for deterministic linearized systems, our framework derives the maximum entropy linear quadratic optimal control law. We provide a complete and detailed derivation of our probabilistic approach and highlight its advantages in comparison to other deterministic and probabilistic solvers.
Self-Paced Contextual Reinforcement Learning
Oct 07, 2019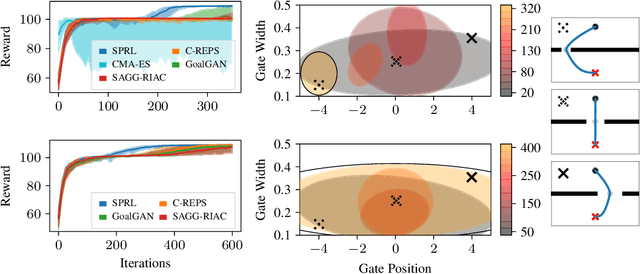

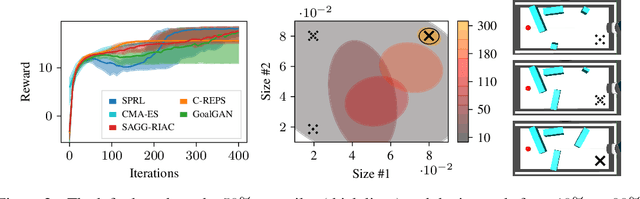
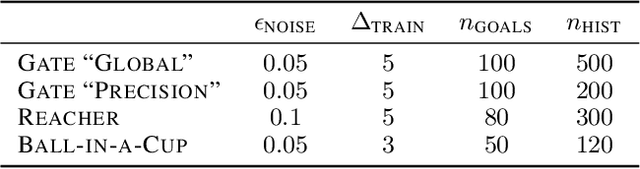
Generalization and adaptation of learned skills to novel situations is a core requirement for intelligent autonomous robots. Although contextual reinforcement learning provides a principled framework for learning and generalization of behaviors across related tasks, it generally relies on uninformed sampling of environments from an unknown, uncontrolled context distribution, thus missing the benefits of structured, sequential learning. We introduce a novel relative entropy reinforcement learning algorithm that gives the agent the freedom to control the intermediate task distribution, allowing for its gradual progression towards the target context distribution. Empirical evaluation shows that the proposed curriculum learning scheme drastically improves sample efficiency and enables learning in scenarios with both broad and sharp target context distributions in which classical approaches perform sub-optimally.