 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Mean Shift for Representation Learning
Oct 19, 2021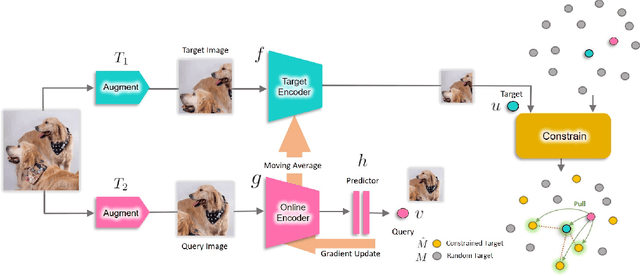
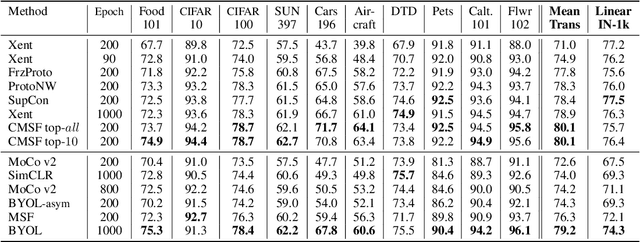

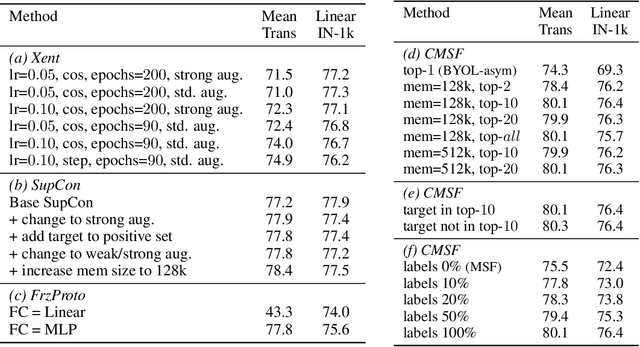
We are interested in representation learning from labeled or unlabeled data. Inspired by recent success of self-supervised learning (SSL), we develop a non-contrastive representation learning method that can exploit additional knowledge. This additional knowledge may come from annotated labels in the supervised setting or an SSL model from another modality in the SSL setting. Our main idea is to generalize the mean-shift algorithm by constraining the search space of nearest neighbors, resulting in semantically purer representations. Our method simply pulls the embedding of an instance closer to its nearest neighbors in a search space that is constrained using the additional knowledge. By leveraging this non-contrastive loss, we show that the supervised ImageNet-1k pretraining with our method results in better transfer performance as compared to the baselines. Further, we demonstrate that our method is relatively robust to label noise. Finally, we show that it is possible to use the noisy constraint across modalities to train self-supervised video models.
Consistent Explanations by Contrastive Learning
Oct 01, 2021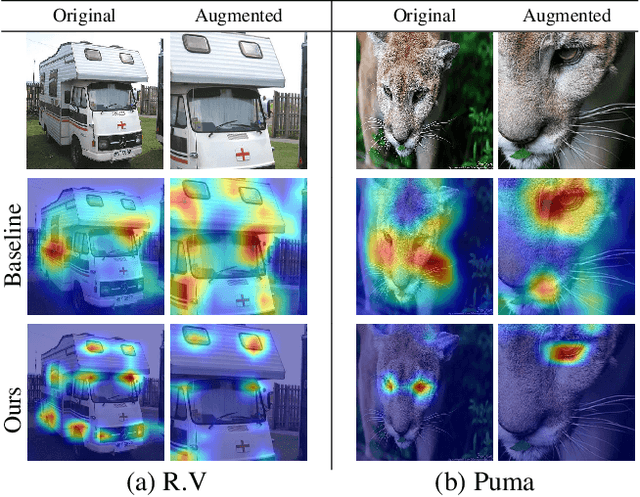
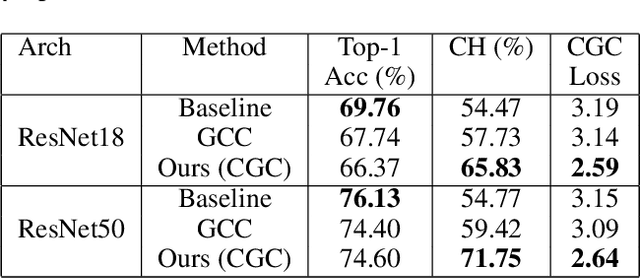
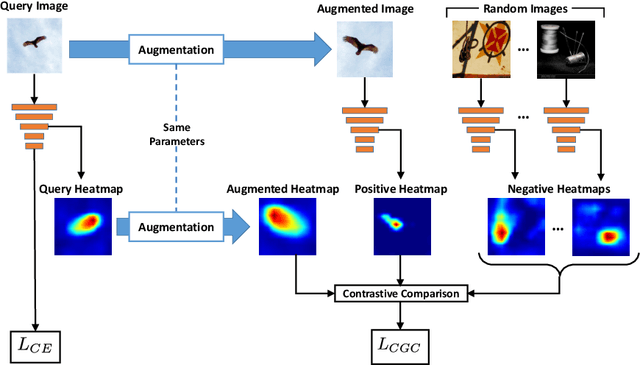

Understanding and explaining the decisions of neural networks are critical to building trust, rather than relying on them as black box algorithms. Post-hoc evaluation techniques, such as Grad-CAM, enable humans to inspect the spatial regions responsible for a particular network decision. However, it is shown that such explanations are not always consistent with human priors, such as consistency across image transformations. Given an interpretation algorithm, e.g., Grad-CAM, we introduce a novel training method to train the model to produce more consistent explanations. Since obtaining the ground truth for a desired model interpretation is not a well-defined task, we adopt ideas from contrastive self-supervised learning and apply them to the interpretations of the model rather than its embeddings. Explicitly training the network to produce more reasonable interpretations and subsequently evaluating those interpretations will enhance our ability to trust the network. We show that our method, Contrastive Grad-CAM Consistency (CGC), results in Grad-CAM interpretation heatmaps that are consistent with human annotations while still achieving comparable classification accuracy. Moreover, since our method can be seen as a form of regularizer, on limited-data fine-grained classification settings, our method outperforms the baseline classification accuracy on Caltech-Birds, Stanford Cars, VGG Flowers, and FGVC-Aircraft datasets. In addition, because our method does not rely on annotations, it allows for the incorporation of unlabeled data into training, which enables better generalization of the model. Our code is publicly available.
Backdoor Attacks on Self-Supervised Learning
May 21, 2021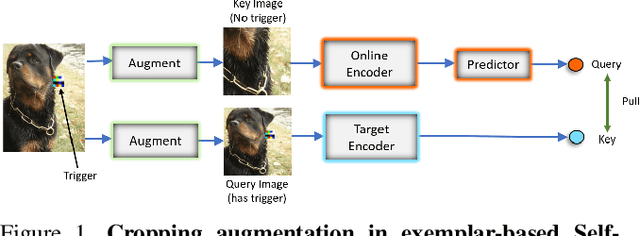
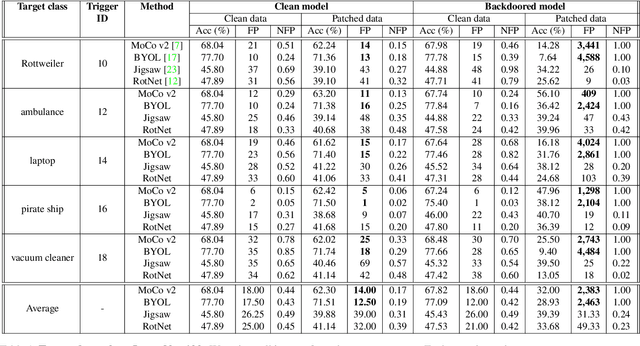
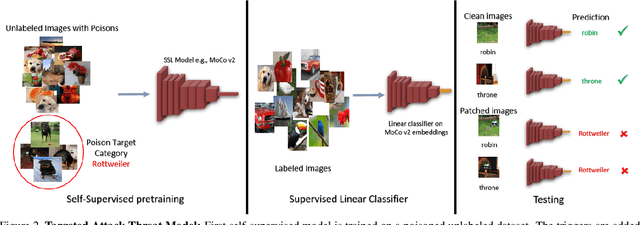
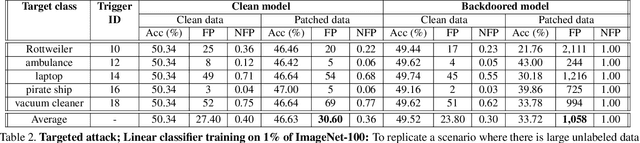
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack. Our code is available here: https://github.com/UMBCvision/SSL-Backdoor .
Mean Shift for Self-Supervised Learning
May 15, 2021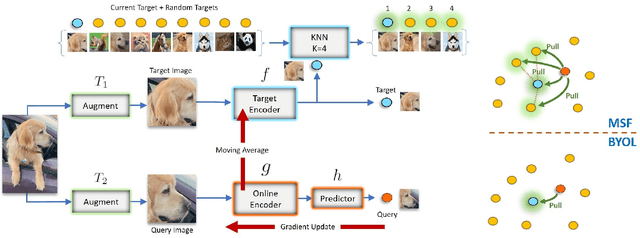
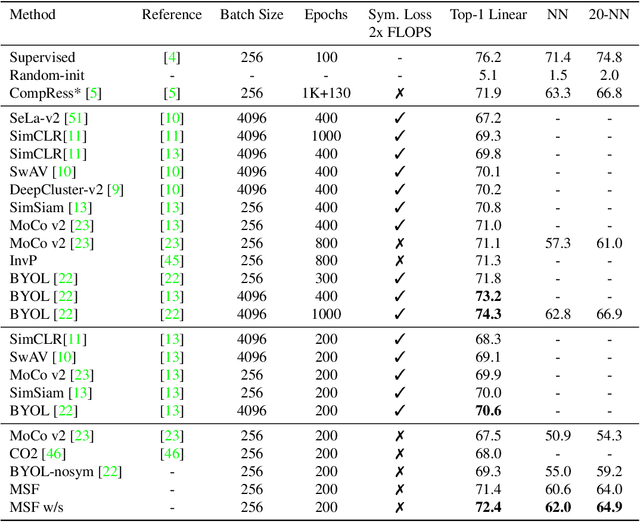

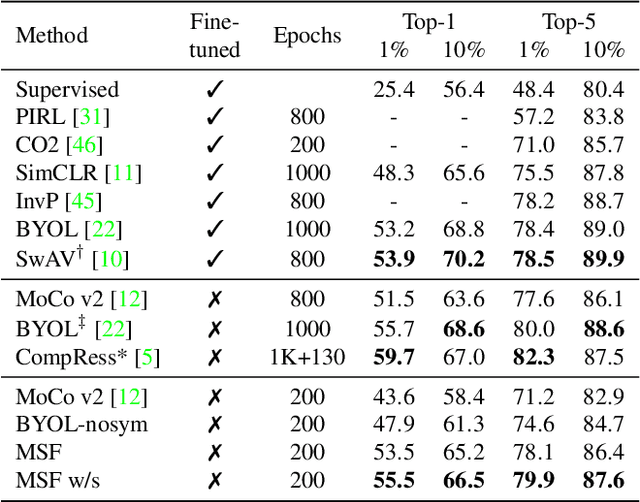
Most recent self-supervised learning (SSL) algorithms learn features by contrasting between instances of images or by clustering the images and then contrasting between the image clusters. We introduce a simple mean-shift algorithm that learns representations by grouping images together without contrasting between them or adopting much of prior on the structure of the clusters. We simply "shift" the embedding of each image to be close to the "mean" of its neighbors. Since in our setting, the closest neighbor is always another augmentation of the same image, our model will be identical to BYOL when using only one nearest neighbor instead of 5 as used in our experiments. Our model achieves 72.4% on ImageNet linear evaluation with ResNet50 at 200 epochs outperforming BYOL. Our code is available here: https://github.com/UMBCvision/MSF
ISD: Self-Supervised Learning by Iterative Similarity Distillation
Dec 16, 2020
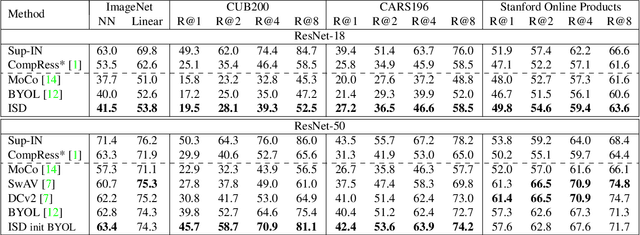

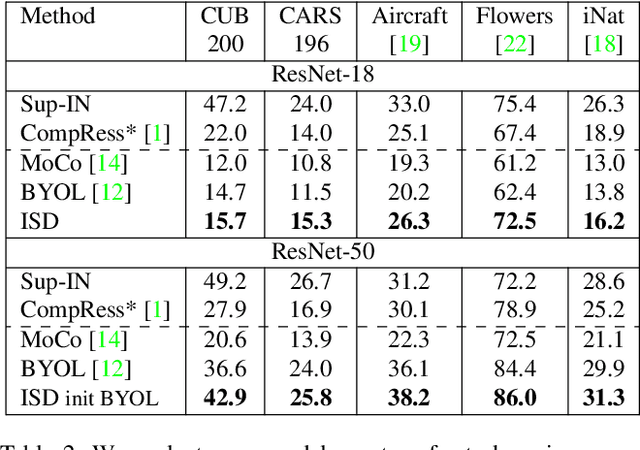
Recently, contrastive learning has achieved great results in self-supervised learning, where the main idea is to push two augmentations of an image (positive pairs) closer compared to other random images (negative pairs). We argue that not all random images are equal. Hence, we introduce a self supervised learning algorithm where we use a soft similarity for the negative images rather than a binary distinction between positive and negative pairs. We iteratively distill a slowly evolving teacher model to the student model by capturing the similarity of a query image to some random images and transferring that knowledge to the student. We argue that our method is less constrained compared to recent contrastive learning methods, so it can learn better features. Specifically, our method should handle unbalanced and unlabeled data better than existing contrastive learning methods, because the randomly chosen negative set might include many samples that are semantically similar to the query image. In this case, our method labels them as highly similar while standard contrastive methods label them as negative pairs. Our method achieves better results compared to state-of-the-art models like BYOL and MoCo on transfer learning settings. We also show that our method performs better in the settings where the unlabeled data is unbalanced. Our code is available here: https://github.com/UMBCvision/ISD.
COOT: Cooperative Hierarchical Transformer for Video-Text Representation Learning
Nov 01, 2020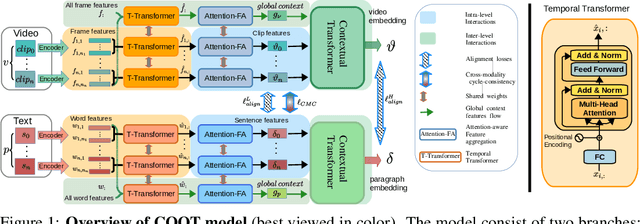
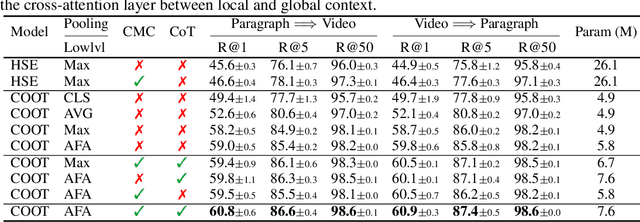
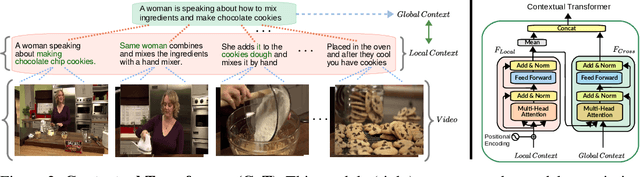
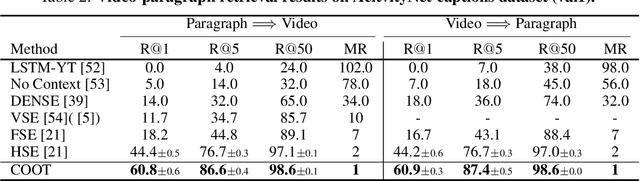
Many real-world video-text tasks involve different levels of granularity, such as frames and words, clip and sentences or videos and paragraphs, each with distinct semantics. In this paper, we propose a Cooperative hierarchical Transformer (COOT) to leverage this hierarchy information and model the interactions between different levels of granularity and different modalities. The method consists of three major components: an attention-aware feature aggregation layer, which leverages the local temporal context (intra-level, e.g., within a clip), a contextual transformer to learn the interactions between low-level and high-level semantics (inter-level, e.g. clip-video, sentence-paragraph), and a cross-modal cycle-consistency loss to connect video and text. The resulting method compares favorably to the state of the art on several benchmarks while having few parameters. All code is available open-source at https://github.com/gingsi/coot-videotext
CompRess: Self-Supervised Learning by Compressing Representations
Oct 28, 2020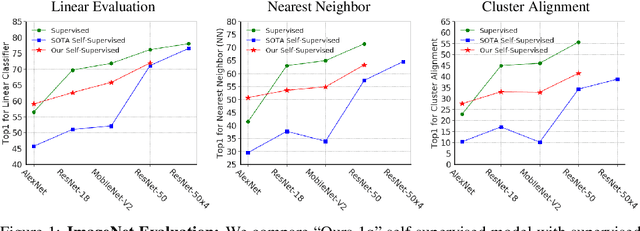
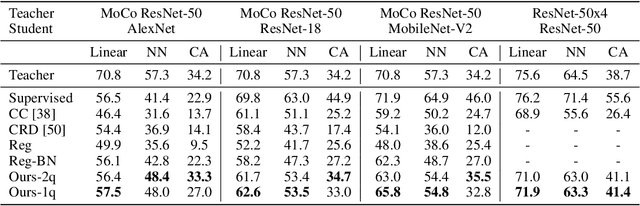
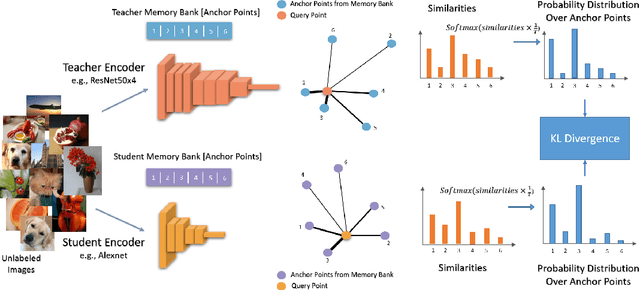

Self-supervised learning aims to learn good representations with unlabeled data. Recent works have shown that larger models benefit more from self-supervised learning than smaller models. As a result, the gap between supervised and self-supervised learning has been greatly reduced for larger models. In this work, instead of designing a new pseudo task for self-supervised learning, we develop a model compression method to compress an already learned, deep self-supervised model (teacher) to a smaller one (student). We train the student model so that it mimics the relative similarity between the data points in the teacher's embedding space. For AlexNet, our method outperforms all previous methods including the fully supervised model on ImageNet linear evaluation (59.0% compared to 56.5%) and on nearest neighbor evaluation (50.7% compared to 41.4%). To the best of our knowledge, this is the first time a self-supervised AlexNet has outperformed supervised one on ImageNet classification. Our code is available here: https://github.com/UMBCvision/CompRess
A simple baseline for domain adaptation using rotation prediction
Dec 26, 2019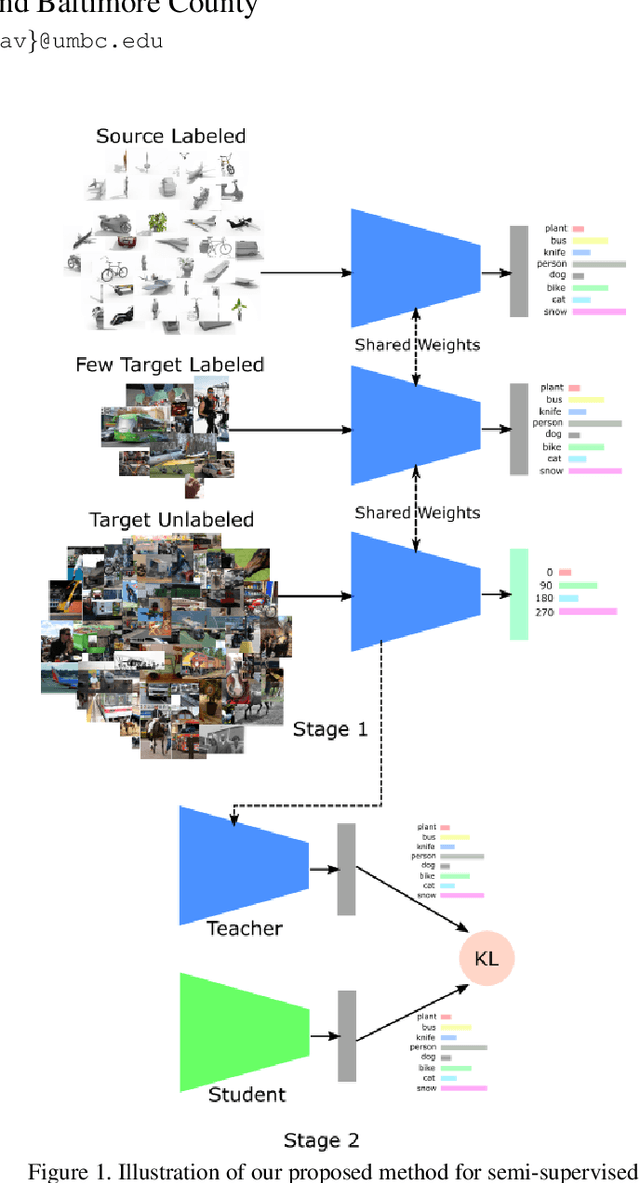
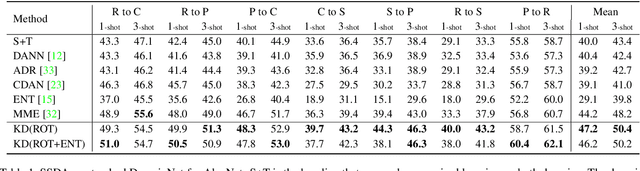

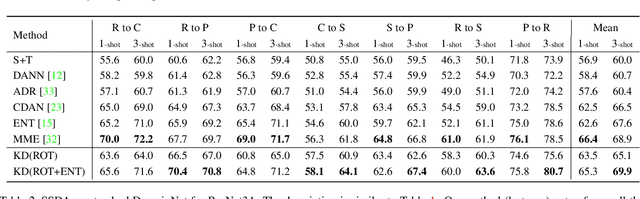
Recently, domain adaptation has become a hot research area with lots of applications. The goal is to adapt a model trained in one domain to another domain with scarce annotated data. We propose a simple yet effective method based on self-supervised learning that outperforms or is on par with most state-of-the-art algorithms, e.g. adversarial domain adaptation. Our method involves two phases: predicting random rotations (self-supervised) on the target domain along with correct labels for the source domain (supervised), and then using self-distillation on the target domain. Our simple method achieves state-of-the-art results on semi-supervised domain adaptation on DomainNet dataset. Further, we observe that the unlabeled target datasets of popular domain adaptation benchmarks do not contain any categories apart from testing categories. We believe this introduces a bias that does not exist in many real applications. We show that removing this bias from the unlabeled data results in a large drop in performance of state-of-the-art methods, while our simple method is relatively robust.
Adversarial Patches Exploiting Contextual Reasoning in Object Detection
Sep 30, 2019


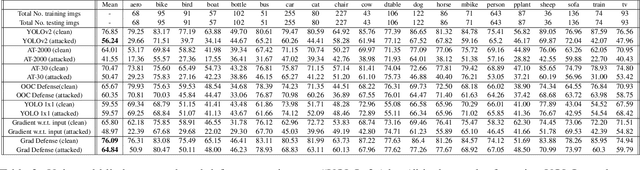
The usefulness of spatial context in most fast object detection algorithms that do a single forward pass per image is well known where they utilize context to improve their accuracy. In fact, they must do it to increase the inference speed by processing the image just once. We show that an adversary can attack the model by exploiting contextual reasoning. We develop adversarial attack algorithms that make an object detector blind to a particular category chosen by the adversary even though the patch does not overlap with the missed detections. We also show that limiting the use of contextual reasoning in learning the object detector acts as a form of defense that improves the accuracy of the detector after an attack. We believe defending against our practical adversarial attack algorithms is not easy and needs attention from the research community.
Hidden Trigger Backdoor Attacks
Sep 30, 2019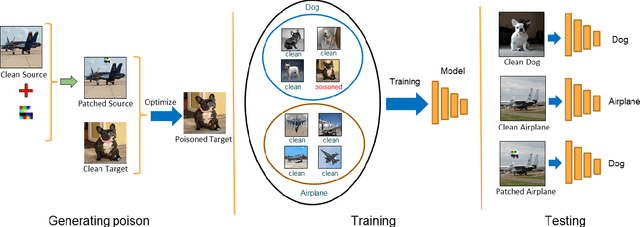


With the success of deep learning algorithms in various domains, studying adversarial attacks to secure deep models in real world applications has become an important research topic. Backdoor attacks are a form of adversarial attacks on deep networks where the attacker provides poisoned data to the victim to train the model with, and then activates the attack by showing a specific trigger pattern at the test time. Most state-of-the-art backdoor attacks either provide mislabeled poisoning data that is possible to identify by visual inspection, reveal the trigger in the poisoned data, or use noise and perturbation to hide the trigger. We propose a novel form of backdoor attack where poisoned data look natural with correct labels and also more importantly, the attacker hides the trigger in the poisoned data and keeps the trigger secret until the test time. We perform an extensive study on various image classification settings and show that our attack can fool the model by pasting the trigger at random locations on unseen images although the model performs well on clean data. We also show that our proposed attack cannot be easily defended using a state-of-the-art defense algorithm for backdoor attacks.