 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Approach to Adversarial Robustness in Few-shot Image Classification
Apr 11, 2022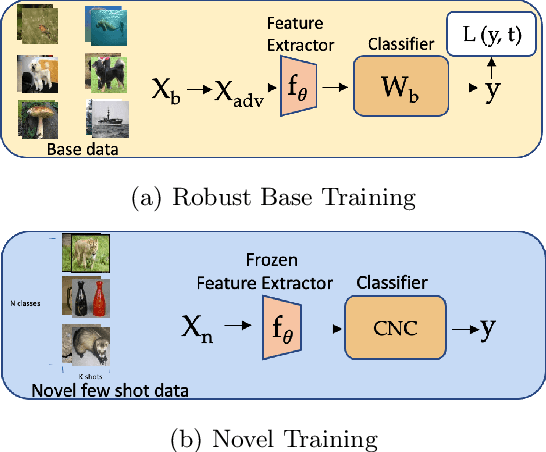
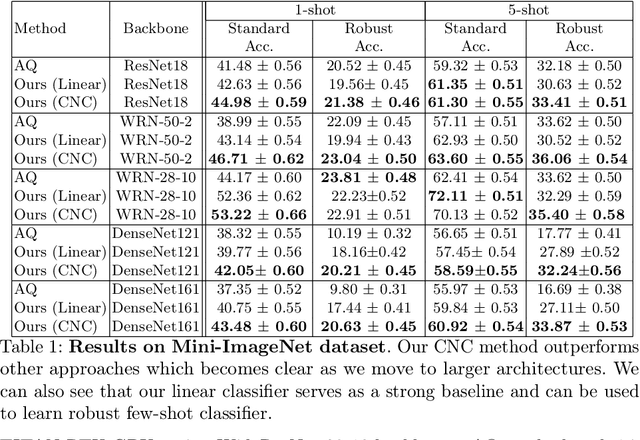
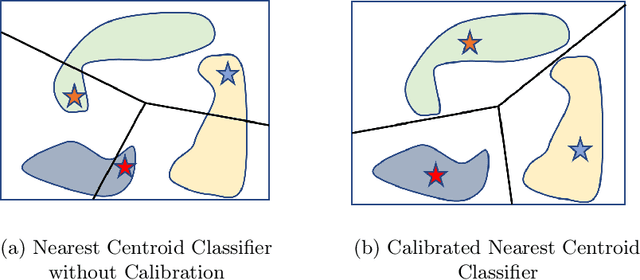
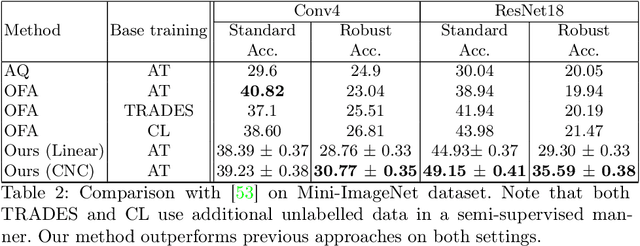
Few-shot image classification, where the goal is to generalize to tasks with limited labeled data, has seen great progress over the years. However, the classifiers are vulnerable to adversarial examples, posing a question regarding their generalization capabilities. Recent works have tried to combine meta-learning approaches with adversarial training to improve the robustness of few-shot classifiers. We show that a simple transfer-learning based approach can be used to train adversarially robust few-shot classifiers. We also present a method for novel classification task based on calibrating the centroid of the few-shot category towards the base classes. We show that standard adversarial training on base categories along with calibrated centroid-based classifier in the novel categories, outperforms or is on-par with state-of-the-art advanced methods on standard benchmarks for few-shot learning. Our method is simple, easy to scale, and with little effort can lead to robust few-shot classifiers. Code is available here: \url{https://github.com/UCDvision/Simple_few_shot.git}
Sparsity and Heterogeneous Dropout for Continual Learning in the Null Space of Neural Activations
Mar 12, 2022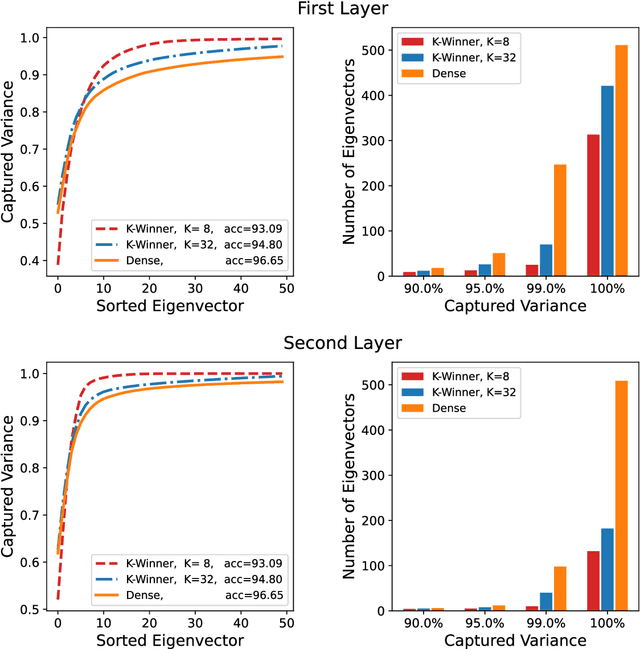
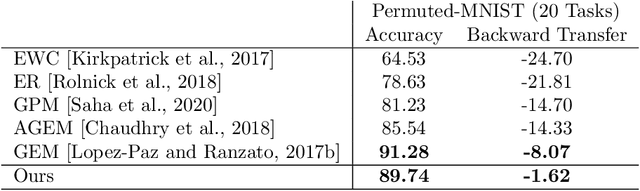
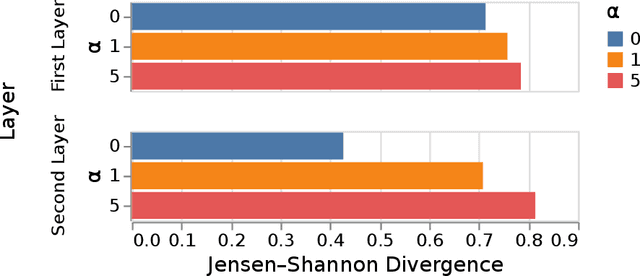
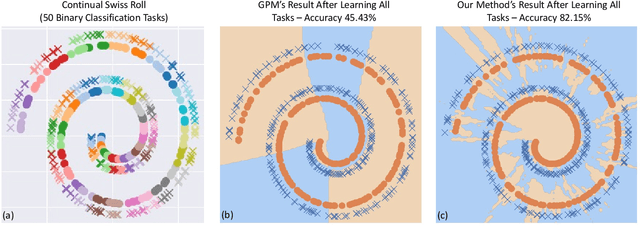
Continual/lifelong learning from a non-stationary input data stream is a cornerstone of intelligence. Despite their phenomenal performance in a wide variety of applications, deep neural networks are prone to forgetting their previously learned information upon learning new ones. This phenomenon is called "catastrophic forgetting" and is deeply rooted in the stability-plasticity dilemma. Overcoming catastrophic forgetting in deep neural networks has become an active field of research in recent years. In particular, gradient projection-based methods have recently shown exceptional performance at overcoming catastrophic forgetting. This paper proposes two biologically-inspired mechanisms based on sparsity and heterogeneous dropout that significantly increase a continual learner's performance over a long sequence of tasks. Our proposed approach builds on the Gradient Projection Memory (GPM) framework. We leverage K-winner activations in each layer of a neural network to enforce layer-wise sparse activations for each task, together with a between-task heterogeneous dropout that encourages the network to use non-overlapping activation patterns between different tasks. In addition, we introduce Continual Swiss Roll as a lightweight and interpretable -- yet challenging -- synthetic benchmark for continual learning. Lastly, we provide an in-depth analysis of our proposed method and demonstrate a significant performance boost on various benchmark continual learning problems.
Amenable Sparse Network Investigator
Feb 18, 2022As the optimization problem of pruning a neural network is nonconvex and the strategies are only guaranteed to find local solutions, a good initialization becomes paramount. To this end, we present the Amenable Sparse Network Investigator ASNI algorithm that learns a sparse network whose initialization is compressed. The learned sparse structure found by ASNI is amenable since its corresponding initialization, which is also learned by ASNI, consists of only 2L numbers, where L is the number of layers. Requiring just a few numbers for parameter initialization of the learned sparse network makes the sparse network amenable. The learned initialization set consists of L signed pairs that act as the centroids of parameter values of each layer. These centroids are learned by the ASNI algorithm after only one single round of training. We experimentally show that the learned centroids are sufficient to initialize the nonzero parameters of the learned sparse structure in order to achieve approximately the accuracy of non-sparse network. We also empirically show that in order to learn the centroids, one needs to prune the network globally and gradually. Hence, for parameter pruning we propose a novel strategy based on a sigmoid function that specifies the sparsity percentage across the network globally. Then, pruning is done magnitude-wise and after each epoch of training. We have performed a series of experiments utilizing networks such as ResNets, VGG-style, small convolutional, and fully connected ones on ImageNet, CIFAR10, and MNIST datasets.
SimReg: Regression as a Simple Yet Effective Tool for Self-supervised Knowledge Distillation
Jan 13, 2022
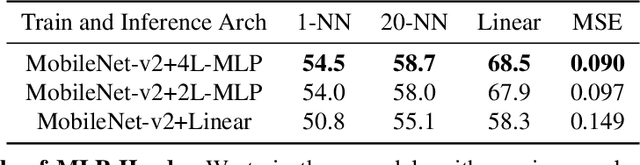

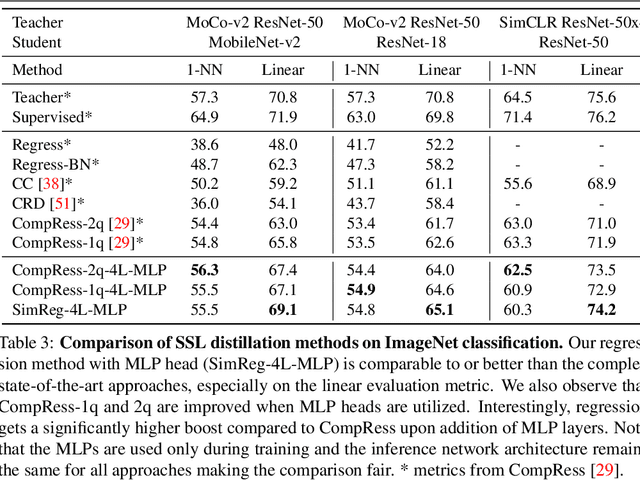
Feature regression is a simple way to distill large neural network models to smaller ones. We show that with simple changes to the network architecture, regression can outperform more complex state-of-the-art approaches for knowledge distillation from self-supervised models. Surprisingly, the addition of a multi-layer perceptron head to the CNN backbone is beneficial even if used only during distillation and discarded in the downstream task. Deeper non-linear projections can thus be used to accurately mimic the teacher without changing inference architecture and time. Moreover, we utilize independent projection heads to simultaneously distill multiple teacher networks. We also find that using the same weakly augmented image as input for both teacher and student networks aids distillation. Experiments on ImageNet dataset demonstrate the efficacy of the proposed changes in various self-supervised distillation settings.
A Fistful of Words: Learning Transferable Visual Models from Bag-of-Words Supervision
Jan 06, 2022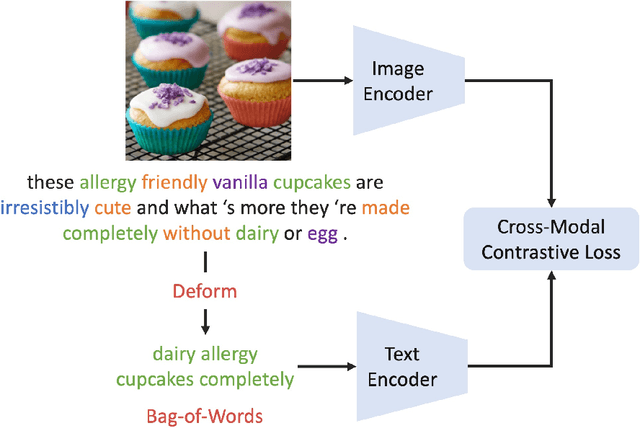
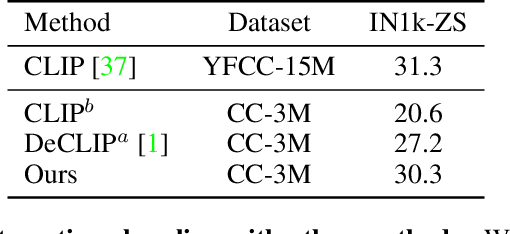

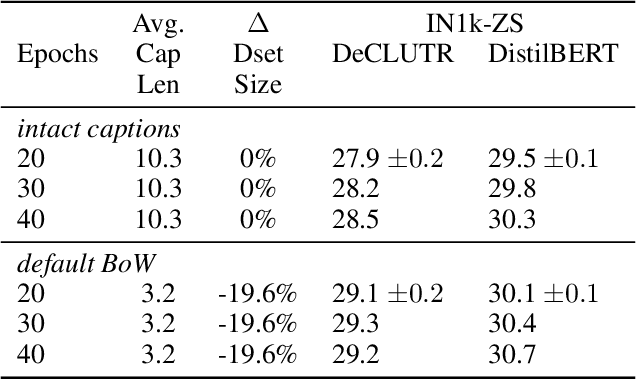
Using natural language as a supervision for training visual recognition models holds great promise. Recent works have shown that if such supervision is used in the form of alignment between images and captions in large training datasets, then the resulting aligned models perform well on zero-shot classification as downstream tasks2. In this paper, we focus on teasing out what parts of the language supervision are essential for training zero-shot image classification models. Through extensive and careful experiments, we show that: 1) A simple Bag-of-Words (BoW) caption could be used as a replacement for most of the image captions in the dataset. Surprisingly, we observe that this approach improves the zero-shot classification performance when combined with word balancing. 2) Using a BoW pretrained model, we can obtain more training data by generating pseudo-BoW captions on images that do not have a caption. Models trained on images with real and pseudo-BoW captions achieve stronger zero-shot performance. On ImageNet-1k zero-shot evaluation, our best model, that uses only 3M image-caption pairs, performs on-par with a CLIP model trained on 15M image-caption pairs (31.5% vs 31.3%).
Constrained Mean Shift Using Distant Yet Related Neighbors for Representation Learning
Dec 08, 2021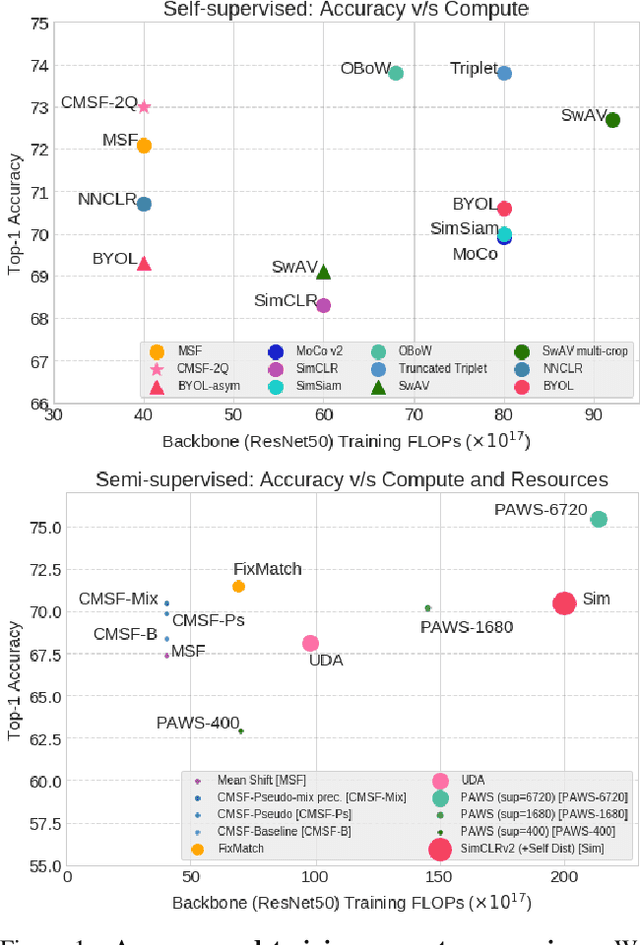
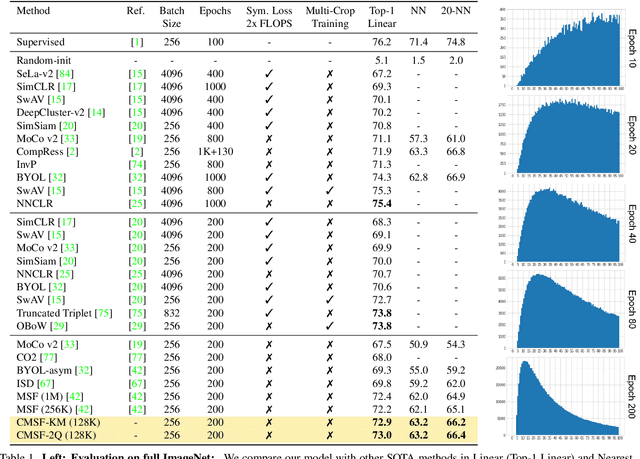
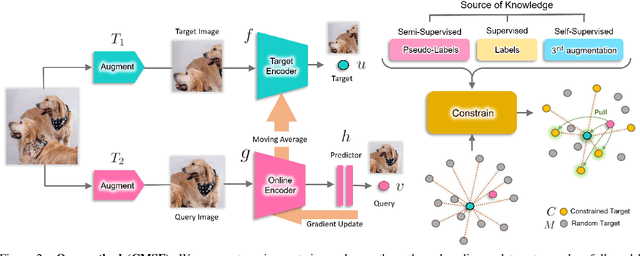
We are interested in representation learning in self-supervised, supervised, or semi-supervised settings. The prior work on applying mean-shift idea for self-supervised learning, MSF, generalizes the BYOL idea by pulling a query image to not only be closer to its other augmentation, but also to the nearest neighbors (NNs) of its other augmentation. We believe the learning can benefit from choosing far away neighbors that are still semantically related to the query. Hence, we propose to generalize MSF algorithm by constraining the search space for nearest neighbors. We show that our method outperforms MSF in SSL setting when the constraint utilizes a different augmentation of an image, and outperforms PAWS in semi-supervised setting with less training resources when the constraint ensures the NNs have the same pseudo-label as the query.
STAF: A Spatio-Temporal Attention Fusion Network for Few-shot Video Classification
Dec 08, 2021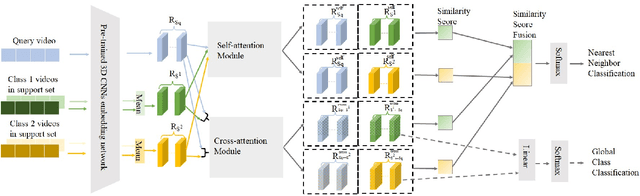
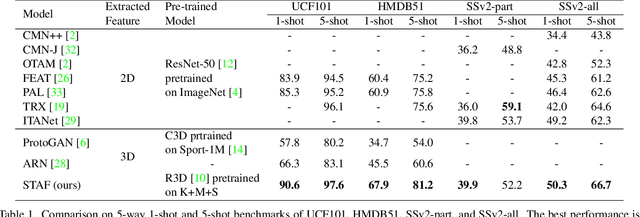
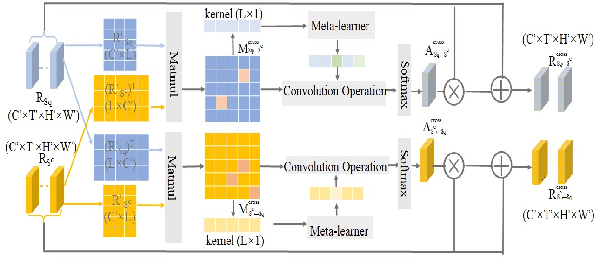
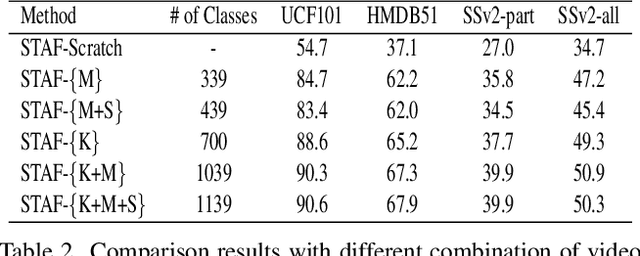
We propose STAF, a Spatio-Temporal Attention Fusion network for few-shot video classification. STAF first extracts coarse-grained spatial and temporal features of videos by applying a 3D Convolution Neural Networks embedding network. It then fine-tunes the extracted features using self-attention and cross-attention networks. Last, STAF applies a lightweight fusion network and a nearest neighbor classifier to classify each query video. To evaluate STAF, we conduct extensive experiments on three benchmarks (UCF101, HMDB51, and Something-Something-V2). The experimental results show that STAF improves state-of-the-art accuracy by a large margin, e.g., STAF increases the five-way one-shot accuracy by 5.3% and 7.0% for UCF101 and HMDB51, respectively.
ATS: Adaptive Token Sampling For Efficient Vision Transformers
Nov 30, 2021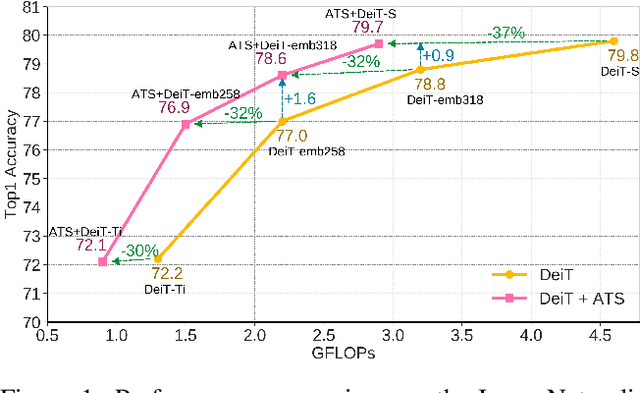
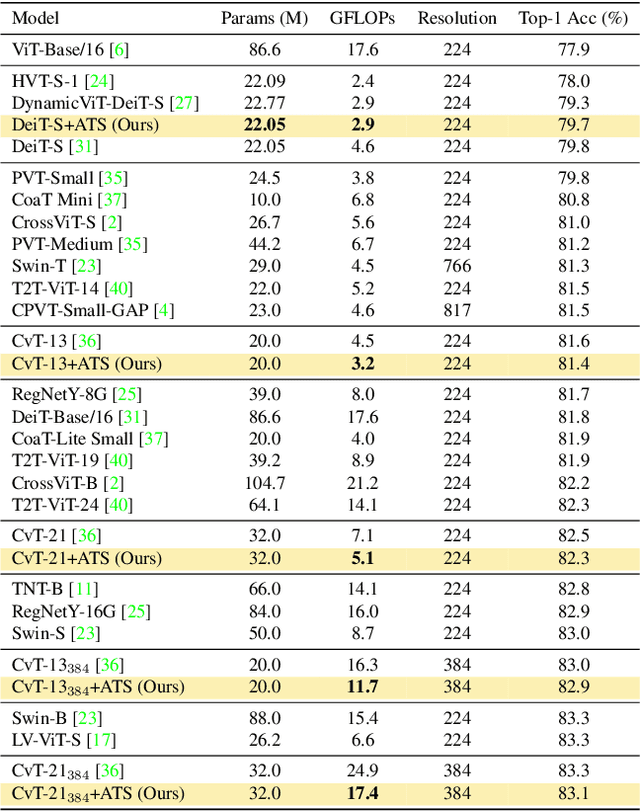
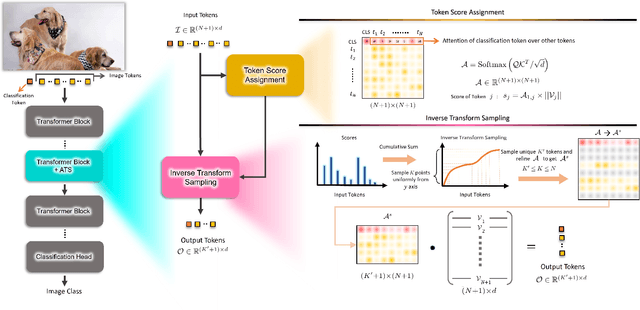

While state-of-the-art vision transformer models achieve promising results for image classification, they are computationally very expensive and require many GFLOPs. Although the GFLOPs of a vision transformer can be decreased by reducing the number of tokens in the network, there is no setting that is optimal for all input images. In this work, we, therefore, introduce a differentiable parameter-free Adaptive Token Sampling (ATS) module, which can be plugged into any existing vision transformer architecture. ATS empowers vision transformers by scoring and adaptively sampling significant tokens. As a result, the number of tokens is not anymore static but it varies for each input image. By integrating ATS as an additional layer within current transformer blocks, we can convert them into much more efficient vision transformers with an adaptive number of tokens. Since ATS is a parameter-free module, it can be added to off-the-shelf pretrained vision transformers as a plug-and-play module, thus reducing their GFLOPs without any additional training. However, due to its differentiable design, one can also train a vision transformer equipped with ATS. We evaluate our module on the ImageNet dataset by adding it to multiple state-of-the-art vision transformers. Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs) by 37% while preserving the accuracy.
A Simple Baseline for Low-Budget Active Learning
Oct 22, 2021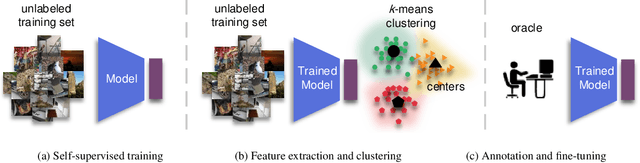
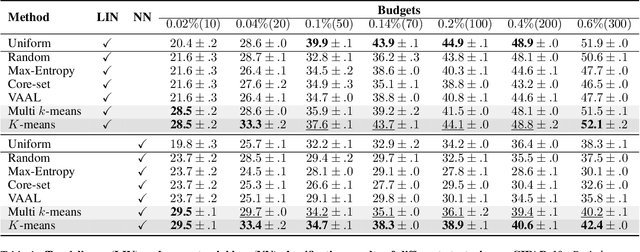

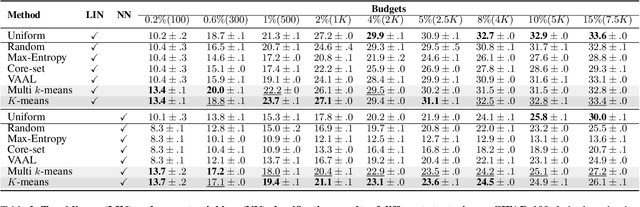
Active learning focuses on choosing a subset of unlabeled data to be labeled. However, most such methods assume that a large subset of the data can be annotated. We are interested in low-budget active learning where only a small subset (e.g., 0.2% of ImageNet) can be annotated. Instead of proposing a new query strategy to iteratively sample batches of unlabeled data given an initial pool, we learn rich features by an off-the-shelf self-supervised learning method only once and then study the effectiveness of different sampling strategies given a low budget on a variety of datasets as well as ImageNet dataset. We show that although the state-of-the-art active learning methods work well given a large budget of data labeling, a simple k-means clustering algorithm can outperform them on low budgets. We believe this method can be used as a simple baseline for low-budget active learning on image classification. Code is available at: https://github.com/UCDvision/low-budget-al
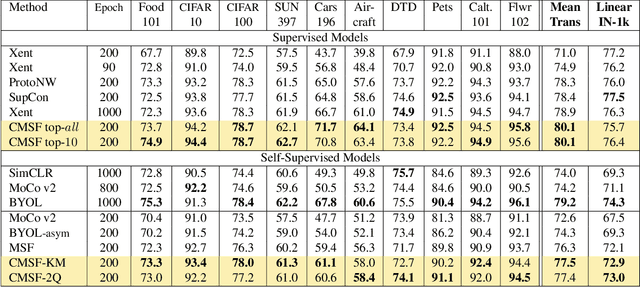
Constrained Mean Shift for Representation Learning
Oct 19, 2021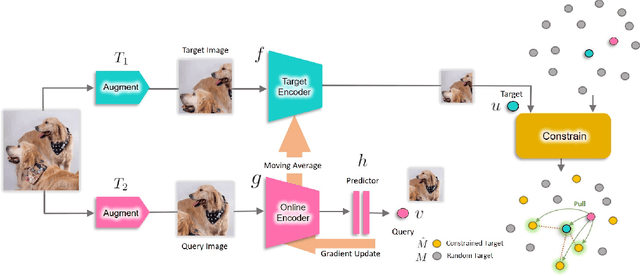
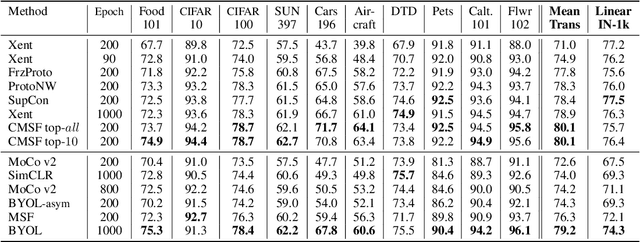

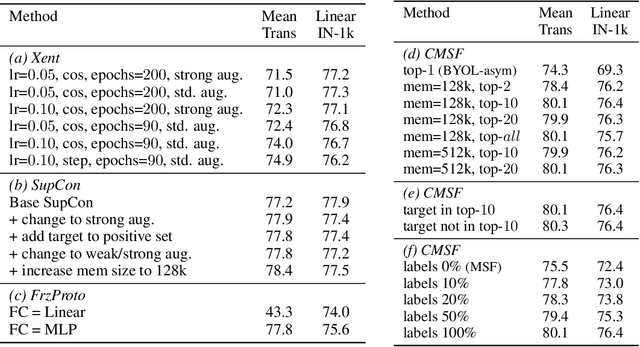
We are interested in representation learning from labeled or unlabeled data. Inspired by recent success of self-supervised learning (SSL), we develop a non-contrastive representation learning method that can exploit additional knowledge. This additional knowledge may come from annotated labels in the supervised setting or an SSL model from another modality in the SSL setting. Our main idea is to generalize the mean-shift algorithm by constraining the search space of nearest neighbors, resulting in semantically purer representations. Our method simply pulls the embedding of an instance closer to its nearest neighbors in a search space that is constrained using the additional knowledge. By leveraging this non-contrastive loss, we show that the supervised ImageNet-1k pretraining with our method results in better transfer performance as compared to the baselines. Further, we demonstrate that our method is relatively robust to label noise. Finally, we show that it is possible to use the noisy constraint across modalities to train self-supervised video models.