 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoIN: Mixture of Introvert Experts to Upcycle an LLM
Oct 13, 2024The goal of this paper is to improve (upcycle) an existing large language model without the prohibitive requirements of continued pre-training of the full-model. The idea is to split the pre-training data into semantically relevant groups and train an expert on each subset. An expert takes the form of a lightweight adapter added on the top of a frozen base model. During inference, an incoming query is first routed to the most relevant expert which is then loaded onto the base model for the forward pass. Unlike typical Mixture of Experts (MoE) models, the experts in our method do not work with other experts for a single query. Hence, we dub them "introvert" experts. Freezing the base model and keeping the experts as lightweight adapters allows extreme parallelism during training and inference. Training of all experts can be done in parallel without any communication channels between them. Similarly, the inference can also be heavily parallelized by distributing experts on different GPUs and routing each request to the GPU containing its relevant expert. We implement a proof-of-concept version of this method and show the validity of our approach.
Constrained Mean Shift Using Distant Yet Related Neighbors for Representation Learning
Dec 08, 2021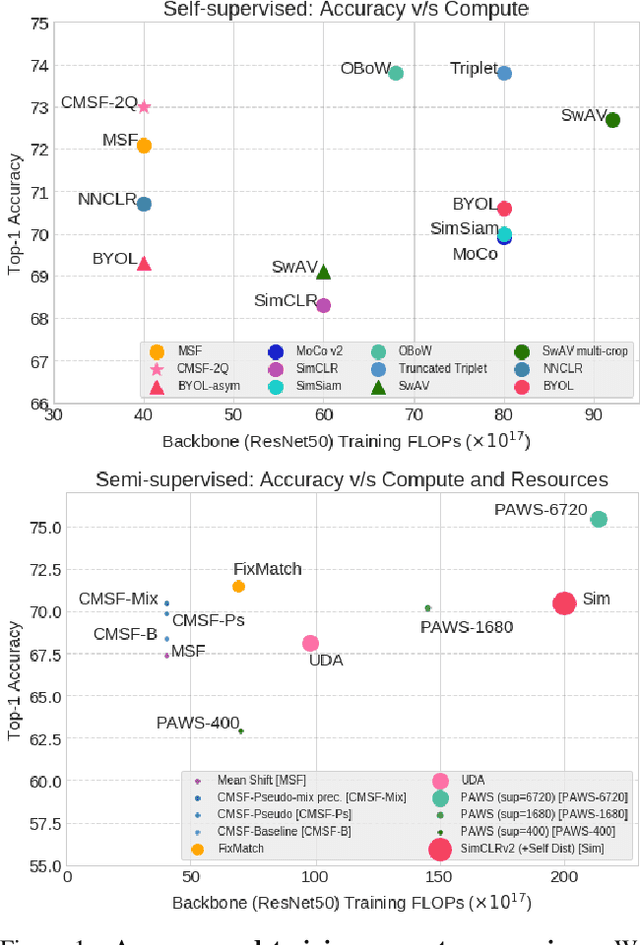
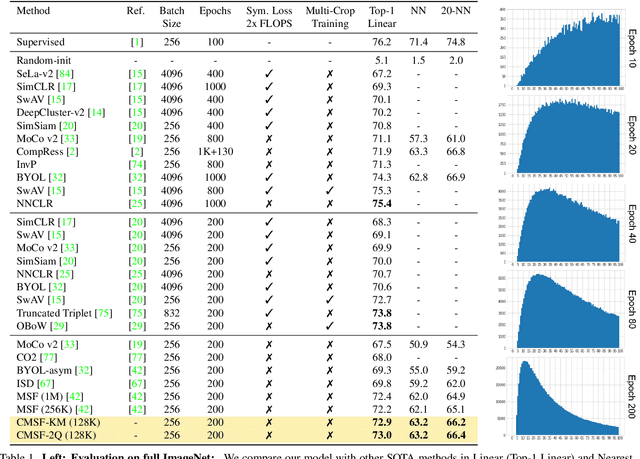
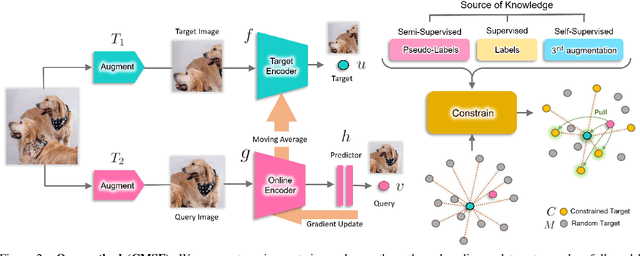
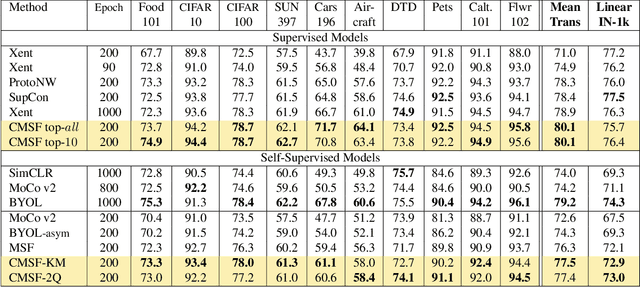
We are interested in representation learning in self-supervised, supervised, or semi-supervised settings. The prior work on applying mean-shift idea for self-supervised learning, MSF, generalizes the BYOL idea by pulling a query image to not only be closer to its other augmentation, but also to the nearest neighbors (NNs) of its other augmentation. We believe the learning can benefit from choosing far away neighbors that are still semantically related to the query. Hence, we propose to generalize MSF algorithm by constraining the search space for nearest neighbors. We show that our method outperforms MSF in SSL setting when the constraint utilizes a different augmentation of an image, and outperforms PAWS in semi-supervised setting with less training resources when the constraint ensures the NNs have the same pseudo-label as the query.
A Simple Baseline for Low-Budget Active Learning
Oct 22, 2021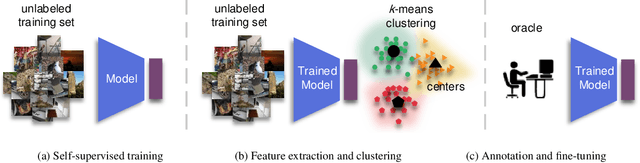
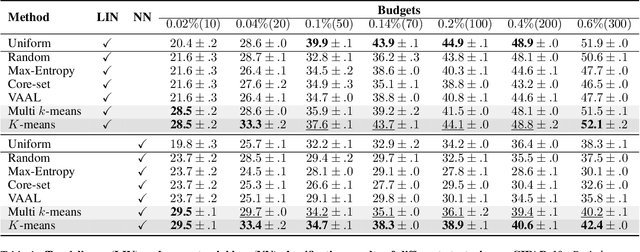

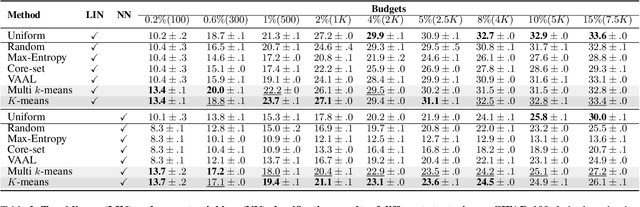
Active learning focuses on choosing a subset of unlabeled data to be labeled. However, most such methods assume that a large subset of the data can be annotated. We are interested in low-budget active learning where only a small subset (e.g., 0.2% of ImageNet) can be annotated. Instead of proposing a new query strategy to iteratively sample batches of unlabeled data given an initial pool, we learn rich features by an off-the-shelf self-supervised learning method only once and then study the effectiveness of different sampling strategies given a low budget on a variety of datasets as well as ImageNet dataset. We show that although the state-of-the-art active learning methods work well given a large budget of data labeling, a simple k-means clustering algorithm can outperform them on low budgets. We believe this method can be used as a simple baseline for low-budget active learning on image classification. Code is available at: https://github.com/UCDvision/low-budget-al
TaxoNN: A Light-Weight Accelerator for Deep Neural Network Training
Oct 11, 2020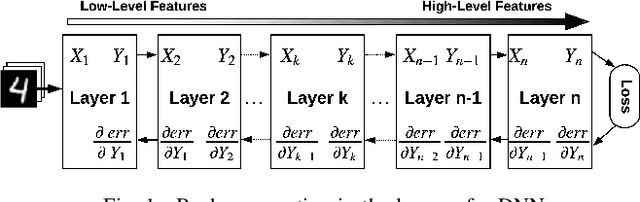
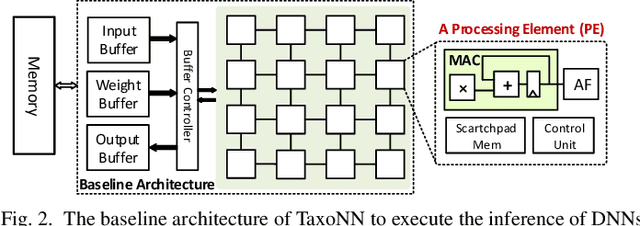
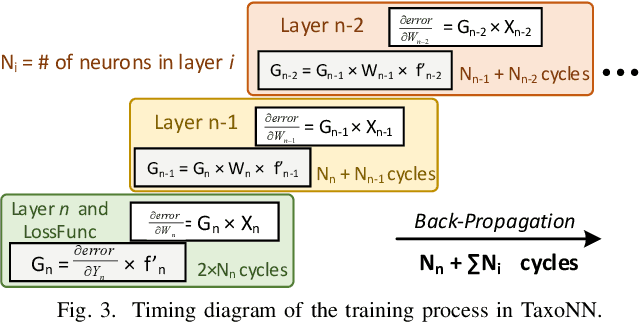
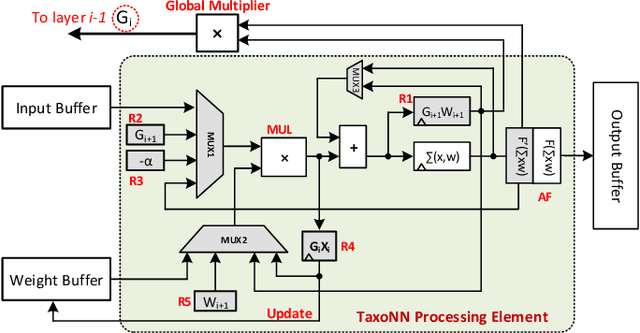
Emerging intelligent embedded devices rely on Deep Neural Networks (DNNs) to be able to interact with the real-world environment. This interaction comes with the ability to retrain DNNs, since environmental conditions change continuously in time. Stochastic Gradient Descent (SGD) is a widely used algorithm to train DNNs by optimizing the parameters over the training data iteratively. In this work, first we present a novel approach to add the training ability to a baseline DNN accelerator (inference only) by splitting the SGD algorithm into simple computational elements. Then, based on this heuristic approach we propose TaxoNN, a light-weight accelerator for DNN training. TaxoNN can easily tune the DNN weights by reusing the hardware resources used in the inference process using a time-multiplexing approach and low-bitwidth units. Our experimental results show that TaxoNN delivers, on average, 0.97% higher misclassification rate compared to a full-precision implementation. Moreover, TaxoNN provides 2.1$\times$ power saving and 1.65$\times$ area reduction over the state-of-the-art DNN training accelerator.
* Accepted to ISCAS 2020. 5 pages, 5 figures