 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lottery Ticket Hypothesis for Self-attention in Convolutional Neural Network
Jul 16, 2022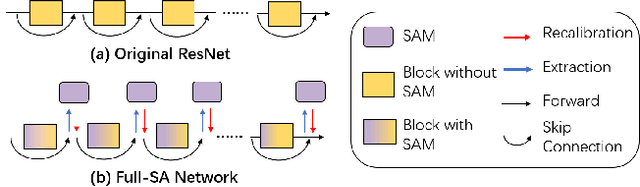
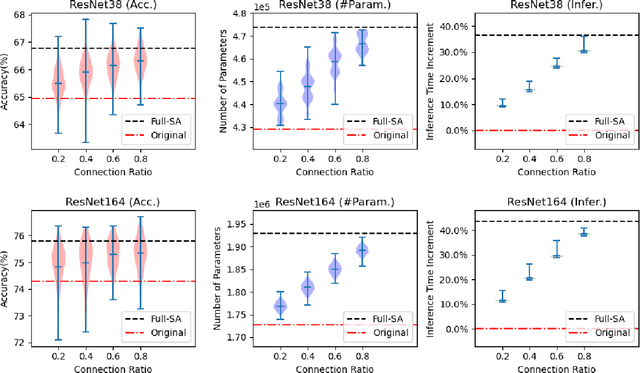
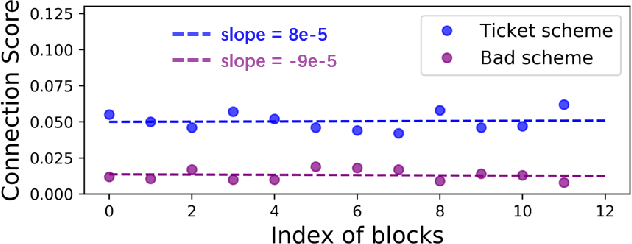
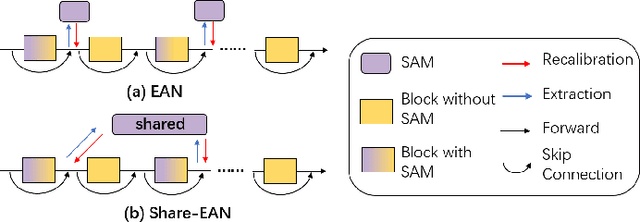
Recently many plug-and-play self-attention modules (SAMs) are proposed to enhance the model generalization by exploiting the internal information of deep convolutional neural networks (CNNs). In general, previous works ignore where to plug in the SAMs since they connect the SAMs individually with each block of the entire CNN backbone for granted, leading to incremental computational cost and the number of parameters with the growth of network depth. However, we empirically find and verify some counterintuitive phenomena that: (a) Connecting the SAMs to all the blocks may not always bring the largest performance boost, and connecting to partial blocks would be even better; (b) Adding the SAMs to a CNN may not always bring a performance boost, and instead it may even harm the performance of the original CNN backbone. Therefore, we articulate and demonstrate the Lottery Ticket Hypothesis for Self-attention Networks: a full self-attention network contains a subnetwork with sparse self-attention connections that can (1) accelerate inference, (2) reduce extra parameter increment, and (3) maintain accuracy. In addition to the empirical evidence, this hypothesis is also supported by our theoretical evidence. Furthermore, we propose a simple yet effective reinforcement-learning-based method to search the ticket, i.e., the connection scheme that satisfies the three above-mentioned conditions. Extensive experiments on widely-used benchmark datasets and popular self-attention networks show the effectiveness of our method. Besides, our experiments illustrate that our searched ticket has the capacity of transferring to some vision tasks, e.g., crowd counting and segmentation.
Finite Expression Method for Solving High-Dimensional Partial Differential Equations
Jun 21, 2022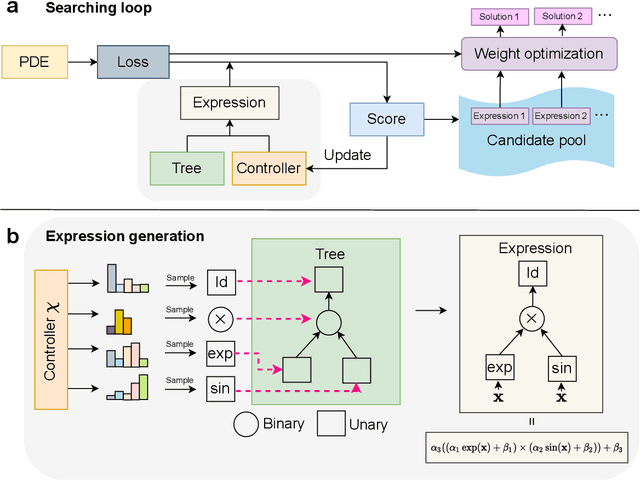

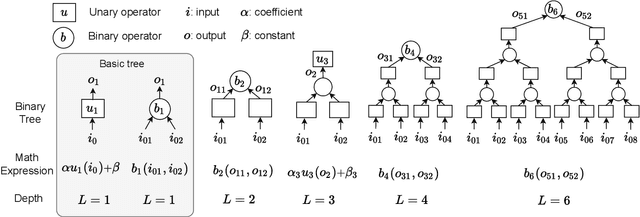
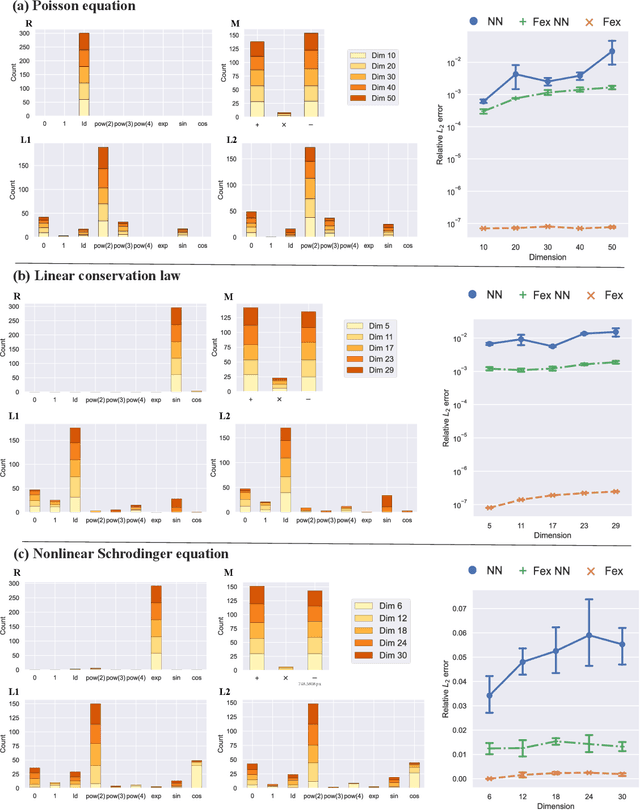
Designing efficient and accurate numerical solvers for high-dimensional partial differential equations (PDEs) remains a challenging and important topic in computational science and engineering, mainly due to the ``curse of dimensionality" in designing numerical schemes that scale in dimension. This paper introduces a new methodology that seeks an approximate PDE solution in the space of functions with finitely many analytic expressions and, hence, this methodology is named the finite expression method (FEX). It is proved in approximation theory that FEX can avoid the curse of dimensionality. As a proof of concept, a deep reinforcement learning method is proposed to implement FEX for various high-dimensional PDEs in different dimensions, achieving high and even machine accuracy with a memory complexity polynomial in dimension and an amenable time complexity. An approximate solution with finite analytic expressions also provides interpretable insights into the ground truth PDE solution, which can further help to advance the understanding of physical systems and design postprocessing techniques for a refined solution.
Reinforced Inverse Scattering
Jun 08, 2022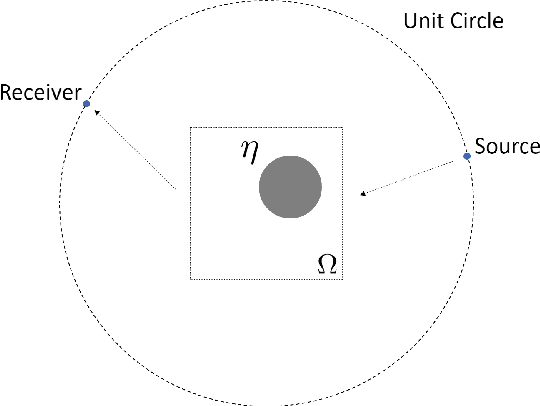



Inverse wave scattering aims at determining the properties of an object using data on how the object scatters incoming waves. In order to collect information, sensors are put in different locations to send and receive waves from each other. The choice of sensor positions and incident wave frequencies determines the reconstruction quality of scatterer properties. This paper introduces reinforcement learning to develop precision imaging that decides sensor positions and wave frequencies adaptive to different scatterers in an intelligent way, thus obtaining a significant improvement in reconstruction quality with limited imaging resources. Extensive numerical results will be provided to demonstrate the superiority of the proposed method over existing methods.
Neural Network Architecture Beyond Width and Depth
May 19, 2022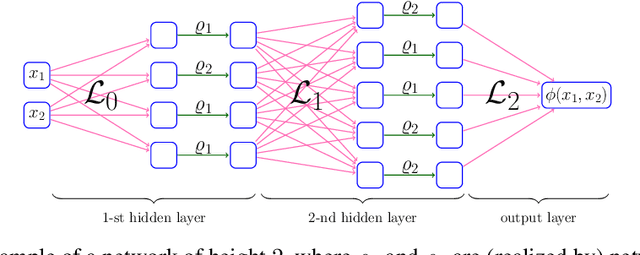

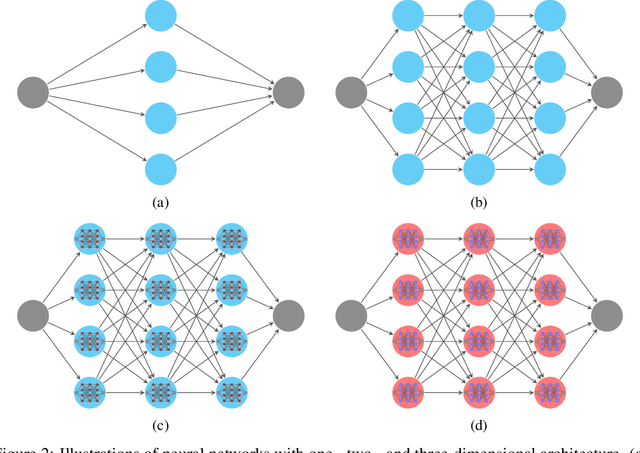
This paper proposes a new neural network architecture by introducing an additional dimension called height beyond width and depth. Neural network architectures with height, width, and depth as hyperparameters are called three-dimensional architectures. It is shown that neural networks with three-dimensional architectures are significantly more expressive than the ones with two-dimensional architectures (those with only width and depth as hyperparameters), e.g., standard fully connected networks. The new network architecture is constructed recursively via a nested structure, and hence we call a network with the new architecture nested network (NestNet). A NestNet of height $s$ is built with each hidden neuron activated by a NestNet of height $\le s-1$. When $s=1$, a NestNet degenerates to a standard network with a two-dimensional architecture. It is proved by construction that height-$s$ ReLU NestNets with $\mathcal{O}(n)$ parameters can approximate Lipschitz continuous functions on $[0,1]^d$ with an error $\mathcal{O}(n^{-(s+1)/d})$, while the optimal approximation error of standard ReLU networks with $\mathcal{O}(n)$ parameters is $\mathcal{O}(n^{-2/d})$. Furthermore, such a result is extended to generic continuous functions on $[0,1]^d$ with the approximation error characterized by the modulus of continuity. Finally, a numerical example is provided to explore the advantages of the super approximation power of ReLU NestNets.
IAE-Net: Integral Autoencoders for Discretization-Invariant Learning
Mar 30, 2022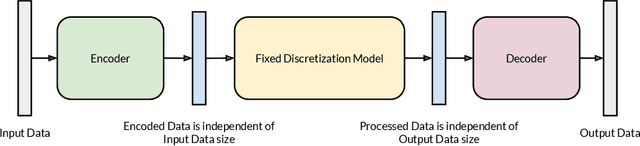

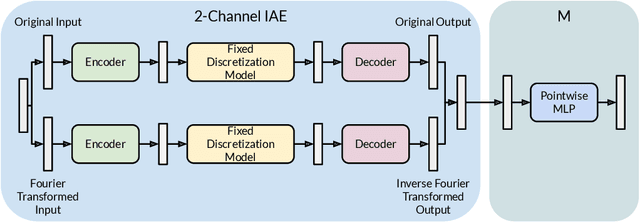

Discretization invariant learning aims at learning in the infinite-dimensional function spaces with the capacity to process heterogeneous discrete representations of functions as inputs and/or outputs of a learning model. This paper proposes a novel deep learning framework based on integral autoencoders (IAE-Net) for discretization invariant learning. The basic building block of IAE-Net consists of an encoder and a decoder as integral transforms with data-driven kernels, and a fully connected neural network between the encoder and decoder. This basic building block is applied in parallel in a wide multi-channel structure, which are repeatedly composed to form a deep and densely connected neural network with skip connections as IAE-Net. IAE-Net is trained with randomized data augmentation that generates training data with heterogeneous structures to facilitate the performance of discretization invariant learning. The proposed IAE-Net is tested with various applications in predictive data science, solving forward and inverse problems in scientific computing, and signal/image processing. Compared with alternatives in the literature, IAE-Net achieves state-of-the-art performance in existing applications and creates a wide range of new applications.
Connecting Optimization and Generalization via Gradient Flow Path Length
Feb 22, 2022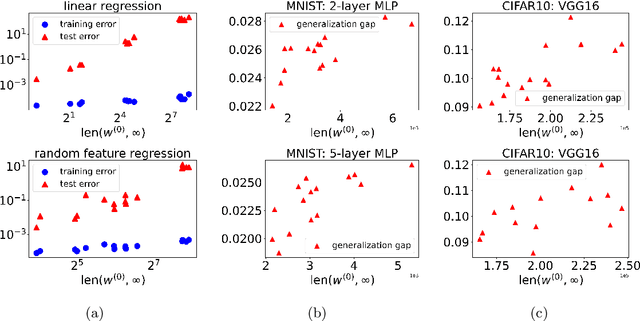
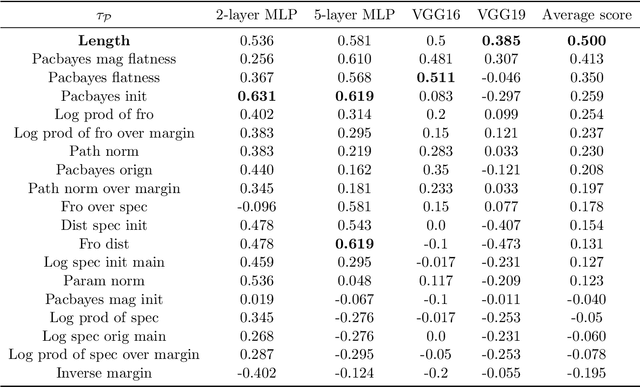
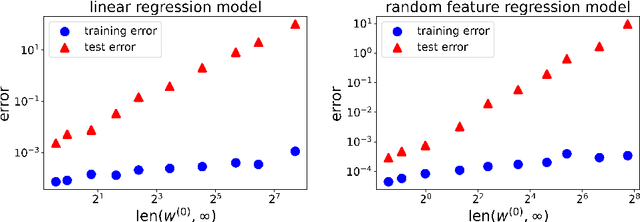
Optimization and generalization are two essential aspects of machine learning. In this paper, we propose a framework to connect optimization with generalization by analyzing the generalization error based on the length of optimization trajectory under the gradient flow algorithm after convergence. Through our approach, we show that, with a proper initialization, gradient flow converges following a short path with an explicit length estimate. Such an estimate induces a length-based generalization bound, showing that short optimization paths after convergence are associated with good generalization, which also matches our numerical results. Our framework can be applied to broad settings. For example, we use it to obtain generalization estimates on three distinct machine learning models: underdetermined $\ell_p$ linear regression, kernel regression, and overparameterized two-layer ReLU neural networks.
Deep Nonparametric Estimation of Operators between Infinite Dimensional Spaces
Jan 01, 2022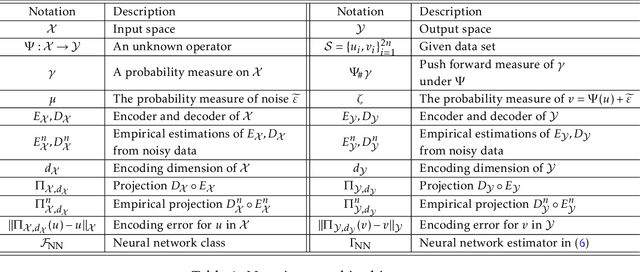
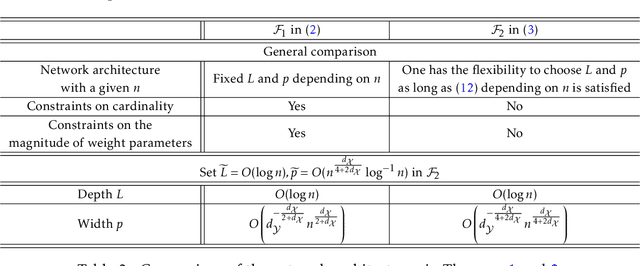
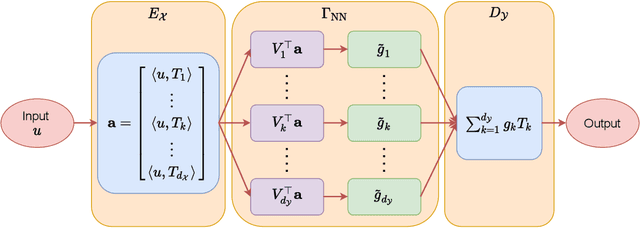
Learning operators between infinitely dimensional spaces is an important learning task arising in wide applications in machine learning, imaging science, mathematical modeling and simulations, etc. This paper studies the nonparametric estimation of Lipschitz operators using deep neural networks. Non-asymptotic upper bounds are derived for the generalization error of the empirical risk minimizer over a properly chosen network class. Under the assumption that the target operator exhibits a low dimensional structure, our error bounds decay as the training sample size increases, with an attractive fast rate depending on the intrinsic dimension in our estimation. Our assumptions cover most scenarios in real applications and our results give rise to fast rates by exploiting low dimensional structures of data in operator estimation. We also investigate the influence of network structures (e.g., network width, depth, and sparsity) on the generalization error of the neural network estimator and propose a general suggestion on the choice of network structures to maximize the learning efficiency quantitatively.
ReLU Network Approximation in Terms of Intrinsic Parameters
Nov 15, 2021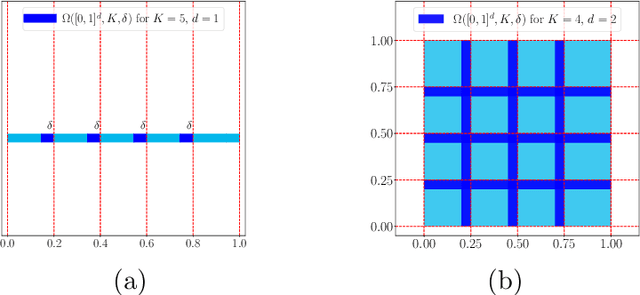
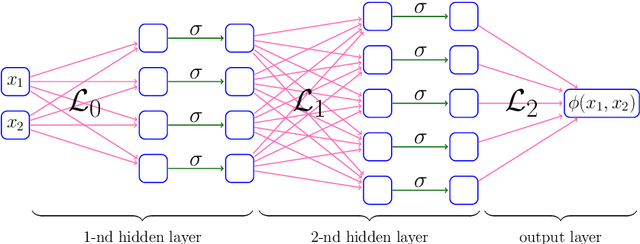
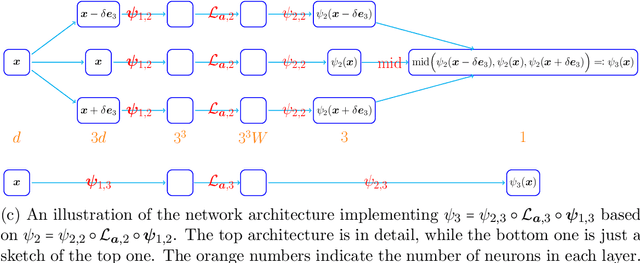
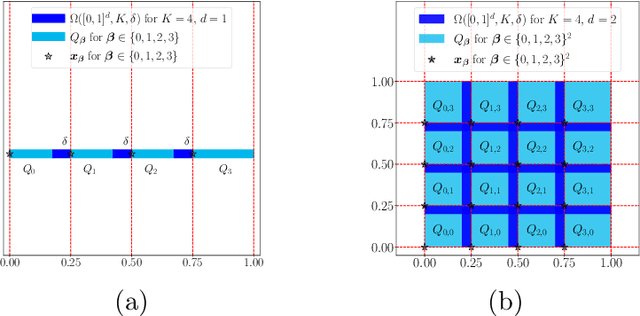
This paper studies the approximation error of ReLU networks in terms of the number of intrinsic parameters (i.e., those depending on the target function $f$). First, we prove by construction that, for any Lipschitz continuous function $f$ on $[0,1]^d$ with a Lipschitz constant $\lambda>0$, a ReLU network with $n+2$ intrinsic parameters can approximate $f$ with an exponentially small error $5\lambda \sqrt{d}\,2^{-n}$ measured in the $L^p$-norm for $p\in [1,\infty)$. More generally for an arbitrary continuous function $f$ on $[0,1]^d$ with a modulus of continuity $\omega_f(\cdot)$, the approximation error is $\omega_f(\sqrt{d}\, 2^{-n})+2^{-n+2}\omega_f(\sqrt{d})$. Next, we extend these two results from the $L^p$-norm to the $L^\infty$-norm at a price of $3^d n+2$ intrinsic parameters. Finally, by using a high-precision binary representation and the bit extraction technique via a fixed ReLU network independent of the target function, we design, theoretically, a ReLU network with only three intrinsic parameters to approximate H\"older continuous functions with an arbitrarily small error.
Stationary Density Estimation of Itô Diffusions Using Deep Learning
Sep 09, 2021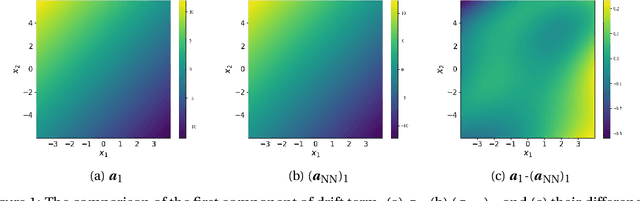
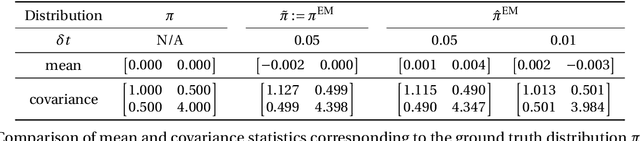
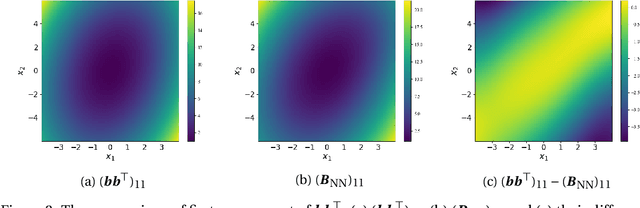
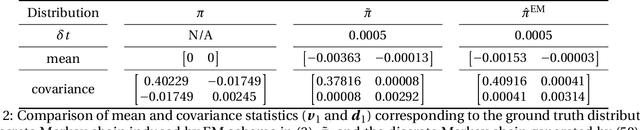
In this paper, we consider the density estimation problem associated with the stationary measure of ergodic It\^o diffusions from a discrete-time series that approximate the solutions of the stochastic differential equations. To take an advantage of the characterization of density function through the stationary solution of a parabolic-type Fokker-Planck PDE, we proceed as follows. First, we employ deep neural networks to approximate the drift and diffusion terms of the SDE by solving appropriate supervised learning tasks. Subsequently, we solve a steady-state Fokker-Plank equation associated with the estimated drift and diffusion coefficients with a neural-network-based least-squares method. We establish the convergence of the proposed scheme under appropriate mathematical assumptions, accounting for the generalization errors induced by regressing the drift and diffusion coefficients, and the PDE solvers. This theoretical study relies on a recent perturbation theory of Markov chain result that shows a linear dependence of the density estimation to the error in estimating the drift term, and generalization error results of nonparametric regression and of PDE regression solution obtained with neural-network models. The effectiveness of this method is reflected by numerical simulations of a two-dimensional Student's t distribution and a 20-dimensional Langevin dynamics.
Blending Pruning Criteria for Convolutional Neural Networks
Jul 11, 2021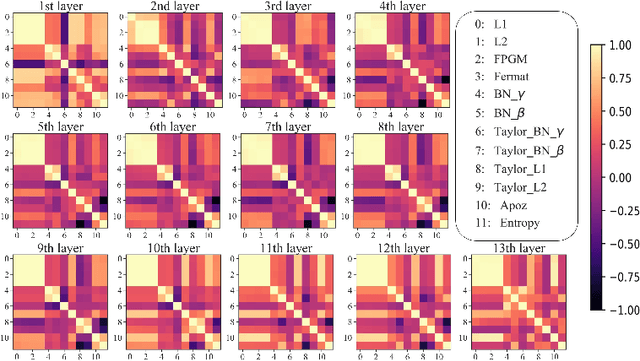
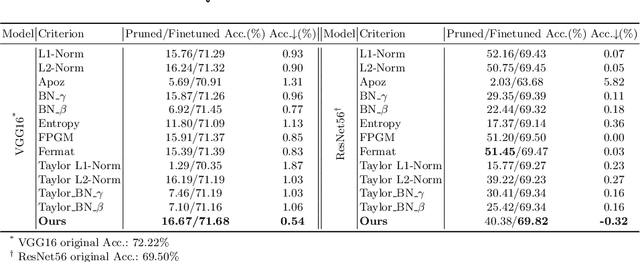
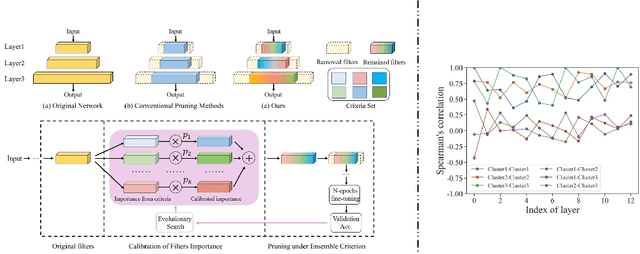
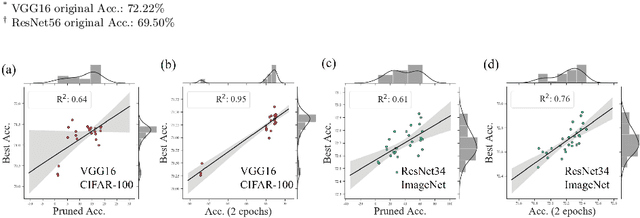
The advancement of convolutional neural networks (CNNs) on various vision applications has attracted lots of attention. Yet the majority of CNNs are unable to satisfy the strict requirement for real-world deployment. To overcome this, the recent popular network pruning is an effective method to reduce the redundancy of the models. However, the ranking of filters according to their "importance" on different pruning criteria may be inconsistent. One filter could be important according to a certain criterion, while it is unnecessary according to another one, which indicates that each criterion is only a partial view of the comprehensive "importance". From this motivation, we propose a novel framework to integrate the existing filter pruning criteria by exploring the criteria diversity. The proposed framework contains two stages: Criteria Clustering and Filters Importance Calibration. First, we condense the pruning criteria via layerwise clustering based on the rank of "importance" score. Second, within each cluster, we propose a calibration factor to adjust their significance for each selected blending candidates and search for the optimal blending criterion via Evolutionary Algorithm. Quantitative results on the CIFAR-100 and ImageNet benchmarks show that our framework outperforms the state-of-the-art baselines, regrading to the compact model performance after pruning.