 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Model for Image Inpainting with Local Binary Pattern Learning and Spatial Attention
Sep 02, 2020

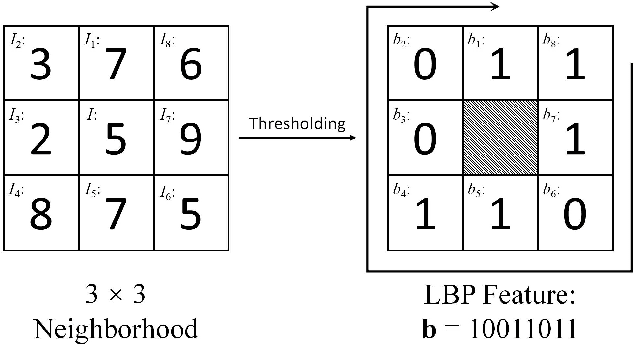
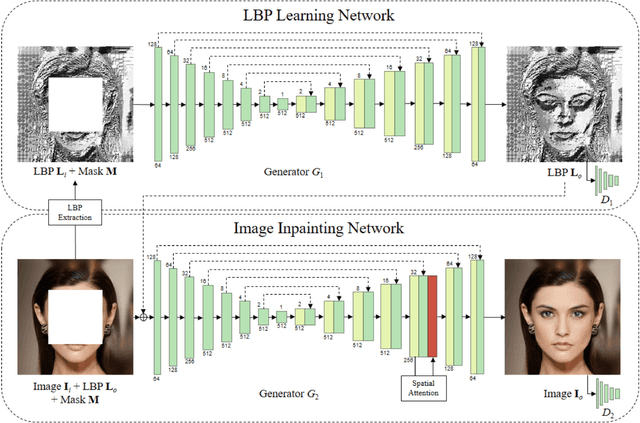
Deep learning (DL) has demonstrated its powerful capabilities in the field of image inpainting. The DL-based image inpainting approaches can produce visually plausible results, but often generate various unpleasant artifacts, especially in the boundary and highly textured regions. To tackle this challenge, in this work, we propose a new end-to-end, two-stage (coarse-to-fine) generative model through combining a local binary pattern (LBP) learning network with an actual inpainting network. Specifically, the first LBP learning network using U-Net architecture is designed to accurately predict the structural information of the missing region, which subsequently guides the second image inpainting network for better filling the missing pixels. Furthermore, an improved spatial attention mechanism is integrated in the image inpainting network, by considering the consistency not only between the known region with the generated one, but also within the generated region itself. Extensive experiments on public datasets including CelebA-HQ, Places and Paris StreetView demonstrate that our model generates better inpainting results than the state-of-the-art competing algorithms, both quantitatively and qualitatively. The source code and trained models will be made available at https://github.com/HighwayWu/ImageInpainting.
Privacy Leakage of SIFT Features via Deep Generative Model based Image Reconstruction
Sep 02, 2020
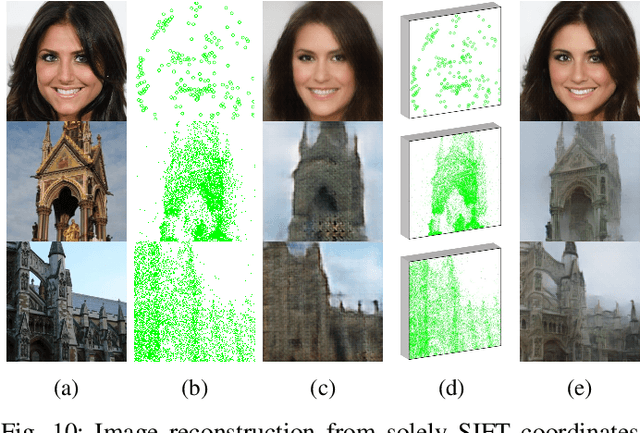
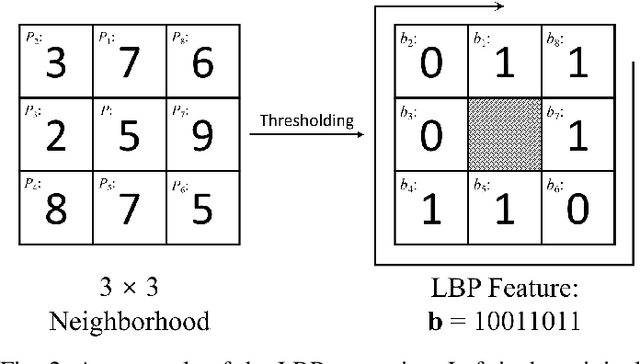
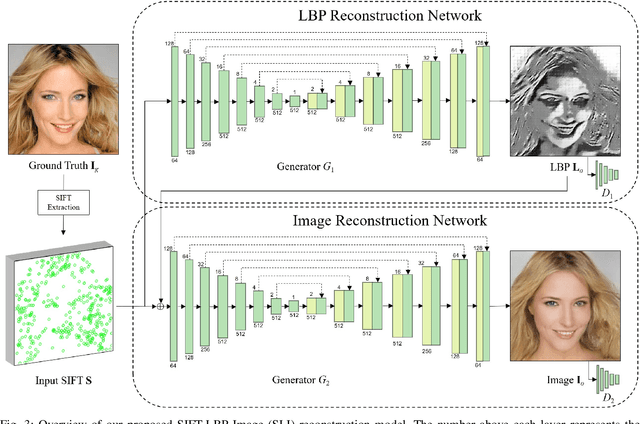
Many practical applications, e.g., content based image retrieval and object recognition, heavily rely on the local features extracted from the query image. As these local features are usually exposed to untrustworthy parties, the privacy leakage problem of image local features has received increasing attention in recent years. In this work, we thoroughly evaluate the privacy leakage of Scale Invariant Feature Transform (SIFT), which is one of the most widely-used image local features. We first consider the case that the adversary can fully access the SIFT features, i.e., both the SIFT descriptors and the coordinates are available. We propose a novel end-to-end, coarse-to-fine deep generative model for reconstructing the latent image from its SIFT features. The designed deep generative model consists of two networks, where the first one attempts to learn the structural information of the latent image by transforming from SIFT features to Local Binary Pattern (LBP) features, while the second one aims to reconstruct the pixel values guided by the learned LBP. Compared with the state-of-the-art algorithms, the proposed deep generative model produces much improved reconstructed results over three public datasets. Furthermore, we address more challenging cases that only partial SIFT features (either SIFT descriptors or coordinates) are accessible to the adversary. It is shown that, if the adversary can only have access to the SIFT descriptors while not their coordinates, then the modest success of reconstructing the latent image can be achieved for highly-structured images (e.g., faces) and would fail in general settings. In addition, the latent image can be reconstructed with reasonably good quality solely from the SIFT coordinates. Our results would suggest that the privacy leakage problem can be largely avoided if the SIFT coordinates can be well protected.
Mask Detection and Breath Monitoring from Speech: on Data Augmentation, Feature Representation and Modeling
Aug 14, 2020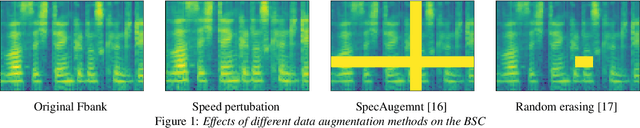

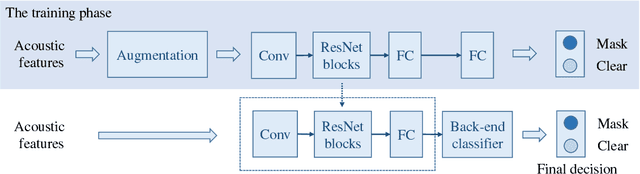
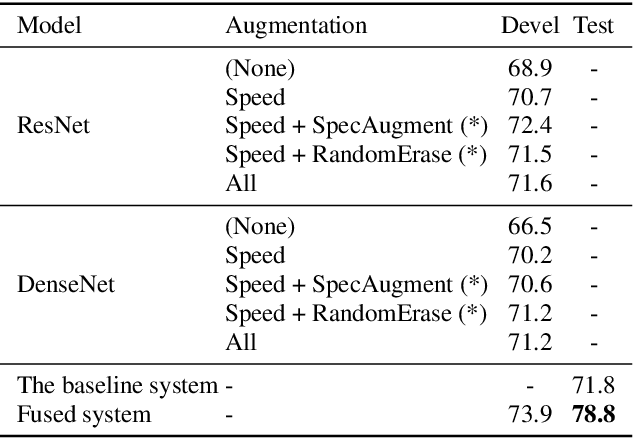
This paper introduces our approaches for the Mask and Breathing Sub-Challenge in the Interspeech COMPARE Challenge 2020. For the mask detection task, we train deep convolutional neural networks with filter-bank energies, gender-aware features, and speaker-aware features. Support Vector Machines follows as the back-end classifiers for binary prediction on the extracted deep embeddings. Several data augmentation schemes are used to increase the quantity of training data and improve our models' robustness, including speed perturbation, SpecAugment, and random erasing. For the speech breath monitoring task, we investigate different bottleneck features based on the Bi-LSTM structure. Experimental results show that our proposed methods outperform the baselines and achieve 0.746 PCC and 78.8% UAR on the Breathing and Mask evaluation set, respectively.
Acoustic Word Embedding System for Code-Switching Query-by-example Spoken Term Detection
May 24, 2020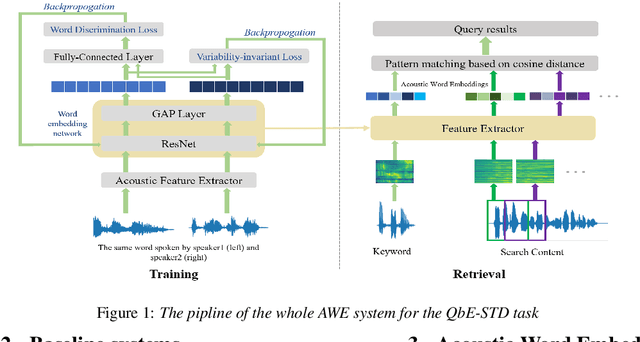
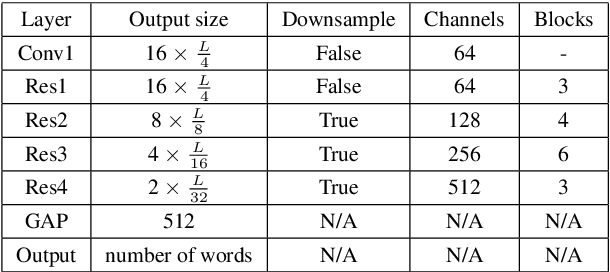
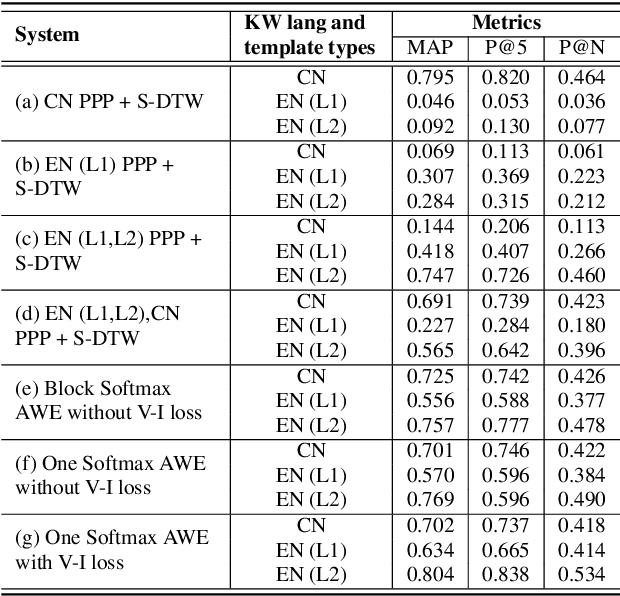
In this paper, we propose a deep convolutional neural network-based acoustic word embedding system on code-switching query by example spoken term detection. Different from previous configurations, we combine audio data in two languages for training instead of only using one single language. We transform the acoustic features of keyword templates and searching content to fixed-dimensional vectors and calculate the distances between keyword segments and searching content segments obtained in a sliding manner. An auxiliary variability-invariant loss is also applied to training data within the same word but different speakers. This strategy is used to prevent the extractor from encoding undesired speaker- or accent-related information into the acoustic word embeddings. Experimental results show that our proposed system produces promising searching results in the code-switching test scenario. With the increased number of templates and the employment of variability-invariant loss, the searching performance is further enhanced.
Domain Aware Training for Far-field Small-footprint Keyword Spotting
May 16, 2020
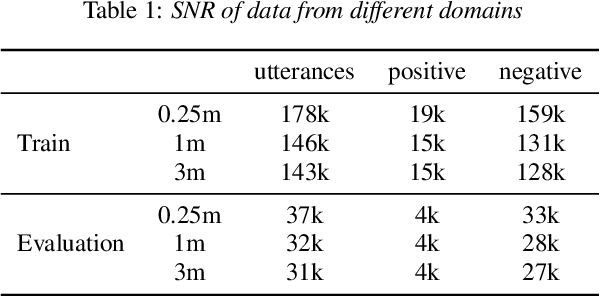
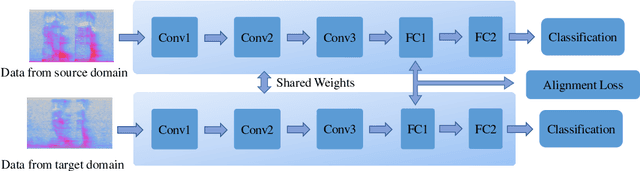
In this paper, we focus on the task of small-footprint keyword spotting under the far-field scenario. Far-field environments are commonly encountered in real-life speech applications, causing severe degradation of performance due to room reverberation and various kinds of noises. Our baseline system is built on the convolutional neural network trained with pooled data of both far-field and close-talking speech. To cope with the distortions, we develop three domain aware training systems, including the domain embedding system, the deep CORAL system, and the multi-task learning system. These methods incorporate domain knowledge into network training and improve the performance of the keyword classifier on far-field conditions. Experimental results show that our proposed methods manage to maintain the performance on the close-talking speech and achieve significant improvement on the far-field test set.
The DKU Replay Detection System for the ASVspoof 2019 Challenge: On Data Augmentation, Feature Representation, Classification, and Fusion
Jul 05, 2019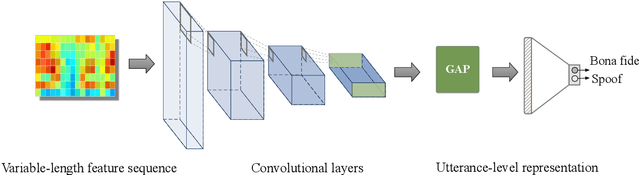
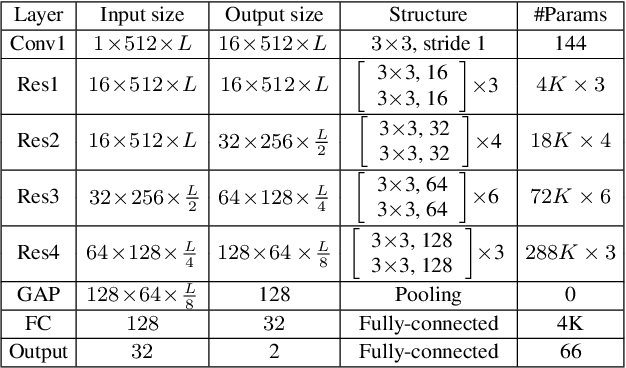
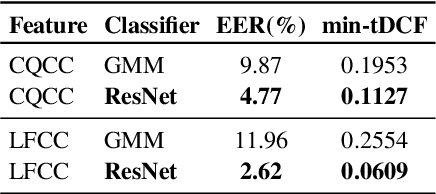
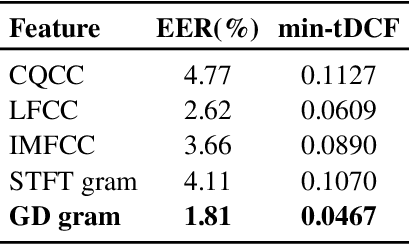
This paper describes our DKU replay detection system for the ASVspoof 2019 challenge. The goal is to develop spoofing countermeasure for automatic speaker recognition in physical access scenario. We leverage the countermeasure system pipeline from four aspects, including the data augmentation, feature representation, classification, and fusion. First, we introduce an utterance-level deep learning framework for anti-spoofing. It receives the variable-length feature sequence and outputs the utterance-level scores directly. Based on the framework, we try out various kinds of input feature representations extracted from either the magnitude spectrum or phase spectrum. Besides, we also perform the data augmentation strategy by applying the speed perturbation on the raw waveform. Our best single system employs a residual neural network trained by the speed-perturbed group delay gram. It achieves EER of 1.04% on the development set, as well as EER of 1.08% on the evaluation set. Finally, using the simple average score from several single systems can further improve the performance. EER of 0.24% on the development set and 0.66% on the evaluation set is obtained for our primary system.