 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Bias in Production Speech Models
May 11, 2017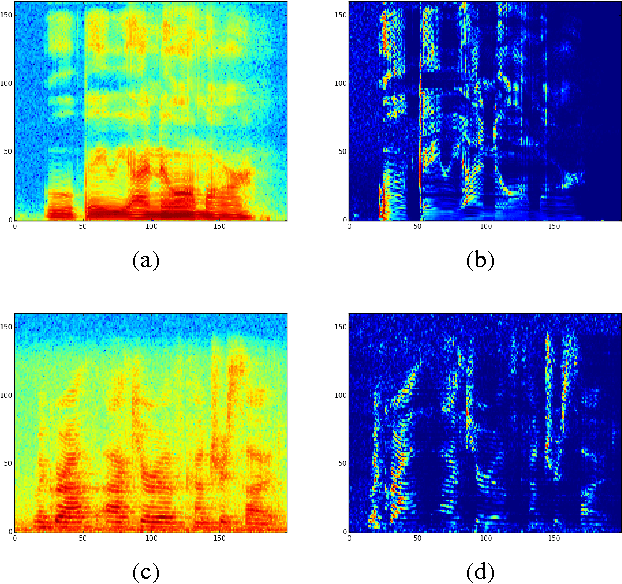
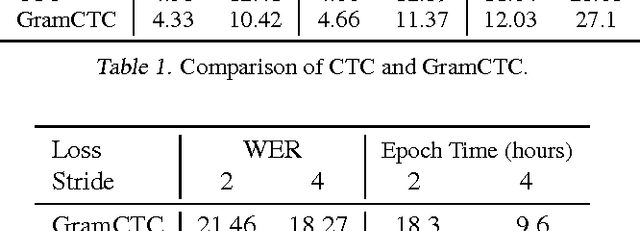
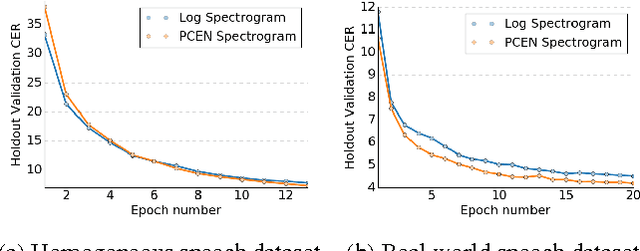
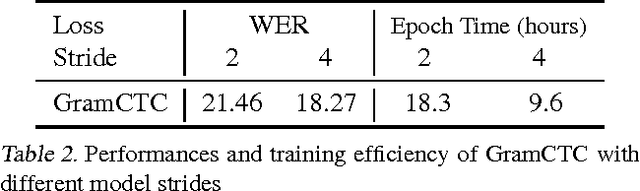
Replacing hand-engineered pipelines with end-to-end deep learning systems has enabled strong results in applications like speech and object recognition. However, the causality and latency constraints of production systems put end-to-end speech models back into the underfitting regime and expose biases in the model that we show cannot be overcome by "scaling up", i.e., training bigger models on more data. In this work we systematically identify and address sources of bias, reducing error rates by up to 20% while remaining practical for deployment. We achieve this by utilizing improved neural architectures for streaming inference, solving optimization issues, and employing strategies that increase audio and label modelling versatility.
Active Learning for Speech Recognition: the Power of Gradients
Dec 10, 2016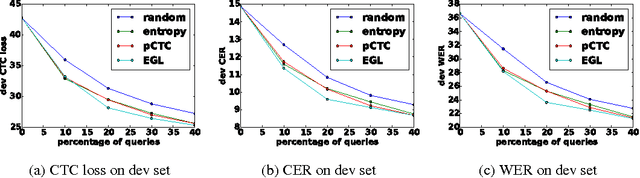
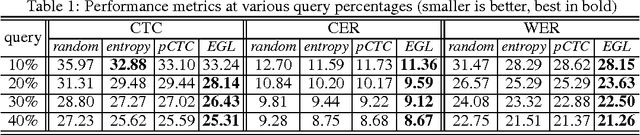
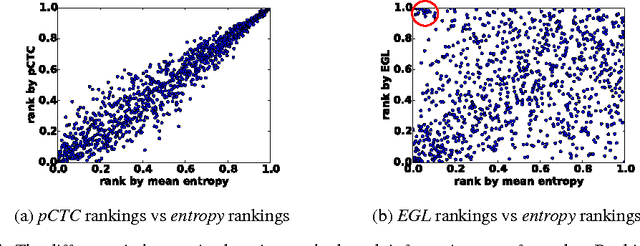
In training speech recognition systems, labeling audio clips can be expensive, and not all data is equally valuable. Active learning aims to label only the most informative samples to reduce cost. For speech recognition, confidence scores and other likelihood-based active learning methods have been shown to be effective. Gradient-based active learning methods, however, are still not well-understood. This work investigates the Expected Gradient Length (EGL) approach in active learning for end-to-end speech recognition. We justify EGL from a variance reduction perspective, and observe that EGL's measure of informativeness picks novel samples uncorrelated with confidence scores. Experimentally, we show that EGL can reduce word errors by 11\%, or alternatively, reduce the number of samples to label by 50\%, when compared to random sampling.
Revealing Cluster Structure of Graph by Path Following Replicator Dynamic
Mar 11, 2013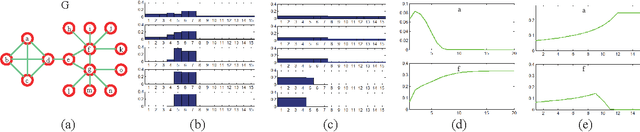
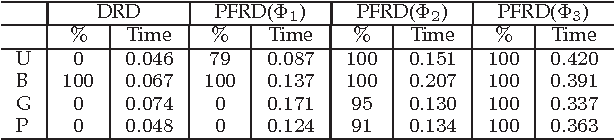

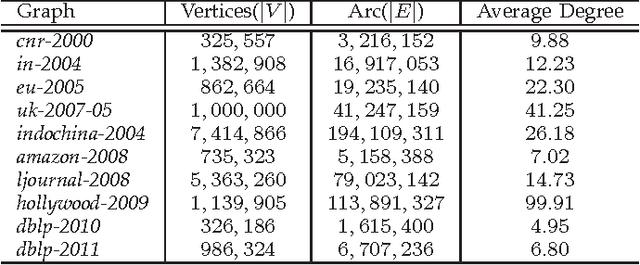
In this paper, we propose a path following replicator dynamic, and investigate its potentials in uncovering the underlying cluster structure of a graph. The proposed dynamic is a generalization of the discrete replicator dynamic. The replicator dynamic has been successfully used to extract dense clusters of graphs; however, it is often sensitive to the degree distribution of a graph, and usually biased by vertices with large degrees, thus may fail to detect the densest cluster. To overcome this problem, we introduce a dynamic parameter, called path parameter, into the evolution process. The path parameter can be interpreted as the maximal possible probability of a current cluster containing a vertex, and it monotonically increases as evolution process proceeds. By limiting the maximal probability, the phenomenon of some vertices dominating the early stage of evolution process is suppressed, thus making evolution process more robust. To solve the optimization problem with a fixed path parameter, we propose an efficient fixed point algorithm. The time complexity of the path following replicator dynamic is only linear in the number of edges of a graph, thus it can analyze graphs with millions of vertices and tens of millions of edges on a common PC in a few minutes. Besides, it can be naturally generalized to hypergraph and graph with edges of different orders. We apply it to four important problems: maximum clique problem, densest k-subgraph problem, structure fitting, and discovery of high-density regions. The extensive experimental results clearly demonstrate its advantages, in terms of robustness, scalability and flexility.