 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential quantum advantage in processing massive classical data
Apr 08, 2026Broadly applicable quantum advantage, particularly in classical data processing and machine learning, has been a fundamental open problem. In this work, we prove that a small quantum computer of polylogarithmic size can perform large-scale classification and dimension reduction on massive classical data by processing samples on the fly, whereas any classical machine achieving the same prediction performance requires exponentially larger size. Furthermore, classical machines that are exponentially larger yet below the required size need superpolynomially more samples and time. We validate these quantum advantages in real-world applications, including single-cell RNA sequencing and movie review sentiment analysis, demonstrating four to six orders of magnitude reduction in size with fewer than 60 logical qubits. These quantum advantages are enabled by quantum oracle sketching, an algorithm for accessing the classical world in quantum superposition using only random classical data samples. Combined with classical shadows, our algorithm circumvents the data loading and readout bottleneck to construct succinct classical models from massive classical data, a task provably impossible for any classical machine that is not exponentially larger than the quantum machine. These quantum advantages persist even when classical machines are granted unlimited time or if BPP=BQP, and rely only on the correctness of quantum mechanics. Together, our results establish machine learning on classical data as a broad and natural domain of quantum advantage and a fundamental test of quantum mechanics at the complexity frontier.
Learning to erase quantum states: thermodynamic implications of quantum learning theory
Apr 09, 2025The energy cost of erasing quantum states depends on our knowledge of the states. We show that learning algorithms can acquire such knowledge to erase many copies of an unknown state at the optimal energy cost. This is proved by showing that learning can be made fully reversible and has no fundamental energy cost itself. With simple counting arguments, we relate the energy cost of erasing quantum states to their complexity, entanglement, and magic. We further show that the constructed erasure protocol is computationally efficient when learning is efficient. Conversely, under standard cryptographic assumptions, we prove that the optimal energy cost cannot be achieved efficiently in general. These results also enable efficient work extraction based on learning. Together, our results establish a concrete connection between quantum learning theory and thermodynamics, highlighting the physical significance of learning processes and enabling efficient learning-based protocols for thermodynamic tasks.
Entanglement-induced provable and robust quantum learning advantages
Oct 04, 2024

Quantum computing holds the unparalleled potentials to enhance, speed up or innovate machine learning. However, an unambiguous demonstration of quantum learning advantage has not been achieved so far. Here, we rigorously establish a noise-robust, unconditional quantum learning advantage in terms of expressivity, inference speed, and training efficiency, compared to commonly-used classical machine learning models. Our proof is information-theoretic and pinpoints the origin of this advantage: quantum entanglement can be used to reduce the communication required by non-local machine learning tasks. In particular, we design a fully classical task that can be solved with unit accuracy by a quantum model with a constant number of variational parameters using entanglement resources, whereas commonly-used classical models must scale at least linearly with the size of the task to achieve a larger-than-exponentially-small accuracy. We further show that the quantum model can be trained with constant time and a number of samples inversely proportional to the problem size. We prove that this advantage is robust against constant depolarization noise. We show through numerical simulations that even though the classical models can have improved performance as their sizes are increased, they would suffer from overfitting. The constant-versus-linear separation, bolstered by the overfitting problem, makes it possible to demonstrate the quantum advantage with relatively small system sizes. We demonstrate, through both numerical simulations and trapped-ion experiments on IonQ Aria, the desired quantum-classical learning separation. Our results provide a valuable guide for demonstrating quantum learning advantages in practical applications with current noisy intermediate-scale quantum devices.
Learning quantum states and unitaries of bounded gate complexity
Oct 30, 2023

While quantum state tomography is notoriously hard, most states hold little interest to practically-minded tomographers. Given that states and unitaries appearing in Nature are of bounded gate complexity, it is natural to ask if efficient learning becomes possible. In this work, we prove that to learn a state generated by a quantum circuit with $G$ two-qubit gates to a small trace distance, a sample complexity scaling linearly in $G$ is necessary and sufficient. We also prove that the optimal query complexity to learn a unitary generated by $G$ gates to a small average-case error scales linearly in $G$. While sample-efficient learning can be achieved, we show that under reasonable cryptographic conjectures, the computational complexity for learning states and unitaries of gate complexity $G$ must scale exponentially in $G$. We illustrate how these results establish fundamental limitations on the expressivity of quantum machine learning models and provide new perspectives on no-free-lunch theorems in unitary learning. Together, our results answer how the complexity of learning quantum states and unitaries relate to the complexity of creating these states and unitaries.
Empirical Sample Complexity of Neural Network Mixed State Reconstruction
Jul 04, 2023Quantum state reconstruction using Neural Quantum States has been proposed as a viable tool to reduce quantum shot complexity in practical applications, and its advantage over competing techniques has been shown in numerical experiments focusing mainly on the noiseless case. In this work, we numerically investigate the performance of different quantum state reconstruction techniques for mixed states: the finite-temperature Ising model. We show how to systematically reduce the quantum resource requirement of the algorithms by applying variance reduction techniques. Then, we compare the two leading neural quantum state encodings of the state, namely, the Neural Density Operator and the positive operator-valued measurement representation, and illustrate their different performance as the mixedness of the target state varies. We find that certain encodings are more efficient in different regimes of mixedness and point out the need for designing more efficient encodings in terms of both classical and quantum resources.
Exact Decomposition of Quantum Channels for Non-IID Quantum Federated Learning
Sep 02, 2022



Federated learning refers to the task of performing machine learning with decentralized data from multiple clients while protecting data security and privacy. Works have been done to incorporate quantum advantage in such scenarios. However, when the clients' data are not independent and identically distributed (IID), the performance of conventional federated algorithms deteriorates. In this work, we explore this phenomenon in the quantum regime with both theoretical and numerical analysis. We further prove that a global quantum channel can be exactly decomposed into channels trained by each client with the help of local density estimators. It leads to a general framework for quantum federated learning on non-IID data with one-shot communication complexity. We demonstrate it on classification tasks with numerical simulations.
MAGIC: Microlensing Analysis Guided by Intelligent Computation
Jun 16, 2022
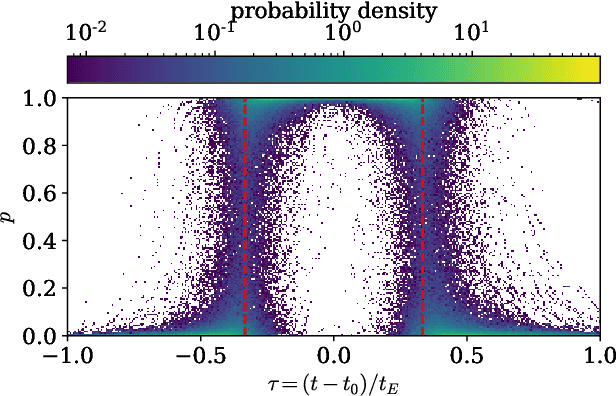

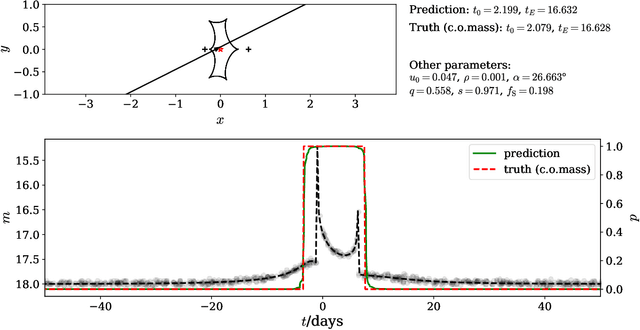
The modeling of binary microlensing light curves via the standard sampling-based method can be challenging, because of the time-consuming light curve computation and the pathological likelihood landscape in the high-dimensional parameter space. In this work, we present MAGIC, which is a machine learning framework to efficiently and accurately infer the microlensing parameters of binary events with realistic data quality. In MAGIC, binary microlensing parameters are divided into two groups and inferred separately with different neural networks. The key feature of MAGIC is the introduction of neural controlled differential equation, which provides the capability to handle light curves with irregular sampling and large data gaps. Based on simulated light curves, we show that MAGIC can achieve fractional uncertainties of a few percent on the binary mass ratio and separation. We also test MAGIC on a real microlensing event. MAGIC is able to locate the degenerate solutions even when large data gaps are introduced. As irregular samplings are common in astronomical surveys, our method also has implications to other studies that involve time series.
CAE-ADMM: Implicit Bitrate Optimization via ADMM-based Pruning in Compressive Autoencoders
Jan 30, 2019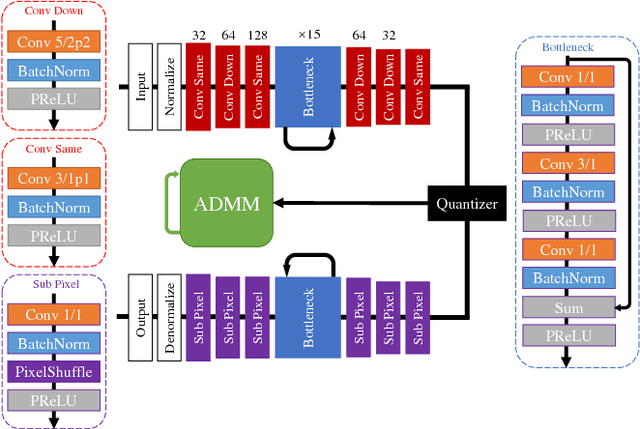

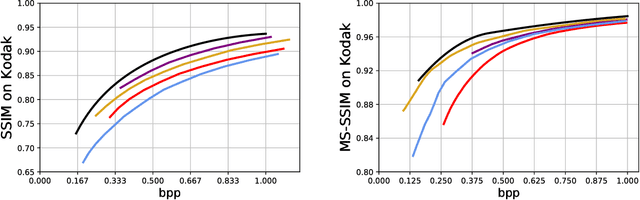

We introduce CAE-ADMM (ADMM-pruned compressive autoencoder), a lossy image compression model, inspired by researches in neural architecture search (NAS) and is capable of implicitly optimizing the bitrate without the use of an entropy estimator. Our experiments show that by introducing alternating direction method of multipliers (ADMM) to the model pipeline, the pruning paradigm yields more accurate results (SSIM/MS-SSIM-wise) when compared to entropy-based approaches and that of traditional codecs (JPEG, JPEG 2000, etc.) while maintaining acceptable inference speed. We further explore the effectiveness of the pruning method in CAE-ADMM by examining the generated latent codes.