 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicLog: Towards Accurate and Efficient LLM-based Log Parsing via Progressive Meta In-Context Learning
Jan 11, 2026Log parsing converts semi-structured logs into structured templates, forming a critical foundation for downstream analysis. Traditional syntax and semantic-based parsers often struggle with semantic variations in evolving logs and data scarcity stemming from their limited domain coverage. Recent large language model (LLM)-based parsers leverage in-context learning (ICL) to extract semantics from examples, demonstrating superior accuracy. However, LLM-based parsers face two main challenges: 1) underutilization of ICL capabilities, particularly in dynamic example selection and cross-domain generalization, leading to inconsistent performance; 2) time-consuming and costly LLM querying. To address these challenges, we present MicLog, the first progressive meta in-context learning (ProgMeta-ICL) log parsing framework that combines meta-learning with ICL on small open-source LLMs (i.e., Qwen-2.5-3B). Specifically, MicLog: i) enhances LLMs' ICL capability through a zero-shot to k-shot ProgMeta-ICL paradigm, employing weighted DBSCAN candidate sampling and enhanced BM25 demonstration selection; ii) accelerates parsing via a multi-level pre-query cache that dynamically matches and refines recently parsed templates. Evaluated on Loghub-2.0, MicLog achieves 10.3% higher parsing accuracy than the state-of-the-art parser while reducing parsing time by 42.4%.
Cascaded multi-scale and multi-dimension convolutional neural network for stereo matching
Apr 17, 2018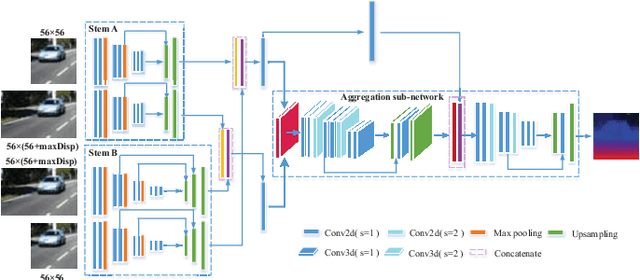

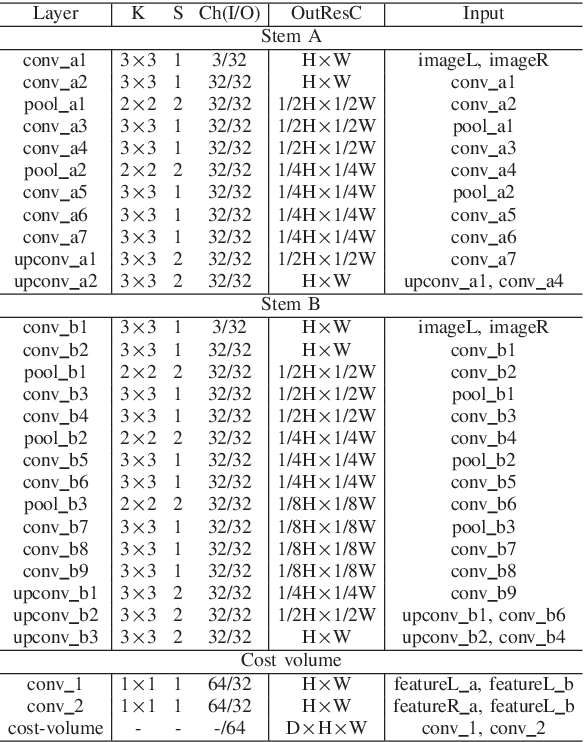
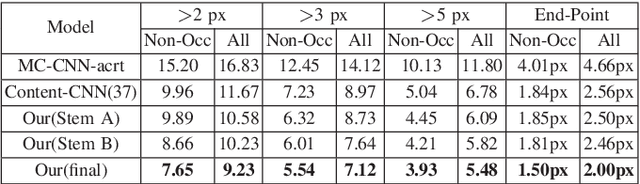
Convolutional neural networks(CNN) have been shown to perform better than the conventional stereo algorithms for stereo estimation. Numerous efforts focus on the pixel-wise matching cost computation, which is the important building block for many start-of-the-art algorithms. However, those architectures are limited to small and single scale receptive fields and use traditional methods for cost aggregation or even ignore cost aggregation. Differently we take them both into consideration. Firstly, we propose a new multi-scale matching cost computation sub-network, in which two different sizes of receptive fields are implemented parallelly. In this way, the network can make the best use of both variants and balance the trade-off between the increase of receptive field and the loss of detail. Furthermore, we show that our multi-dimension aggregation sub-network which containing 2D convolution and 3D convolution operations can provide rich context and semantic information for estimating an accurate initial disparity. Finally, experiments on challenging stereo benchmark KITTI demonstrate that the proposed method can achieve competitive results even without any additional post-processing.