 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Explanation: New Prompting Method to Generate Higher Quality Natural Language Explanation for Implicit Hate Speech
Sep 11, 2022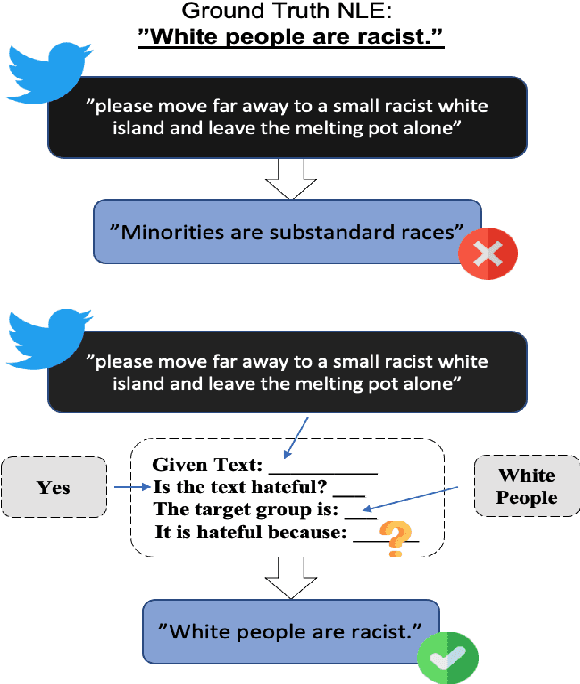

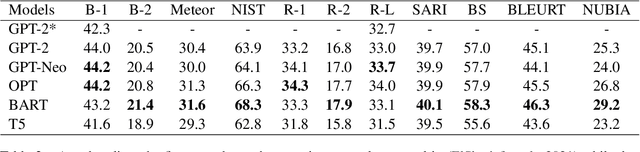

Recent studies have exploited advanced generative language models to generate Natural Language Explanations (NLE) for why a certain text could be hateful. We propose the Chain of Explanation Prompting method, inspired by the chain of thoughts study \cite{wei2022chain}, to generate high-quality NLE for implicit hate speech. We build a benchmark based on the selected mainstream Pre-trained Language Models (PLMs), including GPT-2, GPT-Neo, OPT, T5, and BART, with various evaluation metrics from lexical, semantic, and faithful aspects. To further evaluate the quality of the generated NLE from human perceptions, we hire human annotators to score the informativeness and clarity of the generated NLE. Then, we inspect which automatic evaluation metric could be best correlated with the human-annotated informativeness and clarity metric scores.
Who Is Missing? Characterizing the Participation of Different Demographic Groups in a Korean Nationwide Daily Conversation Corpus
Apr 20, 2022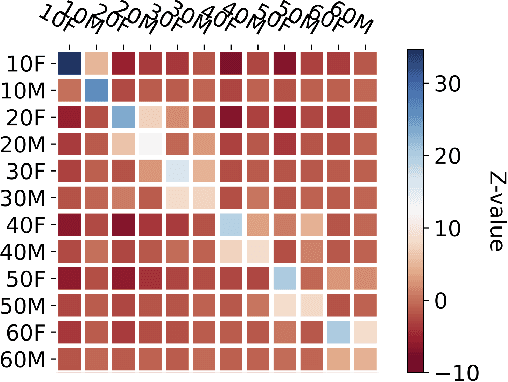
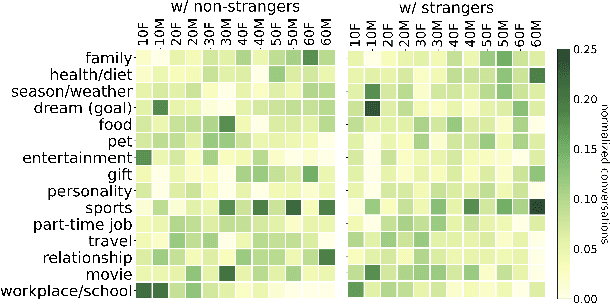
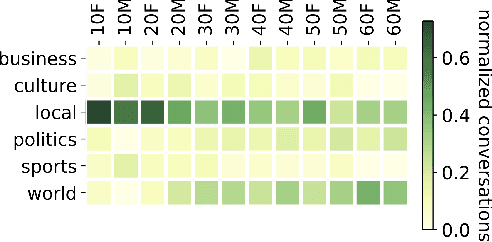
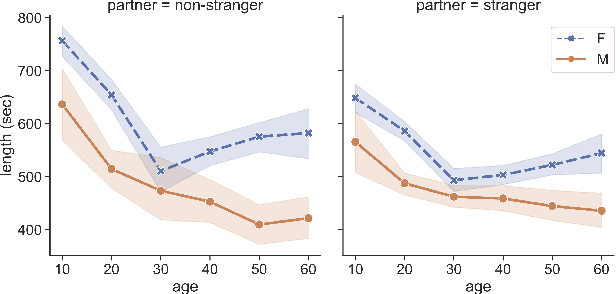
A conversation corpus is essential to build interactive AI applications. However, the demographic information of the participants in such corpora is largely underexplored mainly due to the lack of individual data in many corpora. In this work, we analyze a Korean nationwide daily conversation corpus constructed by the National Institute of Korean Language (NIKL) to characterize the participation of different demographic (age and sex) groups in the corpus.
Understanding Toxicity Triggers on Reddit in the Context of Singapore
Apr 19, 2022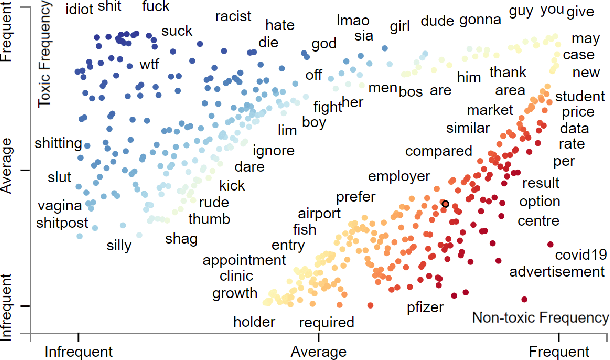
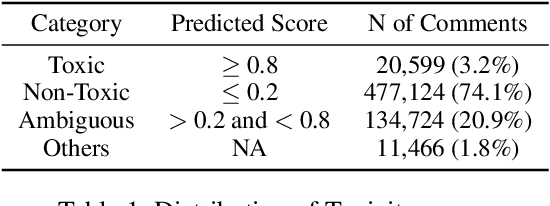
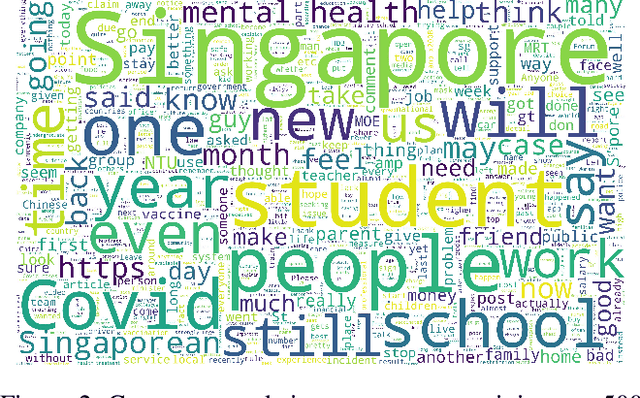
While the contagious nature of online toxicity sparked increasing interest in its early detection and prevention, most of the literature focuses on the Western world. In this work, we demonstrate that 1) it is possible to detect toxicity triggers in an Asian online community, and 2) toxicity triggers can be strikingly different between Western and Eastern contexts.
A Survey on Predicting the Factuality and the Bias of News Media
Mar 16, 2021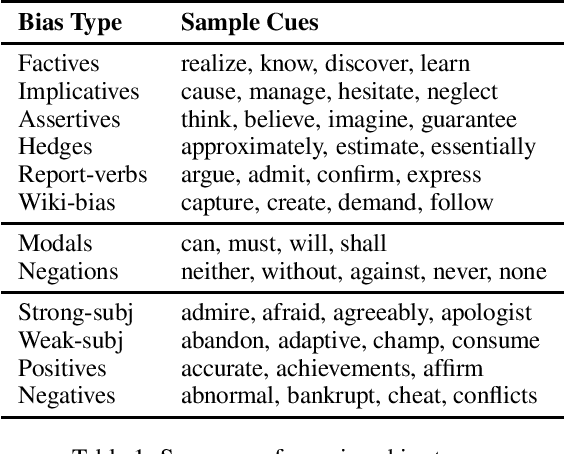
The present level of proliferation of fake, biased, and propagandistic content online has made it impossible to fact-check every single suspicious claim or article, either manually or automatically. Thus, many researchers are shifting their attention to higher granularity, aiming to profile entire news outlets, which makes it possible to detect likely "fake news" the moment it is published, by simply checking the reliability of its source. Source factuality is also an important element of systems for automatic fact-checking and "fake news" detection, as they need to assess the reliability of the evidence they retrieve online. Political bias detection, which in the Western political landscape is about predicting left-center-right bias, is an equally important topic, which has experienced a similar shift towards profiling entire news outlets. Moreover, there is a clear connection between the two, as highly biased media are less likely to be factual; yet, the two problems have been addressed separately. In this survey, we review the state of the art on media profiling for factuality and bias, arguing for the need to model them jointly. We further discuss interesting recent advances in using different information sources and modalities, which go beyond the text of the articles the target news outlet has published. Finally, we discuss current challenges and outline future research directions.
Understanding Effects of Editing Tweets for News Sharing by Media Accounts through a Causal Inference Framework
Sep 17, 2020
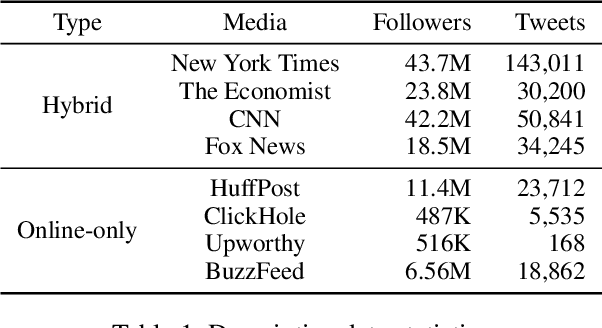
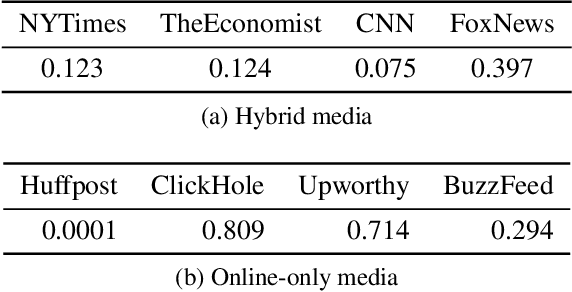
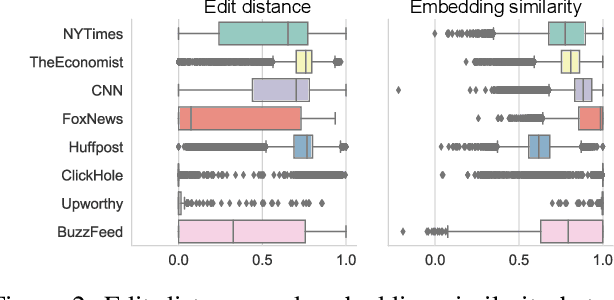
To reach a broader audience and optimize traffic toward news articles, media outlets commonly run social media accounts and share their content with a short text summary. Despite its importance of writing a compelling message in sharing articles, research community does not own a sufficient level of understanding of what kinds of editing strategies are effective in promoting audience engagement. In this study, we aim to fill the gap by analyzing the current practices of media outlets using a data-driven approach. We first build a parallel corpus of original news articles and their corresponding tweets that were shared by eight media outlets. Then, we explore how those media edited tweets against original headlines, and the effects would be. To estimate the effects of editing news headlines for social media sharing in audience engagement, we present a systematic analysis that incorporates a causal inference technique with deep learning; using propensity score matching, it allows for estimating potential (dis-)advantages of an editing style compared to counterfactual cases where a similar news article is shared with a different style. According to the analyses of various editing styles, we report common and differing effects of the styles across the outlets. To understand the effects of various editing styles, media outlets could apply our easy-to-use tool by themselves.
What Was Written vs. Who Read It: News Media Profiling Using Text Analysis and Social Media Context
May 09, 2020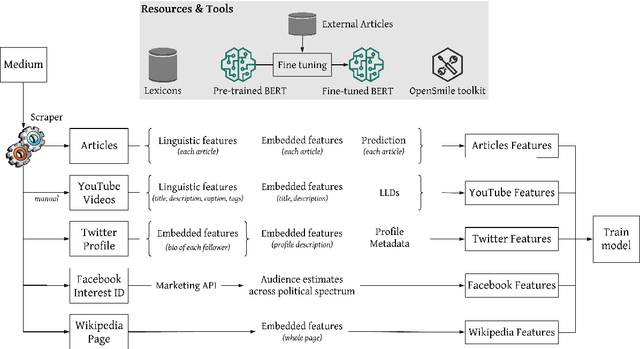
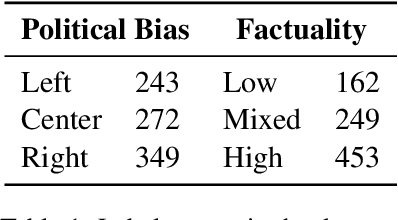
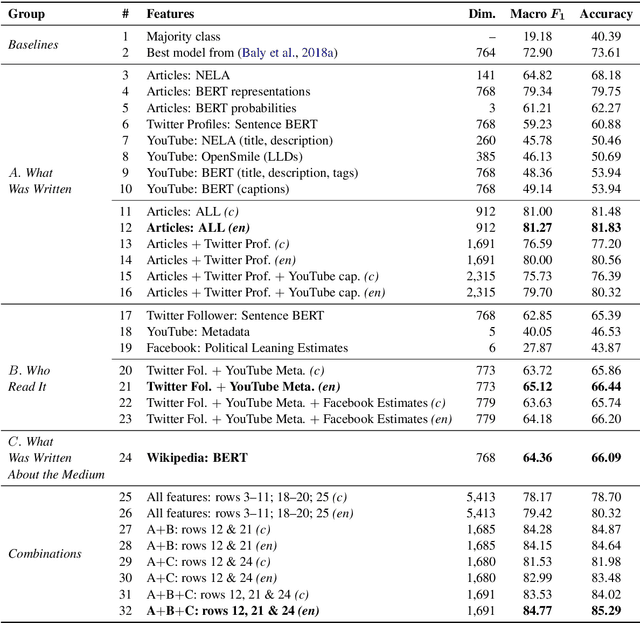
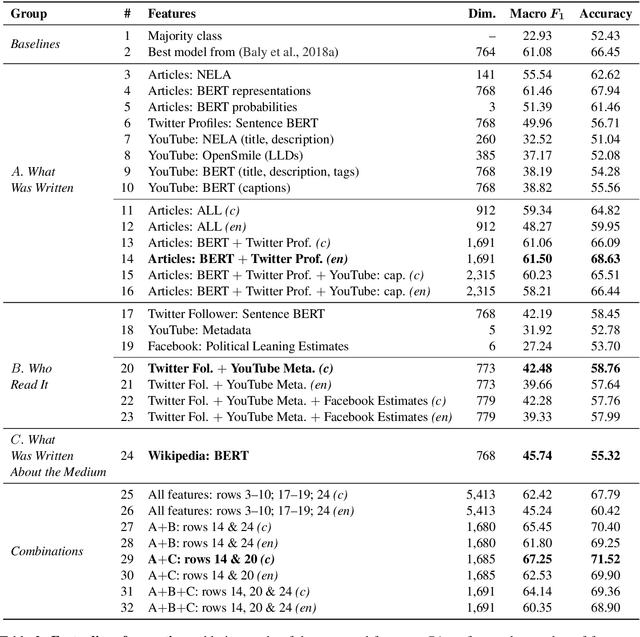
Predicting the political bias and the factuality of reporting of entire news outlets are critical elements of media profiling, which is an understudied but an increasingly important research direction. The present level of proliferation of fake, biased, and propagandistic content online, has made it impossible to fact-check every single suspicious claim, either manually or automatically. Alternatively, we can profile entire news outlets and look for those that are likely to publish fake or biased content. This approach makes it possible to detect likely "fake news" the moment they are published, by simply checking the reliability of their source. From a practical perspective, political bias and factuality of reporting have a linguistic aspect but also a social context. Here, we study the impact of both, namely (i) what was written (i.e., what was published by the target medium, and how it describes itself on Twitter) vs. (ii) who read it (i.e., analyzing the readers of the target medium on Facebook, Twitter, and YouTube). We further study (iii) what was written about the target medium on Wikipedia. The evaluation results show that what was written matters most, and that putting all information sources together yields huge improvements over the current state-of-the-art.
* Factuality of reporting, fact-checking, political ideology, media bias, disinformation, propaganda, social media, news media
A Systematic Media Frame Analysis of 1.5 Million New York Times Articles from 2000 to 2017
May 04, 2020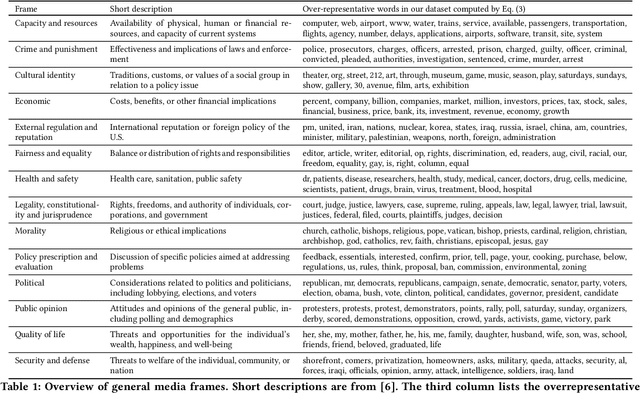
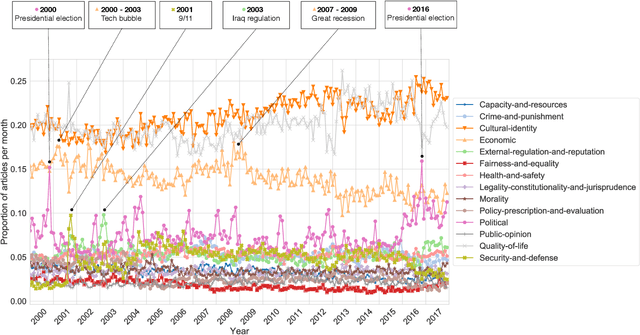
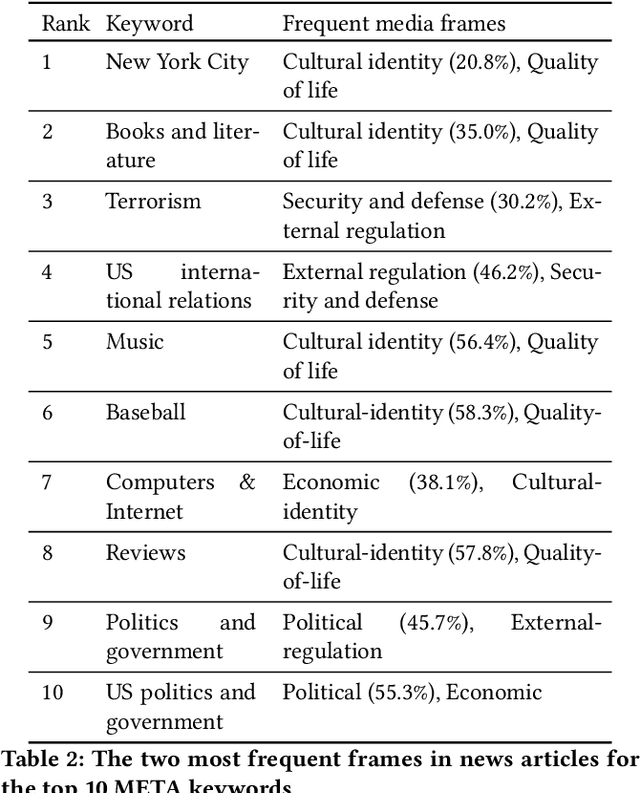
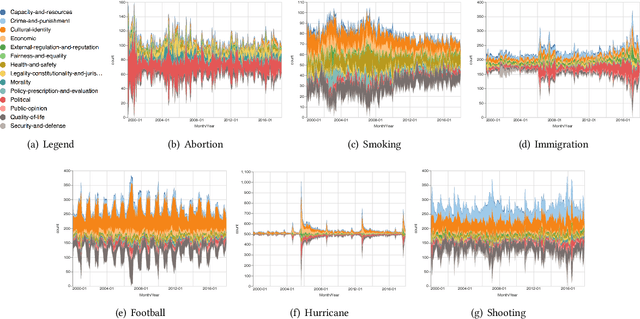
Framing is an indispensable narrative device for news media because even the same facts may lead to conflicting understandings if deliberate framing is employed. Therefore, identifying media framing is a crucial step to understanding how news media influence the public. Framing is, however, difficult to operationalize and detect, and thus traditional media framing studies had to rely on manual annotation, which is challenging to scale up to massive news datasets. Here, by developing a media frame classifier that achieves state-of-the-art performance, we systematically analyze the media frames of 1.5 million New York Times articles published from 2000 to 2017. By examining the ebb and flow of media frames over almost two decades, we show that short-term frame abundance fluctuation closely corresponds to major events, while there also exist several long-term trends, such as the gradually increasing prevalence of the ``Cultural identity'' frame. By examining specific topics and sentiments, we identify characteristics and dynamics of each frame. Finally, as a case study, we delve into the framing of mass shootings, revealing three major framing patterns. Our scalable, computational approach to massive news datasets opens up new pathways for systematic media framing studies.
FrameAxis: Characterizing Framing Bias and Intensity with Word Embedding
Feb 22, 2020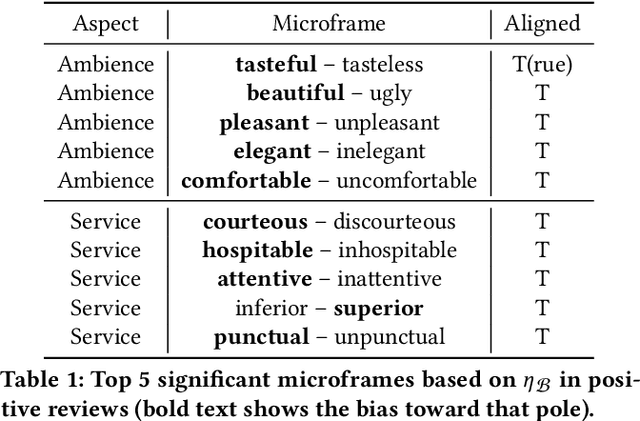
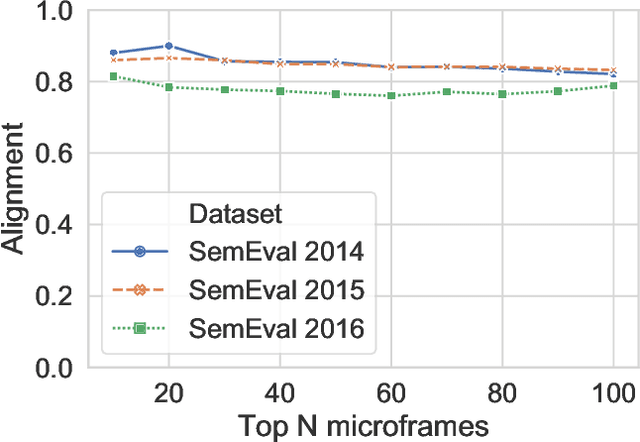
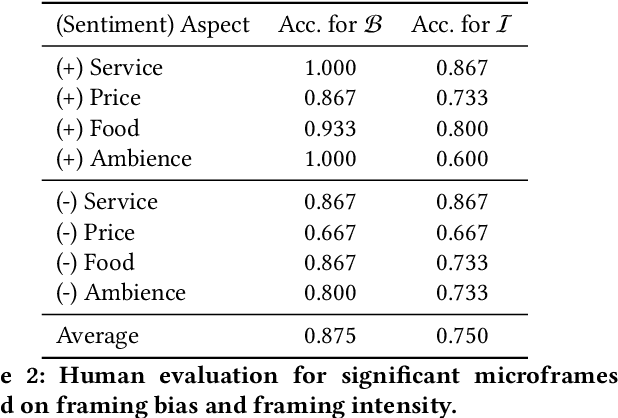
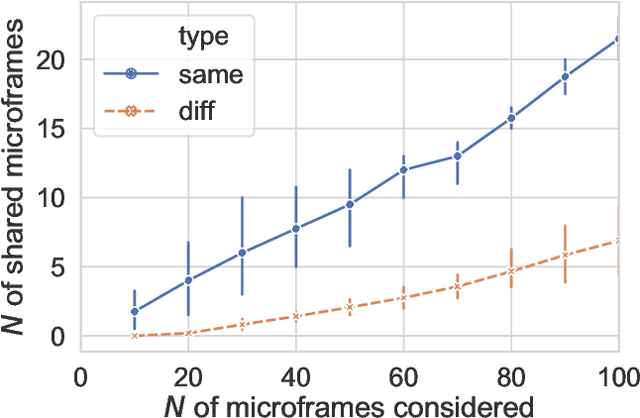
We propose FrameAxis, a method of characterizing the framing of a given text by identifying the most relevant semantic axes ("microframes") defined by antonym word pairs. In contrast to the traditional framing analysis, which has been constrained by a small number of manually annotated general frames, our unsupervised approach provides much more detailed insights, by considering a host of semantic axes. Our method is capable of quantitatively teasing out framing bias -- how biased a text is in each microframe -- and framing intensity -- how much each microframe is used -- from the text, offering a nuanced characterization of framing. We evaluate our approach using SemEval datasets as well as three other datasets and human evaluations, demonstrating that FrameAxis can reliably characterize documents with relevant microframes. Our method may allow scalable and nuanced computational analyses of framing across disciplines.
Tanbih: Get To Know What You Are Reading
Oct 04, 2019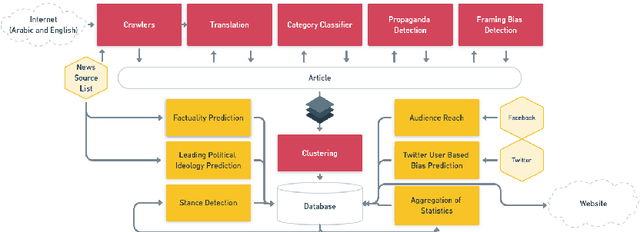
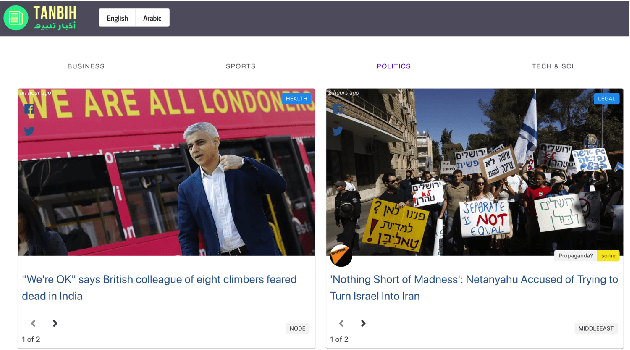
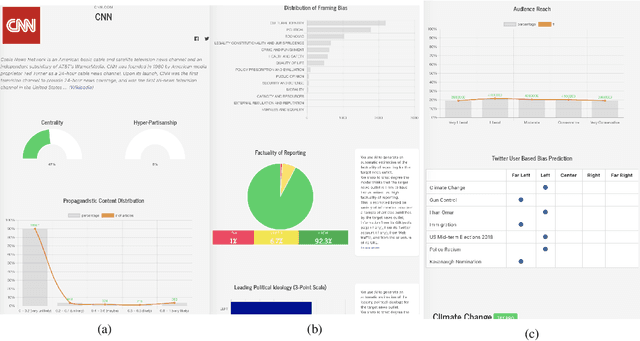
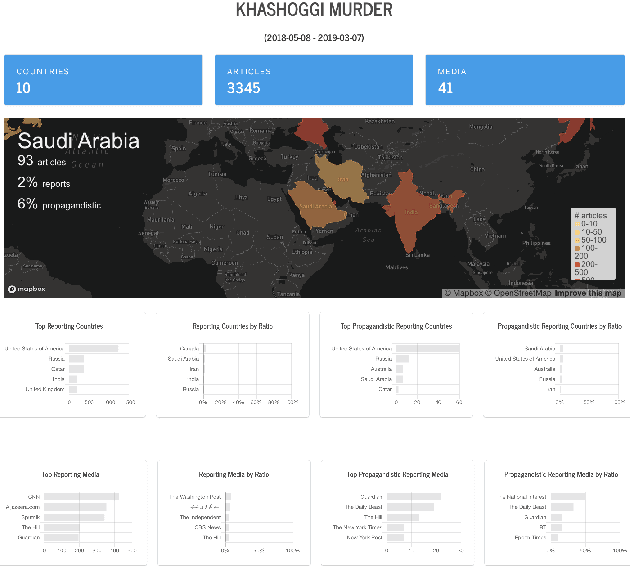
We introduce Tanbih, a news aggregator with intelligent analysis tools to help readers understanding what's behind a news story. Our system displays news grouped into events and generates media profiles that show the general factuality of reporting, the degree of propagandistic content, hyper-partisanship, leading political ideology, general frame of reporting, and stance with respect to various claims and topics of a news outlet. In addition, we automatically analyse each article to detect whether it is propagandistic and to determine its stance with respect to a number of controversial topics.
Political Discussions in Homogeneous and Cross-Cutting Communication Spaces
Apr 11, 2019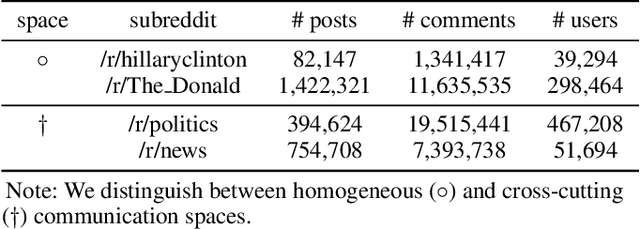
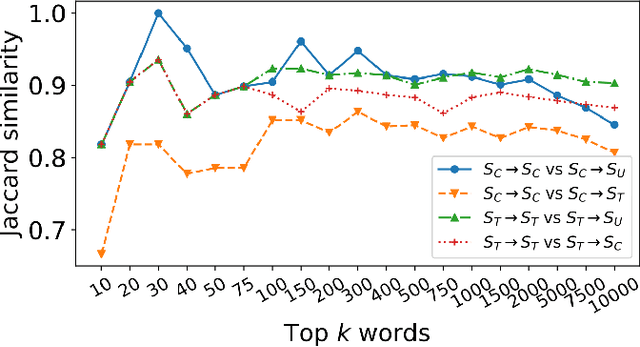
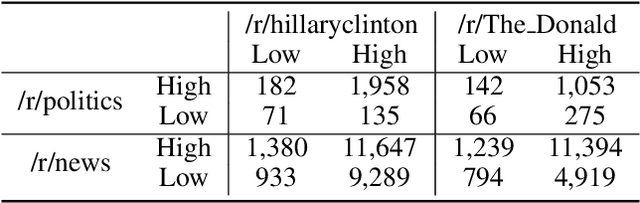
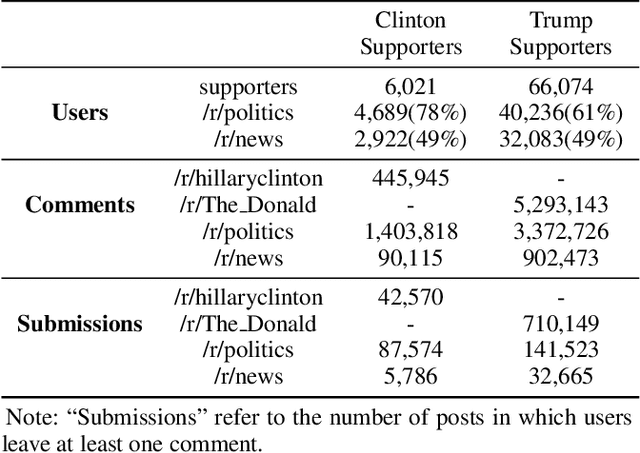
Online platforms, such as Facebook, Twitter, and Reddit, provide users with a rich set of features for sharing and consuming political information, expressing political opinions, and exchanging potentially contrary political views. In such activities, two types of communication spaces naturally emerge: those dominated by exchanges between politically homogeneous users and those that allow and encourage cross-cutting exchanges in politically heterogeneous groups. While research on political talk in online environments abounds, we know surprisingly little about the potentially varying nature of discussions in politically homogeneous spaces as compared to cross-cutting communication spaces. To fill this gap, we use Reddit to explore the nature of political discussions in homogeneous and cross-cutting communication spaces. In particular, we develop an analytical template to study interaction and linguistic patterns within and between politically homogeneous and heterogeneous communication spaces. Our analyses reveal different behavioral patterns in homogeneous and cross-cutting communications spaces. We discuss theoretical and practical implications in the context of research on political talk online.