 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Approach to Adding Differential Privacy to Iterative Training Procedures
Dec 15, 2018
In this work we address the practical challenges of training machine learning models on privacy-sensitive datasets by introducing a modular approach that minimizes changes to training algorithms, provides a variety of configuration strategies for the privacy mechanism, and then isolates and simplifies the critical logic that computes the final privacy guarantees. A key challenge is that training algorithms often require estimating many different quantities (vectors) from the same set of examples --- for example, gradients of different layers in a deep learning architecture, as well as metrics and batch normalization parameters. Each of these may have different properties like dimensionality, magnitude, and tolerance to noise. By extending previous work on the Moments Accountant for the subsampled Gaussian mechanism, we can provide privacy for such heterogeneous sets of vectors, while also structuring the approach to minimize software engineering challenges.
Learning Differentially Private Recurrent Language Models
Feb 24, 2018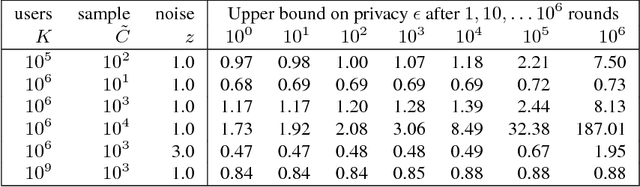
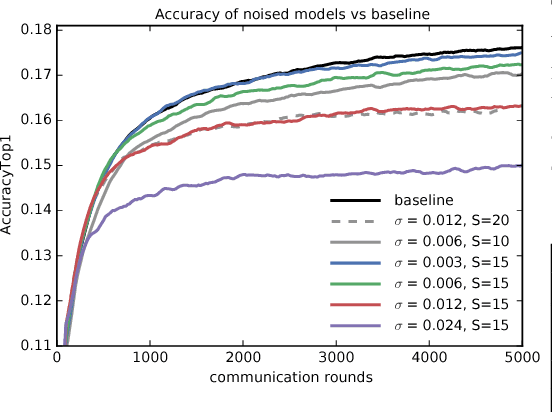
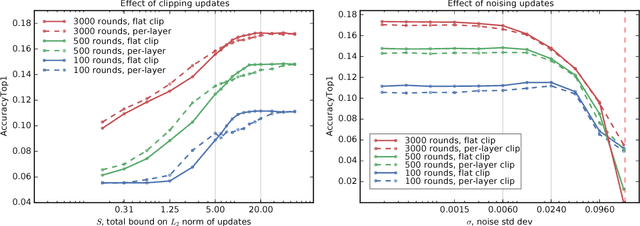
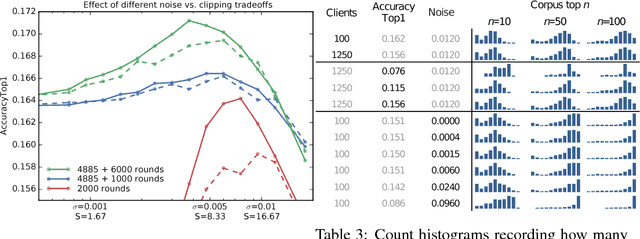
We demonstrate that it is possible to train large recurrent language models with user-level differential privacy guarantees with only a negligible cost in predictive accuracy. Our work builds on recent advances in the training of deep networks on user-partitioned data and privacy accounting for stochastic gradient descent. In particular, we add user-level privacy protection to the federated averaging algorithm, which makes "large step" updates from user-level data. Our work demonstrates that given a dataset with a sufficiently large number of users (a requirement easily met by even small internet-scale datasets), achieving differential privacy comes at the cost of increased computation, rather than in decreased utility as in most prior work. We find that our private LSTM language models are quantitatively and qualitatively similar to un-noised models when trained on a large dataset.
Federated Learning: Strategies for Improving Communication Efficiency
Oct 30, 2017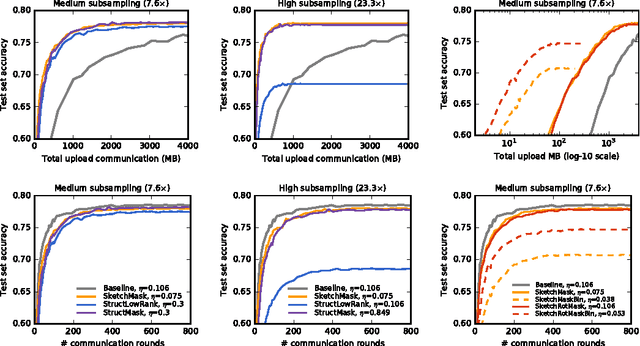
Federated Learning is a machine learning setting where the goal is to train a high-quality centralized model while training data remains distributed over a large number of clients each with unreliable and relatively slow network connections. We consider learning algorithms for this setting where on each round, each client independently computes an update to the current model based on its local data, and communicates this update to a central server, where the client-side updates are aggregated to compute a new global model. The typical clients in this setting are mobile phones, and communication efficiency is of the utmost importance. In this paper, we propose two ways to reduce the uplink communication costs: structured updates, where we directly learn an update from a restricted space parametrized using a smaller number of variables, e.g. either low-rank or a random mask; and sketched updates, where we learn a full model update and then compress it using a combination of quantization, random rotations, and subsampling before sending it to the server. Experiments on both convolutional and recurrent networks show that the proposed methods can reduce the communication cost by two orders of magnitude.
Distributed Mean Estimation with Limited Communication
Sep 25, 2017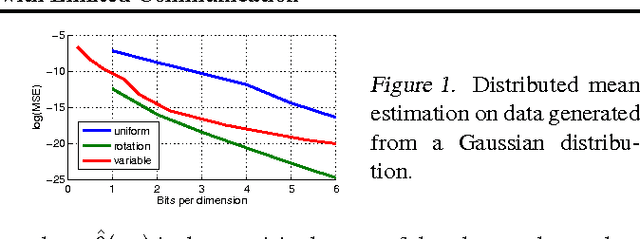
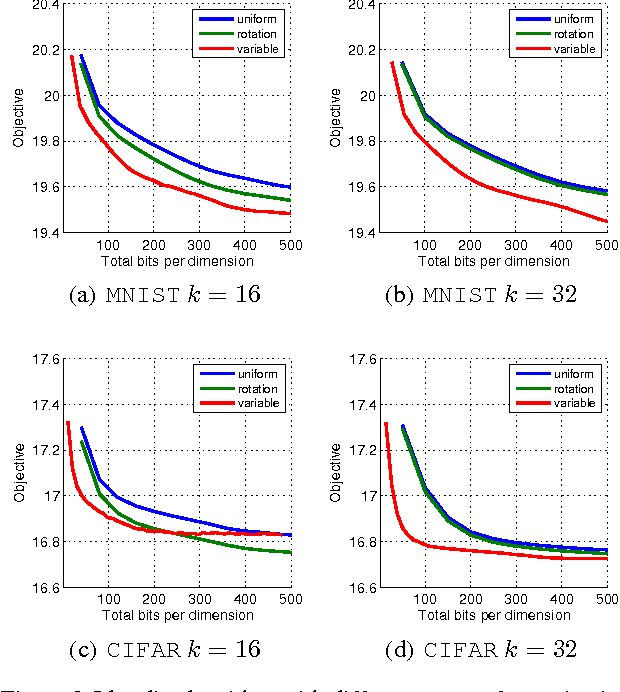
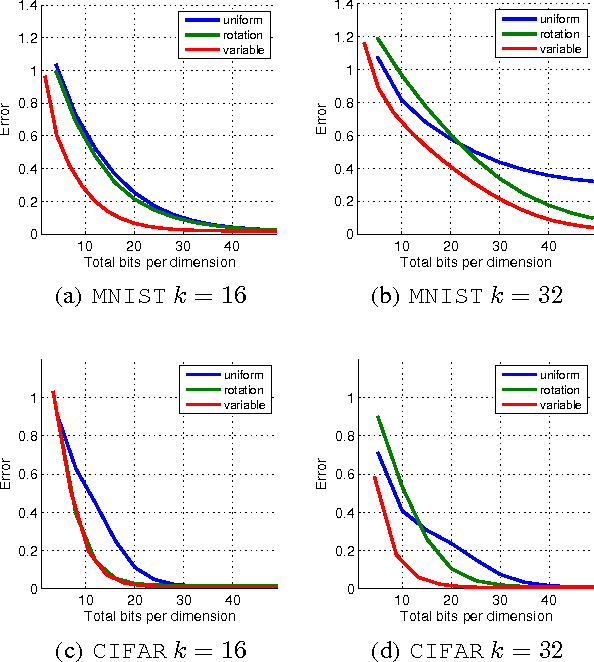
Motivated by the need for distributed learning and optimization algorithms with low communication cost, we study communication efficient algorithms for distributed mean estimation. Unlike previous works, we make no probabilistic assumptions on the data. We first show that for $d$ dimensional data with $n$ clients, a naive stochastic binary rounding approach yields a mean squared error (MSE) of $\Theta(d/n)$ and uses a constant number of bits per dimension per client. We then extend this naive algorithm in two ways: we show that applying a structured random rotation before quantization reduces the error to $\mathcal{O}((\log d)/n)$ and a better coding strategy further reduces the error to $\mathcal{O}(1/n)$ and uses a constant number of bits per dimension per client. We also show that the latter coding strategy is optimal up to a constant in the minimax sense i.e., it achieves the best MSE for a given communication cost. We finally demonstrate the practicality of our algorithms by applying them to distributed Lloyd's algorithm for k-means and power iteration for PCA.
On the Protection of Private Information in Machine Learning Systems: Two Recent Approaches
Aug 26, 2017The recent, remarkable growth of machine learning has led to intense interest in the privacy of the data on which machine learning relies, and to new techniques for preserving privacy. However, older ideas about privacy may well remain valid and useful. This note reviews two recent works on privacy in the light of the wisdom of some of the early literature, in particular the principles distilled by Saltzer and Schroeder in the 1970s.
Communication-Efficient Learning of Deep Networks from Decentralized Data
Feb 28, 2017

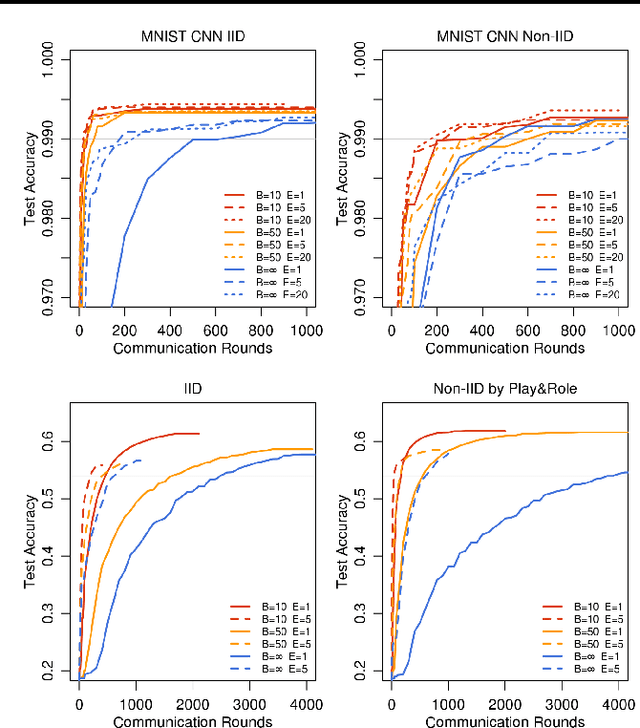
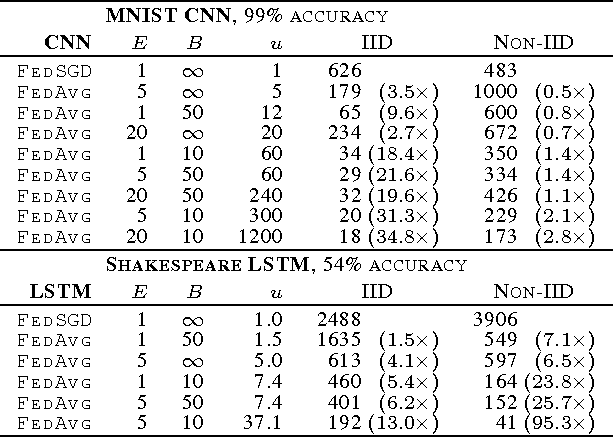
Modern mobile devices have access to a wealth of data suitable for learning models, which in turn can greatly improve the user experience on the device. For example, language models can improve speech recognition and text entry, and image models can automatically select good photos. However, this rich data is often privacy sensitive, large in quantity, or both, which may preclude logging to the data center and training there using conventional approaches. We advocate an alternative that leaves the training data distributed on the mobile devices, and learns a shared model by aggregating locally-computed updates. We term this decentralized approach Federated Learning. We present a practical method for the federated learning of deep networks based on iterative model averaging, and conduct an extensive empirical evaluation, considering five different model architectures and four datasets. These experiments demonstrate the approach is robust to the unbalanced and non-IID data distributions that are a defining characteristic of this setting. Communication costs are the principal constraint, and we show a reduction in required communication rounds by 10-100x as compared to synchronized stochastic gradient descent.
* This version updates the large-scale LSTM experiments, along with other minor changes. In earlier versions, an inconsistency in our implementation of FedSGD caused us to report much lower learning rates for the large-scale LSTM. We reran these experiments, and also found that fewer local epochs offers better performance, leading to slightly better results for FedAvg than previously reported
Practical Secure Aggregation for Federated Learning on User-Held Data
Nov 14, 2016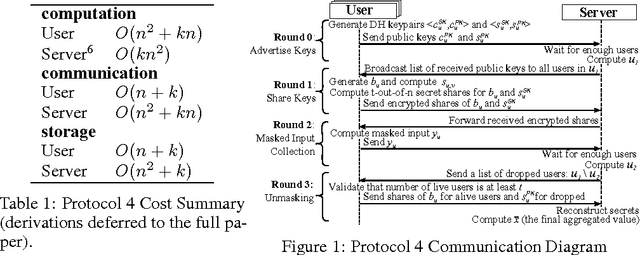
Secure Aggregation protocols allow a collection of mutually distrust parties, each holding a private value, to collaboratively compute the sum of those values without revealing the values themselves. We consider training a deep neural network in the Federated Learning model, using distributed stochastic gradient descent across user-held training data on mobile devices, wherein Secure Aggregation protects each user's model gradient. We design a novel, communication-efficient Secure Aggregation protocol for high-dimensional data that tolerates up to 1/3 users failing to complete the protocol. For 16-bit input values, our protocol offers 1.73x communication expansion for $2^{10}$ users and $2^{20}$-dimensional vectors, and 1.98x expansion for $2^{14}$ users and $2^{24}$ dimensional vectors.
Deep Learning with Differential Privacy
Oct 24, 2016
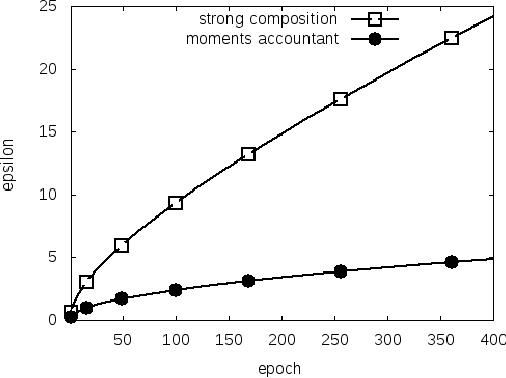
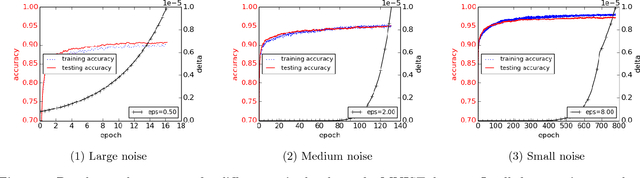
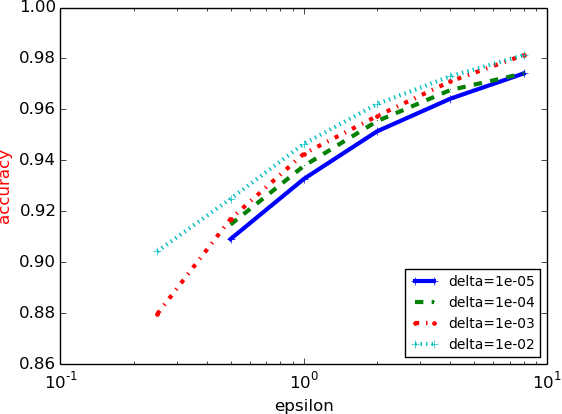
Machine learning techniques based on neural networks are achieving remarkable results in a wide variety of domains. Often, the training of models requires large, representative datasets, which may be crowdsourced and contain sensitive information. The models should not expose private information in these datasets. Addressing this goal, we develop new algorithmic techniques for learning and a refined analysis of privacy costs within the framework of differential privacy. Our implementation and experiments demonstrate that we can train deep neural networks with non-convex objectives, under a modest privacy budget, and at a manageable cost in software complexity, training efficiency, and model quality.
Federated Optimization: Distributed Machine Learning for On-Device Intelligence
Oct 08, 2016
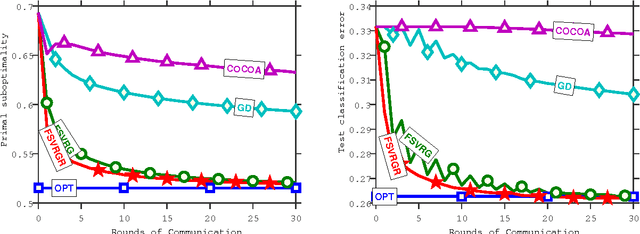

We introduce a new and increasingly relevant setting for distributed optimization in machine learning, where the data defining the optimization are unevenly distributed over an extremely large number of nodes. The goal is to train a high-quality centralized model. We refer to this setting as Federated Optimization. In this setting, communication efficiency is of the utmost importance and minimizing the number of rounds of communication is the principal goal. A motivating example arises when we keep the training data locally on users' mobile devices instead of logging it to a data center for training. In federated optimziation, the devices are used as compute nodes performing computation on their local data in order to update a global model. We suppose that we have extremely large number of devices in the network --- as many as the number of users of a given service, each of which has only a tiny fraction of the total data available. In particular, we expect the number of data points available locally to be much smaller than the number of devices. Additionally, since different users generate data with different patterns, it is reasonable to assume that no device has a representative sample of the overall distribution. We show that existing algorithms are not suitable for this setting, and propose a new algorithm which shows encouraging experimental results for sparse convex problems. This work also sets a path for future research needed in the context of \federated optimization.
A Survey of Algorithms and Analysis for Adaptive Online Learning
Nov 09, 2015

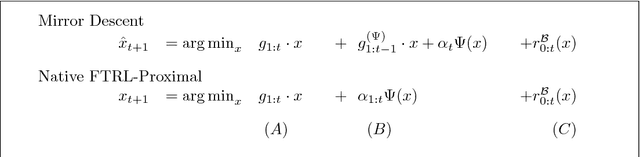
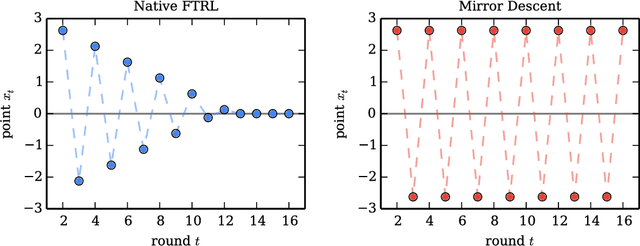
We present tools for the analysis of Follow-The-Regularized-Leader (FTRL), Dual Averaging, and Mirror Descent algorithms when the regularizer (equivalently, prox-function or learning rate schedule) is chosen adaptively based on the data. Adaptivity can be used to prove regret bounds that hold on every round, and also allows for data-dependent regret bounds as in AdaGrad-style algorithms (e.g., Online Gradient Descent with adaptive per-coordinate learning rates). We present results from a large number of prior works in a unified manner, using a modular and tight analysis that isolates the key arguments in easily re-usable lemmas. This approach strengthens pre-viously known FTRL analysis techniques to produce bounds as tight as those achieved by potential functions or primal-dual analysis. Further, we prove a general and exact equivalence between an arbitrary adaptive Mirror Descent algorithm and a correspond- ing FTRL update, which allows us to analyze any Mirror Descent algorithm in the same framework. The key to bridging the gap between Dual Averaging and Mirror Descent algorithms lies in an analysis of the FTRL-Proximal algorithm family. Our regret bounds are proved in the most general form, holding for arbitrary norms and non-smooth regularizers with time-varying weight.