 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Terrain Aware Bipedal Locomotion via Reduced Dimensional Perceptual Representations
Dec 15, 2025



This work introduces a hierarchical strategy for terrain-aware bipedal locomotion that integrates reduced-dimensional perceptual representations to enhance reinforcement learning (RL)-based high-level (HL) policies for real-time gait generation. Unlike end-to-end approaches, our framework leverages latent terrain encodings via a Convolutional Variational Autoencoder (CNN-VAE) alongside reduced-order robot dynamics, optimizing the locomotion decision process with a compact state. We systematically analyze the impact of latent space dimensionality on learning efficiency and policy robustness. Additionally, we extend our method to be history-aware, incorporating sequences of recent terrain observations into the latent representation to improve robustness. To address real-world feasibility, we introduce a distillation method to learn the latent representation directly from depth camera images and provide preliminary hardware validation by comparing simulated and real sensor data. We further validate our framework using the high-fidelity Agility Robotics (AR) simulator, incorporating realistic sensor noise, state estimation, and actuator dynamics. The results confirm the robustness and adaptability of our method, underscoring its potential for hardware deployment.
Rethink Repeatable Measures of Robot Performance with Statistical Query
May 13, 2025For a general standardized testing algorithm designed to evaluate a specific aspect of a robot's performance, several key expectations are commonly imposed. Beyond accuracy (i.e., closeness to a typically unknown ground-truth reference) and efficiency (i.e., feasibility within acceptable testing costs and equipment constraints), one particularly important attribute is repeatability. Repeatability refers to the ability to consistently obtain the same testing outcome when similar testing algorithms are executed on the same subject robot by different stakeholders, across different times or locations. However, achieving repeatable testing has become increasingly challenging as the components involved grow more complex, intelligent, diverse, and, most importantly, stochastic. While related efforts have addressed repeatability at ethical, hardware, and procedural levels, this study focuses specifically on repeatable testing at the algorithmic level. Specifically, we target the well-adopted class of testing algorithms in standardized evaluation: statistical query (SQ) algorithms (i.e., algorithms that estimate the expected value of a bounded function over a distribution using sampled data). We propose a lightweight, parameterized, and adaptive modification applicable to any SQ routine, whether based on Monte Carlo sampling, importance sampling, or adaptive importance sampling, that makes it provably repeatable, with guaranteed bounds on both accuracy and efficiency. We demonstrate the effectiveness of the proposed approach across three representative scenarios: (i) established and widely adopted standardized testing of manipulators, (ii) emerging intelligent testing algorithms for operational risk assessment in automated vehicles, and (iii) developing use cases involving command tracking performance evaluation of humanoid robots in locomotion tasks.
Real-Time Safe Bipedal Robot Navigation using Linear Discrete Control Barrier Functions
Nov 06, 2024Safe navigation in real-time is an essential task for humanoid robots in real-world deployment. Since humanoid robots are inherently underactuated thanks to unilateral ground contacts, a path is considered safe if it is obstacle-free and respects the robot's physical limitations and underlying dynamics. Existing approaches often decouple path planning from gait control due to the significant computational challenge caused by the full-order robot dynamics. In this work, we develop a unified, safe path and gait planning framework that can be evaluated online in real-time, allowing the robot to navigate clustered environments while sustaining stable locomotion. Our approach uses the popular Linear Inverted Pendulum (LIP) model as a template model to represent walking dynamics. It incorporates heading angles in the model to evaluate kinematic constraints essential for physically feasible gaits properly. In addition, we leverage discrete control barrier functions (DCBF) for obstacle avoidance, ensuring that the subsequent foot placement provides a safe navigation path within clustered environments. To guarantee real-time computation, we use a novel approximation of the DCBF to produce linear DCBF (LDCBF) constraints. We validate the proposed approach in simulation using a Digit robot in randomly generated environments. The results demonstrate that our approach can generate safe gaits for a non-trivial humanoid robot to navigate environments with randomly generated obstacles in real-time.
Repeatable and Reliable Efforts of Accelerated Risk Assessment
May 30, 2024



Risk assessment of a robot in controlled environments, such as laboratories and proving grounds, is a common means to assess, certify, validate, verify, and characterize the robots' safety performance before, during, and even after their commercialization in the real-world. A standard testing program that acquires the risk estimate is expected to be (i) repeatable, such that it obtains similar risk assessments of the same testing subject among multiple trials or attempts with the similar testing effort by different stakeholders, and (ii) reliable against a variety of testing subjects produced by different vendors and manufacturers. Both repeatability and reliability are fundamental and crucial for a testing algorithm's validity, fairness, and practical feasibility, especially for standardization. However, these properties are rarely satisfied or ensured, especially as the subject robots become more complex, uncertain, and varied. This issue was present in traditional risk assessments through Monte-Carlo sampling, and remains a bottleneck for the recent accelerated risk assessment methods, primarily those using importance sampling. This study aims to enhance existing accelerated testing frameworks by proposing a new algorithm that provably integrates repeatability and reliability with the already established formality and efficiency. It also features demonstrations assessing the risk of instability from frontal impacts, initiated by push-over disturbances on a controlled inverted pendulum and a 7-DoF planar bipedal robot Rabbit managed by various control algorithms.
Data-Driven Latent Space Representation for Robust Bipedal Locomotion Learning
Sep 27, 2023



This paper presents a novel framework for learning robust bipedal walking by combining a data-driven state representation with a Reinforcement Learning (RL) based locomotion policy. The framework utilizes an autoencoder to learn a low-dimensional latent space that captures the complex dynamics of bipedal locomotion from existing locomotion data. This reduced dimensional state representation is then used as states for training a robust RL-based gait policy, eliminating the need for heuristic state selections or the use of template models for gait planning. The results demonstrate that the learned latent variables are disentangled and directly correspond to different gaits or speeds, such as moving forward, backward, or walking in place. Compared to traditional template model-based approaches, our framework exhibits superior performance and robustness in simulation. The trained policy effectively tracks a wide range of walking speeds and demonstrates good generalization capabilities to unseen scenarios.
Template Model Inspired Task Space Learning for Robust Bipedal Locomotion
Sep 27, 2023



This work presents a hierarchical framework for bipedal locomotion that combines a Reinforcement Learning (RL)-based high-level (HL) planner policy for the online generation of task space commands with a model-based low-level (LL) controller to track the desired task space trajectories. Different from traditional end-to-end learning approaches, our HL policy takes insights from the angular momentum-based linear inverted pendulum (ALIP) to carefully design the observation and action spaces of the Markov Decision Process (MDP). This simple yet effective design creates an insightful mapping between a low-dimensional state that effectively captures the complex dynamics of bipedal locomotion and a set of task space outputs that shape the walking gait of the robot. The HL policy is agnostic to the task space LL controller, which increases the flexibility of the design and generalization of the framework to other bipedal robots. This hierarchical design results in a learning-based framework with improved performance, data efficiency, and robustness compared with the ALIP model-based approach and state-of-the-art learning-based frameworks for bipedal locomotion. The proposed hierarchical controller is tested in three different robots, Rabbit, a five-link underactuated planar biped; Walker2D, a seven-link fully-actuated planar biped; and Digit, a 3D humanoid robot with 20 actuated joints. The trained policy naturally learns human-like locomotion behaviors and is able to effectively track a wide range of walking speeds while preserving the robustness and stability of the walking gait even under adversarial conditions.
Towards Standardized Disturbance Rejection Testing of Legged Robot Locomotion with Linear Impactor: A Preliminary Study, Observations, and Implications
Aug 28, 2023



Dynamic locomotion in legged robots is close to industrial collaboration, but a lack of standardized testing obstructs commercialization. The issues are not merely political, theoretical, or algorithmic but also physical, indicating limited studies and comprehension regarding standard testing infrastructure and equipment. For decades, the approaches we have been testing legged robots were rarely standardizable with hand-pushing, foot-kicking, rope-dragging, stick-poking, and ball-swinging. This paper aims to bridge the gap by proposing the use of the linear impactor, a well-established tool in other standardized testing disciplines, to serve as an adaptive, repeatable, and fair disturbance rejection testing equipment for legged robots. A pneumatic linear impactor is also adopted for the case study involving the humanoid robot Digit. Three locomotion controllers are examined, including a commercial one, using a walking-in-place task against frontal impacts. The statistically best controller was able to withstand the impact momentum (26.376 kg$\cdot$m/s) on par with a reported average effective momentum from straight punches by Olympic boxers (26.506 kg$\cdot$m/s). Moreover, the case study highlights other anti-intuitive observations, demonstrations, and implications that, to the best of the authors' knowledge, are first-of-its-kind revealed in real-world testing of legged robots.
Rethink the Adversarial Scenario-based Safety Testing of Robots: the Comparability and Optimal Aggressiveness
Sep 20, 2022
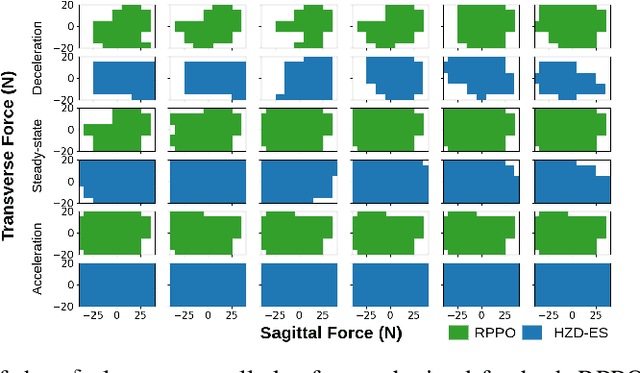
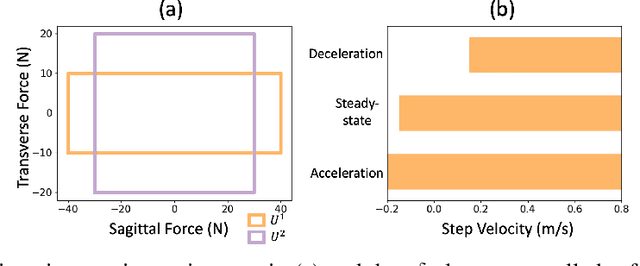
This paper studies the class of scenario-based safety testing algorithms in the black-box safety testing configuration. For algorithms sharing the same state-action set coverage with different sampling distributions, it is commonly believed that prioritizing the exploration of high-risk state-actions leads to a better sampling efficiency. Our proposal disputes the above intuition by introducing an impossibility theorem that provably shows all safety testing algorithms of the aforementioned difference perform equally well with the same expected sampling efficiency. Moreover, for testing algorithms covering different sets of state-actions, the sampling efficiency criterion is no longer applicable as different algorithms do not necessarily converge to the same termination condition. We then propose a testing aggressiveness definition based on the almost safe set concept along with an unbiased and efficient algorithm that compares the aggressiveness between testing algorithms. Empirical observations from the safety testing of bipedal locomotion controllers and vehicle decision-making modules are also presented to support the proposed theoretical implications and methodologies.
On Safety Testing, Validation, and Characterization with Scenario-Sampling: A Case Study of Legged Robots
Apr 16, 2022
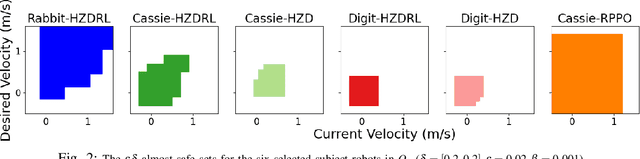
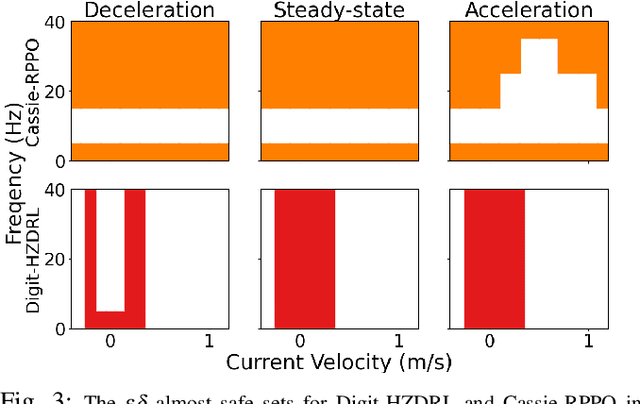
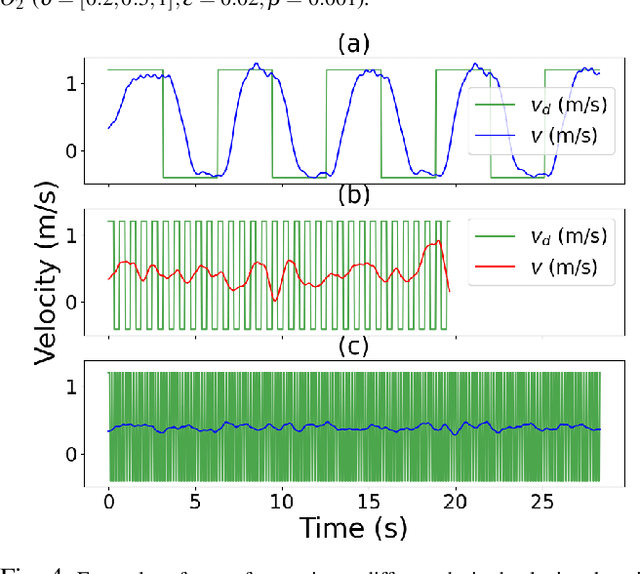
The dynamic response of the legged robot locomotion is non-Lipschitz and can be stochastic due to environmental uncertainties. To test, validate, and characterize the safety performance of legged robots, existing solutions on observed and inferred risk can be incomplete and sampling inefficient. Some formal verification methods suffer from the model precision and other surrogate assumptions. In this paper, we propose a scenario sampling based testing framework that characterizes the overall safety performance of a legged robot by specifying (i) where (in terms of a set of states) the robot is potentially safe, and (ii) how safe the robot is within the specified set. The framework can also help certify the commercial deployment of the legged robot in real-world environment along with human and compare safety performance among legged robots with different mechanical structures and dynamic properties. The proposed framework is further deployed to evaluate a group of state-of-the-art legged robot locomotion controllers from various model-based, deep neural network involved, and reinforcement learning based methods in the literature. Among a series of intended work domains of the studied legged robots (e.g. tracking speed on sloped surface, with abrupt changes on demanded velocity, and against adversarial push-over disturbances), we show that the method can adequately capture the overall safety characterization and the subtle performance insights. Many of the observed safety outcomes, to the best of our knowledge, have never been reported by the existing work in the legged robot literature.
Linear Policies are Sufficient to Realize Robust Bipedal Walking on Challenging Terrains
Oct 05, 2021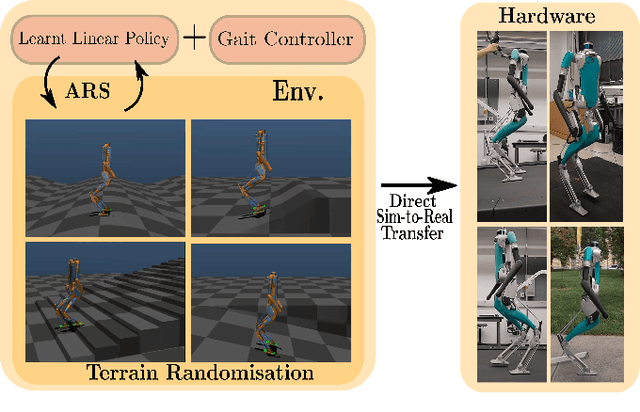
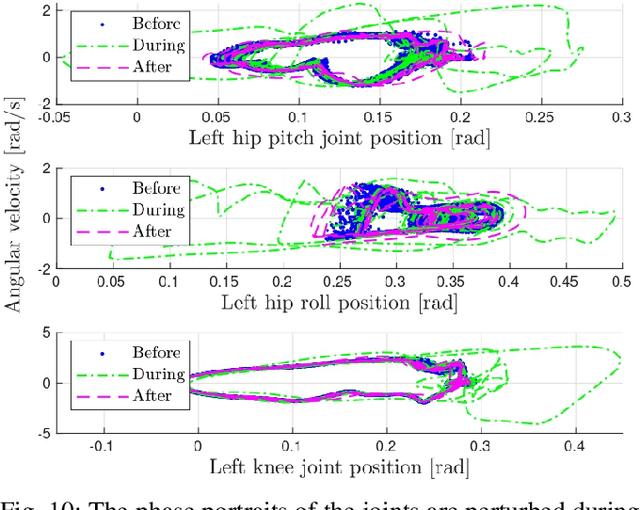
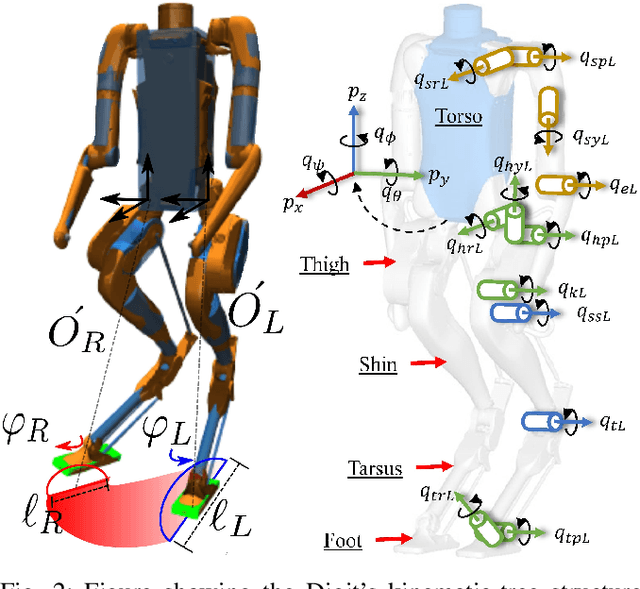
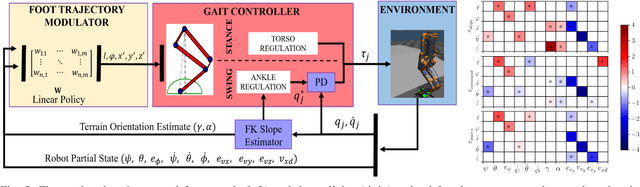
In this work, we demonstrate robust walking in the bipedal robot Digit on uneven terrains by just learning a single linear policy. In particular, we propose a new control pipeline, wherein the high-level trajectory modulator shapes the end-foot ellipsoidal trajectories, and the low-level gait controller regulates the torso and ankle orientation. The foot-trajectory modulator uses a linear policy and the regulator uses a linear PD control law. As opposed to neural network-based policies, the proposed linear policy has only 13 learnable parameters, thereby not only guaranteeing sample efficient learning but also enabling simplicity and interpretability of the policy. This is achieved with no loss of performance on challenging terrains like slopes, stairs and outdoor landscapes. We first demonstrate robust walking in the custom simulation environment, MuJoCo, and then directly transfer to hardware with no modification of the control pipeline. We subject the biped to a series of pushes and terrain height changes, both indoors and outdoors, thereby validating the presented work.