 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transformations for Classification Forests
Feb 06, 2014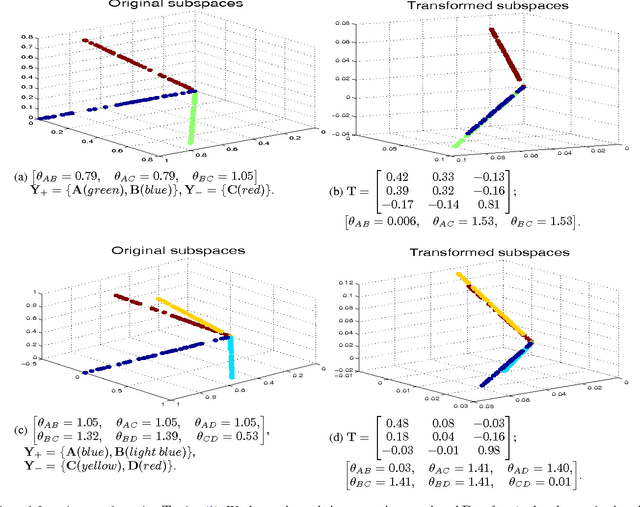
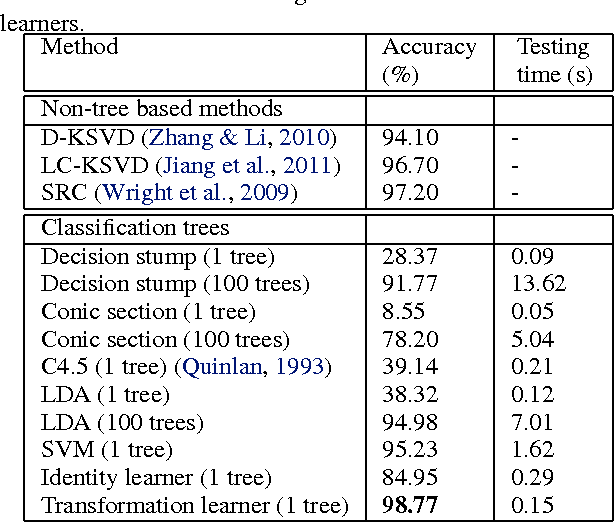


This work introduces a transformation-based learner model for classification forests. The weak learner at each split node plays a crucial role in a classification tree. We propose to optimize the splitting objective by learning a linear transformation on subspaces using nuclear norm as the optimization criteria. The learned linear transformation restores a low-rank structure for data from the same class, and, at the same time, maximizes the separation between different classes, thereby improving the performance of the split function. Theoretical and experimental results support the proposed framework.
Robust Multimodal Graph Matching: Sparse Coding Meets Graph Matching
Nov 25, 2013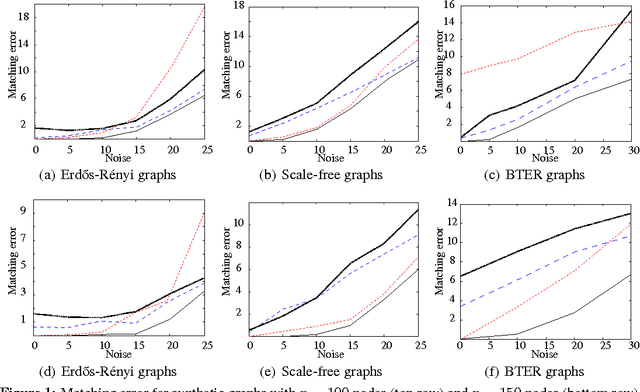
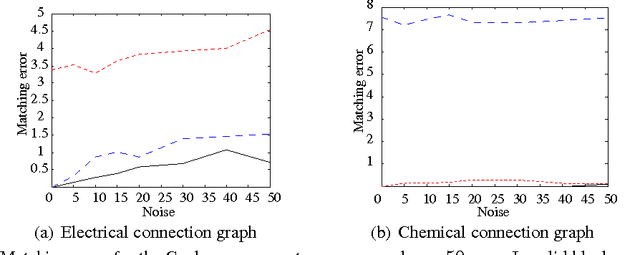
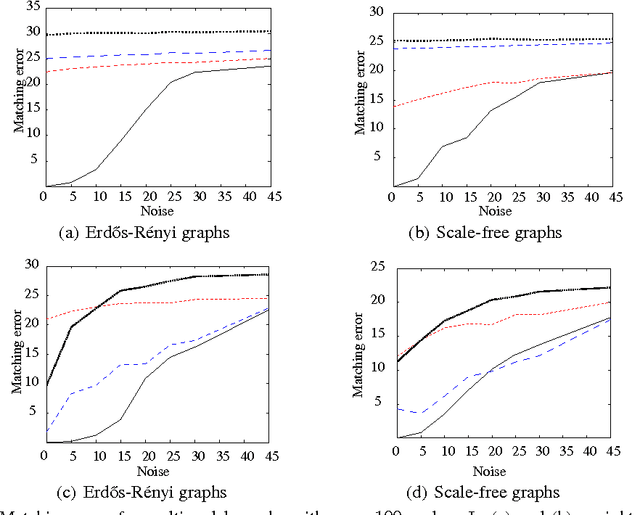
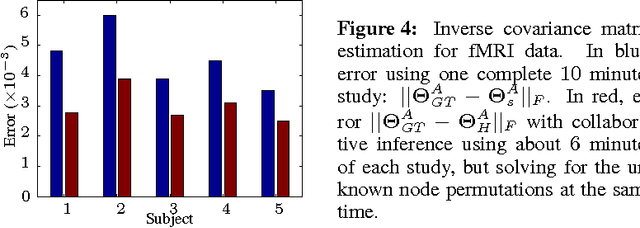
Graph matching is a challenging problem with very important applications in a wide range of fields, from image and video analysis to biological and biomedical problems. We propose a robust graph matching algorithm inspired in sparsity-related techniques. We cast the problem, resembling group or collaborative sparsity formulations, as a non-smooth convex optimization problem that can be efficiently solved using augmented Lagrangian techniques. The method can deal with weighted or unweighted graphs, as well as multimodal data, where different graphs represent different types of data. The proposed approach is also naturally integrated with collaborative graph inference techniques, solving general network inference problems where the observed variables, possibly coming from different modalities, are not in correspondence. The algorithm is tested and compared with state-of-the-art graph matching techniques in both synthetic and real graphs. We also present results on multimodal graphs and applications to collaborative inference of brain connectivity from alignment-free functional magnetic resonance imaging (fMRI) data. The code is publicly available.
Adaptive Temporal Compressive Sensing for Video
Oct 15, 2013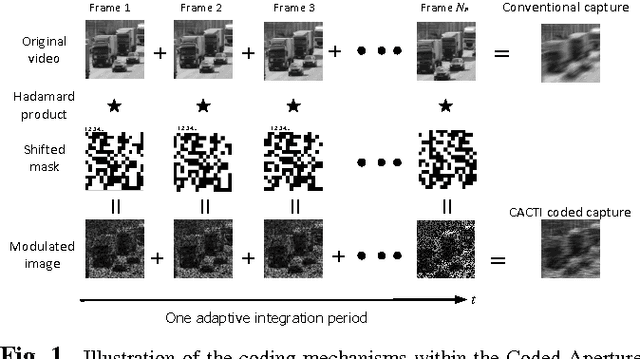
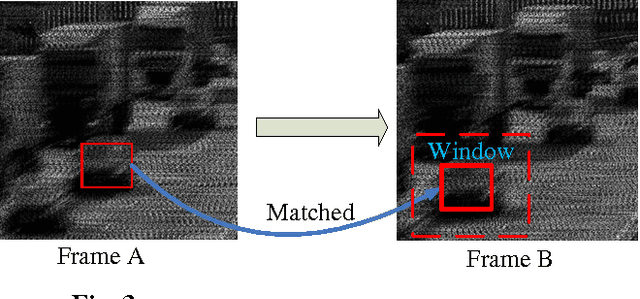

This paper introduces the concept of adaptive temporal compressive sensing (CS) for video. We propose a CS algorithm to adapt the compression ratio based on the scene's temporal complexity, computed from the compressed data, without compromising the quality of the reconstructed video. The temporal adaptivity is manifested by manipulating the integration time of the camera, opening the possibility to real-time implementation. The proposed algorithm is a generalized temporal CS approach that can be incorporated with a diverse set of existing hardware systems.
Domain-invariant Face Recognition using Learned Low-rank Transformation
Aug 01, 2013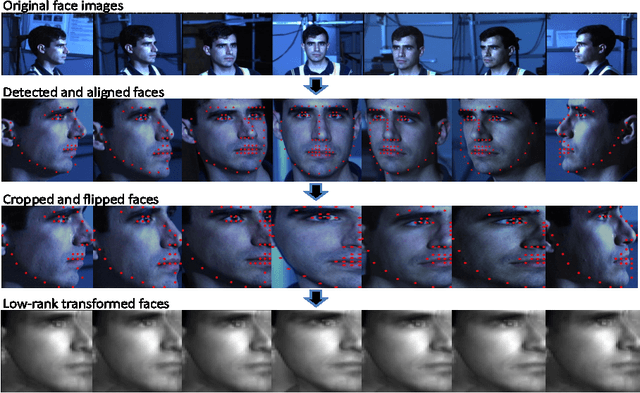
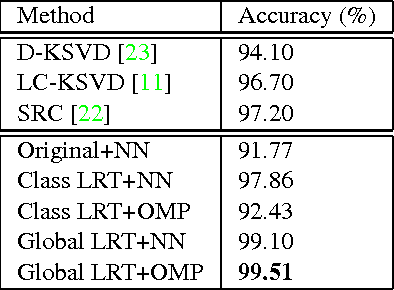

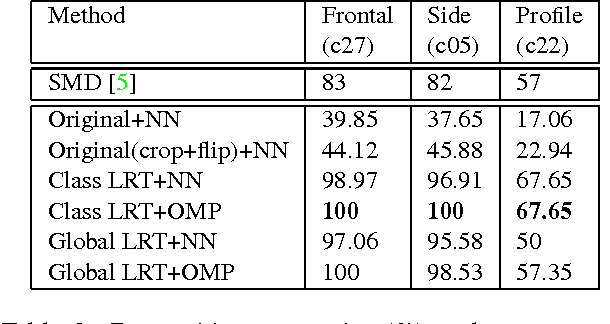
We present a low-rank transformation approach to compensate for face variations due to changes in visual domains, such as pose and illumination. The key idea is to learn discriminative linear transformations for face images using matrix rank as the optimization criteria. The learned linear transformations restore a shared low-rank structure for faces from the same subject, and, at the same time, force a high-rank structure for faces from different subjects. In this way, among the transformed faces, we reduce variations caused by domain changes within the classes, and increase separations between the classes for better face recognition across domains. Extensive experiments using public datasets are presented to demonstrate the effectiveness of our approach for face recognition across domains. The potential of the approach for feature extraction in generic object recognition and coded aperture design are discussed as well.
Learning Robust Subspace Clustering
Aug 01, 2013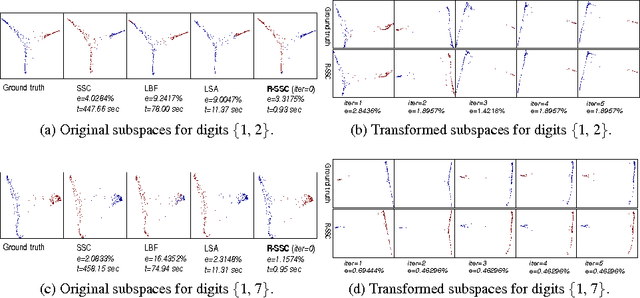

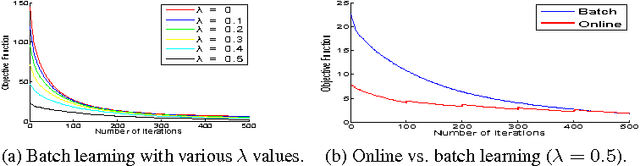

We propose a low-rank transformation-learning framework to robustify subspace clustering. Many high-dimensional data, such as face images and motion sequences, lie in a union of low-dimensional subspaces. The subspace clustering problem has been extensively studied in the literature to partition such high-dimensional data into clusters corresponding to their underlying low-dimensional subspaces. However, low-dimensional intrinsic structures are often violated for real-world observations, as they can be corrupted by errors or deviate from ideal models. We propose to address this by learning a linear transformation on subspaces using matrix rank, via its convex surrogate nuclear norm, as the optimization criteria. The learned linear transformation restores a low-rank structure for data from the same subspace, and, at the same time, forces a high-rank structure for data from different subspaces. In this way, we reduce variations within the subspaces, and increase separations between the subspaces for more accurate subspace clustering. This proposed learned robust subspace clustering framework significantly enhances the performance of existing subspace clustering methods. To exploit the low-rank structures of the transformed subspaces, we further introduce a subspace clustering technique, called Robust Sparse Subspace Clustering, which efficiently combines robust PCA with sparse modeling. We also discuss the online learning of the transformation, and learning of the transformation while simultaneously reducing the data dimensionality. Extensive experiments using public datasets are presented, showing that the proposed approach significantly outperforms state-of-the-art subspace clustering methods.
Video Human Segmentation using Fuzzy Object Models and its Application to Body Pose Estimation of Toddlers for Behavior Studies
May 29, 2013
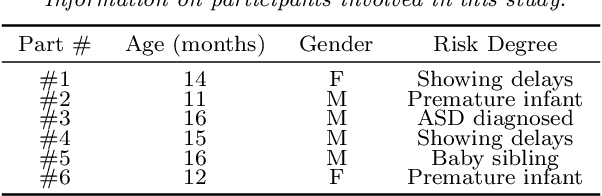
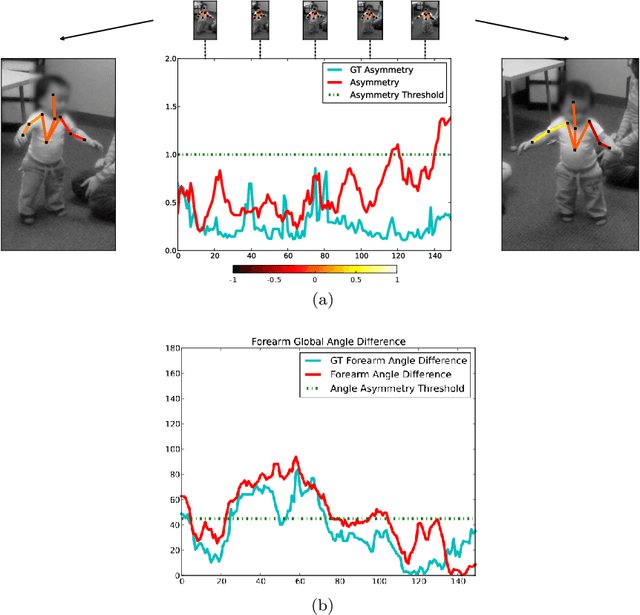
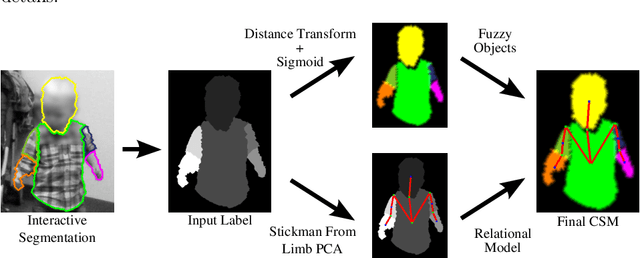
Video object segmentation is a challenging problem due to the presence of deformable, connected, and articulated objects, intra- and inter-object occlusions, object motion, and poor lighting. Some of these challenges call for object models that can locate a desired object and separate it from its surrounding background, even when both share similar colors and textures. In this work, we extend a fuzzy object model, named cloud system model (CSM), to handle video segmentation, and evaluate it for body pose estimation of toddlers at risk of autism. CSM has been successfully used to model the parts of the brain (cerebrum, left and right brain hemispheres, and cerebellum) in order to automatically locate and separate them from each other, the connected brain stem, and the background in 3D MR-images. In our case, the objects are articulated parts (2D projections) of the human body, which can deform, cause self-occlusions, and move along the video. The proposed CSM extension handles articulation by connecting the individual clouds, body parts, of the system using a 2D stickman model. The stickman representation naturally allows us to extract 2D body pose measures of arm asymmetry patterns during unsupported gait of toddlers, a possible behavioral marker of autism. The results show that our method can provide insightful knowledge to assist the specialist's observations during real in-clinic assessments.
Coded aperture compressive temporal imaging
Feb 04, 2013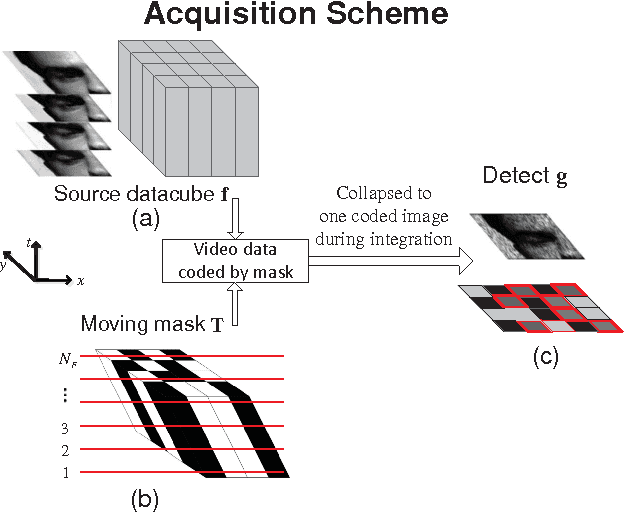

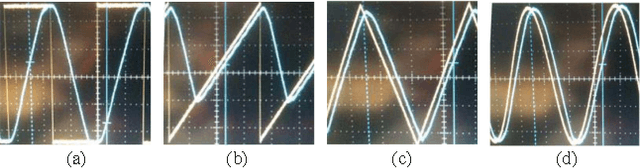
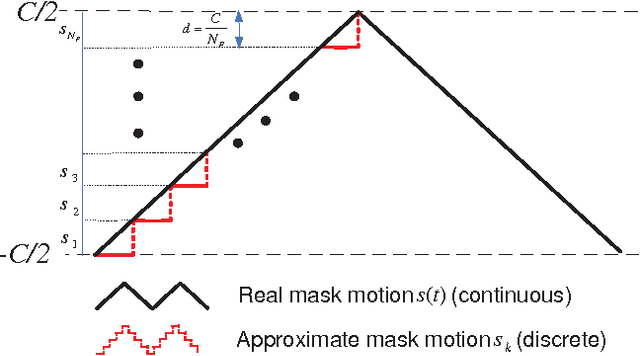
We use mechanical translation of a coded aperture for code division multiple access compression of video. We present experimental results for reconstruction at 148 frames per coded snapshot.
Learning efficient sparse and low rank models
Dec 14, 2012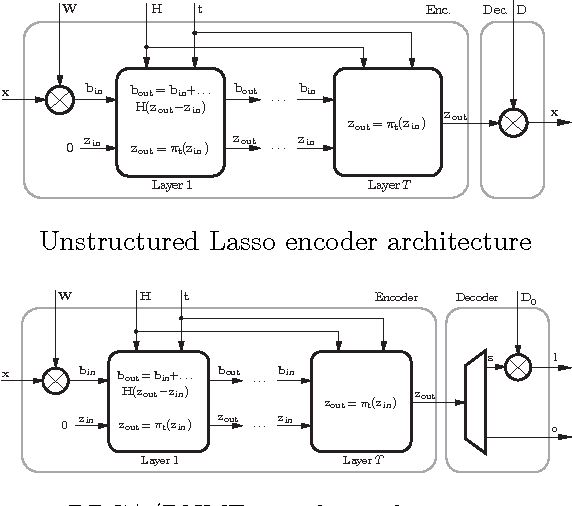

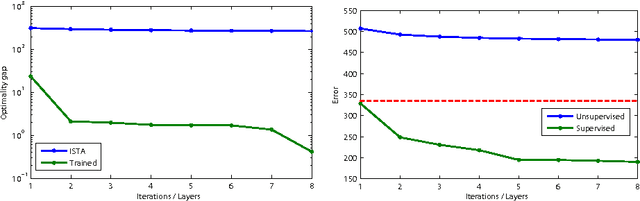

Parsimony, including sparsity and low rank, has been shown to successfully model data in numerous machine learning and signal processing tasks. Traditionally, such modeling approaches rely on an iterative algorithm that minimizes an objective function with parsimony-promoting terms. The inherently sequential structure and data-dependent complexity and latency of iterative optimization constitute a major limitation in many applications requiring real-time performance or involving large-scale data. Another limitation encountered by these modeling techniques is the difficulty of their inclusion in discriminative learning scenarios. In this work, we propose to move the emphasis from the model to the pursuit algorithm, and develop a process-centric view of parsimonious modeling, in which a learned deterministic fixed-complexity pursuit process is used in lieu of iterative optimization. We show a principled way to construct learnable pursuit process architectures for structured sparse and robust low rank models, derived from the iteration of proximal descent algorithms. These architectures learn to approximate the exact parsimonious representation at a fraction of the complexity of the standard optimization methods. We also show that appropriate training regimes allow to naturally extend parsimonious models to discriminative settings. State-of-the-art results are demonstrated on several challenging problems in image and audio processing with several orders of magnitude speedup compared to the exact optimization algorithms.
Computer vision tools for the non-invasive assessment of autism-related behavioral markers
Nov 08, 2012
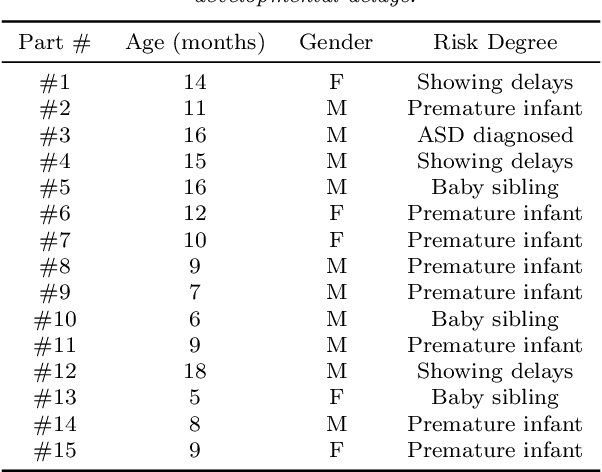
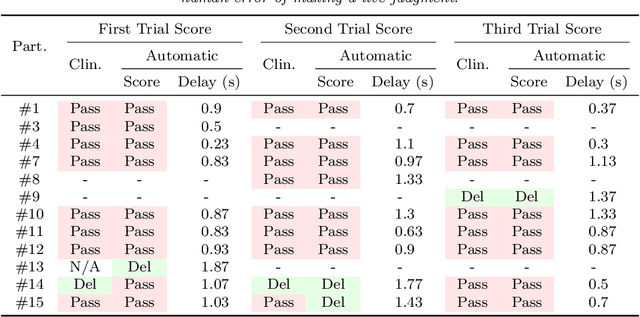
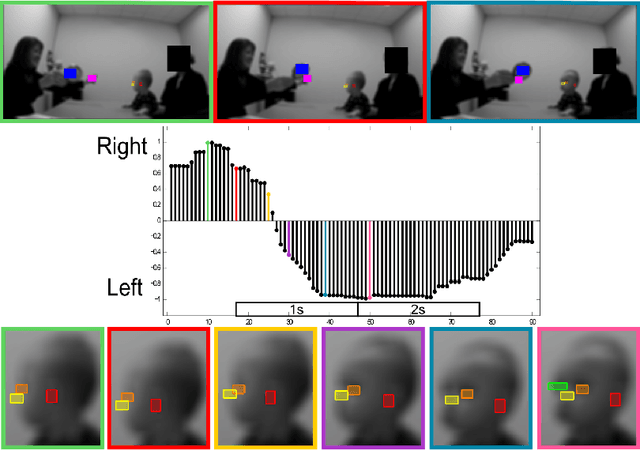
The early detection of developmental disorders is key to child outcome, allowing interventions to be initiated that promote development and improve prognosis. Research on autism spectrum disorder (ASD) suggests behavioral markers can be observed late in the first year of life. Many of these studies involved extensive frame-by-frame video observation and analysis of a child's natural behavior. Although non-intrusive, these methods are extremely time-intensive and require a high level of observer training; thus, they are impractical for clinical and large population research purposes. Diagnostic measures for ASD are available for infants but are only accurate when used by specialists experienced in early diagnosis. This work is a first milestone in a long-term multidisciplinary project that aims at helping clinicians and general practitioners accomplish this early detection/measurement task automatically. We focus on providing computer vision tools to measure and identify ASD behavioral markers based on components of the Autism Observation Scale for Infants (AOSI). In particular, we develop algorithms to measure three critical AOSI activities that assess visual attention. We augment these AOSI activities with an additional test that analyzes asymmetrical patterns in unsupported gait. The first set of algorithms involves assessing head motion by tracking facial features, while the gait analysis relies on joint foreground segmentation and 2D body pose estimation in video. We show results that provide insightful knowledge to augment the clinician's behavioral observations obtained from real in-clinic assessments.
A Complete System for Candidate Polyps Detection in Virtual Colonoscopy
Sep 28, 2012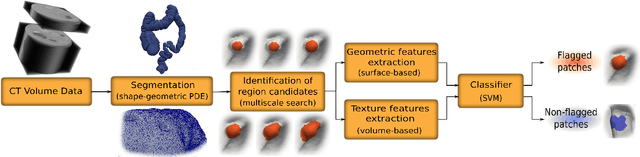
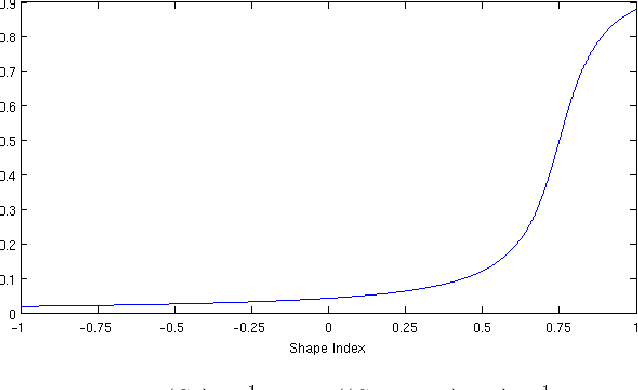


Computer tomographic colonography, combined with computer-aided detection, is a promising emerging technique for colonic polyp analysis. We present a complete pipeline for polyp detection, starting with a simple colon segmentation technique that enhances polyps, followed by an adaptive-scale candidate polyp delineation and classification based on new texture and geometric features that consider both the information in the candidate polyp location and its immediate surrounding area. The proposed system is tested with ground truth data, including flat and small polyps which are hard to detect even with optical colonoscopy. For polyps larger than 6mm in size we achieve 100% sensitivity with just 0.9 false positives per case, and for polyps larger than 3mm in size we achieve 93% sensitivity with 2.8 false positives per case.