 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdmissibility of Completely Randomized Trials: A Large-Deviation Approach
Jun 05, 2025When an experimenter has the option of running an adaptive trial, is it admissible to ignore this option and run a non-adaptive trial instead? We provide a negative answer to this question in the best-arm identification problem, where the experimenter aims to allocate measurement efforts judiciously to confidently deploy the most effective treatment arm. We find that, whenever there are at least three treatment arms, there exist simple adaptive designs that universally and strictly dominate non-adaptive completely randomized trials. This dominance is characterized by a notion called efficiency exponent, which quantifies a design's statistical efficiency when the experimental sample is large. Our analysis focuses on the class of batched arm elimination designs, which progressively eliminate underperforming arms at pre-specified batch intervals. We characterize simple sufficient conditions under which these designs universally and strictly dominate completely randomized trials. These results resolve the second open problem posed in Qin [2022].
Identification of Average Treatment Effects in Nonparametric Panel Models
Mar 25, 2025This paper studies identification of average treatment effects in a panel data setting. It introduces a novel nonparametric factor model and proves identification of average treatment effects. The identification proof is based on the introduction of a consistent estimator. Underlying the proof is a result that there is a consistent estimator for the expected outcome in the absence of the treatment for each unit and time period; this result can be applied more broadly, for example in problems of decompositions of group-level differences in outcomes, such as the much-studied gender wage gap.
Estimating the Value of Evidence-Based Decision Making
Jun 21, 2023

Business/policy decisions are often based on evidence from randomized experiments and observational studies. In this article we propose an empirical framework to estimate the value of evidence-based decision making (EBDM) and the return on the investment in statistical precision.
Double and Single Descent in Causal Inference with an Application to High-Dimensional Synthetic Control
May 01, 2023



Motivated by a recent literature on the double-descent phenomenon in machine learning, we consider highly over-parametrized models in causal inference, including synthetic control with many control units. In such models, there may be so many free parameters that the model fits the training data perfectly. As a motivating example, we first investigate high-dimensional linear regression for imputing wage data, where we find that models with many more covariates than sample size can outperform simple ones. As our main contribution, we document the performance of high-dimensional synthetic control estimators with many control units. We find that adding control units can help improve imputation performance even beyond the point where the pre-treatment fit is perfect. We then provide a unified theoretical perspective on the performance of these high-dimensional models. Specifically, we show that more complex models can be interpreted as model-averaging estimators over simpler ones, which we link to an improvement in average performance. This perspective yields concrete insights into the use of synthetic control when control units are many relative to the number of pre-treatment periods.
Long-term Causal Inference Under Persistent Confounding via Data Combination
Feb 15, 2022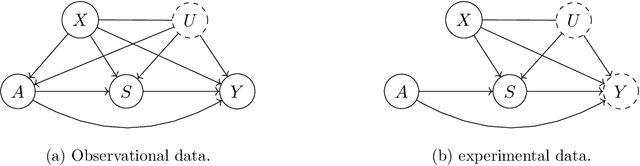
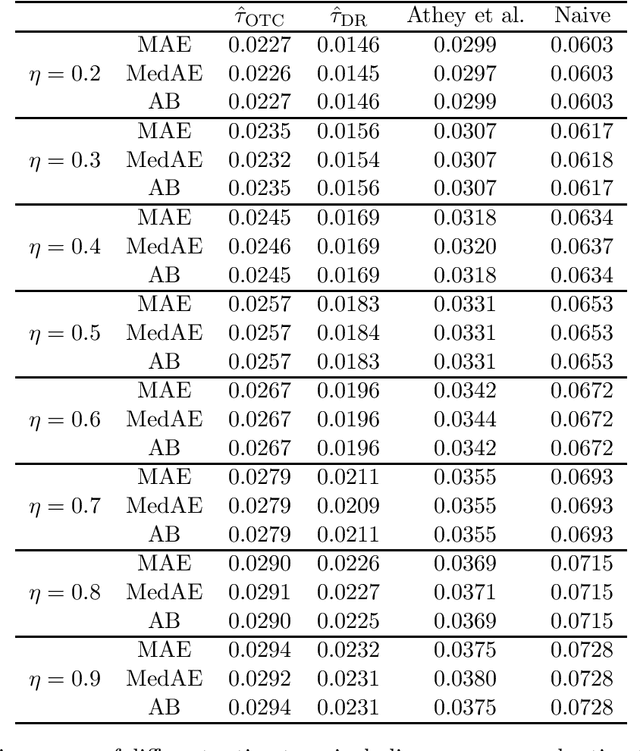
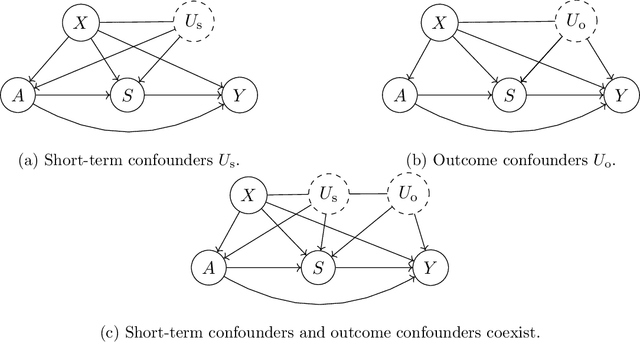
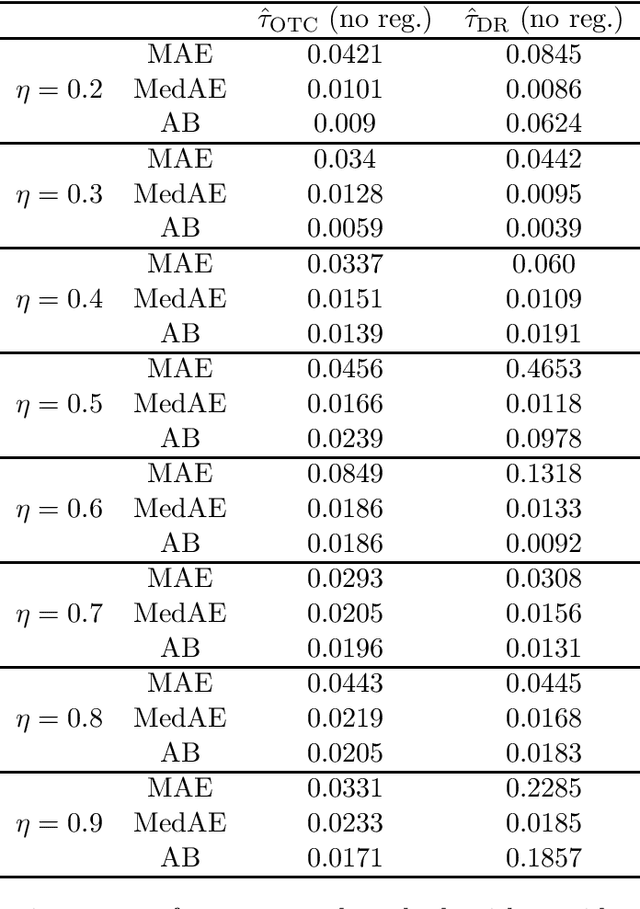
We study the identification and estimation of long-term treatment effects when both experimental and observational data are available. Since the long-term outcome is observed only after a long delay, it is not measured in the experimental data, but only recorded in the observational data. However, both types of data include observations of some short-term outcomes. In this paper, we uniquely tackle the challenge of persistent unmeasured confounders, i.e., some unmeasured confounders that can simultaneously affect the treatment, short-term outcomes and the long-term outcome, noting that they invalidate identification strategies in previous literature. To address this challenge, we exploit the sequential structure of multiple short-term outcomes, and develop three novel identification strategies for the average long-term treatment effect. We further propose three corresponding estimators and prove their asymptotic consistency and asymptotic normality. We finally apply our methods to estimate the effect of a job training program on long-term employment using semi-synthetic data. We numerically show that our proposals outperform existing methods that fail to handle persistent confounders.
Synthetic Design: An Optimization Approach to Experimental Design with Synthetic Controls
Dec 01, 2021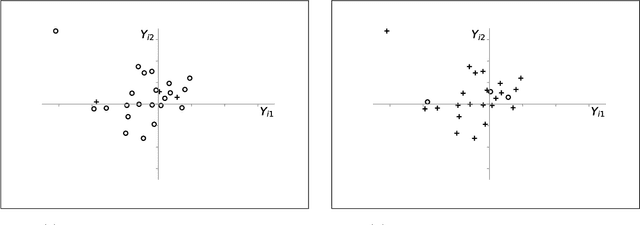
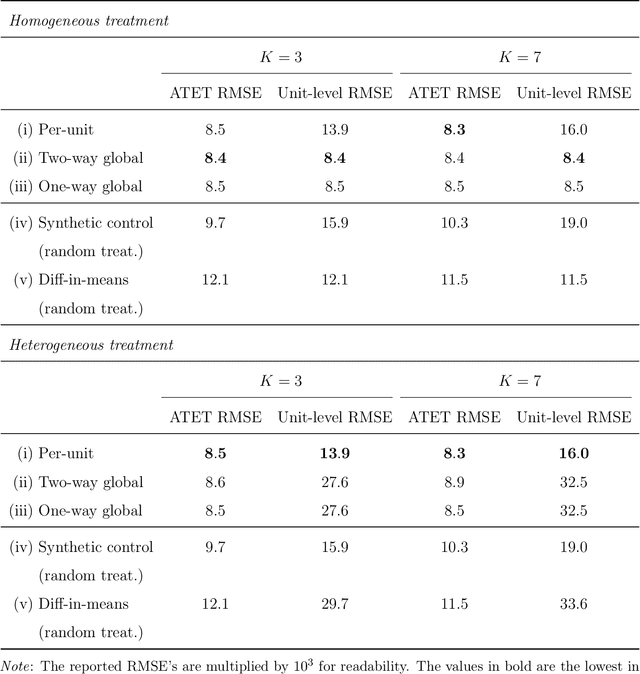
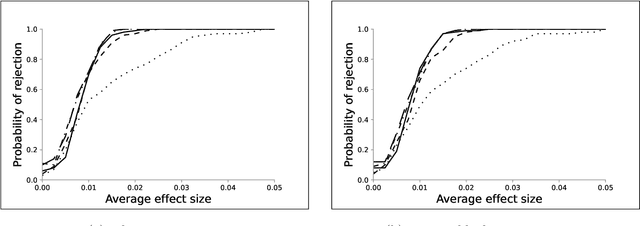
We investigate the optimal design of experimental studies that have pre-treatment outcome data available. The average treatment effect is estimated as the difference between the weighted average outcomes of the treated and control units. A number of commonly used approaches fit this formulation, including the difference-in-means estimator and a variety of synthetic-control techniques. We propose several methods for choosing the set of treated units in conjunction with the weights. Observing the NP-hardness of the problem, we introduce a mixed-integer programming formulation which selects both the treatment and control sets and unit weightings. We prove that these proposed approaches lead to qualitatively different experimental units being selected for treatment. We use simulations based on publicly available data from the US Bureau of Labor Statistics that show improvements in terms of mean squared error and statistical power when compared to simple and commonly used alternatives such as randomized trials.
Decoupling Learning Rates Using Empirical Bayes Priors
Feb 04, 2020
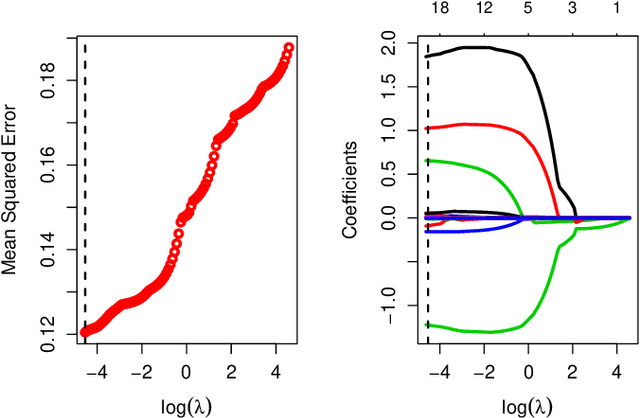
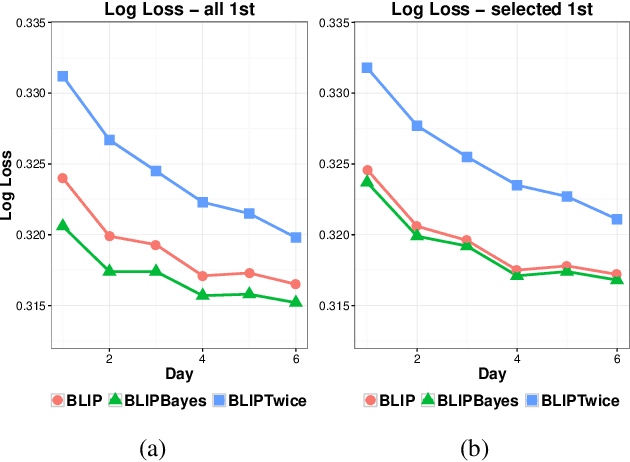
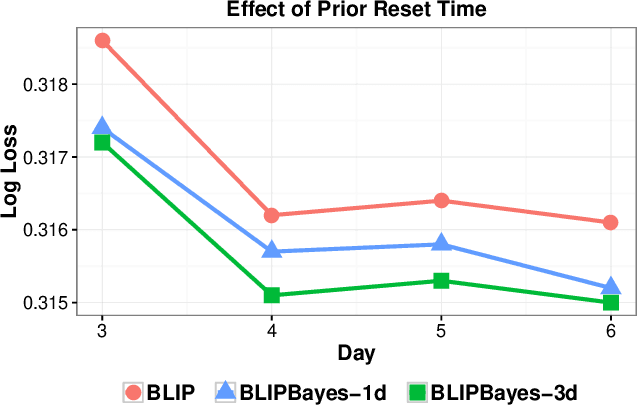
In this work, we propose an Empirical Bayes approach to decouple the learning rates of first order and second order features (or any other feature grouping) in a Generalized Linear Model. Such needs arise in small-batch or low-traffic use-cases. As the first order features are likely to have a more pronounced effect on the outcome, focusing on learning first order weights first is likely to improve performance and convergence time. Our Empirical Bayes method clamps features in each group together and uses the observed data for the deployed model to empirically compute a hierarchical prior in hindsight. We apply our method to a standard classification setting, as well as a contextual bandit setting in an Amazon production system. Both during simulations and live experiments, our method shows marked improvements, especially in cases of small traffic. Our findings are promising, as optimizing over sparse data is often a challenge. Furthermore, our approach can be applied to any problem instance modeled as a Bayesian framework.
Optimal Experimental Design for Staggered Rollouts
Nov 09, 2019
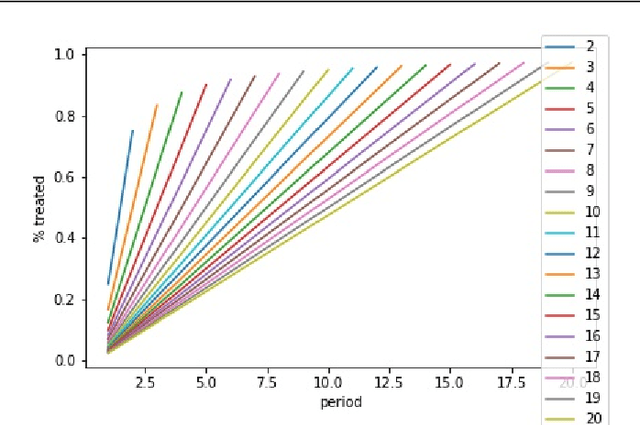
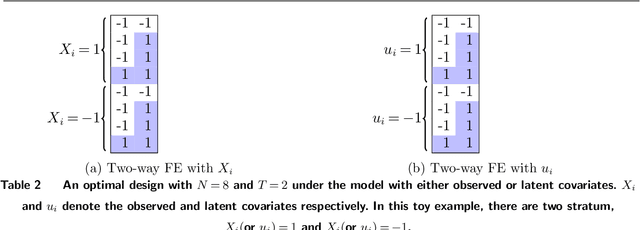
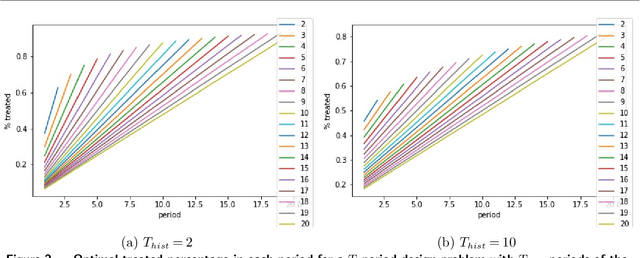
Experimentation has become an increasingly prevalent tool for guiding policy choices, firm decisions, and product innovation. A common hurdle in designing experiments is the lack of statistical power. In this paper, we study optimal multi-period experimental design under the constraint that the treatment cannot be easily removed once implemented; for example, a government or firm might implement treatment in different geographies at different times, where the treatment cannot be easily removed due to practical constraints. The design problem is to select which units to treat at which time, intending to test hypotheses about the effect of the treatment. When the potential outcome is a linear function of a unit effect, a time effect, and observed discrete covariates, we provide an analytically feasible solution to the design problem where the variance of the estimator for the treatment effect is at most 1+O(1/N^2) times the variance of the optimal design, where N is the number of units. This solution assigns units in a staggered treatment adoption pattern, where the proportion treated is a linear function of time. In the general setting where outcomes depend on latent covariates, we show that historical data can be utilized in the optimal design. We propose a data-driven local search algorithm with the minimax decision criterion to assign units to treatment times. We demonstrate that our approach improves upon benchmark experimental designs through synthetic experiments on real-world data sets from several domains, including healthcare, finance, and retail. Finally, we consider the case where the treatment effect changes with the time of treatment, showing that the optimal design treats a smaller fraction of units at the beginning and a greater share at the end.
Machine Learning Methods Economists Should Know About
Mar 24, 2019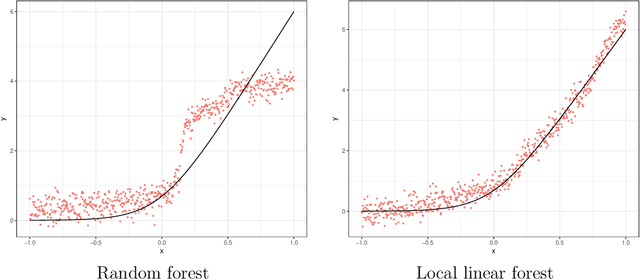
We discuss the relevance of the recent Machine Learning (ML) literature for economics and econometrics. First we discuss the differences in goals, methods and settings between the ML literature and the traditional econometrics and statistics literatures. Then we discuss some specific methods from the machine learning literature that we view as important for empirical researchers in economics. These include supervised learning methods for regression and classification, unsupervised learning methods, as well as matrix completion methods. Finally, we highlight newly developed methods at the intersection of ML and econometrics, methods that typically perform better than either off-the-shelf ML or more traditional econometric methods when applied to particular classes of problems, problems that include causal inference for average treatment effects, optimal policy estimation, and estimation of the counterfactual effect of price changes in consumer choice models.
Balanced Linear Contextual Bandits
Dec 15, 2018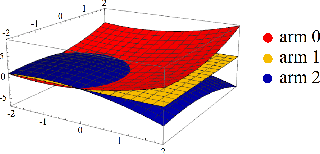
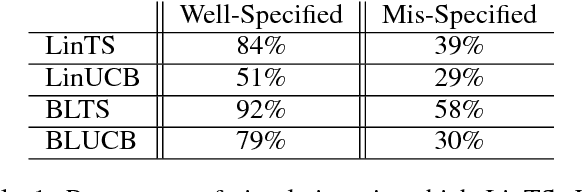
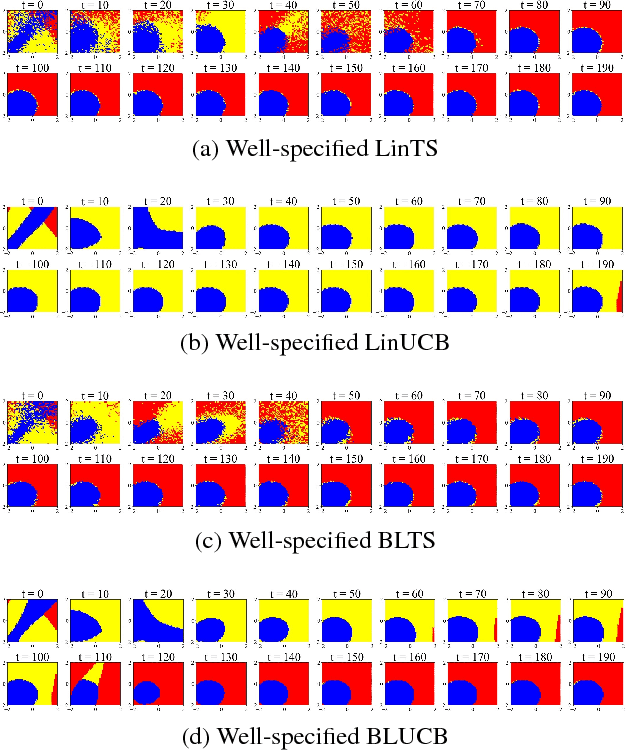
Contextual bandit algorithms are sensitive to the estimation method of the outcome model as well as the exploration method used, particularly in the presence of rich heterogeneity or complex outcome models, which can lead to difficult estimation problems along the path of learning. We develop algorithms for contextual bandits with linear payoffs that integrate balancing methods from the causal inference literature in their estimation to make it less prone to problems of estimation bias. We provide the first regret bound analyses for linear contextual bandits with balancing and show that our algorithms match the state of the art theoretical guarantees. We demonstrate the strong practical advantage of balanced contextual bandits on a large number of supervised learning datasets and on a synthetic example that simulates model misspecification and prejudice in the initial training data.