 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavAgent: Multi-scale Urban Street View Fusion For UAV Embodied Vision-and-Language Navigation
Nov 13, 2024Vision-and-Language Navigation (VLN), as a widely discussed research direction in embodied intelligence, aims to enable embodied agents to navigate in complicated visual environments through natural language commands. Most existing VLN methods focus on indoor ground robot scenarios. However, when applied to UAV VLN in outdoor urban scenes, it faces two significant challenges. First, urban scenes contain numerous objects, which makes it challenging to match fine-grained landmarks in images with complex textual descriptions of these landmarks. Second, overall environmental information encompasses multiple modal dimensions, and the diversity of representations significantly increases the complexity of the encoding process. To address these challenges, we propose NavAgent, the first urban UAV embodied navigation model driven by a large Vision-Language Model. NavAgent undertakes navigation tasks by synthesizing multi-scale environmental information, including topological maps (global), panoramas (medium), and fine-grained landmarks (local). Specifically, we utilize GLIP to build a visual recognizer for landmark capable of identifying and linguisticizing fine-grained landmarks. Subsequently, we develop dynamically growing scene topology map that integrate environmental information and employ Graph Convolutional Networks to encode global environmental data. In addition, to train the visual recognizer for landmark, we develop NavAgent-Landmark2K, the first fine-grained landmark dataset for real urban street scenes. In experiments conducted on the Touchdown and Map2seq datasets, NavAgent outperforms strong baseline models. The code and dataset will be released to the community to facilitate the exploration and development of outdoor VLN.
COT: A Generative Approach for Hate Speech Counter-Narratives via Contrastive Optimal Transport
Jun 18, 2024



Counter-narratives, which are direct responses consisting of non-aggressive fact-based arguments, have emerged as a highly effective approach to combat the proliferation of hate speech. Previous methodologies have primarily focused on fine-tuning and post-editing techniques to ensure the fluency of generated contents, while overlooking the critical aspects of individualization and relevance concerning the specific hatred targets, such as LGBT groups, immigrants, etc. This research paper introduces a novel framework based on contrastive optimal transport, which effectively addresses the challenges of maintaining target interaction and promoting diversification in generating counter-narratives. Firstly, an Optimal Transport Kernel (OTK) module is leveraged to incorporate hatred target information in the token representations, in which the comparison pairs are extracted between original and transported features. Secondly, a self-contrastive learning module is employed to address the issue of model degeneration. This module achieves this by generating an anisotropic distribution of token representations. Finally, a target-oriented search method is integrated as an improved decoding strategy to explicitly promote domain relevance and diversification in the inference process. This strategy modifies the model's confidence score by considering both token similarity and target relevance. Quantitative and qualitative experiments have been evaluated on two benchmark datasets, which demonstrate that our proposed model significantly outperforms current methods evaluated by metrics from multiple aspects.
TOT: Topology-Aware Optimal Transport For Multimodal Hate Detection
Feb 27, 2023



Multimodal hate detection, which aims to identify harmful content online such as memes, is crucial for building a wholesome internet environment. Previous work has made enlightening exploration in detecting explicit hate remarks. However, most of their approaches neglect the analysis of implicit harm, which is particularly challenging as explicit text markers and demographic visual cues are often twisted or missing. The leveraged cross-modal attention mechanisms also suffer from the distributional modality gap and lack logical interpretability. To address these semantic gaps issues, we propose TOT: a topology-aware optimal transport framework to decipher the implicit harm in memes scenario, which formulates the cross-modal aligning problem as solutions for optimal transportation plans. Specifically, we leverage an optimal transport kernel method to capture complementary information from multiple modalities. The kernel embedding provides a non-linear transformation ability to reproduce a kernel Hilbert space (RKHS), which reflects significance for eliminating the distributional modality gap. Moreover, we perceive the topology information based on aligned representations to conduct bipartite graph path reasoning. The newly achieved state-of-the-art performance on two publicly available benchmark datasets, together with further visual analysis, demonstrate the superiority of TOT in capturing implicit cross-modal alignment.
HYPER^2: Hyperbolic Poincare Embedding for Hyper-Relational Link Prediction
Apr 20, 2021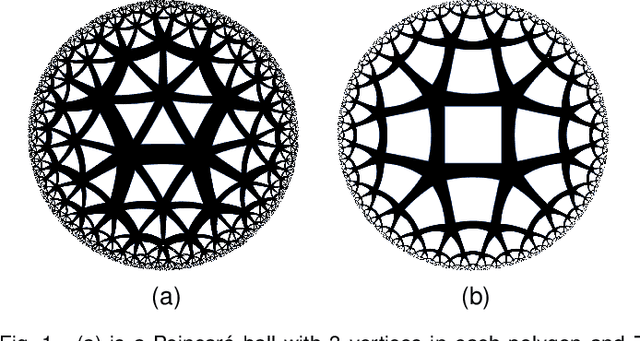
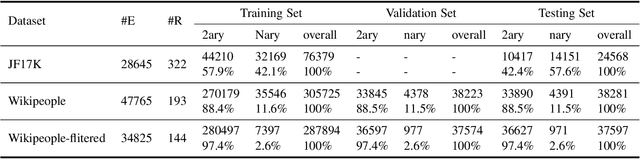
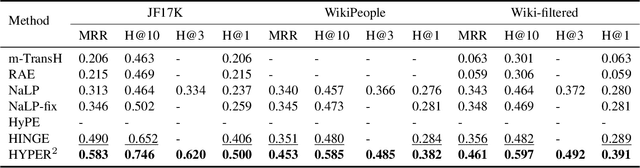
Link Prediction, addressing the issue of completing KGs with missing facts, has been broadly studied. However, less light is shed on the ubiquitous hyper-relational KGs. Most existing hyper-relational KG embedding models still tear an n-ary fact into smaller tuples, neglecting the indecomposability of some n-ary facts. While other frameworks work for certain arity facts only or ignore the significance of primary triple. In this paper, we represent an n-ary fact as a whole, simultaneously keeping the integrity of n-ary fact and maintaining the vital role that the primary triple plays. In addition, we generalize hyperbolic Poincar\'e embedding from binary to arbitrary arity data, which has not been studied yet. To tackle the weak expressiveness and high complexity issue, we propose HYPER^2 which is qualified for capturing the interaction between entities within and beyond triple through information aggregation on the tangent space. Extensive experiments demonstrate HYPER^2 achieves superior performance to its translational and deep analogues, improving SOTA by up to 34.5\% with relatively few dimensions. Moreover, we study the side effect of literals and we theoretically and experimentally compare the computational complexity of HYPER^2 against several best performing baselines, HYPER^2 is 49-61 times quicker than its counterparts.
High Quality Remote Sensing Image Super-Resolution Using Deep Memory Connected Network
Oct 01, 2020
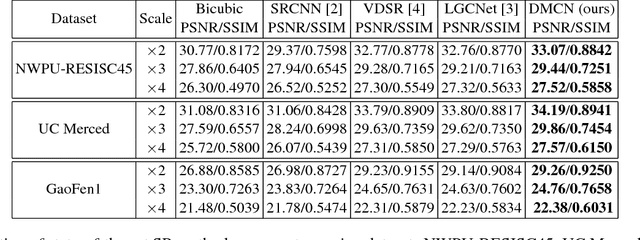
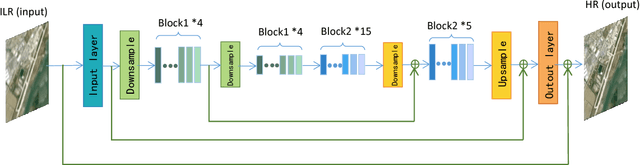

Single image super-resolution is an effective way to enhance the spatial resolution of remote sensing image, which is crucial for many applications such as target detection and image classification. However, existing methods based on the neural network usually have small receptive fields and ignore the image detail. We propose a novel method named deep memory connected network (DMCN) based on a convolutional neural network to reconstruct high-quality super-resolution images. We build local and global memory connections to combine image detail with environmental information. To further reduce parameters and ease time-consuming, we propose downsampling units, shrinking the spatial size of feature maps. We test DMCN on three remote sensing datasets with different spatial resolution. Experimental results indicate that our method yields promising improvements in both accuracy and visual performance over the current state-of-the-art.
Where is the Model Looking At?--Concentrate and Explain the Network Attention
Sep 29, 2020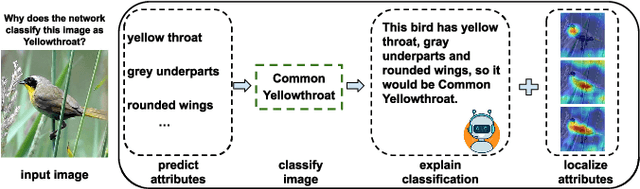
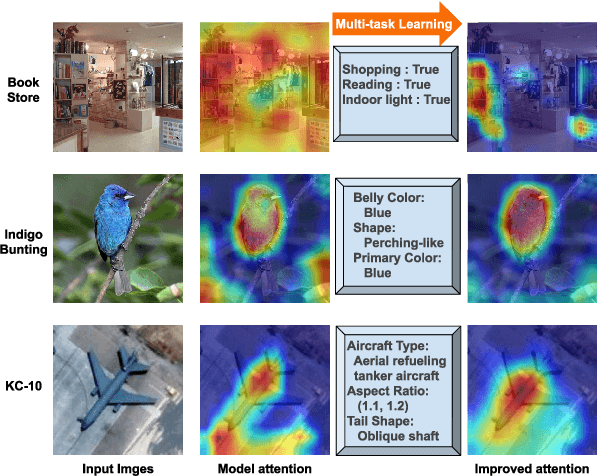
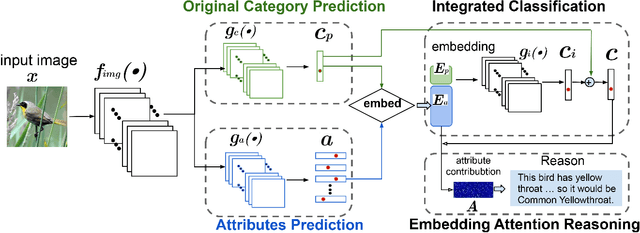

Image classification models have achieved satisfactory performance on many datasets, sometimes even better than human. However, The model attention is unclear since the lack of interpretability. This paper investigates the fidelity and interpretability of model attention. We propose an Explainable Attribute-based Multi-task (EAT) framework to concentrate the model attention on the discriminative image area and make the attention interpretable. We introduce attributes prediction to the multi-task learning network, helping the network to concentrate attention on the foreground objects. We generate attribute-based textual explanations for the network and ground the attributes on the image to show visual explanations. The multi-model explanation can not only improve user trust but also help to find the weakness of network and dataset. Our framework can be generalized to any basic model. We perform experiments on three datasets and five basic models. Results indicate that the EAT framework can give multi-modal explanations that interpret the network decision. The performance of several recognition approaches is improved by guiding network attention.
SRQA: Synthetic Reader for Factoid Question Answering
Sep 02, 2020
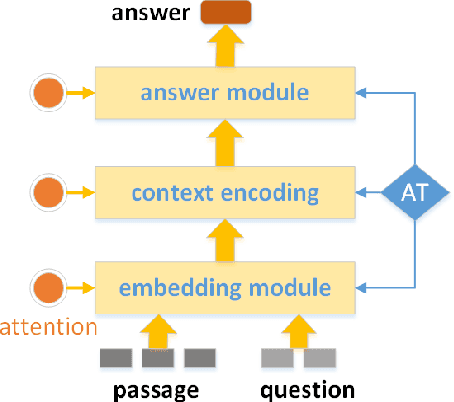
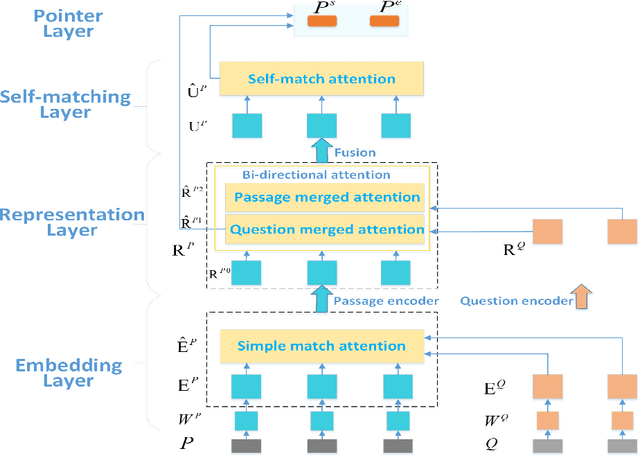

The question answering system can answer questions from various fields and forms with deep neural networks, but it still lacks effective ways when facing multiple evidences. We introduce a new model called SRQA, which means Synthetic Reader for Factoid Question Answering. This model enhances the question answering system in the multi-document scenario from three aspects: model structure, optimization goal, and training method, corresponding to Multilayer Attention (MA), Cross Evidence (CE), and Adversarial Training (AT) respectively. First, we propose a multilayer attention network to obtain a better representation of the evidences. The multilayer attention mechanism conducts interaction between the question and the passage within each layer, making the token representation of evidences in each layer takes the requirement of the question into account. Second, we design a cross evidence strategy to choose the answer span within more evidences. We improve the optimization goal, considering all the answers' locations in multiple evidences as training targets, which leads the model to reason among multiple evidences. Third, adversarial training is employed to high-level variables besides the word embedding in our model. A new normalization method is also proposed for adversarial perturbations so that we can jointly add perturbations to several target variables. As an effective regularization method, adversarial training enhances the model's ability to process noisy data. Combining these three strategies, we enhance the contextual representation and locating ability of our model, which could synthetically extract the answer span from several evidences. We perform SRQA on the WebQA dataset, and experiments show that our model outperforms the state-of-the-art models (the best fuzzy score of our model is up to 78.56%, with an improvement of about 2%).
* arXiv admin note: text overlap with arXiv:1809.00676
ASTRAL: Adversarial Trained LSTM-CNN for Named Entity Recognition
Sep 02, 2020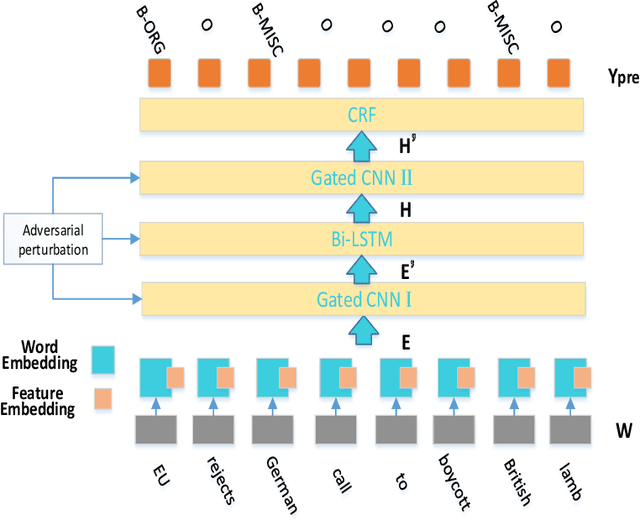
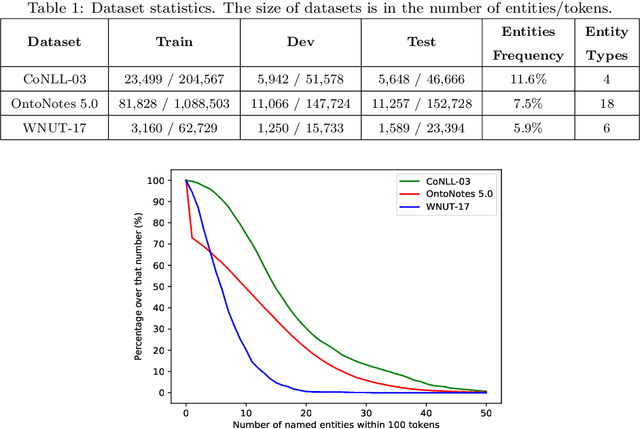
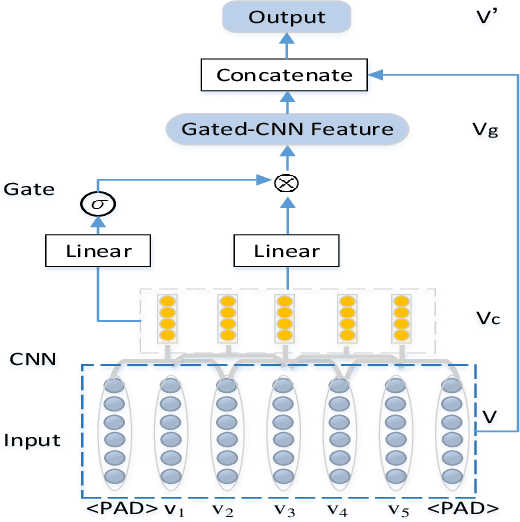
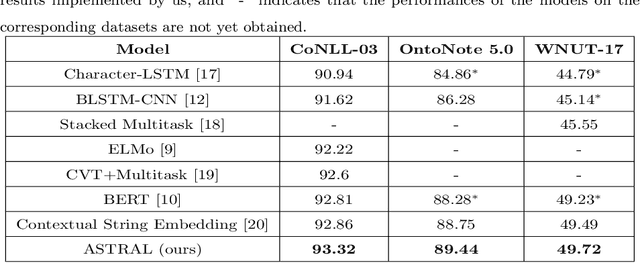
Named Entity Recognition (NER) is a challenging task that extracts named entities from unstructured text data, including news, articles, social comments, etc. The NER system has been studied for decades. Recently, the development of Deep Neural Networks and the progress of pre-trained word embedding have become a driving force for NER. Under such circumstances, how to make full use of the information extracted by word embedding requires more in-depth research. In this paper, we propose an Adversarial Trained LSTM-CNN (ASTRAL) system to improve the current NER method from both the model structure and the training process. In order to make use of the spatial information between adjacent words, Gated-CNN is introduced to fuse the information of adjacent words. Besides, a specific Adversarial training method is proposed to deal with the overfitting problem in NER. We add perturbation to variables in the network during the training process, making the variables more diverse, improving the generalization and robustness of the model. Our model is evaluated on three benchmarks, CoNLL-03, OntoNotes 5.0, and WNUT-17, achieving state-of-the-art results. Ablation study and case study also show that our system can converge faster and is less prone to overfitting.
Deep Discriminative Representation Learning with Attention Map for Scene Classification
Feb 21, 2019
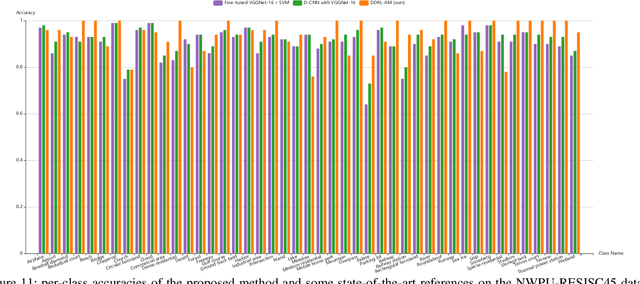
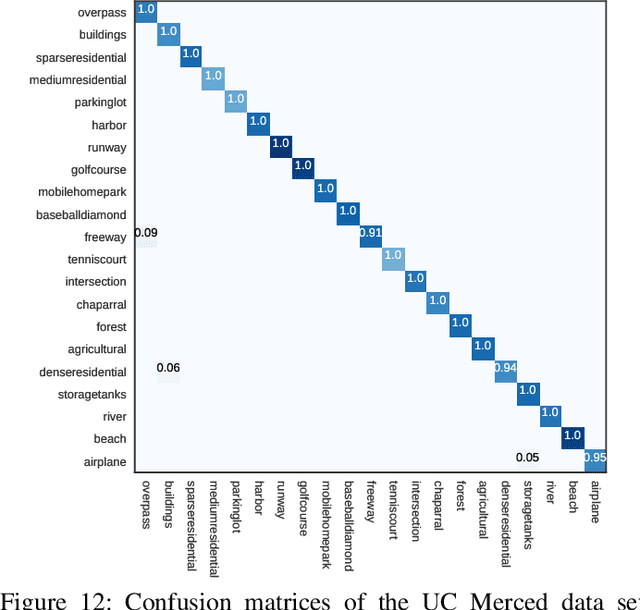
Learning powerful discriminative features for remote sensing image scene classification is a challenging computer vision problem. In the past, most classification approaches were based on handcrafted features. However, most recent approaches to remote sensing scene classification are based on Convolutional Neural Networks (CNNs). The de facto practice when learning these CNN models is only to use original RGB patches as input with training performed on large amounts of labeled data (ImageNet). In this paper, we show class activation map (CAM) encoded CNN models, codenamed DDRL-AM, trained using original RGB patches and attention map based class information provide complementary information to the standard RGB deep models. To the best of our knowledge, we are the first to investigate attention information encoded CNNs. Additionally, to enhance the discriminability, we further employ a recently developed object function called "center loss," which has proved to be very useful in face recognition. Finally, our framework provides attention guidance to the model in an end-to-end fashion. Extensive experiments on two benchmark datasets show that our approach matches or exceeds the performance of other methods.
A Remote Sensing Image Dataset for Cloud Removal
Jan 03, 2019

Cloud-based overlays are often present in optical remote sensing images, thus limiting the application of acquired data. Removing clouds is an indispensable pre-processing step in remote sensing image analysis. Deep learning has achieved great success in the field of remote sensing in recent years, including scene classification and change detection. However, deep learning is rarely applied in remote sensing image removal clouds. The reason is the lack of data sets for training neural networks. In order to solve this problem, this paper first proposed the Remote sensing Image Cloud rEmoving dataset (RICE). The proposed dataset consists of two parts: RICE1 contains 500 pairs of images, each pair has images with cloud and cloudless size of 512*512; RICE2 contains 450 sets of images, each set contains three 512*512 size images. , respectively, the reference picture without clouds, the picture of the cloud and the mask of its cloud. The dataset is freely available at \url{https://github.com/BUPTLdy/RICE_DATASET}.