 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Distortion Accumulation in Multi-Hop Semantic Communication
Aug 22, 2023Recently, semantic communication has been investigated to boost the performance of end-to-end image transmission systems. However, existing semantic approaches are generally based on deep learning and belong to lossy transmission. Consequently, as the receiver continues to transmit received images to another device, the distortion of images accumulates with each transmission. Unfortunately, most recent advances overlook this issue and only consider single-hop scenarios, where images are transmitted only once from a transmitter to a receiver. In this letter, we propose a novel framework of a multi-hop semantic communication system. To address the problem of distortion accumulation, we introduce a novel recursive training method for the encoder and decoder of semantic communication systems. Specifically, the received images are recursively input into the encoder and decoder to retrain the semantic communication system. This empowers the system to handle distorted received images and achieve higher performance. Our extensive simulation results demonstrate that the proposed methods significantly alleviate distortion accumulation in multi-hop semantic communication.
SCAN: Semantic Communication with Adaptive Channel Feedback
Jun 27, 2023In existing semantic communication systems for image transmission, some images are generally reconstructed with considerably low quality. As a result, the reliable transmission of each image cannot be guaranteed, bringing significant uncertainty to semantic communication systems. To address this issue, we propose a novel performance metric to characterize the reliability of semantic communication systems termed semantic distortion outage probability (SDOP), which is defined as the probability of the instantaneous distortion larger than a given target threshold. Then, since the images with lower reconstruction quality are generally less robust and need to be allocated with more communication resources, we propose a novel framework of Semantic Communication with Adaptive chaNnel feedback (SCAN). It can reduce SDOP by adaptively adjusting the overhead of channel feedback for images with different reconstruction qualities, thereby enhancing transmission reliability. To realize SCAN, we first develop a deep learning-enabled semantic communication system for multiple-input multiple-output (MIMO) channels (DeepSC-MIMO) by leveraging the channel state information (CSI) and noise variance in the model design. We then develop a performance evaluator to predict the reconstruction quality of each image at the transmitter by distilling knowledge from DeepSC-MIMO. In this way, images with lower predicted reconstruction quality will be allocated with a longer CSI codeword to guarantee the reconstruction quality. We perform extensive experiments to demonstrate that the proposed scheme can significantly improve the reliability of image transmission while greatly reducing the feedback overhead.
Meta-Gating Framework for Fast and Continuous Resource Optimization in Dynamic Wireless Environments
Jun 23, 2023



With the great success of deep learning (DL) in image classification, speech recognition, and other fields, more and more studies have applied various neural networks (NNs) to wireless resource allocation. Generally speaking, these artificial intelligent (AI) models are trained under some special learning hypotheses, especially that the statistics of the training data are static during the training stage. However, the distribution of channel state information (CSI) is constantly changing in the real-world wireless communication environment. Therefore, it is essential to study effective dynamic DL technologies to solve wireless resource allocation problems. In this paper, we propose a novel framework, named meta-gating, for solving resource allocation problems in an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. The proposed framework, consisting of an inner network and an outer network, aims to adapt to the dynamic wireless environment by achieving three important goals, i.e., seamlessness, quickness and continuity. Specifically, for the former two goals, we propose a training method by combining a model-agnostic meta-learning (MAML) algorithm with an unsupervised learning mechanism. With this training method, the inner network is able to fast adapt to different channel distributions because of the good initialization. As for the goal of continuity, the outer network can learn to evaluate the importance of inner network's parameters under different CSI distributions, and then decide which subset of the inner network should be activated through the gating operation. Additionally, we theoretically analyze the performance of the proposed meta-gating framework.
Rate-Adaptive Coding Mechanism for Semantic Communications With Multi-Modal Data
May 18, 2023



Recently, the ever-increasing demand for bandwidth in multi-modal communication systems requires a paradigm shift. Powered by deep learning, semantic communications are applied to multi-modal scenarios to boost communication efficiency and save communication resources. However, the existing end-to-end neural network (NN) based framework without the channel encoder/decoder is incompatible with modern digital communication systems. Moreover, most end-to-end designs are task-specific and require re-design and re-training for new tasks, which limits their applications. In this paper, we propose a distributed multi-modal semantic communication framework incorporating the conventional channel encoder/decoder. We adopt NN-based semantic encoder and decoder to extract correlated semantic information contained in different modalities, including speech, text, and image. Based on the proposed framework, we further establish a general rate-adaptive coding mechanism for various types of multi-modal semantic tasks. In particular, we utilize unequal error protection based on semantic importance, which is derived by evaluating the distortion bound of each modality. We further formulate and solve an optimization problem that aims at minimizing inference delay while maintaining inference accuracy for semantic tasks. Numerical results show that the proposed mechanism fares better than both conventional communication and existing semantic communication systems in terms of task performance, inference delay, and deployment complexity.
Deep-Unfolding for Next-Generation Transceivers
May 15, 2023The stringent performance requirements of future wireless networks, such as ultra-high data rates, extremely high reliability and low latency, are spurring worldwide studies on defining the next-generation multiple-input multiple-output (MIMO) transceivers. For the design of advanced transceivers in wireless communications, optimization approaches often leading to iterative algorithms have achieved great success for MIMO transceivers. However, these algorithms generally require a large number of iterations to converge, which entails considerable computational complexity and often requires fine-tuning of various parameters. With the development of deep learning, approximating the iterative algorithms with deep neural networks (DNNs) can significantly reduce the computational time. However, DNNs typically lead to black-box solvers, which requires amounts of data and extensive training time. To further overcome these challenges, deep-unfolding has emerged which incorporates the benefits of both deep learning and iterative algorithms, by unfolding the iterative algorithm into a layer-wise structure analogous to DNNs. In this article, we first go through the framework of deep-unfolding for transceiver design with matrix parameters and its recent advancements. Then, some endeavors in applying deep-unfolding approaches in next-generation advanced transceiver design are presented. Moreover, some open issues for future research are highlighted.
FAST: Feature Arrangement for Semantic Transmission
May 05, 2023



Although existing semantic communication systems have achieved great success, they have not considered that the channel is time-varying wherein deep fading occurs occasionally. Moreover, the importance of each semantic feature differs from each other. Consequently, the important features may be affected by channel fading and corrupted, resulting in performance degradation. Therefore, higher performance can be achieved by avoiding the transmission of important features when the channel state is poor. In this paper, we propose a scheme of Feature Arrangement for Semantic Transmission (FAST). In particular, we aim to schedule the transmission order of features and transmit important features when the channel state is good. To this end, we first propose a novel metric termed feature priority, which takes into consideration both feature importance and feature robustness. Then, we perform channel prediction at the transmitter side to obtain the future channel state information (CSI). Furthermore, the feature arrangement module is developed based on the proposed feature priority and the predicted CSI by transmitting the prior features under better CSI. Simulation results show that the proposed scheme significantly improves the performance of image transmission compared to existing semantic communication systems without feature arrangement.
Adaptive CSI Feedback for Deep Learning-Enabled Image Transmission
Feb 27, 2023Recently, deep learning-enabled joint-source channel coding (JSCC) has received increasing attention due to its great success in image transmission. However, most existing JSCC studies only focus on single-input single-output (SISO) channels. In this paper, we first propose a JSCC system for wireless image transmission over multiple-input multiple-output (MIMO) channels. As the complexity of an image determines its reconstruction difficulty, the JSCC achieves quite different reconstruction performances on different images. Moreover, we observe that the images with higher reconstruction qualities are generally more robust to the noise, and can be allocated with less communication resources than the images with lower reconstruction qualities. Based on this observation, we propose an adaptive channel state information (CSI) feedback scheme for precoding, which improves the effectiveness by adjusting the feedback overhead. In particular, we develop a performance evaluator to predict the reconstruction quality of each image, so that the proposed scheme can adaptively decrease the CSI feedback overhead for the transmitted images with high predicted reconstruction qualities in the JSCC system. We perform experiments to demonstrate that the proposed scheme can significantly improve the image transmission performance with much-reduced feedback overhead.
Design and Performance Analysis of Wireless Legitimate Surveillance Systems with Radar Function
Feb 14, 2023



Integrated sensing and communication (ISAC) has recently been considered as a promising approach to save spectrum resources and reduce hardware cost. Meanwhile, as information security becomes increasingly more critical issue, government agencies urgently need to legitimately monitor suspicious communications via proactive eavesdropping. Thus, in this paper, we investigate a wireless legitimate surveillance system with radar function. We seek to jointly optimize the receive and transmit beamforming vectors to maximize the eavesdropping success probability which is transformed into the difference of signal-to-interference-plus-noise ratios (SINRs) subject to the performance requirements of radar and surveillance. The formulated problem is challenging to solve. By employing the Rayleigh quotient and fully exploiting the structure of the problem, we apply the divide-and-conquer principle to divide the formulated problem into two subproblems for two different cases. For the first case, we aim at minimizing the total transmit power, and for the second case we focus on maximizing the jamming power. For both subproblems, with the aid of orthogonal decomposition, we obtain the optimal solution of the receive and transmit beamforming vectors in closed-form. Performance analysis and discussion of some insightful results are also carried out. Finally, extensive simulation results demonstrate the effectiveness of our proposed algorithm in terms of eavesdropping success probability.
Graph Neural Networks Meet Wireless Communications: Motivation, Applications, and Future Directions
Dec 08, 2022As an efficient graph analytical tool, graph neural networks (GNNs) have special properties that are particularly fit for the characteristics and requirements of wireless communications, exhibiting good potential for the advancement of next-generation wireless communications. This article aims to provide a comprehensive overview of the interplay between GNNs and wireless communications, including GNNs for wireless communications (GNN4Com) and wireless communications for GNNs (Com4GNN). In particular, we discuss GNN4Com based on how graphical models are constructed and introduce Com4GNN with corresponding incentives. We also highlight potential research directions to promote future research endeavors for GNNs in wireless communications.
A Unified Multi-Task Semantic Communication System for Multimodal Data
Sep 16, 2022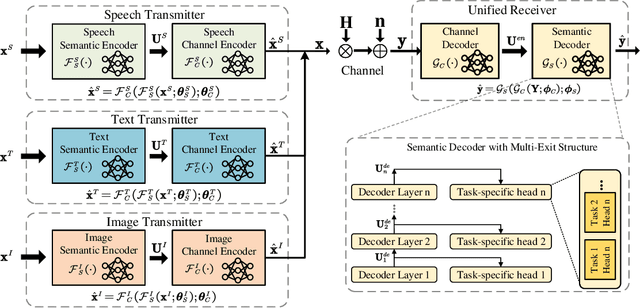
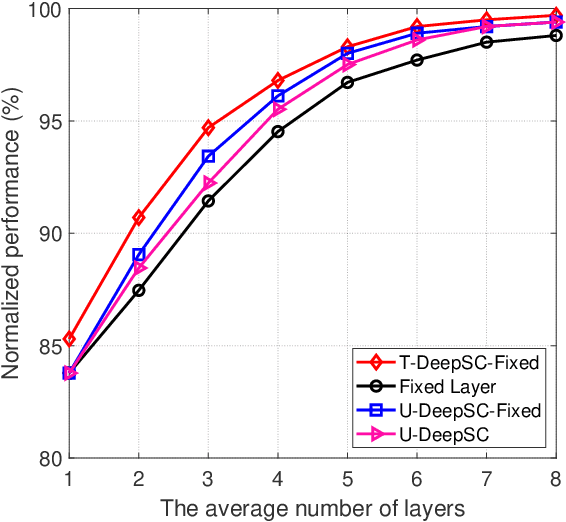
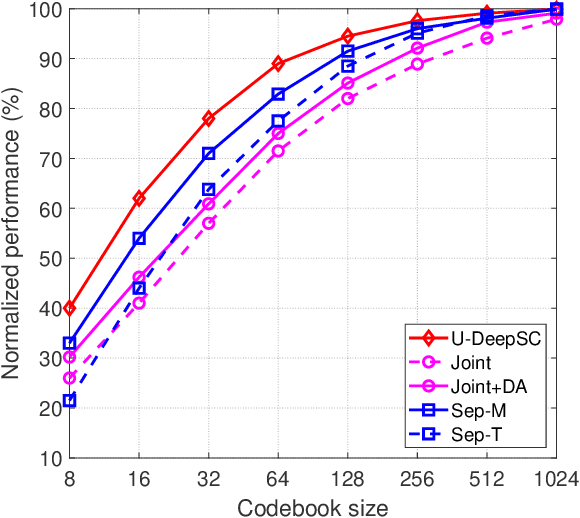
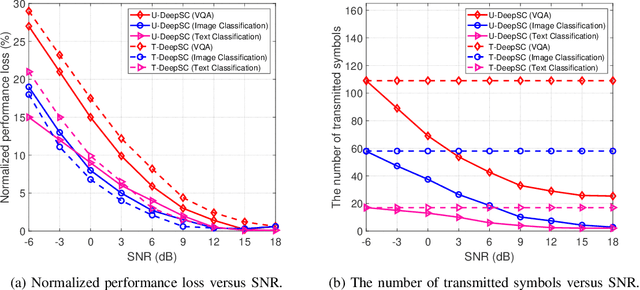
Task-oriented semantic communication has achieved significant performance gains. However, the model has to be updated once the task is changed or multiple models need to be stored for serving different tasks. To address this issue, we develop a unified deep learning enabled semantic communication system (U-DeepSC), where a unified end-to-end framework can serve many different tasks with multiple modalities. As the difficulty varies from different tasks, different numbers of neural network layers are required for various tasks. We develop a multi-exit architecture in U-DeepSC to provide early-exit results for relatively simple tasks. To reduce the transmission overhead, we design a unified codebook for feature representation for serving multiple tasks, in which only the indices of these task-specific features in the codebook are transmitted. Moreover, we propose a dimension-wise dynamic scheme that can adjust the number of transmitted indices for different tasks as the number of required features varies from task to task. Furthermore, our dynamic scheme can adaptively adjust the numbers of transmitted features under different channel conditions to optimize the transmission efficiency. According to simulation results, the proposed U-DeepSC achieves comparable performance to the task-oriented semantic communication system designed for a specific task but with significant reduction in both transmission overhead and model size.