 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectrum Estimation from Samples
Jul 16, 2017
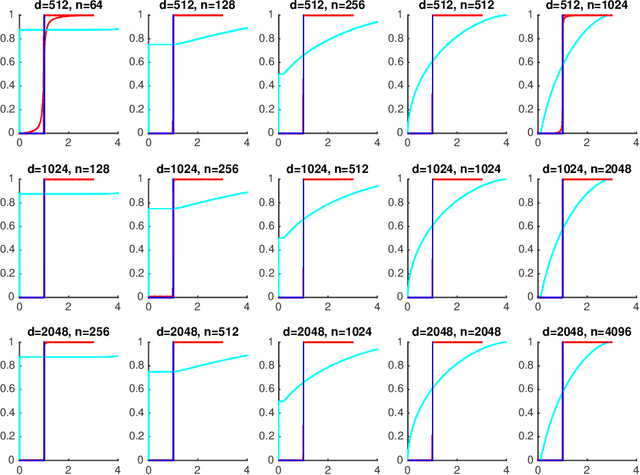
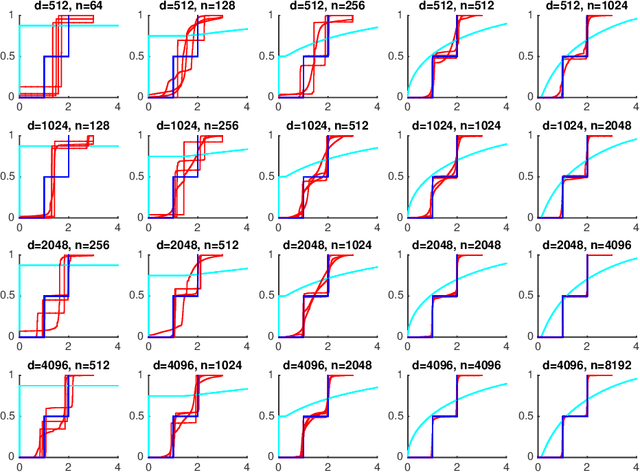
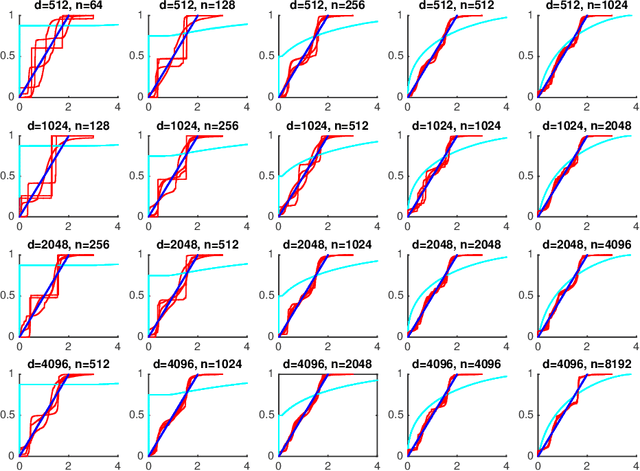
We consider the problem of approximating the set of eigenvalues of the covariance matrix of a multivariate distribution (equivalently, the problem of approximating the "population spectrum"), given access to samples drawn from the distribution. The eigenvalues of the covariance of a distribution contain basic information about the distribution, including the presence or lack of structure in the distribution, the effective dimensionality of the distribution, and the applicability of higher-level machine learning and multivariate statistical tools. We consider this fundamental recovery problem in the regime where the number of samples is comparable, or even sublinear in the dimensionality of the distribution in question. First, we propose a theoretically optimal and computationally efficient algorithm for recovering the moments of the eigenvalues of the population covariance matrix. We then leverage this accurate moment recovery, via a Wasserstein distance argument, to show that the vector of eigenvalues can be accurately recovered. We provide finite--sample bounds on the expected error of the recovered eigenvalues, which imply that our estimator is asymptotically consistent as the dimensionality of the distribution and sample size tend towards infinity, even in the sublinear sample regime where the ratio of the sample size to the dimensionality tends to zero. In addition to our theoretical results, we show that our approach performs well in practice for a broad range of distributions and sample sizes.
Learning from Untrusted Data
Jun 11, 2017The vast majority of theoretical results in machine learning and statistics assume that the available training data is a reasonably reliable reflection of the phenomena to be learned or estimated. Similarly, the majority of machine learning and statistical techniques used in practice are brittle to the presence of large amounts of biased or malicious data. In this work we consider two frameworks in which to study estimation, learning, and optimization in the presence of significant fractions of arbitrary data. The first framework, list-decodable learning, asks whether it is possible to return a list of answers, with the guarantee that at least one of them is accurate. For example, given a dataset of $n$ points for which an unknown subset of $\alpha n$ points are drawn from a distribution of interest, and no assumptions are made about the remaining $(1-\alpha)n$ points, is it possible to return a list of $\operatorname{poly}(1/\alpha)$ answers, one of which is correct? The second framework, which we term the semi-verified learning model, considers the extent to which a small dataset of trusted data (drawn from the distribution in question) can be leveraged to enable the accurate extraction of information from a much larger but untrusted dataset (of which only an $\alpha$-fraction is drawn from the distribution). We show strong positive results in both settings, and provide an algorithm for robust learning in a very general stochastic optimization setting. This general result has immediate implications for robust estimation in a number of settings, including for robustly estimating the mean of distributions with bounded second moments, robustly learning mixtures of such distributions, and robustly finding planted partitions in random graphs in which significant portions of the graph have been perturbed by an adversary.
Avoiding Imposters and Delinquents: Adversarial Crowdsourcing and Peer Prediction
Jun 16, 2016
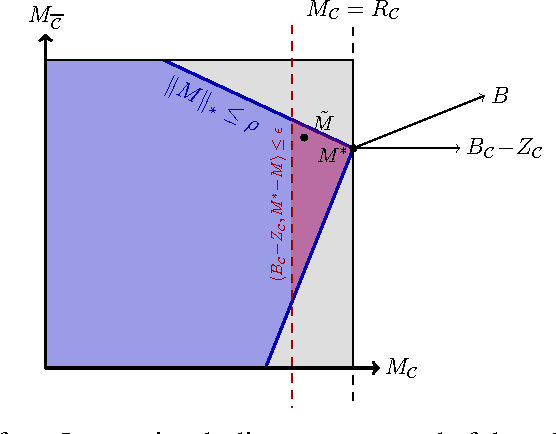
We consider a crowdsourcing model in which $n$ workers are asked to rate the quality of $n$ items previously generated by other workers. An unknown set of $\alpha n$ workers generate reliable ratings, while the remaining workers may behave arbitrarily and possibly adversarially. The manager of the experiment can also manually evaluate the quality of a small number of items, and wishes to curate together almost all of the high-quality items with at most an $\epsilon$ fraction of low-quality items. Perhaps surprisingly, we show that this is possible with an amount of work required of the manager, and each worker, that does not scale with $n$: the dataset can be curated with $\tilde{O}\Big(\frac{1}{\beta\alpha^3\epsilon^4}\Big)$ ratings per worker, and $\tilde{O}\Big(\frac{1}{\beta\epsilon^2}\Big)$ ratings by the manager, where $\beta$ is the fraction of high-quality items. Our results extend to the more general setting of peer prediction, including peer grading in online classrooms.
Instance Optimal Learning
Nov 11, 2015We consider the following basic learning task: given independent draws from an unknown distribution over a discrete support, output an approximation of the distribution that is as accurate as possible in $\ell_1$ distance (i.e. total variation or statistical distance). Perhaps surprisingly, it is often possible to "de-noise" the empirical distribution of the samples to return an approximation of the true distribution that is significantly more accurate than the empirical distribution, without relying on any prior assumptions on the distribution. We present an instance optimal learning algorithm which optimally performs this de-noising for every distribution for which such a de-noising is possible. More formally, given $n$ independent draws from a distribution $p$, our algorithm returns a labelled vector whose expected distance from $p$ is equal to the minimum possible expected error that could be obtained by any algorithm that knows the true unlabeled vector of probabilities of distribution $p$ and simply needs to assign labels, up to an additive subconstant term that is independent of $p$ and goes to zero as $n$ gets large. One conceptual implication of this result is that for large samples, Bayesian assumptions on the "shape" or bounds on the tail probabilities of a distribution over discrete support are not helpful for the task of learning the distribution. As a consequence of our techniques, we also show that given a set of $n$ samples from an arbitrary distribution, one can accurately estimate the expected number of distinct elements that will be observed in a sample of any size up to $n \log n$. This sort of extrapolation is practically relevant, particularly to domains such as genomics where it is important to understand how much more might be discovered given larger sample sizes, and we are optimistic that our approach is practically viable.
Testing Closeness With Unequal Sized Samples
Apr 17, 2015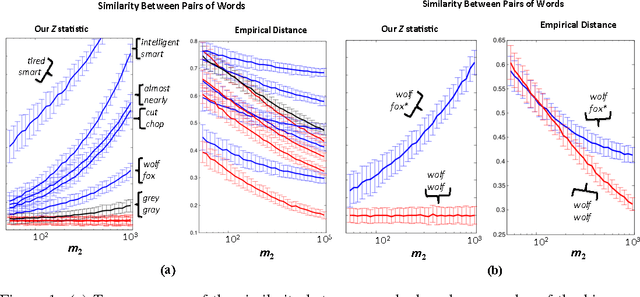
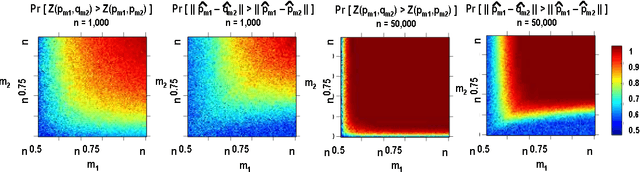
We consider the problem of closeness testing for two discrete distributions in the practically relevant setting of \emph{unequal} sized samples drawn from each of them. Specifically, given a target error parameter $\varepsilon > 0$, $m_1$ independent draws from an unknown distribution $p,$ and $m_2$ draws from an unknown distribution $q$, we describe a test for distinguishing the case that $p=q$ from the case that $||p-q||_1 \geq \varepsilon$. If $p$ and $q$ are supported on at most $n$ elements, then our test is successful with high probability provided $m_1\geq n^{2/3}/\varepsilon^{4/3}$ and $m_2 = \Omega(\max\{\frac{n}{\sqrt m_1\varepsilon^2}, \frac{\sqrt n}{\varepsilon^2}\});$ we show that this tradeoff is optimal throughout this range, to constant factors. These results extend the recent work of Chan et al. who established the sample complexity when the two samples have equal sizes, and tightens the results of Acharya et al. by polynomials factors in both $n$ and $\varepsilon$. As a consequence, we obtain an algorithm for estimating the mixing time of a Markov chain on $n$ states up to a $\log n$ factor that uses $\tilde{O}(n^{3/2} \tau_{mix})$ queries to a "next node" oracle, improving upon the $\tilde{O}(n^{5/3}\tau_{mix})$ query algorithm of Batu et al. Finally, we note that the core of our testing algorithm is a relatively simple statistic that seems to perform well in practice, both on synthetic data and on natural language data.
Least Squares Revisited: Scalable Approaches for Multi-class Prediction
Oct 21, 2013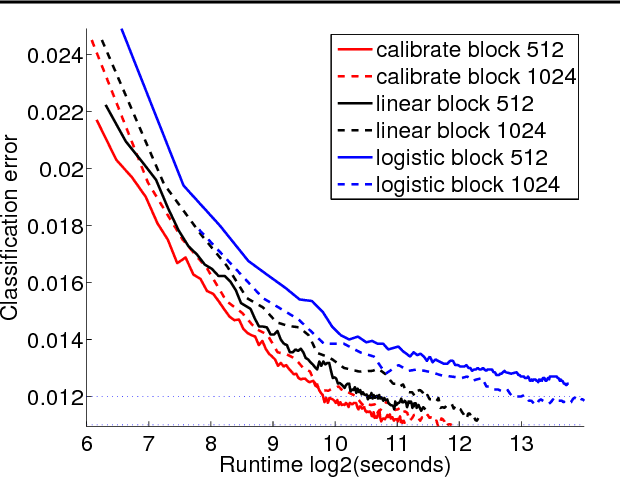

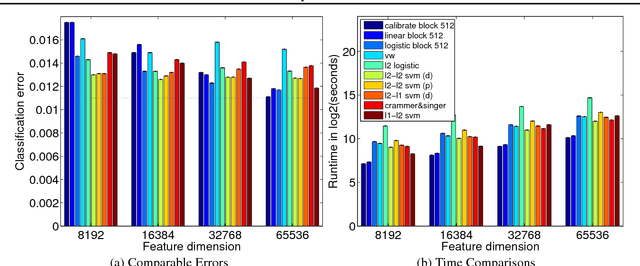
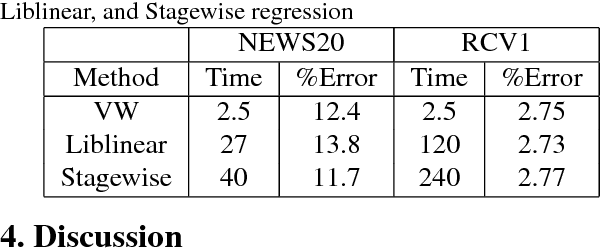
This work provides simple algorithms for multi-class (and multi-label) prediction in settings where both the number of examples n and the data dimension d are relatively large. These robust and parameter free algorithms are essentially iterative least-squares updates and very versatile both in theory and in practice. On the theoretical front, we present several variants with convergence guarantees. Owing to their effective use of second-order structure, these algorithms are substantially better than first-order methods in many practical scenarios. On the empirical side, we present a scalable stagewise variant of our approach, which achieves dramatic computational speedups over popular optimization packages such as Liblinear and Vowpal Wabbit on standard datasets (MNIST and CIFAR-10), while attaining state-of-the-art accuracies.
Optimal Algorithms for Testing Closeness of Discrete Distributions
Aug 19, 2013We study the question of closeness testing for two discrete distributions. More precisely, given samples from two distributions $p$ and $q$ over an $n$-element set, we wish to distinguish whether $p=q$ versus $p$ is at least $\eps$-far from $q$, in either $\ell_1$ or $\ell_2$ distance. Batu et al. gave the first sub-linear time algorithms for these problems, which matched the lower bounds of Valiant up to a logarithmic factor in $n$, and a polynomial factor of $\eps.$ In this work, we present simple (and new) testers for both the $\ell_1$ and $\ell_2$ settings, with sample complexity that is information-theoretically optimal, to constant factors, both in the dependence on $n$, and the dependence on $\eps$; for the $\ell_1$ testing problem we establish that the sample complexity is $\Theta(\max\{n^{2/3}/\eps^{4/3}, n^{1/2}/\eps^2 \}).$
Settling the Polynomial Learnability of Mixtures of Gaussians
Apr 23, 2010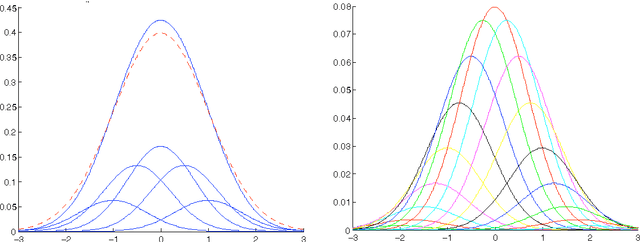


Given data drawn from a mixture of multivariate Gaussians, a basic problem is to accurately estimate the mixture parameters. We give an algorithm for this problem that has a running time, and data requirement polynomial in the dimension and the inverse of the desired accuracy, with provably minimal assumptions on the Gaussians. As simple consequences of our learning algorithm, we can perform near-optimal clustering of the sample points and density estimation for mixtures of k Gaussians, efficiently. The building blocks of our algorithm are based on the work Kalai et al. [STOC 2010] that gives an efficient algorithm for learning mixtures of two Gaussians by considering a series of projections down to one dimension, and applying the method of moments to each univariate projection. A major technical hurdle in Kalai et al. is showing that one can efficiently learn univariate mixtures of two Gaussians. In contrast, because pathological scenarios can arise when considering univariate projections of mixtures of more than two Gaussians, the bulk of the work in this paper concerns how to leverage an algorithm for learning univariate mixtures (of many Gaussians) to yield an efficient algorithm for learning in high dimensions. Our algorithm employs hierarchical clustering and rescaling, together with delicate methods for backtracking and recovering from failures that can occur in our univariate algorithm. Finally, while the running time and data requirements of our algorithm depend exponentially on the number of Gaussians in the mixture, we prove that such a dependence is necessary.