 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Barber: Block-Aware Rebuilder for Sparsity Mask in One-Shot for Large Language Models
Aug 20, 2024Large language models (LLMs) have grown significantly in scale, leading to a critical need for efficient model pruning techniques. Existing post-training pruning techniques primarily focus on measuring weight importance on converged dense models to determine salient weights to retain. However, they often overlook the changes in weight importance during the pruning process, which can lead to performance degradation in the pruned models. To address this issue, we present LLM-Barber (Block-Aware Rebuilder for Sparsity Mask in One-Shot), a novel one-shot pruning framework that rebuilds the sparsity mask of pruned models without any retraining or weight reconstruction. LLM-Barber incorporates block-aware error optimization across Self-Attention and MLP blocks, ensuring global performance optimization. Inspired by the recent discovery of prominent outliers in LLMs, LLM-Barber introduces an innovative pruning metric that identifies weight importance using weights multiplied by gradients. Our experiments show that LLM-Barber can efficiently prune models like LLaMA and OPT families with 7B to 13B parameters on a single A100 GPU in just 30 minutes, achieving state-of-the-art results in both perplexity and zero-shot performance across various language benchmarks. Code is available at https://github.com/YupengSu/LLM-Barber.
Deformable Butterfly: A Highly Structured and Sparse Linear Transform
Mar 25, 2022



We introduce a new kind of linear transform named Deformable Butterfly (DeBut) that generalizes the conventional butterfly matrices and can be adapted to various input-output dimensions. It inherits the fine-to-coarse-grained learnable hierarchy of traditional butterflies and when deployed to neural networks, the prominent structures and sparsity in a DeBut layer constitutes a new way for network compression. We apply DeBut as a drop-in replacement of standard fully connected and convolutional layers, and demonstrate its superiority in homogenizing a neural network and rendering it favorable properties such as light weight and low inference complexity, without compromising accuracy. The natural complexity-accuracy tradeoff arising from the myriad deformations of a DeBut layer also opens up new rooms for analytical and practical research. The codes and Appendix are publicly available at: https://github.com/ruilin0212/DeBut.
Exploiting Elasticity in Tensor Ranks for Compressing Neural Networks
May 10, 2021
Elasticities in depth, width, kernel size and resolution have been explored in compressing deep neural networks (DNNs). Recognizing that the kernels in a convolutional neural network (CNN) are 4-way tensors, we further exploit a new elasticity dimension along the input-output channels. Specifically, a novel nuclear-norm rank minimization factorization (NRMF) approach is proposed to dynamically and globally search for the reduced tensor ranks during training. Correlation between tensor ranks across multiple layers is revealed, and a graceful tradeoff between model size and accuracy is obtained. Experiments then show the superiority of NRMF over the previous non-elastic variational Bayesian matrix factorization (VBMF) scheme.
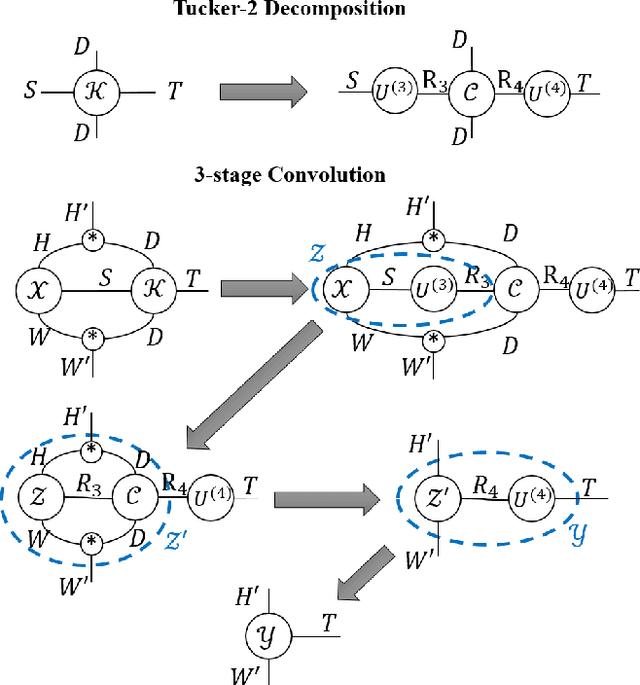
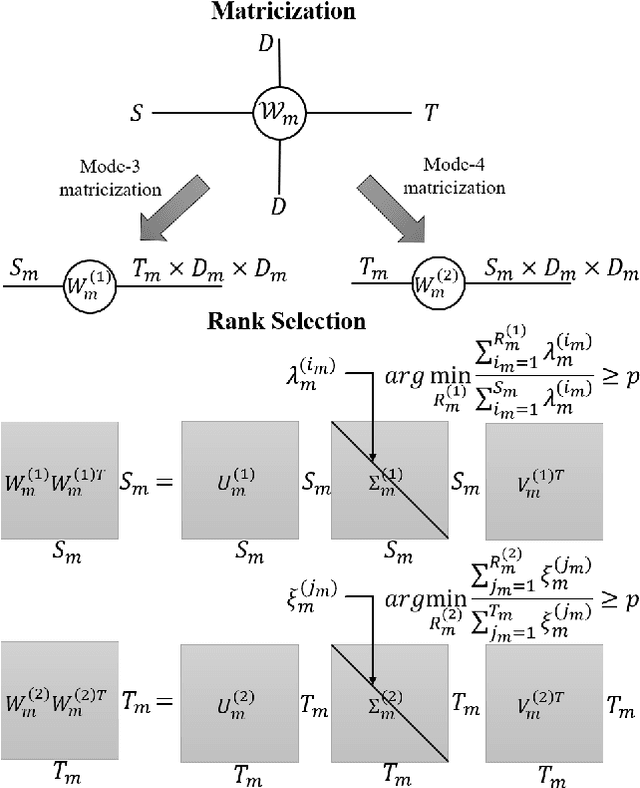
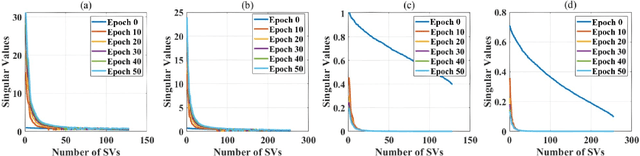
HOTCAKE: Higher Order Tucker Articulated Kernels for Deeper CNN Compression
Feb 28, 2020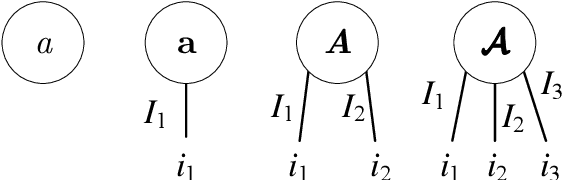
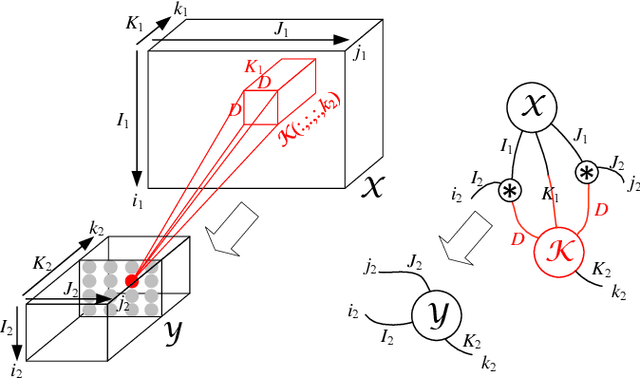
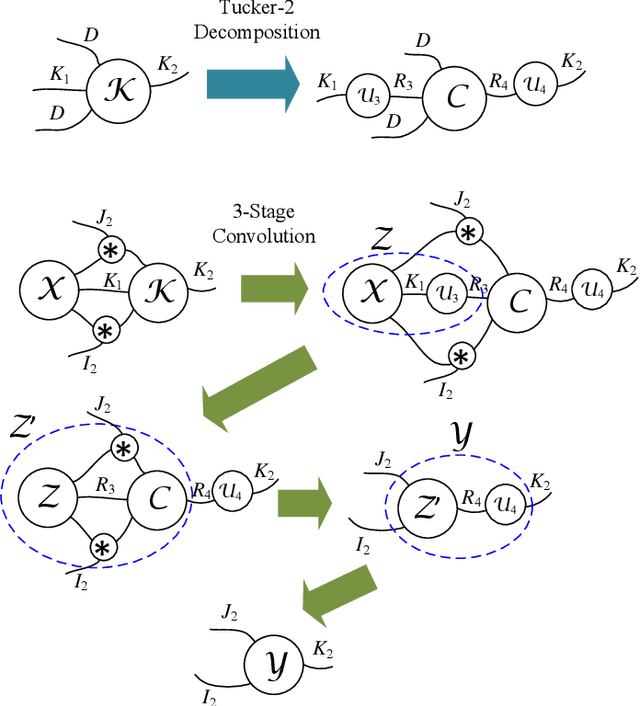
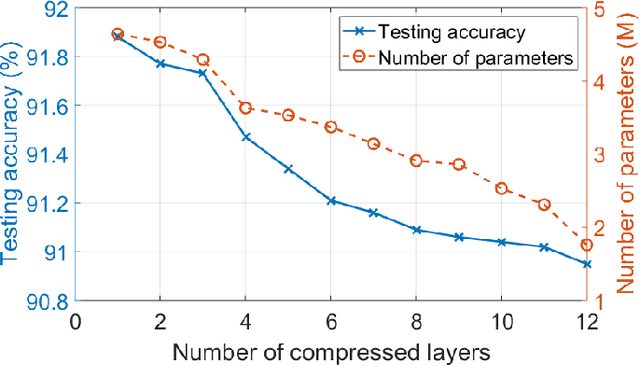
The emerging edge computing has promoted immense interests in compacting a neural network without sacrificing much accuracy. In this regard, low-rank tensor decomposition constitutes a powerful tool to compress convolutional neural networks (CNNs) by decomposing the 4-way kernel tensor into multi-stage smaller ones. Building on top of Tucker-2 decomposition, we propose a generalized Higher Order Tucker Articulated Kernels (HOTCAKE) scheme comprising four steps: input channel decomposition, guided Tucker rank selection, higher order Tucker decomposition and fine-tuning. By subjecting each CONV layer to HOTCAKE, a highly compressed CNN model with graceful accuracy trade-off is obtained. Experiments show HOTCAKE can compress even pre-compressed models and produce state-of-the-art lightweight networks.