 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe "LLM World of Words" English free association norms generated by large language models
Dec 02, 2024Free associations have been extensively used in cognitive psychology and linguistics for studying how conceptual knowledge is organized. Recently, the potential of applying a similar approach for investigating the knowledge encoded in LLMs has emerged, specifically as a method for investigating LLM biases. However, the absence of large-scale LLM-generated free association norms that are comparable with human-generated norms is an obstacle to this new research direction. To address this limitation, we create a new dataset of LLM-generated free association norms modeled after the "Small World of Words" (SWOW) human-generated norms consisting of approximately 12,000 cue words. We prompt three LLMs, namely Mistral, Llama3, and Haiku, with the same cues as those in the SWOW norms to generate three novel comparable datasets, the "LLM World of Words" (LWOW). Using both SWOW and LWOW norms, we construct cognitive network models of semantic memory that represent the conceptual knowledge possessed by humans and LLMs. We demonstrate how these datasets can be used for investigating implicit biases in humans and LLMs, such as the harmful gender stereotypes that are prevalent both in society and LLM outputs.
Forma mentis networks predict creativity ratings of short texts via interpretable artificial intelligence in human and GPT-simulated raters
Nov 30, 2024



Creativity is a fundamental skill of human cognition. We use textual forma mentis networks (TFMN) to extract network (semantic/syntactic associations) and emotional features from approximately one thousand human- and GPT3.5-generated stories. Using Explainable Artificial Intelligence (XAI), we test whether features relative to Mednick's associative theory of creativity can explain creativity ratings assigned by humans and GPT-3.5. Using XGBoost, we examine three scenarios: (i) human ratings of human stories, (ii) GPT-3.5 ratings of human stories, and (iii) GPT-3.5 ratings of GPT-generated stories. Our findings reveal that GPT-3.5 ratings differ significantly from human ratings not only in terms of correlations but also because of feature patterns identified with XAI methods. GPT-3.5 favours 'its own' stories and rates human stories differently from humans. Feature importance analysis with SHAP scores shows that: (i) network features are more predictive for human creativity ratings but also for GPT-3.5's ratings of human stories; (ii) emotional features played a greater role than semantic/syntactic network structure in GPT-3.5 rating its own stories. These quantitative results underscore key limitations in GPT-3.5's ability to align with human assessments of creativity. We emphasise the need for caution when using GPT-3.5 to assess and generate creative content, as it does not yet capture the nuanced complexity that characterises human creativity.
Y Social: an LLM-powered Social Media Digital Twin
Aug 01, 2024



In this paper we introduce Y, a new-generation digital twin designed to replicate an online social media platform. Digital twins are virtual replicas of physical systems that allow for advanced analyses and experimentation. In the case of social media, a digital twin such as Y provides a powerful tool for researchers to simulate and understand complex online interactions. {\tt Y} leverages state-of-the-art Large Language Models (LLMs) to replicate sophisticated agent behaviors, enabling accurate simulations of user interactions, content dissemination, and network dynamics. By integrating these aspects, Y offers valuable insights into user engagement, information spread, and the impact of platform policies. Moreover, the integration of LLMs allows Y to generate nuanced textual content and predict user responses, facilitating the study of emergent phenomena in online environments. To better characterize the proposed digital twin, in this paper we describe the rationale behind its implementation, provide examples of the analyses that can be performed on the data it enables to be generated, and discuss its relevance for multidisciplinary research.
Characterizing User Archetypes and Discussions on Scored.co
Jul 31, 2024In recent years, the proliferation of social platforms has drastically transformed the way individuals interact, organize, and share information. In this scenario, we experience an unprecedented increase in the scale and complexity of interactions and, at the same time, little to no research about some fringe social platforms. In this paper, we present a multi-dimensional framework for characterizing nodes and hyperedges in social hypernetworks, with a focus on the understudied alt-right platform Scored.co. Our approach integrates the possibility of studying higher-order interactions, thanks to the hypernetwork representation, and various node features such as user activity, sentiment, and toxicity, with the aim to define distinct user archetypes and understand their roles within the network. Utilizing a comprehensive dataset from Scored.co, we analyze the dynamics of these archetypes over time and explore their interactions and influence within the community. The framework's versatility allows for detailed analysis of both individual user behaviors and broader social structures. Our findings highlight the importance of higher-order interactions in understanding social dynamics, offering new insights into the roles and behaviors that emerge in complex online environments.
A survey on the impact of AI-based recommenders on human behaviours: methodologies, outcomes and future directions
Jun 29, 2024



Recommendation systems and assistants (in short, recommenders) are ubiquitous in online platforms and influence most actions of our day-to-day lives, suggesting items or providing solutions based on users' preferences or requests. This survey analyses the impact of recommenders in four human-AI ecosystems: social media, online retail, urban mapping and generative AI ecosystems. Its scope is to systematise a fast-growing field in which terminologies employed to classify methodologies and outcomes are fragmented and unsystematic. We follow the customary steps of qualitative systematic review, gathering 144 articles from different disciplines to develop a parsimonious taxonomy of: methodologies employed (empirical, simulation, observational, controlled), outcomes observed (concentration, model collapse, diversity, echo chamber, filter bubble, inequality, polarisation, radicalisation, volume), and their level of analysis (individual, item, model, and systemic). We systematically discuss all findings of our survey substantively and methodologically, highlighting also potential avenues for future research. This survey is addressed to scholars and practitioners interested in different human-AI ecosystems, policymakers and institutional stakeholders who want to understand better the measurable outcomes of recommenders, and tech companies who wish to obtain a systematic view of the impact of their recommenders.
From Perils to Possibilities: Understanding how Human (and AI) Biases affect Online Fora
Mar 21, 2024Social media platforms are online fora where users engage in discussions, share content, and build connections. This review explores the dynamics of social interactions, user-generated contents, and biases within the context of social media analysis (analyzing works that use the tools offered by complex network analysis and natural language processing) through the lens of three key points of view: online debates, online support, and human-AI interactions. On the one hand, we delineate the phenomenon of online debates, where polarization, misinformation, and echo chamber formation often proliferate, driven by algorithmic biases and extreme mechanisms of homophily. On the other hand, we explore the emergence of online support groups through users' self-disclosure and social support mechanisms. Online debates and support mechanisms present a duality of both perils and possibilities within social media; perils of segregated communities and polarized debates, and possibilities of empathy narratives and self-help groups. This dichotomy also extends to a third perspective: users' reliance on AI-generated content, such as the ones produced by Large Language Models, which can manifest both human biases hidden in training sets and non-human biases that emerge from their artificial neural architectures. Analyzing interdisciplinary approaches, we aim to deepen the understanding of the complex interplay between social interactions, user-generated content, and biases within the realm of social media ecosystems.
Redefining Event Types and Group Evolution in Temporal Data
Mar 11, 2024



Groups -- such as clusters of points or communities of nodes -- are fundamental when addressing various data mining tasks. In temporal data, the predominant approach for characterizing group evolution has been through the identification of ``events". However, the events usually described in the literature, e.g., shrinks/growths, splits/merges, are often arbitrarily defined, creating a gap between such theoretical/predefined types and real-data group observations. Moving beyond existing taxonomies, we think of events as ``archetypes" characterized by a unique combination of quantitative dimensions that we call ``facets". Group dynamics are defined by their position within the facet space, where archetypal events occupy extremities. Thus, rather than enforcing strict event types, our approach can allow for hybrid descriptions of dynamics involving group proximity to multiple archetypes. We apply our framework to evolving groups from several face-to-face interaction datasets, showing it enables richer, more reliable characterization of group dynamics with respect to state-of-the-art methods, especially when the groups are subject to complex relationships. Our approach also offers intuitive solutions to common tasks related to dynamic group analysis, such as choosing an appropriate aggregation scale, quantifying partition stability, and evaluating event quality.
Towards hypergraph cognitive networks as feature-rich models of knowledge
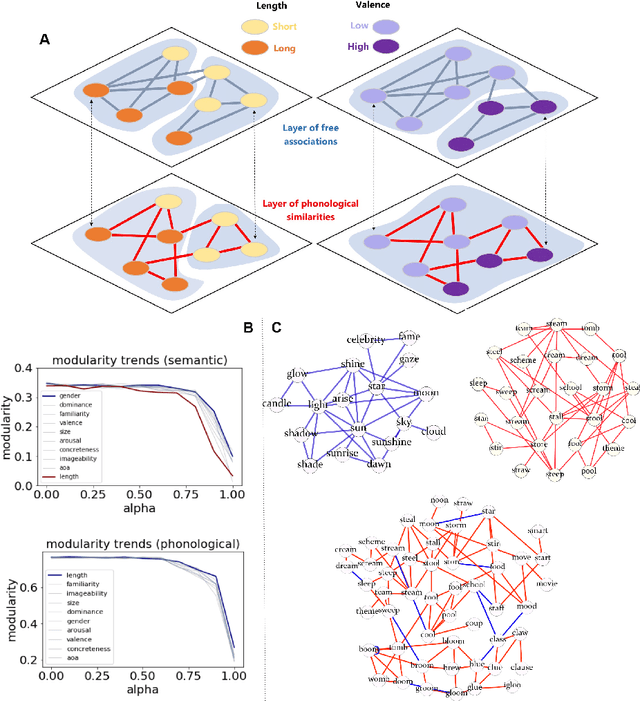
Apr 13, 2023Semantic networks provide a useful tool to understand how related concepts are retrieved from memory. However, most current network approaches use pairwise links to represent memory recall patterns. Pairwise connections neglect higher-order associations, i.e. relationships between more than two concepts at a time. These higher-order interactions might covariate with (and thus contain information about) how similar concepts are along psycholinguistic dimensions like arousal, valence, familiarity, gender and others. We overcome these limits by introducing feature-rich cognitive hypergraphs as quantitative models of human memory where: (i) concepts recalled together can all engage in hyperlinks involving also more than two concepts at once (cognitive hypergraph aspect), and (ii) each concept is endowed with a vector of psycholinguistic features (feature-rich aspect). We build hypergraphs from word association data and use evaluation methods from machine learning features to predict concept concreteness. Since concepts with similar concreteness tend to cluster together in human memory, we expect to be able to leverage this structure. Using word association data from the Small World of Words dataset, we compared a pairwise network and a hypergraph with N=3586 concepts/nodes. Interpretable artificial intelligence models trained on (1) psycholinguistic features only, (2) pairwise-based feature aggregations, and on (3) hypergraph-based aggregations show significant differences between pairwise and hypergraph links. Specifically, our results show that higher-order and feature-rich hypergraph models contain richer information than pairwise networks leading to improved prediction of word concreteness. The relation with previous studies about conceptual clustering and compartmentalisation in associative knowledge and human memory are discussed.
Cognitive modelling with multilayer networks: Insights, advancements and future challenges
Oct 02, 2022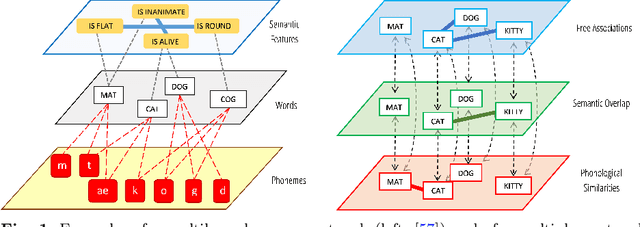
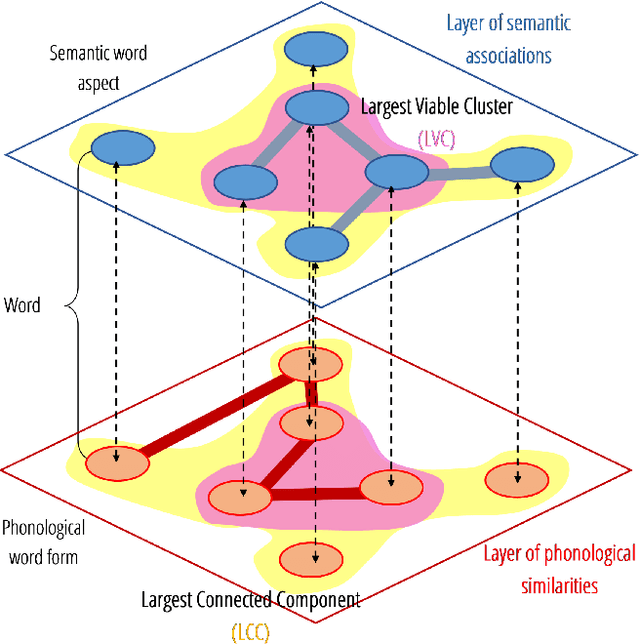
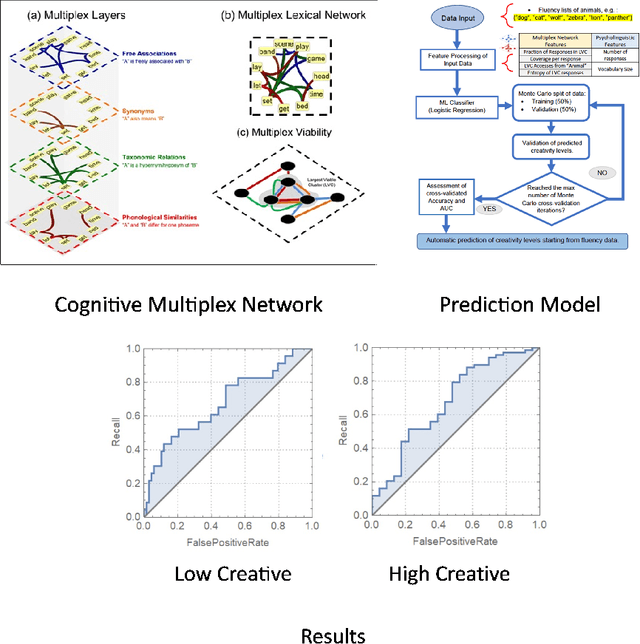
The mental lexicon is a complex cognitive system representing information about the words/concepts that one knows. Decades of psychological experiments have shown that conceptual associations across multiple, interactive cognitive levels can greatly influence word acquisition, storage, and processing. How can semantic, phonological, syntactic, and other types of conceptual associations be mapped within a coherent mathematical framework to study how the mental lexicon works? We here review cognitive multilayer networks as a promising quantitative and interpretative framework for investigating the mental lexicon. Cognitive multilayer networks can map multiple types of information at once, thus capturing how different layers of associations might co-exist within the mental lexicon and influence cognitive processing. This review starts with a gentle introduction to the structure and formalism of multilayer networks. We then discuss quantitative mechanisms of psychological phenomena that could not be observed in single-layer networks and were only unveiled by combining multiple layers of the lexicon: (i) multiplex viability highlights language kernels and facilitative effects of knowledge processing in healthy and clinical populations; (ii) multilayer community detection enables contextual meaning reconstruction depending on psycholinguistic features; (iii) layer analysis can mediate latent interactions of mediation, suppression and facilitation for lexical access. By outlining novel quantitative perspectives where multilayer networks can shed light on cognitive knowledge representations, also in next-generation brain/mind models, we discuss key limitations and promising directions for cutting-edge future research.
Feature-rich multiplex lexical networks reveal mental strategies of early language learning
Jan 13, 2022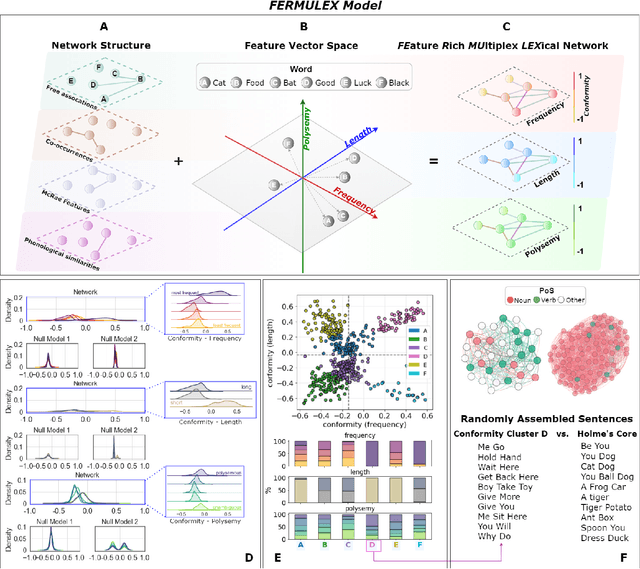
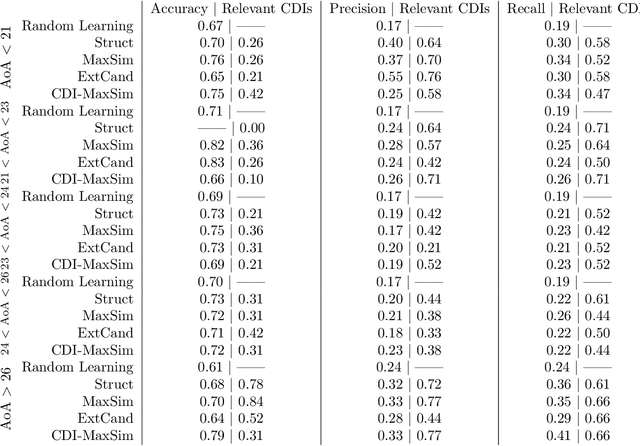
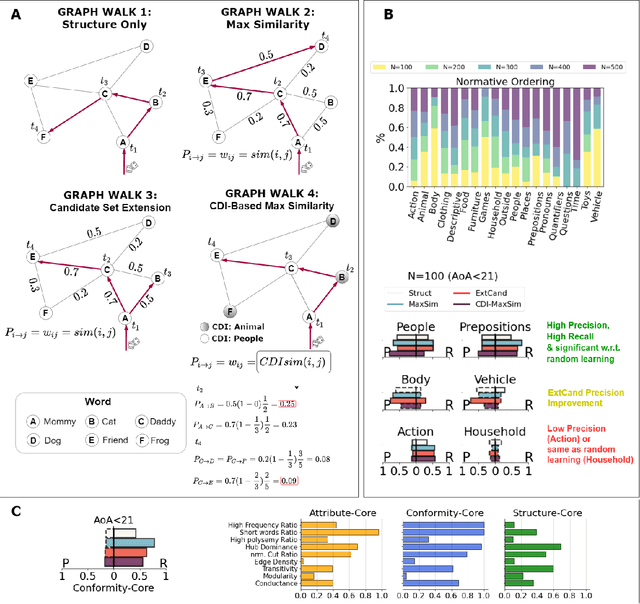
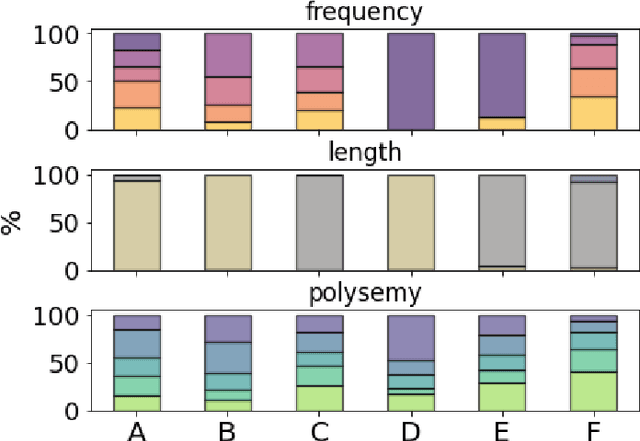
Knowledge in the human mind exhibits a dualistic vector/network nature. Modelling words as vectors is key to natural language processing, whereas networks of word associations can map the nature of semantic memory. We reconcile these paradigms - fragmented across linguistics, psychology and computer science - by introducing FEature-Rich MUltiplex LEXical (FERMULEX) networks. This novel framework merges structural similarities in networks and vector features of words, which can be combined or explored independently. Similarities model heterogenous word associations across semantic/syntactic/phonological aspects of knowledge. Words are enriched with multi-dimensional feature embeddings including frequency, age of acquisition, length and polysemy. These aspects enable unprecedented explorations of cognitive knowledge. Through CHILDES data, we use FERMULEX networks to model normative language acquisition by 1000 toddlers between 18 and 30 months. Similarities and embeddings capture word homophily via conformity, which measures assortative mixing via distance and features. Conformity unearths a language kernel of frequent/polysemous/short nouns and verbs key for basic sentence production, supporting recent evidence of children's syntactic constructs emerging at 30 months. This kernel is invisible to network core-detection and feature-only clustering: It emerges from the dual vector/network nature of words. Our quantitative analysis reveals two key strategies in early word learning. Modelling word acquisition as random walks on FERMULEX topology, we highlight non-uniform filling of communicative developmental inventories (CDIs). Conformity-based walkers lead to accurate (75%), precise (55%) and partially well-recalled (34%) predictions of early word learning in CDIs, providing quantitative support to previous empirical findings and developmental theories.