 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating two value functions instead of one: towards characterizing a new family of Deep Reinforcement Learning algorithms
Sep 01, 2019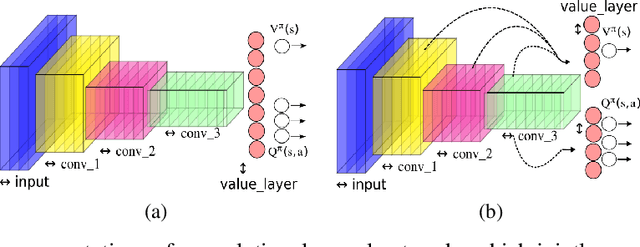
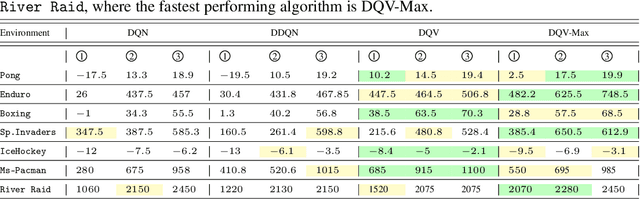
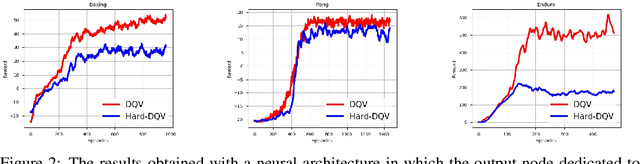
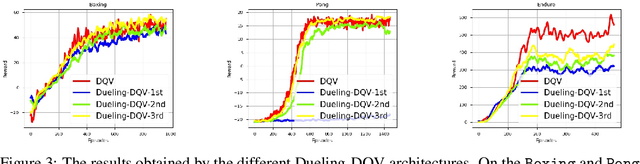
This paper makes one step forward towards characterizing a new family of \textit{model-free} Deep Reinforcement Learning (DRL) algorithms. The aim of these algorithms is to jointly learn an approximation of the state-value function ($V$), alongside an approximation of the state-action value function ($Q$). Our analysis starts with a thorough study of the Deep Quality-Value Learning (DQV) algorithm, a DRL algorithm which has been shown to outperform popular techniques such as Deep-Q-Learning (DQN) and Double-Deep-Q-Learning (DDQN) \cite{sabatelli2018deep}. Intending to investigate why DQV's learning dynamics allow this algorithm to perform so well, we formulate a set of research questions which help us characterize a new family of DRL algorithms. Among our results, we present some specific cases in which DQV's performance can get harmed and introduce a novel \textit{off-policy} DRL algorithm, called DQV-Max, which can outperform DQV. We then study the behavior of the $V$ and $Q$ functions that are learned by DQV and DQV-Max and show that both algorithms might perform so well on several DRL test-beds because they are less prone to suffer from the overestimation bias of the $Q$ function.
Unconstrained Monotonic Neural Networks
Aug 14, 2019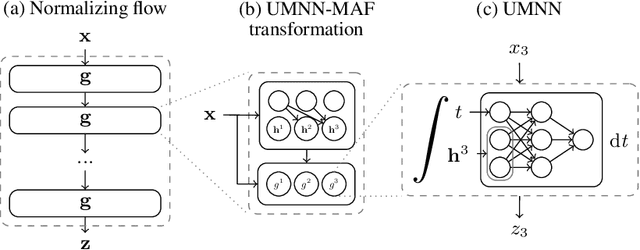
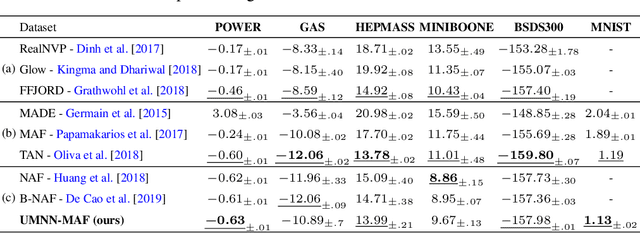

Monotonic neural networks have recently been proposed as a way to define invertible transformations. These transformations can be combined into powerful autoregressive flows that have been shown to be universal approximators of continuous probability distributions. Architectures that ensure monotonicity typically enforce constraints on weights and activation functions, which enables invertibility but leads to a cap on the expressiveness of the resulting transformations. In this work, we propose the Unconstrained Monotonic Neural Network (UMNN) architecture based on the insight that a function is monotonic as long as its derivative is strictly positive. In particular, this latter condition can be enforced with a free-form neural network whose only constraint is the positiveness of its output. We evaluate our new invertible building block within a new autoregressive flow (UMNN-MAF) and demonstrate its effectiveness on density estimation experiments. We also illustrate the ability of UMNNs to improve variational inference.
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Jul 08, 2019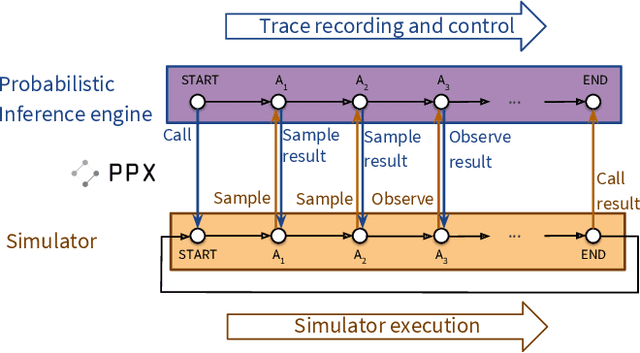

Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN--LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
Effective LHC measurements with matrix elements and machine learning
Jun 04, 2019
One major challenge for the legacy measurements at the LHC is that the likelihood function is not tractable when the collected data is high-dimensional and the detector response has to be modeled. We review how different analysis strategies solve this issue, including the traditional histogram approach used in most particle physics analyses, the Matrix Element Method, Optimal Observables, and modern techniques based on neural density estimation. We then discuss powerful new inference methods that use a combination of matrix element information and machine learning to accurately estimate the likelihood function. The MadMiner package automates all necessary data-processing steps. In first studies we find that these new techniques have the potential to substantially improve the sensitivity of the LHC legacy measurements.
Likelihood-free MCMC with Approximate Likelihood Ratios
Mar 10, 2019
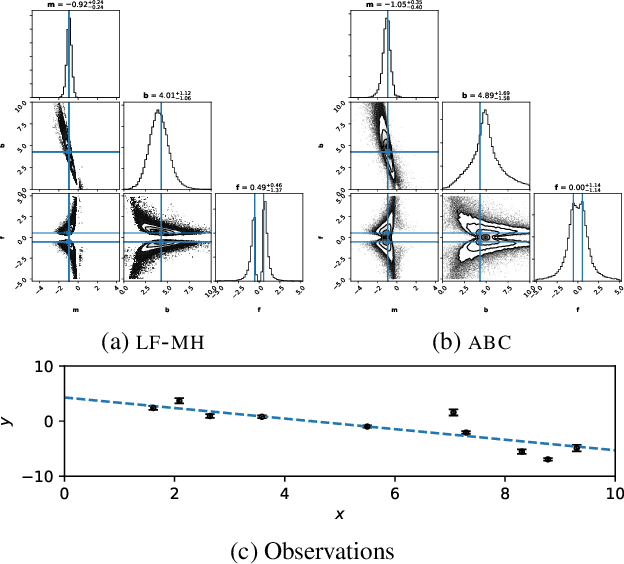
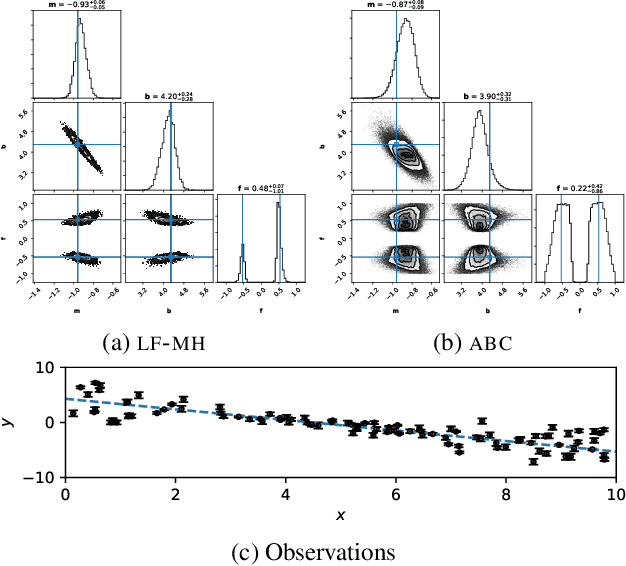
We propose a novel approach for posterior sampling with intractable likelihoods. This is an increasingly important problem in scientific applications where models are implemented as sophisticated computer simulations. As a result, tractable densities are not available, which forces practitioners to rely on approximations during inference. We address the intractability of densities by training a parameterized classifier whose output is used to approximate likelihood ratios between arbitrary model parameters. In turn, we are able to draw posterior samples by plugging this approximator into common Markov chain Monte Carlo samplers such as Metropolis-Hastings and Hamiltonian Monte Carlo. We demonstrate the proposed technique by fitting the generating parameters of implicit models, ranging from a linear probabilistic model to settings in high energy physics with high-dimensional observations. Finally, we discuss several diagnostics to assess the quality of the posterior.
Recurrent machines for likelihood-free inference
Nov 30, 2018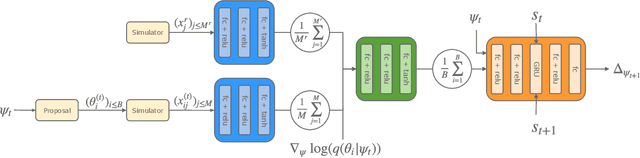
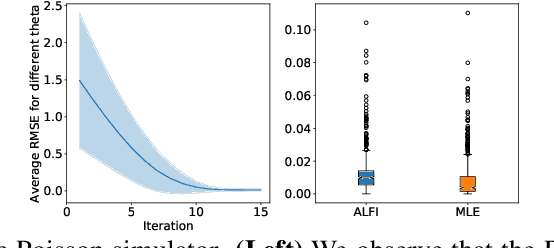
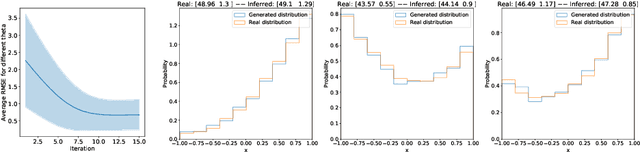
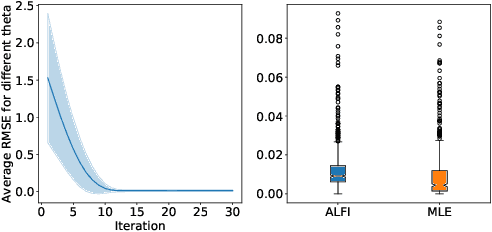
Likelihood-free inference is concerned with the estimation of the parameters of a non-differentiable stochastic simulator that best reproduce real observations. In the absence of a likelihood function, most of the existing inference methods optimize the simulator parameters through a handcrafted iterative procedure that tries to make the simulated data more similar to the observations. In this work, we explore whether meta-learning can be used in the likelihood-free context, for learning automatically from data an iterative optimization procedure that would solve likelihood-free inference problems. We design a recurrent inference machine that learns a sequence of parameter updates leading to good parameter estimates, without ever specifying some explicit notion of divergence between the simulated data and the real data distributions. We demonstrate our approach on toy simulators, showing promising results both in terms of performance and robustness.
Deep Quality-Value (DQV) Learning
Oct 10, 2018
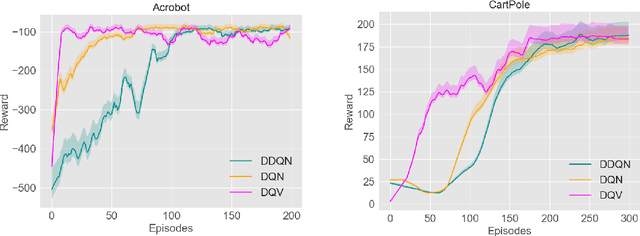
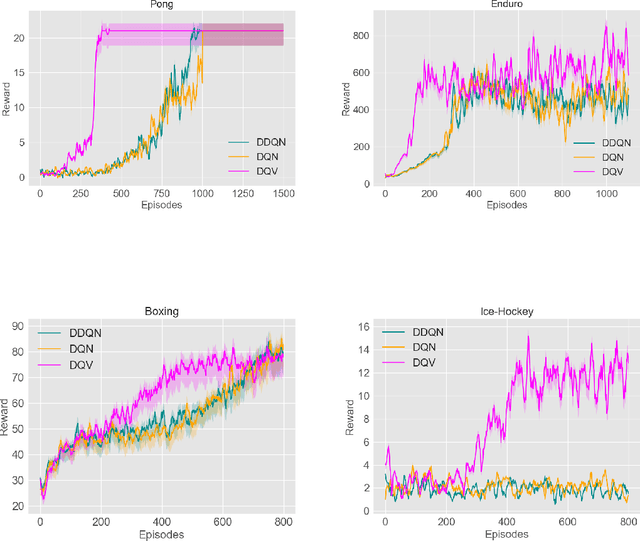
We introduce a novel Deep Reinforcement Learning (DRL) algorithm called Deep Quality-Value (DQV) Learning. DQV uses temporal-difference learning to train a Value neural network and uses this network for training a second Quality-value network that learns to estimate state-action values. We first test DQV's update rules with Multilayer Perceptrons as function approximators on two classic RL problems, and then extend DQV with the use of Deep Convolutional Neural Networks, `Experience Replay' and `Target Neural Networks' for tackling four games of the Atari Arcade Learning environment. Our results show that DQV learns significantly faster and better than Deep Q-Learning and Double Deep Q-Learning, suggesting that our algorithm can potentially be a better performing synchronous temporal difference algorithm than what is currently present in DRL.
Mining gold from implicit models to improve likelihood-free inference
Oct 09, 2018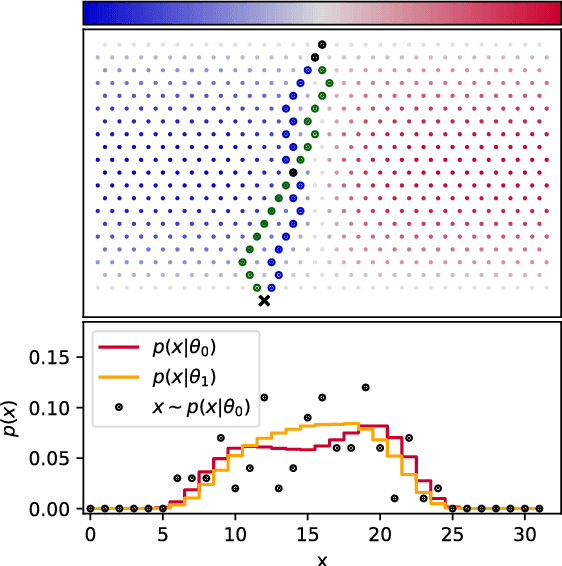
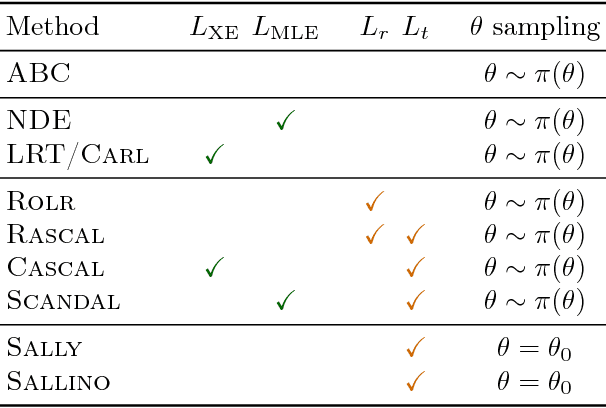
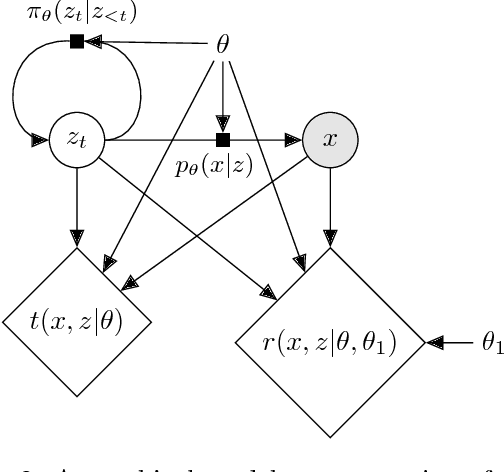
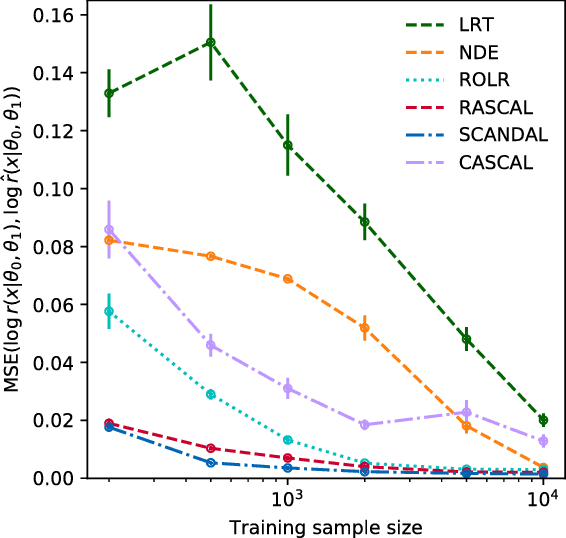
Simulators often provide the best description of real-world phenomena. However, they also lead to challenging inverse problems because the density they implicitly define is often intractable. We present a new suite of simulation-based inference techniques that go beyond the traditional Approximate Bayesian Computation approach, which struggles in a high-dimensional setting, and extend methods that use surrogate models based on neural networks. We show that additional information, such as the joint likelihood ratio and the joint score, can often be extracted from simulators and used to augment the training data for these surrogate models. Finally, we demonstrate that these new techniques are more sample efficient and provide higher-fidelity inference than traditional methods.
Adversarial Variational Optimization of Non-Differentiable Simulators
Oct 05, 2018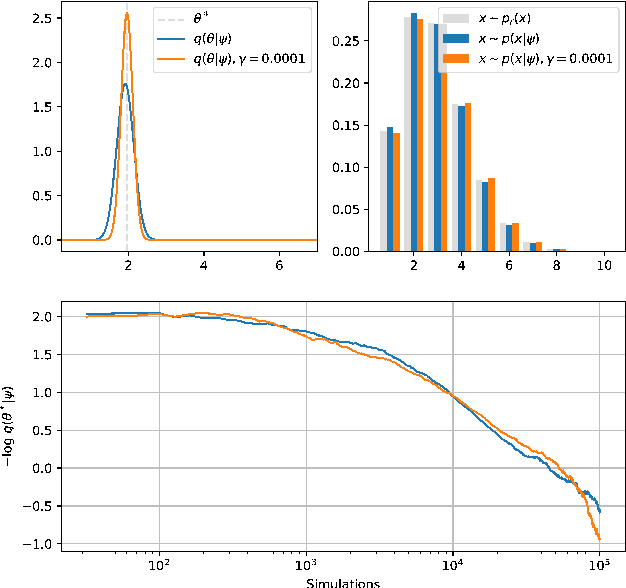
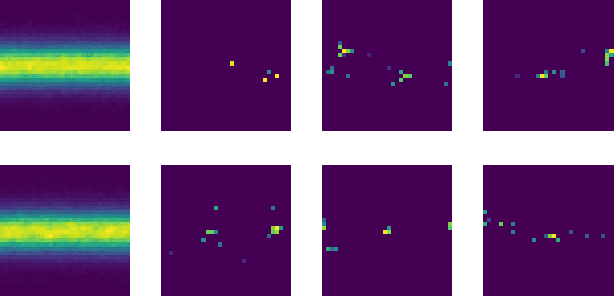
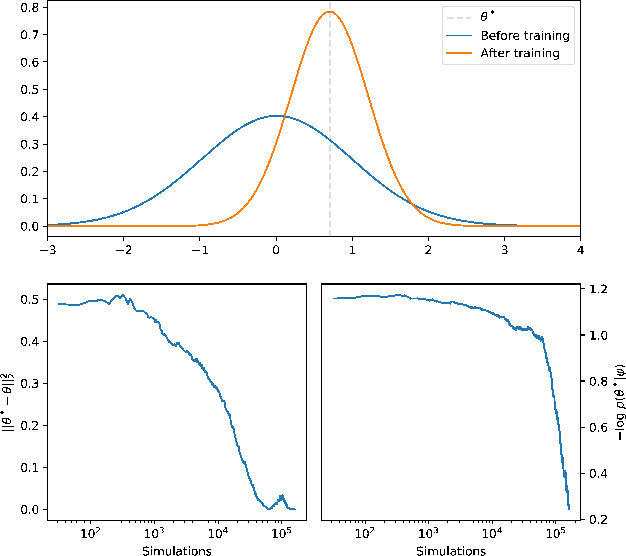
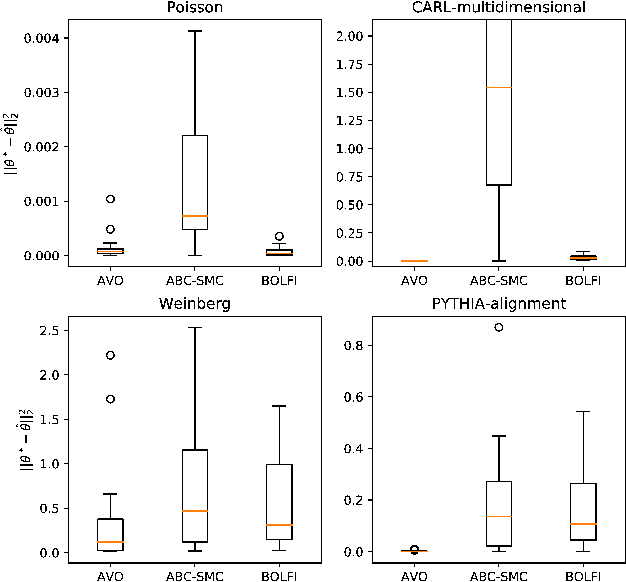
Complex computer simulators are increasingly used across fields of science as generative models tying parameters of an underlying theory to experimental observations. Inference in this setup is often difficult, as simulators rarely admit a tractable density or likelihood function. We introduce Adversarial Variational Optimization (AVO), a likelihood-free inference algorithm for fitting a non-differentiable generative model incorporating ideas from generative adversarial networks, variational optimization and empirical Bayes. We adapt the training procedure of generative adversarial networks by replacing the differentiable generative network with a domain-specific simulator. We solve the resulting non-differentiable minimax problem by minimizing variational upper bounds of the two adversarial objectives. Effectively, the procedure results in learning a proposal distribution over simulator parameters, such that the JS divergence between the marginal distribution of the synthetic data and the empirical distribution of observed data is minimized. We evaluate and compare the method with simulators producing both discrete and continuous data.
Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model
Sep 01, 2018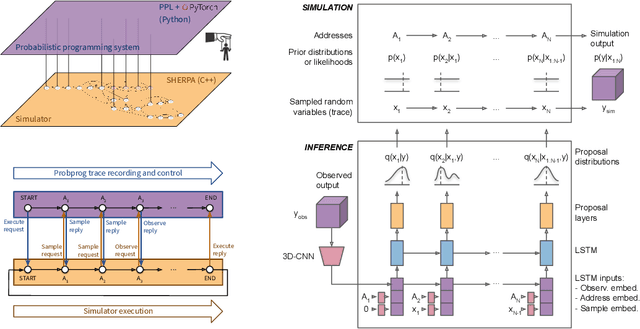
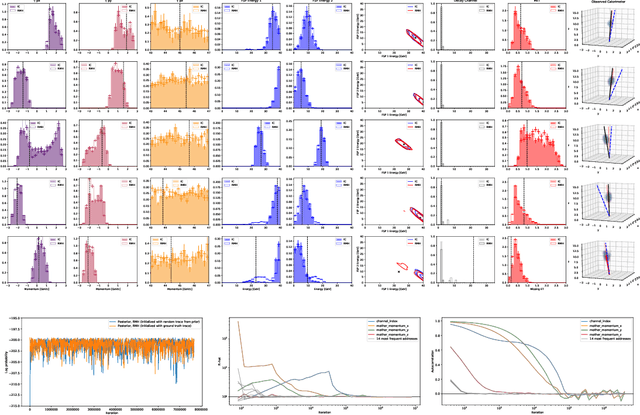


We present a novel framework that enables efficient probabilistic inference in large-scale scientific models by allowing the execution of existing domain-specific simulators as probabilistic programs, resulting in highly interpretable posterior inference. Our framework is general purpose and scalable, and is based on a cross-platform probabilistic execution protocol through which an inference engine can control simulators in a language-agnostic way. We demonstrate the technique in particle physics, on a scientifically accurate simulation of the tau lepton decay, which is a key ingredient in establishing the properties of the Higgs boson. High-energy physics has a rich set of simulators based on quantum field theory and the interaction of particles in matter. We show how to use probabilistic programming to perform Bayesian inference in these existing simulator codebases directly, in particular conditioning on observable outputs from a simulated particle detector to directly produce an interpretable posterior distribution over decay pathways. Inference efficiency is achieved via inference compilation where a deep recurrent neural network is trained to parameterize proposal distributions and control the stochastic simulator in a sequential importance sampling scheme, at a fraction of the computational cost of Markov chain Monte Carlo sampling.