 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Capacity Expert Binary Networks
Oct 07, 2020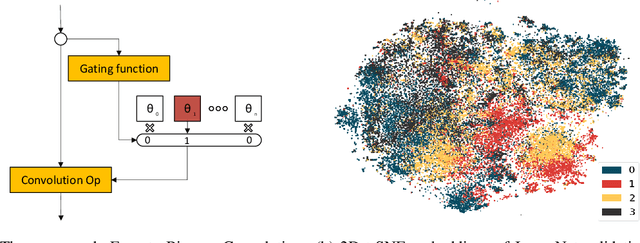
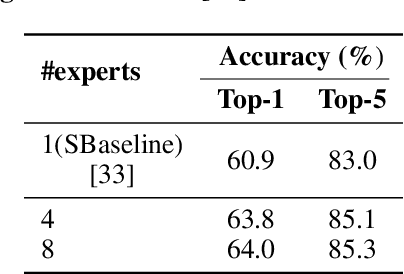
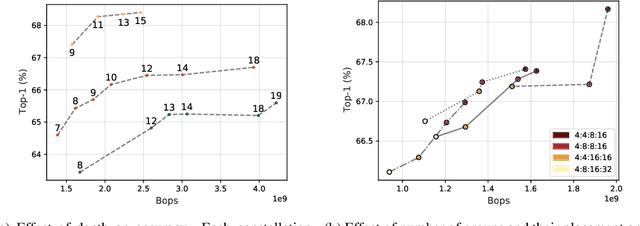
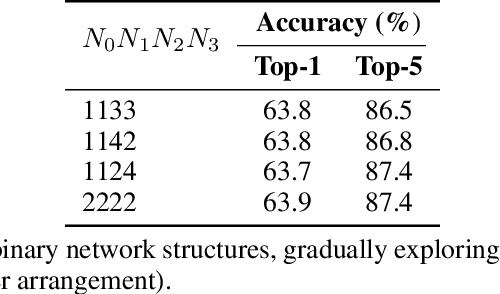
Network binarization is a promising hardware-aware direction for creating efficient deep models. Despite its memory and computational advantages, reducing the accuracy gap between such models and their real-valued counterparts remains an unsolved challenging research problem. To this end, we make the following 3 contributions: (a) To increase model capacity, we propose Expert Binary Convolution, which, for the first time, tailors conditional computing to binary networks by learning to select one data-specific expert binary filter at a time conditioned on input features. (b) To increase representation capacity, we propose to address the inherent information bottleneck in binary networks by introducing an efficient width expansion mechanism which keeps the binary operations within the same budget. (c) To improve network design, we propose a principled binary network growth mechanism that unveils a set of network topologies of favorable properties. Overall, our method improves upon prior work, with no increase in computational cost by ~6%, reaching a groundbreaking ~71% on ImageNet classification.
A Transfer Learning approach to Heatmap Regression for Action Unit intensity estimation
Apr 14, 2020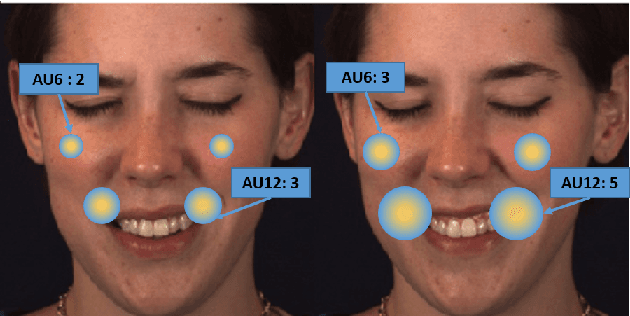
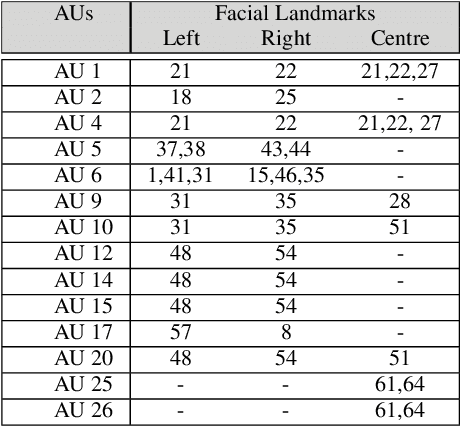
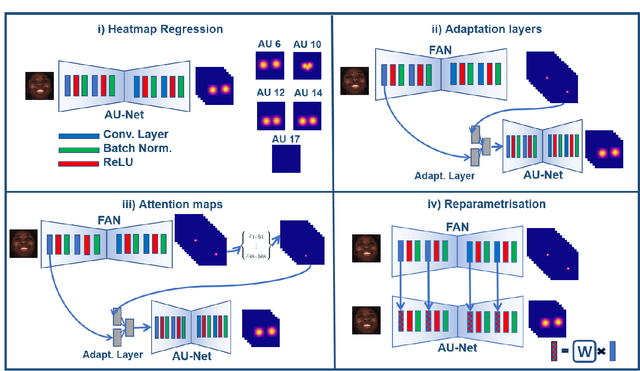
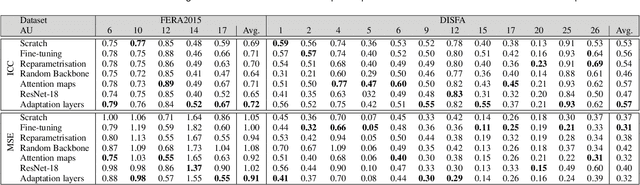
Action Units (AUs) are geometrically-based atomic facial muscle movements known to produce appearance changes at specific facial locations. Motivated by this observation we propose a novel AU modelling problem that consists of jointly estimating their localisation and intensity. To this end, we propose a simple yet efficient approach based on Heatmap Regression that merges both problems into a single task. A Heatmap models whether an AU occurs or not at a given spatial location. To accommodate the joint modelling of AUs intensity, we propose variable size heatmaps, with their amplitude and size varying according to the labelled intensity. Using Heatmap Regression, we can inherit from the progress recently witnessed in facial landmark localisation. Building upon the similarities between both problems, we devise a transfer learning approach where we exploit the knowledge of a network trained on large-scale facial landmark datasets. In particular, we explore different alternatives for transfer learning through a) fine-tuning, b) adaptation layers, c) attention maps, and d) reparametrisation. Our approach effectively inherits the rich facial features produced by a strong face alignment network, with minimal extra computational cost. We empirically validate that our system sets a new state-of-the-art on three popular datasets, namely BP4D, DISFA, and FERA2017.
Training Binary Neural Networks with Real-to-Binary Convolutions
Mar 25, 2020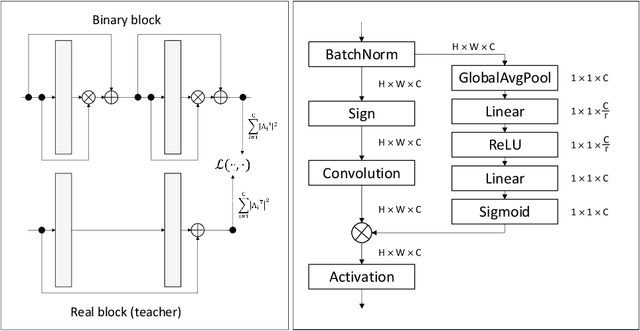
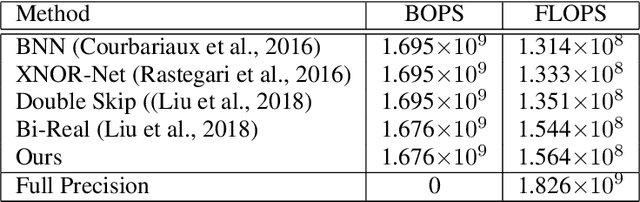
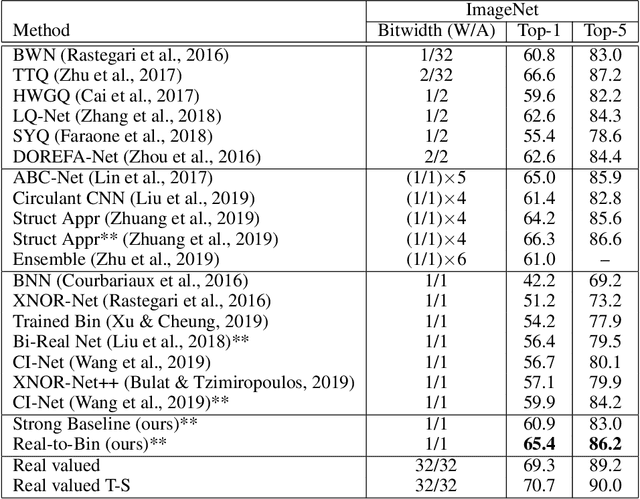
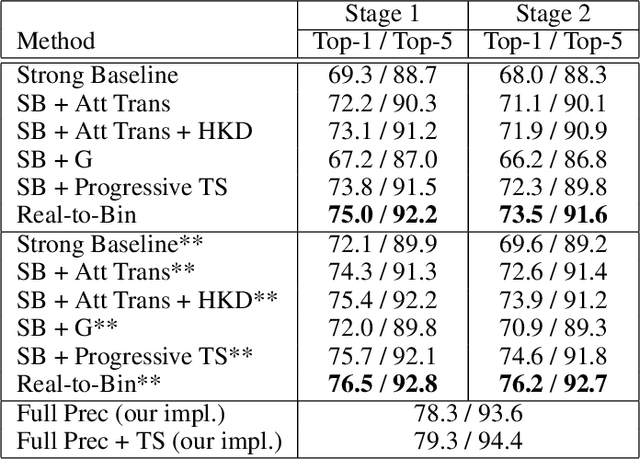
This paper shows how to train binary networks to within a few percent points ($\sim 3-5 \%$) of the full precision counterpart. We first show how to build a strong baseline, which already achieves state-of-the-art accuracy, by combining recently proposed advances and carefully adjusting the optimization procedure. Secondly, we show that by attempting to minimize the discrepancy between the output of the binary and the corresponding real-valued convolution, additional significant accuracy gains can be obtained. We materialize this idea in two complementary ways: (1) with a loss function, during training, by matching the spatial attention maps computed at the output of the binary and real-valued convolutions, and (2) in a data-driven manner, by using the real-valued activations, available during inference prior to the binarization process, for re-scaling the activations right after the binary convolution. Finally, we show that, when putting all of our improvements together, the proposed model beats the current state of the art by more than 5% top-1 accuracy on ImageNet and reduces the gap to its real-valued counterpart to less than 3% and 5% top-1 accuracy on CIFAR-100 and ImageNet respectively when using a ResNet-18 architecture. Code available at https://github.com/brais-martinez/real2binary.
Knowledge distillation via adaptive instance normalization
Mar 09, 2020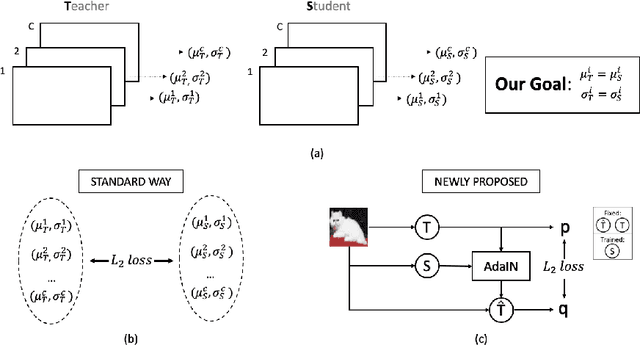
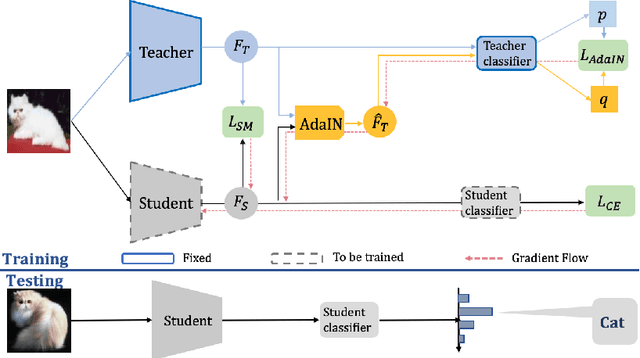
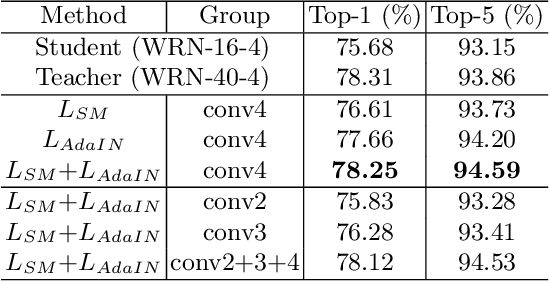
This paper addresses the problem of model compression via knowledge distillation. To this end, we propose a new knowledge distillation method based on transferring feature statistics, specifically the channel-wise mean and variance, from the teacher to the student. Our method goes beyond the standard way of enforcing the mean and variance of the student to be similar to those of the teacher through an $L_2$ loss, which we found it to be of limited effectiveness. Specifically, we propose a new loss based on adaptive instance normalization to effectively transfer the feature statistics. The main idea is to transfer the learned statistics back to the teacher via adaptive instance normalization (conditioned on the student) and let the teacher network "evaluate" via a loss whether the statistics learned by the student are reliably transferred. We show that our distillation method outperforms other state-of-the-art distillation methods over a large set of experimental settings including different (a) network architectures, (b) teacher-student capacities, (c) datasets, and (d) domains.
BATS: Binary ArchitecTure Search
Mar 03, 2020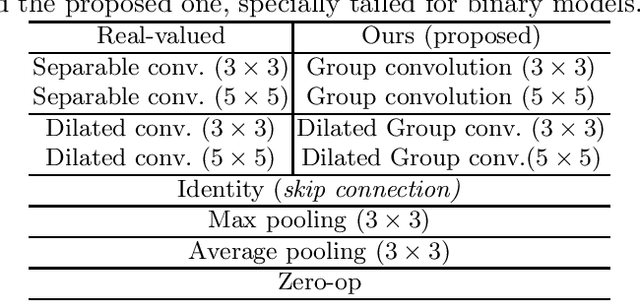
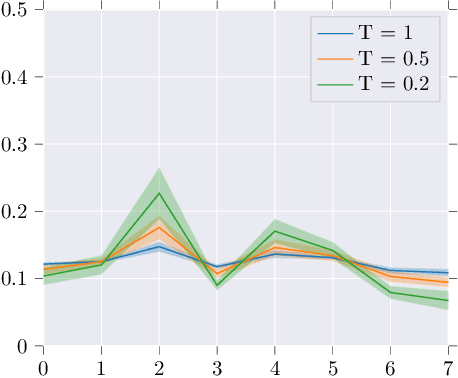
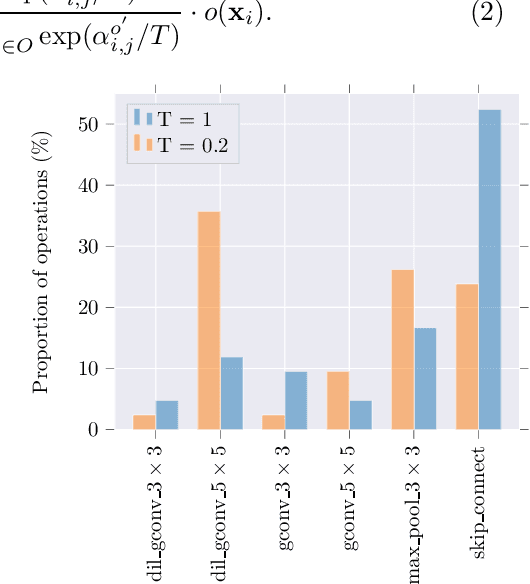

This paper proposes Binary ArchitecTure Search (BATS), a framework that drastically reduces the accuracy gap between binary neural networks and their real-valued counterparts by means of Neural Architecture Search (NAS). We show that directly applying NAS to the binary domain provides very poor results. To alleviate this, we describe, to our knowledge, for the first time, the 3 key ingredients for successfully applying NAS to the binary domain. Specifically, we (1) introduce and design a novel binary-oriented search space, (2) propose a new mechanism for controlling and stabilising the resulting searched topologies, (3) propose and validate a series of new search strategies for binary networks that lead to faster convergence and lower search times. Experimental results demonstrate the effectiveness of the proposed approach and the necessity of searching in the binary space directly. Moreover, (4) we set a new state-of-the-art for binary neural networks on CIFAR10, CIFAR100 and ImageNet datasets. Code will be made available https://github.com/1adrianb/binary-nas
Toward fast and accurate human pose estimation via soft-gated skip connections
Feb 25, 2020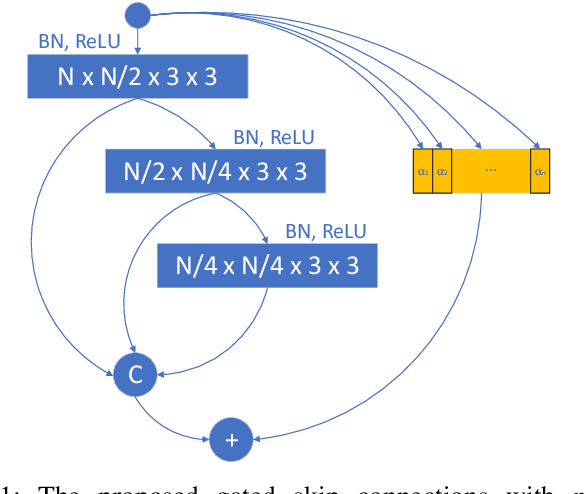
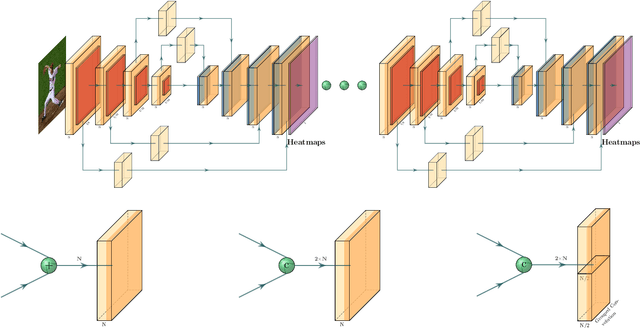

This paper is on highly accurate and highly efficient human pose estimation. Recent works based on Fully Convolutional Networks (FCNs) have demonstrated excellent results for this difficult problem. While residual connections within FCNs have proved to be quintessential for achieving high accuracy, we re-analyze this design choice in the context of improving both the accuracy and the efficiency over the state-of-the-art. In particular, we make the following contributions: (a) We propose gated skip connections with per-channel learnable parameters to control the data flow for each channel within the module within the macro-module. (b) We introduce a hybrid network that combines the HourGlass and U-Net architectures which minimizes the number of identity connections within the network and increases the performance for the same parameter budget. Our model achieves state-of-the-art results on the MPII and LSP datasets. In addition, with a reduction of 3x in model size and complexity, we show no decrease in performance when compared to the original HourGlass network.
Towards Pose-invariant Lip-Reading
Nov 14, 2019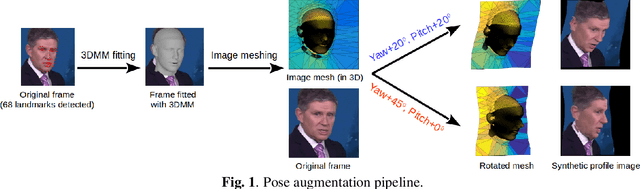
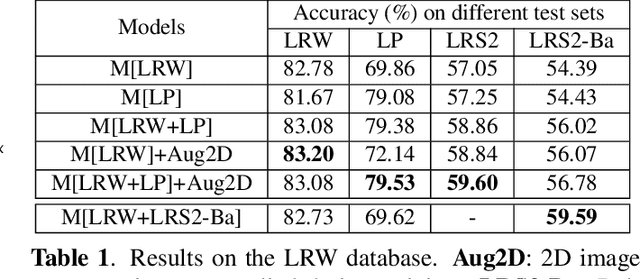
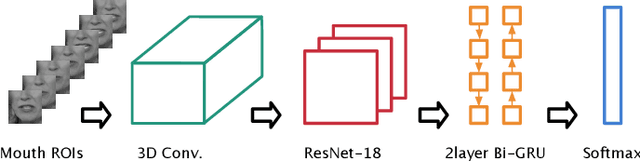
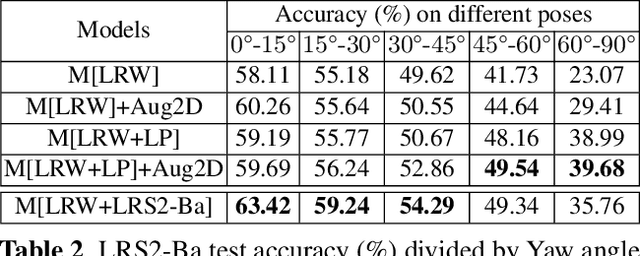
Lip-reading models have been significantly improved recently thanks to powerful deep learning architectures. However, most works focused on frontal or near frontal views of the mouth. As a consequence, lip-reading performance seriously deteriorates in non-frontal mouth views. In this work, we present a framework for training pose-invariant lip-reading models on synthetic data instead of collecting and annotating non-frontal data which is costly and tedious. The proposed model significantly outperforms previous approaches on non-frontal views while retaining the superior performance on frontal and near frontal mouth views. Specifically, we propose to use a 3D Morphable Model (3DMM) to augment LRW, an existing large-scale but mostly frontal dataset, by generating synthetic facial data in arbitrary poses. The newly derived dataset, is used to train a state-of-the-art neural network for lip-reading. We conducted a cross-database experiment for isolated word recognition on the LRS2 dataset, and reported an absolute improvement of 2.55%. The benefit of the proposed approach becomes clearer in extreme poses where an absolute improvement of up to 20.64% over the baseline is achieved.
Object landmark discovery through unsupervised adaptation
Oct 21, 2019
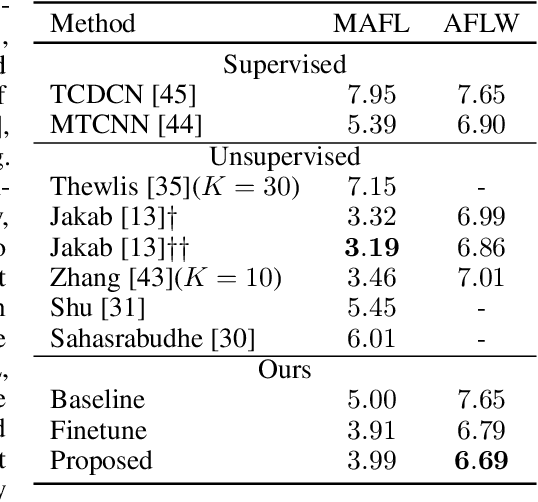
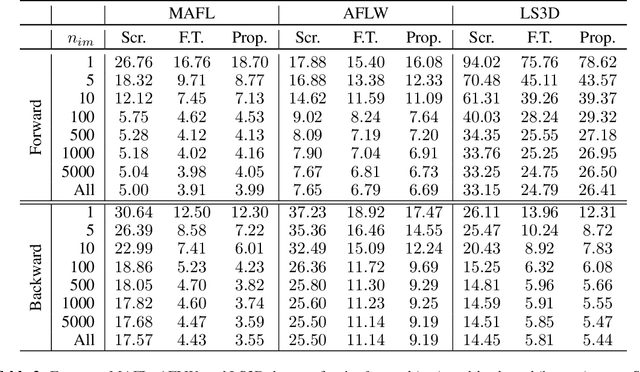

This paper proposes a method to ease the unsupervised learning of object landmark detectors. Similarly to previous methods, our approach is fully unsupervised in a sense that it does not require or make any use of annotated landmarks for the target object category. Contrary to previous works, we do however assume that a landmark detector, which has already learned a structured representation for a given object category in a fully supervised manner, is available. Under this setting, our main idea boils down to adapting the given pre-trained network to the target object categories in a fully unsupervised manner. To this end, our method uses the pre-trained network as a core which remains frozen and does not get updated during training, and learns, in an unsupervised manner, only a projection matrix to perform the adaptation to the target categories. By building upon an existing structured representation learned in a supervised manner, the optimization problem solved by our method is much more constrained with significantly less parameters to learn which seems to be important for the case of unsupervised learning. We show that our method surpasses fully unsupervised techniques trained from scratch as well as a strong baseline based on fine-tuning, and produces state-of-the-art results on several datasets. Code can be found at https://github.com/ESanchezLozano/SAIC-Unsupervised-landmark-detection-NeurIPS2019 .
XNOR-Net++: Improved Binary Neural Networks
Sep 30, 2019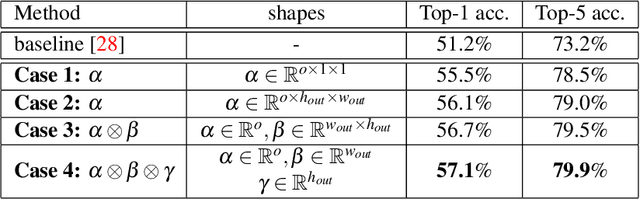
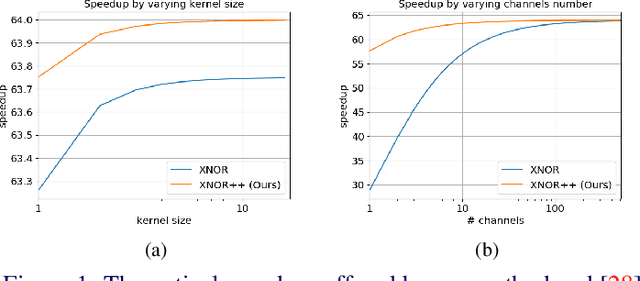
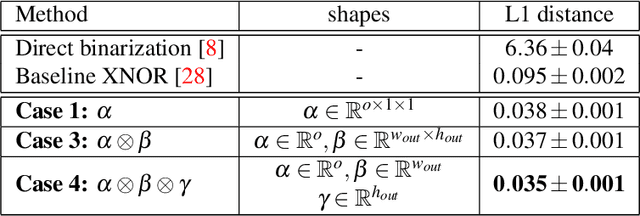
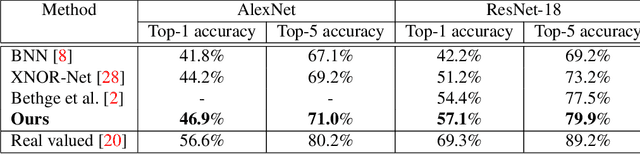
This paper proposes an improved training algorithm for binary neural networks in which both weights and activations are binary numbers. A key but fairly overlooked feature of the current state-of-the-art method of XNOR-Net is the use of analytically calculated real-valued scaling factors for re-weighting the output of binary convolutions. We argue that analytic calculation of these factors is sub-optimal. Instead, in this work, we make the following contributions: (a) we propose to fuse the activation and weight scaling factors into a single one that is learned discriminatively via backpropagation. (b) More importantly, we explore several ways of constructing the shape of the scale factors while keeping the computational budget fixed. (c) We empirically measure the accuracy of our approximations and show that they are significantly more accurate than the analytically calculated one. (d) We show that our approach significantly outperforms XNOR-Net within the same computational budget when tested on the challenging task of ImageNet classification, offering up to 6\% accuracy gain.
AnimalWeb: A Large-Scale Hierarchical Dataset of Annotated Animal Faces
Sep 11, 2019
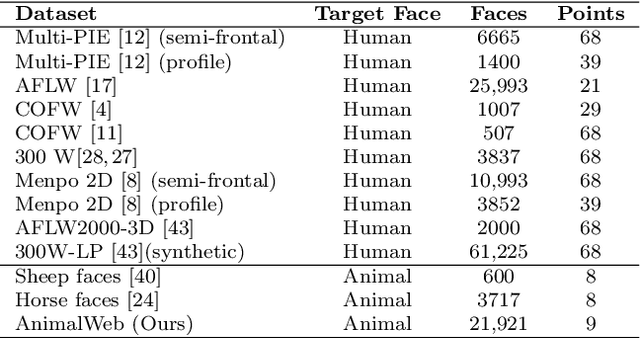

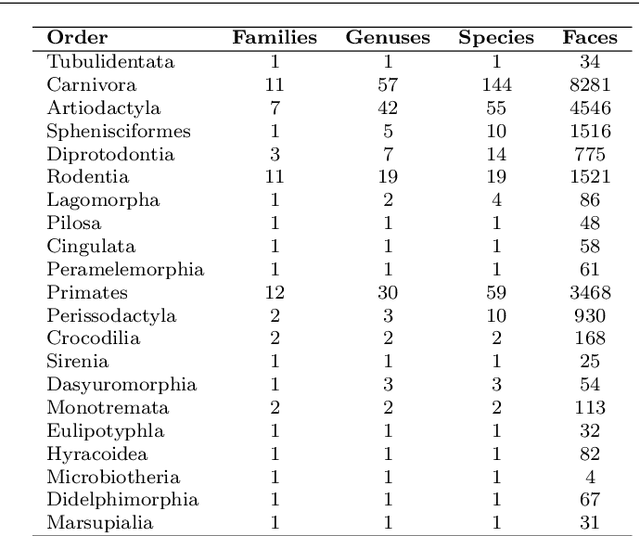
Being heavily reliant on animals, it is our ethical obligation to improve their well-being by understanding their needs. Several studies show that animal needs are often expressed through their faces. Though remarkable progress has been made towards the automatic understanding of human faces, this has regrettably not been the case with animal faces. There exists significant room and appropriate need to develop automatic systems capable of interpreting animal faces. Among many transformative impacts, such a technology will foster better and cheaper animal healthcare, and further advance animal psychology understanding. We believe the underlying research progress is mainly obstructed by the lack of an adequately annotated dataset of animal faces, covering a wide spectrum of animal species. To this end, we introduce a large-scale, hierarchical annotated dataset of animal faces, featuring 21.9K faces from 334 diverse species and 21 animal orders across biological taxonomy. These faces are captured `in-the-wild' conditions and are consistently annotated with 9 landmarks on key facial features. The proposed dataset is structured and scalable by design; its development underwent four systematic stages involving rigorous, manual annotation effort of over 6K man-hours. We benchmark it for face alignment using the existing art under novel problem settings. Results showcase its challenging nature, unique attributes and present definite prospects for novel, adaptive, and generalized face-oriented CV algorithms. We further benchmark the dataset for face detection and fine-grained recognition tasks, to demonstrate multi-task applications and room for improvement. Experiments indicate that this dataset will push the algorithmic advancements across many related CV tasks and encourage the development of novel systems for animal facial behaviour monitoring. We will make the dataset publicly available.