 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Feature-based Online Multi-kernel Learning in Environments with Unknown Dynamics
Jan 17, 2018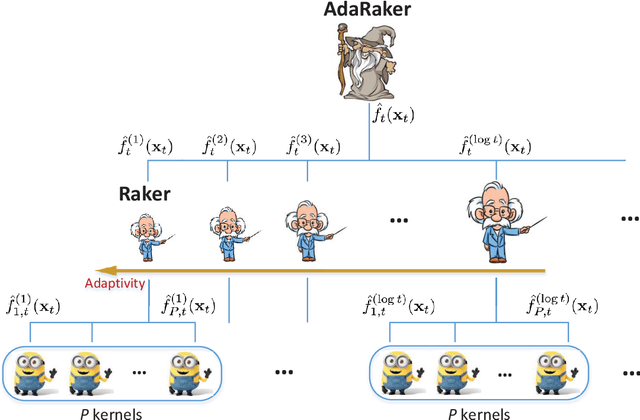

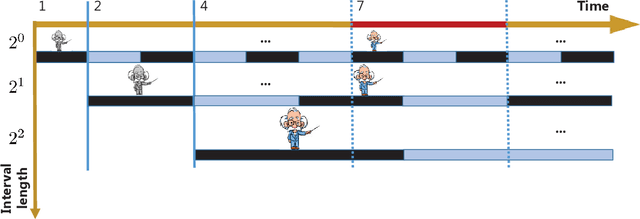
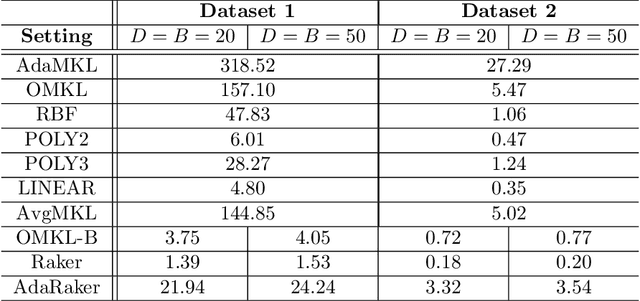
Kernel-based methods exhibit well-documented performance in various nonlinear learning tasks. Most of them rely on a preselected kernel, whose prudent choice presumes task-specific prior information. Especially when the latter is not available, multi-kernel learning has gained popularity thanks to its flexibility in choosing kernels from a prescribed kernel dictionary. Leveraging the random feature approximation and its recent orthogonality-promoting variant, the present contribution develops a scalable multi-kernel learning scheme (termed Raker) to obtain the sought nonlinear learning function `on the fly,' first for static environments. To further boost performance in dynamic environments, an adaptive multi-kernel learning scheme (termed AdaRaker) is developed using weighted combinations of advices from hierarchical ensembles of experts. The weights account not only for each kernel's contribution to the learning, but also for the unknown dynamics. Performance is analyzed in terms of both static and dynamic regrets. AdaRaker is uniquely capable of tracking nonlinear learning functions in environments with unknown dynamics, with analytic performance guarantees. Tests with synthetic and real datasets are carried out to showcase the effectiveness of the novel algorithms, and their performance.
Data-adaptive Active Sampling for Efficient Graph-Cognizant Classification
Dec 26, 2017
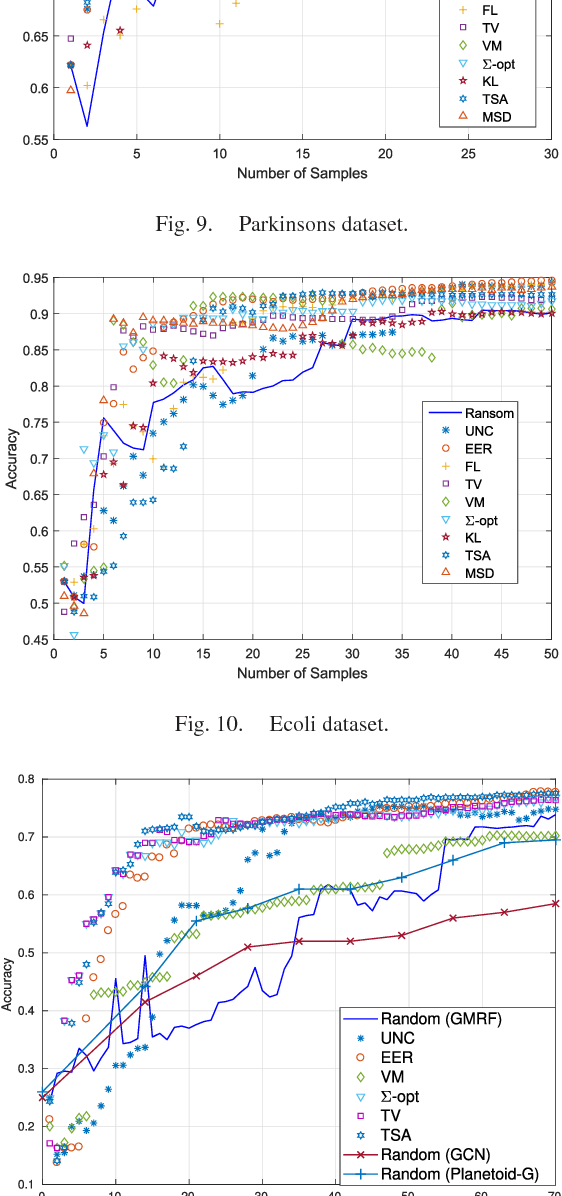
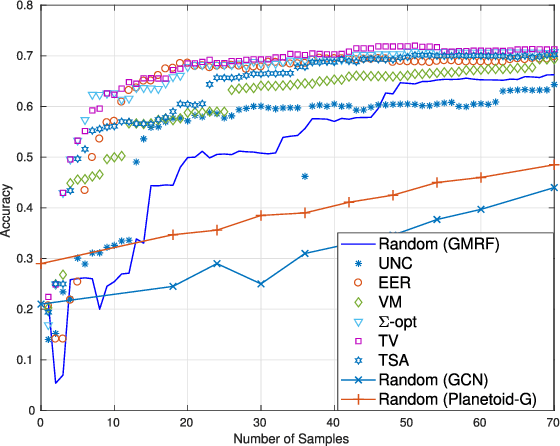
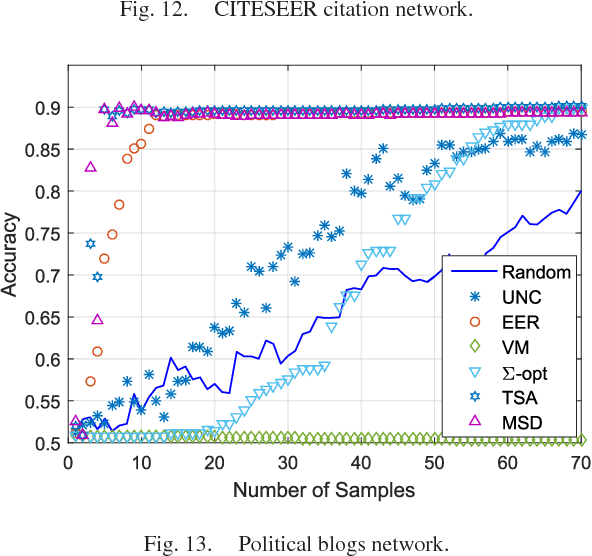
The present work deals with active sampling of graph nodes representing training data for binary classification. The graph may be given or constructed using similarity measures among nodal features. Leveraging the graph for classification builds on the premise that labels across neighboring nodes are correlated according to a categorical Markov random field (MRF). This model is further relaxed to a Gaussian (G)MRF with labels taking continuous values - an approximation that not only mitigates the combinatorial complexity of the categorical model, but also offers optimal unbiased soft predictors of the unlabeled nodes. The proposed sampling strategy is based on querying the node whose label disclosure is expected to inflict the largest change on the GMRF, and in this sense it is the most informative on average. Such a strategy subsumes several measures of expected model change, including uncertainty sampling, variance minimization, and sampling based on the $\Sigma-$optimality criterion. A simple yet effective heuristic is also introduced for increasing the exploration capabilities of the sampler, and reducing bias of the resultant classifier, by taking into account the confidence on the model label predictions. The novel sampling strategies are based on quantities that are readily available without the need for model retraining, rendering them computationally efficient and scalable to large graphs. Numerical tests using synthetic and real data demonstrate that the proposed methods achieve accuracy that is comparable or superior to the state-of-the-art even at reduced runtime.
Large-scale Kernel-based Feature Extraction via Budgeted Nonlinear Subspace Tracking
Dec 26, 2017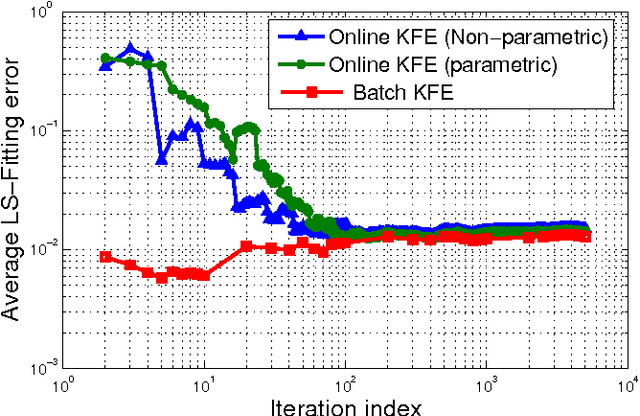
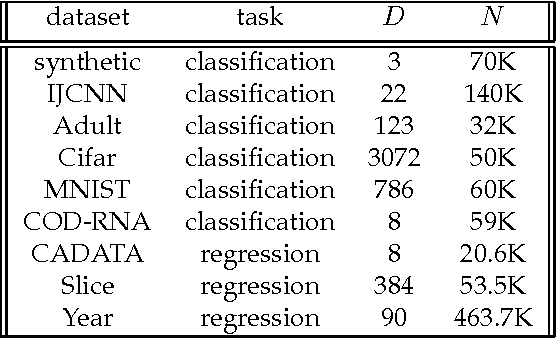
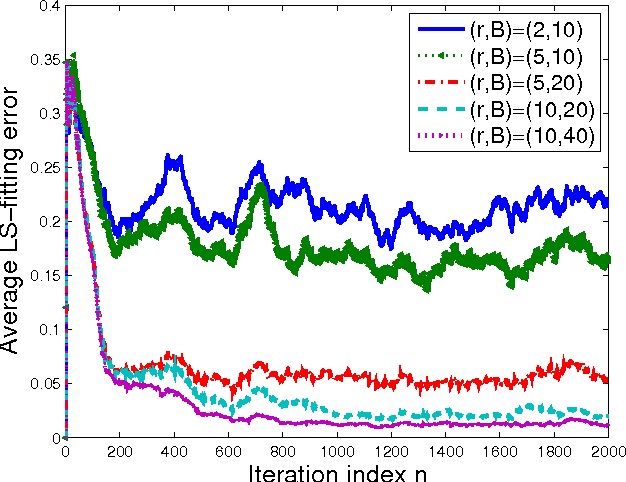
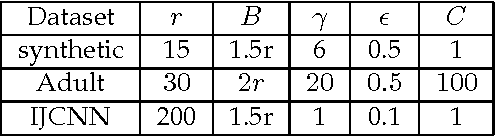
Kernel-based methods enjoy powerful generalization capabilities in handling a variety of learning tasks. When such methods are provided with sufficient training data, broadly-applicable classes of nonlinear functions can be approximated with desired accuracy. Nevertheless, inherent to the nonparametric nature of kernel-based estimators are computational and memory requirements that become prohibitive with large-scale datasets. In response to this formidable challenge, the present work puts forward a low-rank, kernel-based, feature extraction approach that is particularly tailored for online operation, where data streams need not be stored in memory. A novel generative model is introduced to approximate high-dimensional (possibly infinite) features via a low-rank nonlinear subspace, the learning of which leads to a direct kernel function approximation. Offline and online solvers are developed for the subspace learning task, along with affordable versions, in which the number of stored data vectors is confined to a predefined budget. Analytical results provide performance bounds on how well the kernel matrix as well as kernel-based classification and regression tasks can be approximated by leveraging budgeted online subspace learning and feature extraction schemes. Tests on synthetic and real datasets demonstrate and benchmark the efficiency of the proposed method when linear classification and regression is applied to the extracted features.
Inference of Spatio-Temporal Functions over Graphs via Multi-Kernel Kriged Kalman Filtering
Nov 25, 2017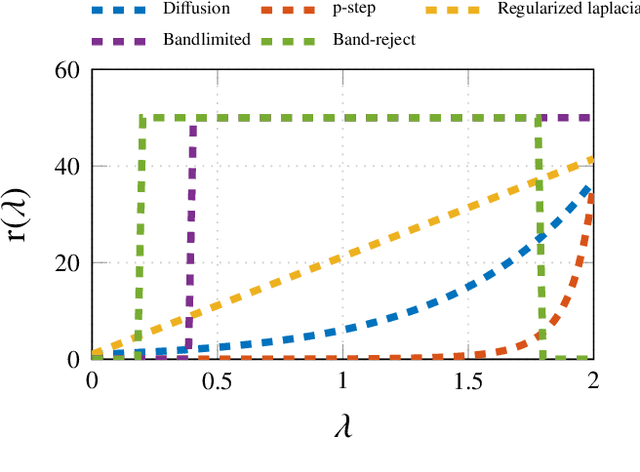
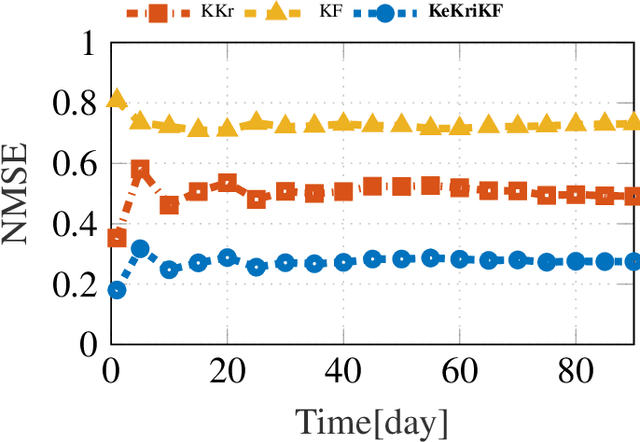
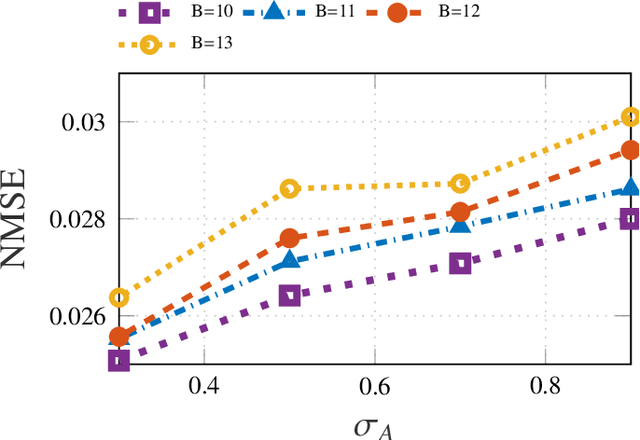
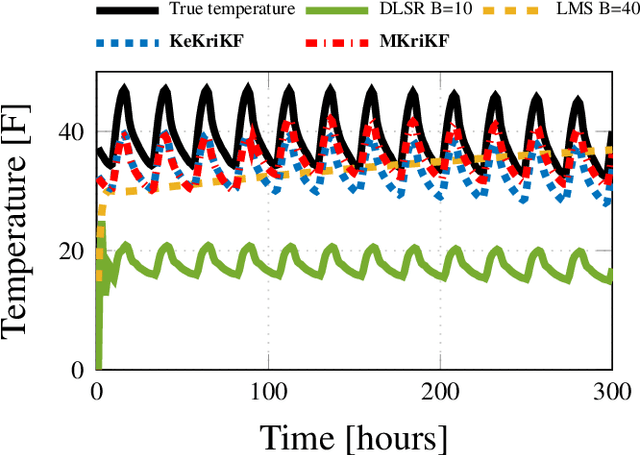
Inference of space-time varying signals on graphs emerges naturally in a plethora of network science related applications. A frequently encountered challenge pertains to reconstructing such dynamic processes, given their values over a subset of vertices and time instants. The present paper develops a graph-aware kernel-based kriged Kalman filter that accounts for the spatio-temporal variations, and offers efficient online reconstruction, even for dynamically evolving network topologies. The kernel-based learning framework bypasses the need for statistical information by capitalizing on the smoothness that graph signals exhibit with respect to the underlying graph. To address the challenge of selecting the appropriate kernel, the proposed filter is combined with a multi-kernel selection module. Such a data-driven method selects a kernel attuned to the signal dynamics on-the-fly within the linear span of a pre-selected dictionary. The novel multi-kernel learning algorithm exploits the eigenstructure of Laplacian kernel matrices to reduce computational complexity. Numerical tests with synthetic and real data demonstrate the superior reconstruction performance of the novel approach relative to state-of-the-art alternatives.
DPCA: Dimensionality Reduction for Discriminative Analytics of Multiple Large-Scale Datasets
Oct 25, 2017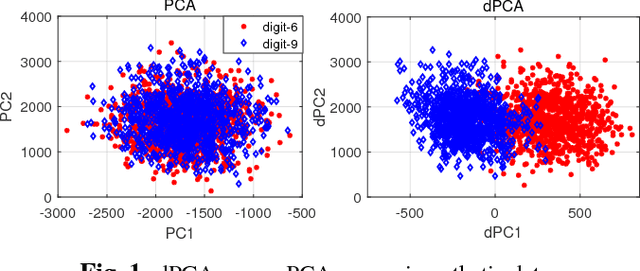
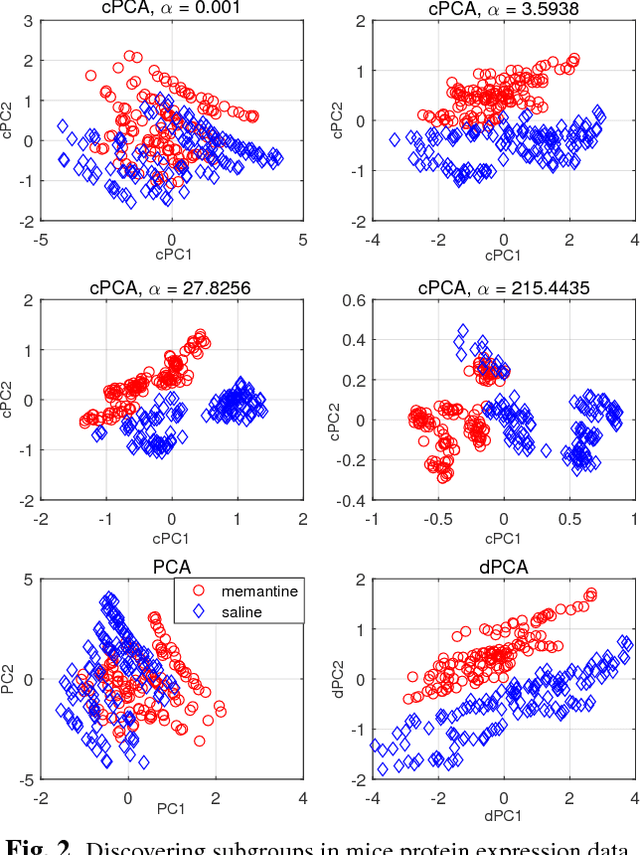
Principal component analysis (PCA) has well-documented merits for data extraction and dimensionality reduction. PCA deals with a single dataset at a time, and it is challenged when it comes to analyzing multiple datasets. Yet in certain setups, one wishes to extract the most significant information of one dataset relative to other datasets. Specifically, the interest may be on identifying, namely extracting features that are specific to a single target dataset but not the others. This paper develops a novel approach for such so-termed discriminative data analysis, and establishes its optimality in the least-squares (LS) sense under suitable data modeling assumptions. The criterion reveals linear combinations of variables by maximizing the ratio of the variance of the target data to that of the remainders. The novel approach solves a generalized eigenvalue problem by performing SVD just once. Numerical tests using synthetic and real datasets showcase the merits of the proposed approach relative to its competing alternatives.
Randomized Block Frank-Wolfe for Convergent Large-Scale Learning
Sep 22, 2017
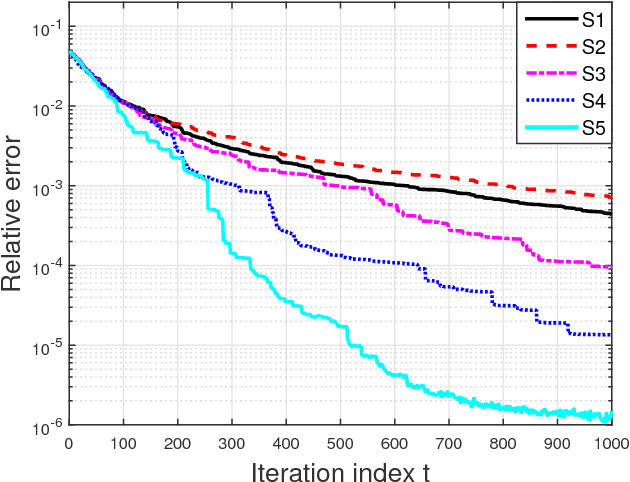
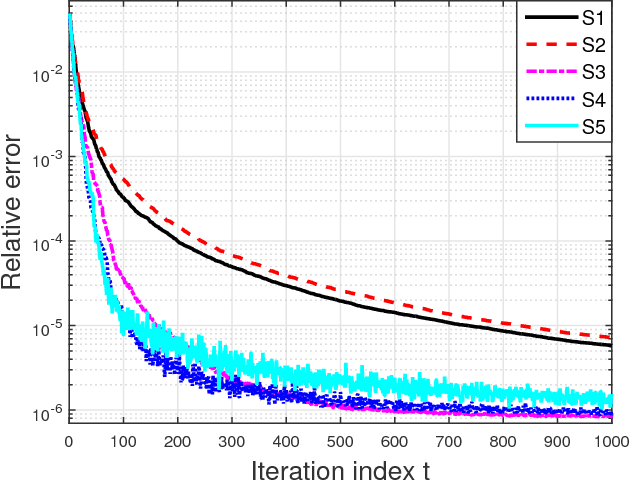
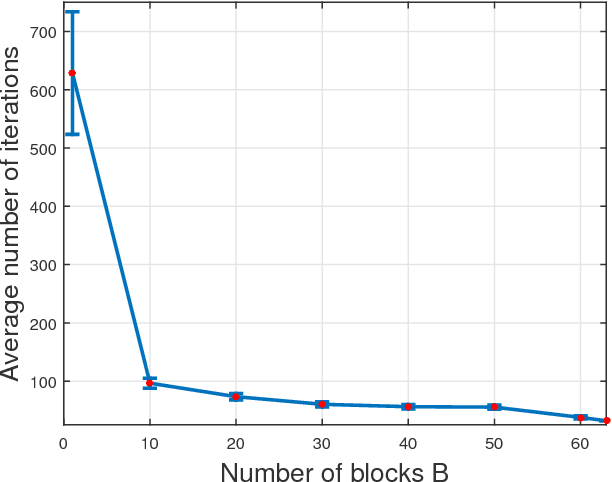
Owing to their low-complexity iterations, Frank-Wolfe (FW) solvers are well suited for various large-scale learning tasks. When block-separable constraints are present, randomized block FW (RB-FW) has been shown to further reduce complexity by updating only a fraction of coordinate blocks per iteration. To circumvent the limitations of existing methods, the present work develops step sizes for RB-FW that enable a flexible selection of the number of blocks to update per iteration while ensuring convergence and feasibility of the iterates. To this end, convergence rates of RB-FW are established through computational bounds on a primal sub-optimality measure and on the duality gap. The novel bounds extend the existing convergence analysis, which only applies to a step-size sequence that does not generally lead to feasible iterates. Furthermore, two classes of step-size sequences that guarantee feasibility of the iterates are also proposed to enhance flexibility in choosing decay rates. The novel convergence results are markedly broadened to encompass also nonconvex objectives, and further assert that RB-FW with exact line-search reaches a stationary point at rate $\mathcal{O}(1/\sqrt{t})$. Performance of RB-FW with different step sizes and number of blocks is demonstrated in two applications, namely charging of electrical vehicles and structural support vector machines. Extensive simulated tests demonstrate the performance improvement of RB-FW relative to existing randomized single-block FW methods.
Solving Systems of Random Quadratic Equations via Truncated Amplitude Flow
Aug 20, 2017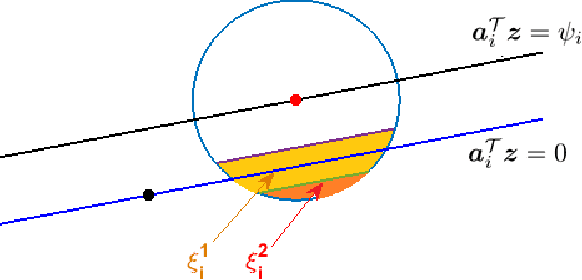
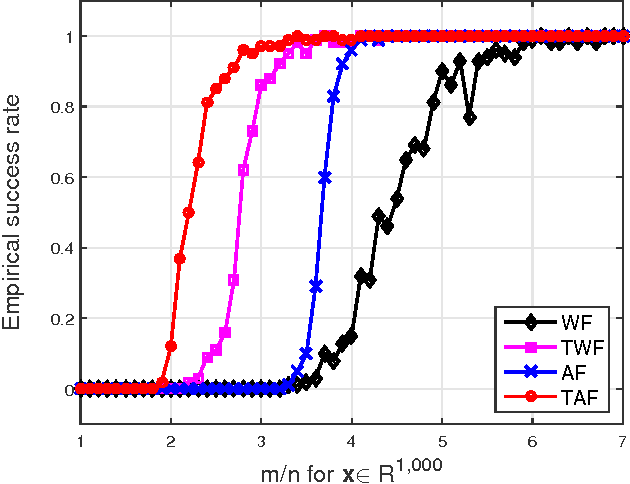
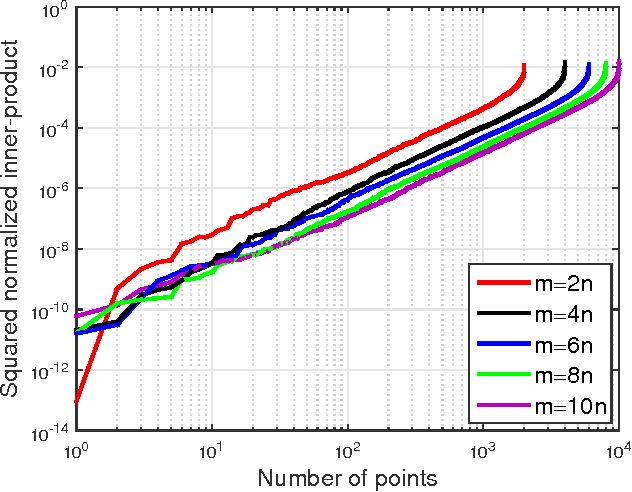
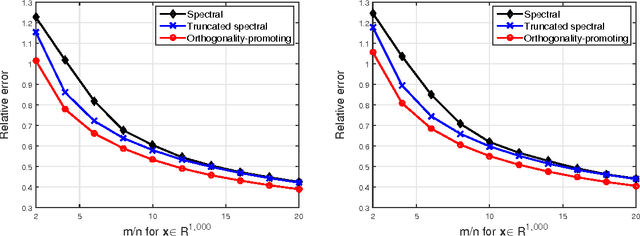
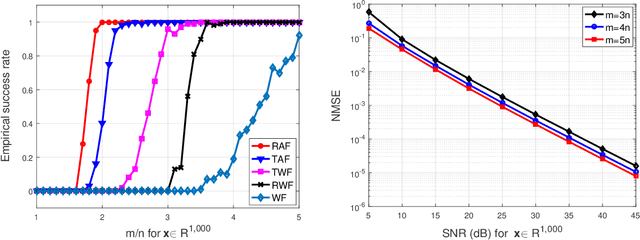
This paper presents a new algorithm, termed \emph{truncated amplitude flow} (TAF), to recover an unknown vector $\bm{x}$ from a system of quadratic equations of the form $y_i=|\langle\bm{a}_i,\bm{x}\rangle|^2$, where $\bm{a}_i$'s are given random measurement vectors. This problem is known to be \emph{NP-hard} in general. We prove that as soon as the number of equations is on the order of the number of unknowns, TAF recovers the solution exactly (up to a global unimodular constant) with high probability and complexity growing linearly with both the number of unknowns and the number of equations. Our TAF approach adopts the \emph{amplitude-based} empirical loss function, and proceeds in two stages. In the first stage, we introduce an \emph{orthogonality-promoting} initialization that can be obtained with a few power iterations. Stage two refines the initial estimate by successive updates of scalable \emph{truncated generalized gradient iterations}, which are able to handle the rather challenging nonconvex and nonsmooth amplitude-based objective function. In particular, when vectors $\bm{x}$ and $\bm{a}_i$'s are real-valued, our gradient truncation rule provably eliminates erroneously estimated signs with high probability to markedly improve upon its untruncated version. Numerical tests using synthetic data and real images demonstrate that our initialization returns more accurate and robust estimates relative to spectral initializations. Furthermore, even under the same initialization, the proposed amplitude-based refinement outperforms existing Wirtinger flow variants, corroborating the superior performance of TAF over state-of-the-art algorithms.
Bandit Convex Optimization for Scalable and Dynamic IoT Management
Jul 27, 2017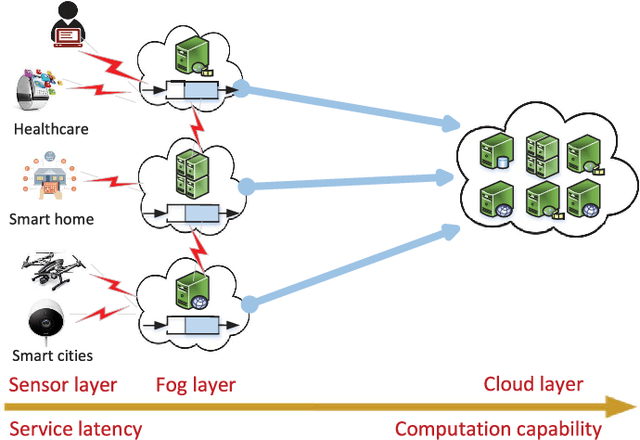
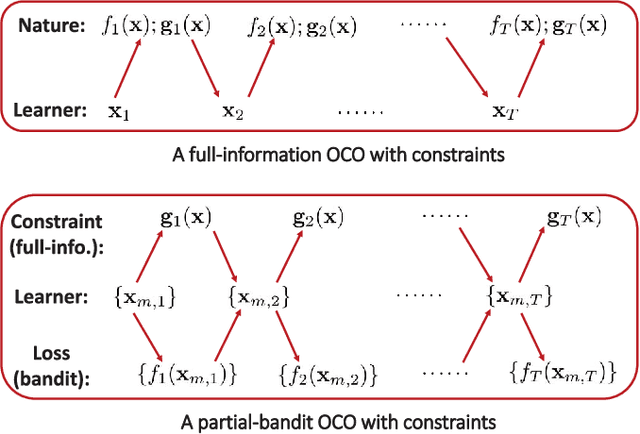
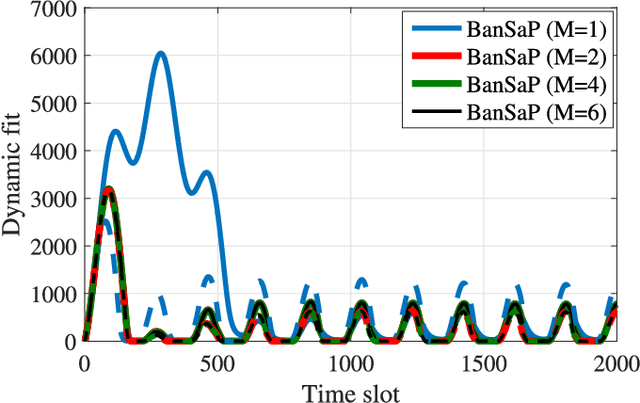
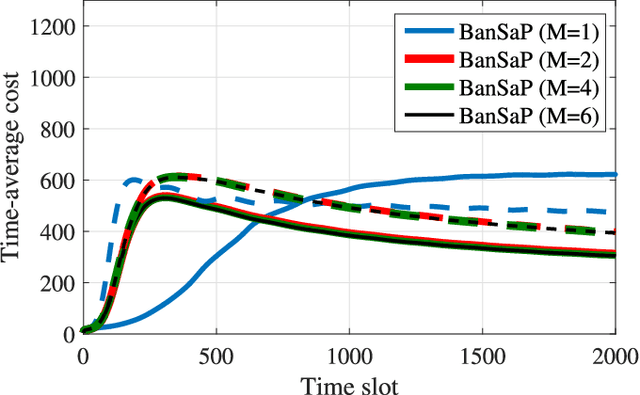
The present paper deals with online convex optimization involving both time-varying loss functions, and time-varying constraints. The loss functions are not fully accessible to the learner, and instead only the function values (a.k.a. bandit feedback) are revealed at queried points. The constraints are revealed after making decisions, and can be instantaneously violated, yet they must be satisfied in the long term. This setting fits nicely the emerging online network tasks such as fog computing in the Internet-of-Things (IoT), where online decisions must flexibly adapt to the changing user preferences (loss functions), and the temporally unpredictable availability of resources (constraints). Tailored for such human-in-the-loop systems where the loss functions are hard to model, a family of bandit online saddle-point (BanSaP) schemes are developed, which adaptively adjust the online operations based on (possibly multiple) bandit feedback of the loss functions, and the changing environment. Performance here is assessed by: i) dynamic regret that generalizes the widely used static regret; and, ii) fit that captures the accumulated amount of constraint violations. Specifically, BanSaP is proved to simultaneously yield sub-linear dynamic regret and fit, provided that the best dynamic solutions vary slowly over time. Numerical tests in fog computation offloading tasks corroborate that our proposed BanSaP approach offers competitive performance relative to existing approaches that are based on gradient feedback.
Solving Almost all Systems of Random Quadratic Equations
May 29, 2017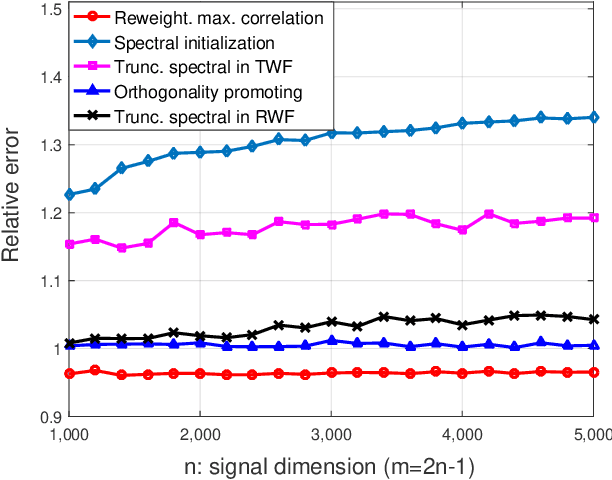
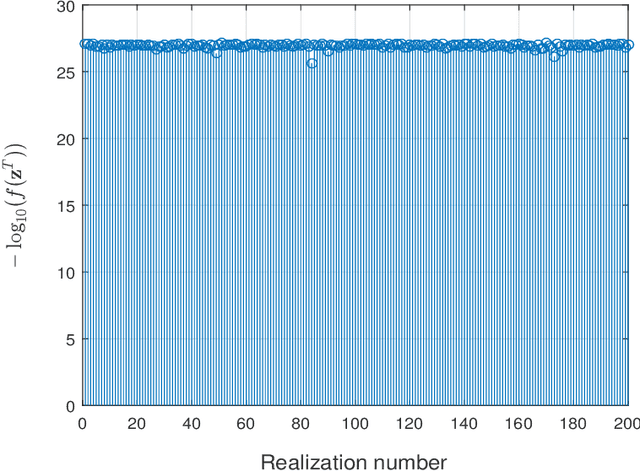

This paper deals with finding an $n$-dimensional solution $x$ to a system of quadratic equations of the form $y_i=|\langle{a}_i,x\rangle|^2$ for $1\le i \le m$, which is also known as phase retrieval and is NP-hard in general. We put forth a novel procedure for minimizing the amplitude-based least-squares empirical loss, that starts with a weighted maximal correlation initialization obtainable with a few power or Lanczos iterations, followed by successive refinements based upon a sequence of iteratively reweighted (generalized) gradient iterations. The two (both the initialization and gradient flow) stages distinguish themselves from prior contributions by the inclusion of a fresh (re)weighting regularization technique. The overall algorithm is conceptually simple, numerically scalable, and easy-to-implement. For certain random measurement models, the novel procedure is shown capable of finding the true solution $x$ in time proportional to reading the data $\{(a_i;y_i)\}_{1\le i \le m}$. This holds with high probability and without extra assumption on the signal $x$ to be recovered, provided that the number $m$ of equations is some constant $c>0$ times the number $n$ of unknowns in the signal vector, namely, $m>cn$. Empirically, the upshots of this contribution are: i) (almost) $100\%$ perfect signal recovery in the high-dimensional (say e.g., $n\ge 2,000$) regime given only an information-theoretic limit number of noiseless equations, namely, $m=2n-1$ in the real-valued Gaussian case; and, ii) (nearly) optimal statistical accuracy in the presence of additive noise of bounded support. Finally, substantial numerical tests using both synthetic data and real images corroborate markedly improved signal recovery performance and computational efficiency of our novel procedure relative to state-of-the-art approaches.
Kernel-based Reconstruction of Space-time Functions on Dynamic Graphs
May 20, 2017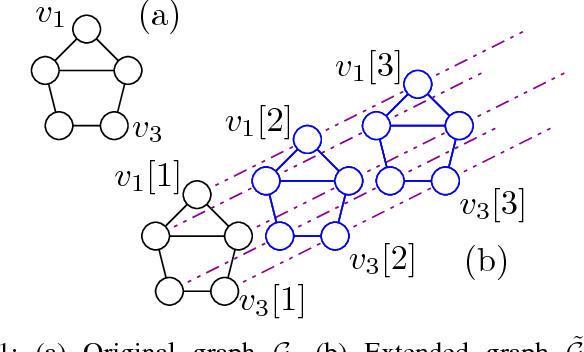
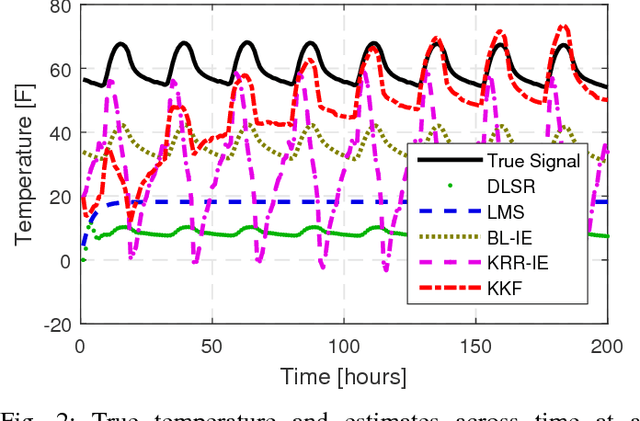
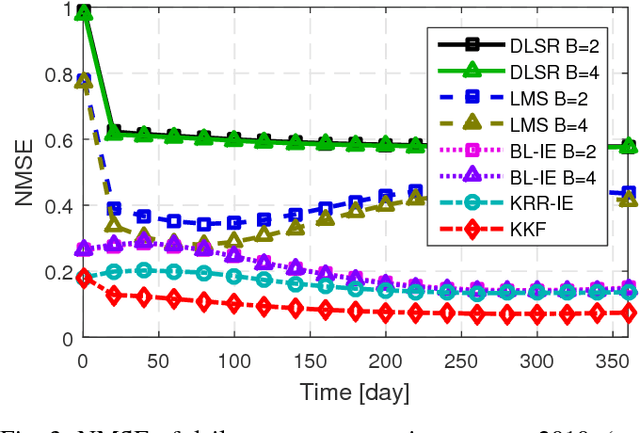
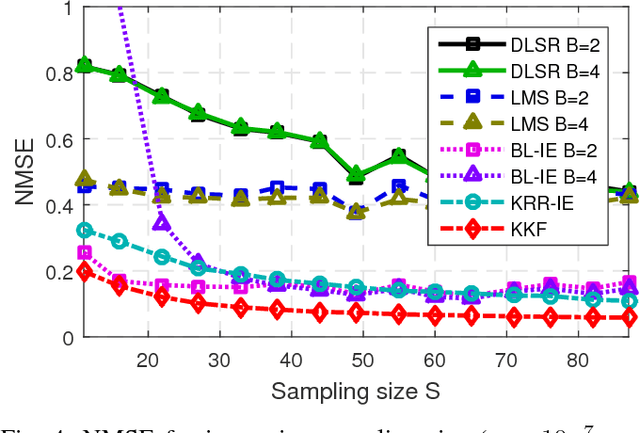
Graph-based methods pervade the inference toolkits of numerous disciplines including sociology, biology, neuroscience, physics, chemistry, and engineering. A challenging problem encountered in this context pertains to determining the attributes of a set of vertices given those of another subset at possibly different time instants. Leveraging spatiotemporal dynamics can drastically reduce the number of observed vertices, and hence the cost of sampling. Alleviating the limited flexibility of existing approaches, the present paper broadens the existing kernel-based graph function reconstruction framework to accommodate time-evolving functions over possibly time-evolving topologies. This approach inherits the versatility and generality of kernel-based methods, for which no knowledge on distributions or second-order statistics is required. Systematic guidelines are provided to construct two families of space-time kernels with complementary strengths. The first facilitates judicious control of regularization on a space-time frequency plane, whereas the second can afford time-varying topologies. Batch and online estimators are also put forth, and a novel kernel Kalman filter is developed to obtain these estimates at affordable computational cost. Numerical tests with real data sets corroborate the merits of the proposed methods relative to competing alternatives.