 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRI-derived quantification of hepatic vessel-to-volume ratios in chronic liver disease using a deep learning approach
Oct 09, 2025Background: We aimed to quantify hepatic vessel volumes across chronic liver disease stages and healthy controls using deep learning-based magnetic resonance imaging (MRI) analysis, and assess correlations with biomarkers for liver (dys)function and fibrosis/portal hypertension. Methods: We assessed retrospectively healthy controls, non-advanced and advanced chronic liver disease (ACLD) patients using a 3D U-Net model for hepatic vessel segmentation on portal venous phase gadoxetic acid-enhanced 3-T MRI. Total (TVVR), hepatic (HVVR), and intrahepatic portal vein-to-volume ratios (PVVR) were compared between groups and correlated with: albumin-bilirubin (ALBI) and model for end-stage liver disease-sodium (MELD-Na) score, and fibrosis/portal hypertension (Fibrosis-4 [FIB-4] score, liver stiffness measurement [LSM], hepatic venous pressure gradient [HVPG], platelet count [PLT], and spleen volume). Results: We included 197 subjects, aged 54.9 $\pm$ 13.8 years (mean $\pm$ standard deviation), 111 males (56.3\%): 35 healthy controls, 44 non-ACLD, and 118 ACLD patients. TVVR and HVVR were highest in controls (3.9; 2.1), intermediate in non-ACLD (2.8; 1.7), and lowest in ACLD patients (2.3; 1.0) ($p \leq 0.001$). PVVR was reduced in both non-ACLD and ACLD patients (both 1.2) compared to controls (1.7) ($p \leq 0.001$), but showed no difference between CLD groups ($p = 0.999$). HVVR significantly correlated indirectly with FIB-4, ALBI, MELD-Na, LSM, and spleen volume ($\rho$ ranging from -0.27 to -0.40), and directly with PLT ($\rho = 0.36$). TVVR and PVVR showed similar but weaker correlations. Conclusions: Deep learning-based hepatic vessel volumetry demonstrated differences between healthy liver and chronic liver disease stages and shows correlations with established markers of disease severity.
Temporal Representation Learning of Phenotype Trajectories for pCR Prediction in Breast Cancer
Sep 18, 2025Effective therapy decisions require models that predict the individual response to treatment. This is challenging since the progression of disease and response to treatment vary substantially across patients. Here, we propose to learn a representation of the early dynamics of treatment response from imaging data to predict pathological complete response (pCR) in breast cancer patients undergoing neoadjuvant chemotherapy (NACT). The longitudinal change in magnetic resonance imaging (MRI) data of the breast forms trajectories in the latent space, serving as basis for prediction of successful response. The multi-task model represents appearance, fosters temporal continuity and accounts for the comparably high heterogeneity in the non-responder cohort.In experiments on the publicly available ISPY-2 dataset, a linear classifier in the latent trajectory space achieves a balanced accuracy of 0.761 using only pre-treatment data (T0), 0.811 using early response (T0 + T1), and 0.861 using four imaging time points (T0 -> T3). The code will be made available upon paper acceptance.
AREPAS: Anomaly Detection in Fine-Grained Anatomy with Reconstruction-Based Semantic Patch-Scoring
Sep 16, 2025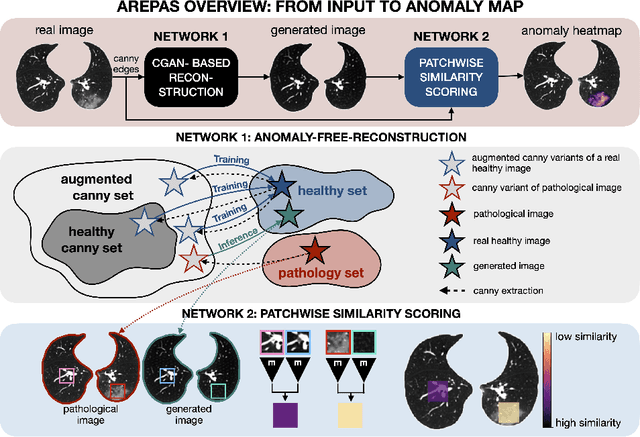
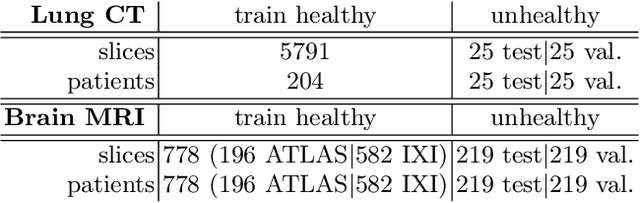
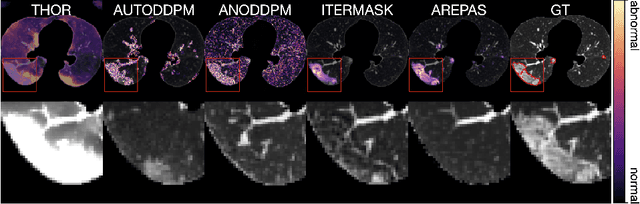
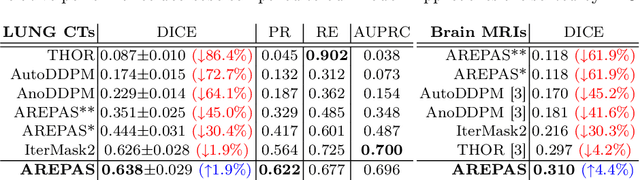
Early detection of newly emerging diseases, lesion severity assessment, differentiation of medical conditions and automated screening are examples for the wide applicability and importance of anomaly detection (AD) and unsupervised segmentation in medicine. Normal fine-grained tissue variability such as present in pulmonary anatomy is a major challenge for existing generative AD methods. Here, we propose a novel generative AD approach addressing this issue. It consists of an image-to-image translation for anomaly-free reconstruction and a subsequent patch similarity scoring between observed and generated image-pairs for precise anomaly localization. We validate the new method on chest computed tomography (CT) scans for the detection and segmentation of infectious disease lesions. To assess generalizability, we evaluate the method on an ischemic stroke lesion segmentation task in T1-weighted brain MRI. Results show improved pixel-level anomaly segmentation in both chest CTs and brain MRIs, with relative DICE score improvements of +1.9% and +4.4%, respectively, compared to other state-of-the-art reconstruction-based methods.
Improving Vessel Segmentation with Multi-Task Learning and Auxiliary Data Available Only During Model Training
Sep 04, 2025



Liver vessel segmentation in magnetic resonance imaging data is important for the computational analysis of vascular remodelling, associated with a wide spectrum of diffuse liver diseases. Existing approaches rely on contrast enhanced imaging data, but the necessary dedicated imaging sequences are not uniformly acquired. Images without contrast enhancement are acquired more frequently, but vessel segmentation is challenging, and requires large-scale annotated data. We propose a multi-task learning framework to segment vessels in liver MRI without contrast. It exploits auxiliary contrast enhanced MRI data available only during training to reduce the need for annotated training examples. Our approach draws on paired native and contrast enhanced data with and without vessel annotations for model training. Results show that auxiliary data improves the accuracy of vessel segmentation, even if they are not available during inference. The advantage is most pronounced if only few annotations are available for training, since the feature representation benefits from the shared task structure. A validation of this approach to augment a model for brain tumor segmentation confirms its benefits across different domains. An auxiliary informative imaging modality can augment expert annotations even if it is only available during training.
Conditional Fetal Brain Atlas Learning for Automatic Tissue Segmentation
Aug 06, 2025Magnetic Resonance Imaging (MRI) of the fetal brain has become a key tool for studying brain development in vivo. Yet, its assessment remains challenging due to variability in brain maturation, imaging protocols, and uncertain estimates of Gestational Age (GA). To overcome these, brain atlases provide a standardized reference framework that facilitates objective evaluation and comparison across subjects by aligning the atlas and subjects in a common coordinate system. In this work, we introduce a novel deep-learning framework for generating continuous, age-specific fetal brain atlases for real-time fetal brain tissue segmentation. The framework combines a direct registration model with a conditional discriminator. Trained on a curated dataset of 219 neurotypical fetal MRIs spanning from 21 to 37 weeks of gestation. The method achieves high registration accuracy, captures dynamic anatomical changes with sharp structural detail, and robust segmentation performance with an average Dice Similarity Coefficient (DSC) of 86.3% across six brain tissues. Furthermore, volumetric analysis of the generated atlases reveals detailed neurotypical growth trajectories, providing valuable insights into the maturation of the fetal brain. This approach enables individualized developmental assessment with minimal pre-processing and real-time performance, supporting both research and clinical applications. The model code is available at https://github.com/cirmuw/fetal-brain-atlas
Identifying Signatures of Image Phenotypes to Track Treatment Response in Liver Disease
Jul 16, 2025



Quantifiable image patterns associated with disease progression and treatment response are critical tools for guiding individual treatment, and for developing novel therapies. Here, we show that unsupervised machine learning can identify a pattern vocabulary of liver tissue in magnetic resonance images that quantifies treatment response in diffuse liver disease. Deep clustering networks simultaneously encode and cluster patches of medical images into a low-dimensional latent space to establish a tissue vocabulary. The resulting tissue types capture differential tissue change and its location in the liver associated with treatment response. We demonstrate the utility of the vocabulary on a randomized controlled trial cohort of non-alcoholic steatohepatitis patients. First, we use the vocabulary to compare longitudinal liver change in a placebo and a treatment cohort. Results show that the method identifies specific liver tissue change pathways associated with treatment, and enables a better separation between treatment groups than established non-imaging measures. Moreover, we show that the vocabulary can predict biopsy derived features from non-invasive imaging data. We validate the method on a separate replication cohort to demonstrate the applicability of the proposed method.
Towards contrast- and pathology-agnostic clinical fetal brain MRI segmentation using SynthSeg
Apr 14, 2025



Magnetic resonance imaging (MRI) has played a crucial role in fetal neurodevelopmental research. Structural annotations of MR images are an important step for quantitative analysis of the developing human brain, with Deep learning providing an automated alternative for this otherwise tedious manual process. However, segmentation performances of Convolutional Neural Networks often suffer from domain shift, where the network fails when applied to subjects that deviate from the distribution with which it is trained on. In this work, we aim to train networks capable of automatically segmenting fetal brain MRIs with a wide range of domain shifts pertaining to differences in subject physiology and acquisition environments, in particular shape-based differences commonly observed in pathological cases. We introduce a novel data-driven train-time sampling strategy that seeks to fully exploit the diversity of a given training dataset to enhance the domain generalizability of the trained networks. We adapted our sampler, together with other existing data augmentation techniques, to the SynthSeg framework, a generator that utilizes domain randomization to generate diverse training data, and ran thorough experimentations and ablation studies on a wide range of training/testing data to test the validity of the approaches. Our networks achieved notable improvements in the segmentation quality on testing subjects with intense anatomical abnormalities (p < 1e-4), though at the cost of a slighter decrease in performance in cases with fewer abnormalities. Our work also lays the foundation for future works on creating and adapting data-driven sampling strategies for other training pipelines.
Detection of Emerging Infectious Diseases in Lung CT based on Spatial Anomaly Patterns
Oct 25, 2024Fast detection of emerging diseases is important for containing their spread and treating patients effectively. Local anomalies are relevant, but often novel diseases involve familiar disease patterns in new spatial distributions. Therefore, established local anomaly detection approaches may fail to identify them as new. Here, we present a novel approach to detect the emergence of new disease phenotypes exhibiting distinct patterns of the spatial distribution of lesions. We first identify anomalies in lung CT data, and then compare their distribution in a continually acquired new patient cohorts with historic patient population observed over a long prior period. We evaluate how accumulated evidence collected in the stream of patients is able to detect the onset of an emerging disease. In a gram-matrix based representation derived from the intermediate layers of a three-dimensional convolutional neural network, newly emerging clusters indicate emerging diseases.
Rigid Single-Slice-in-Volume registration via rotation-equivariant 2D/3D feature matching
Oct 24, 20242D to 3D registration is essential in tasks such as diagnosis, surgical navigation, environmental understanding, navigation in robotics, autonomous systems, or augmented reality. In medical imaging, the aim is often to place a 2D image in a 3D volumetric observation to w. Current approaches for rigid single slice in volume registration are limited by requirements such as pose initialization, stacks of adjacent slices, or reliable anatomical landmarks. Here, we propose a self-supervised 2D/3D registration approach to match a single 2D slice to the corresponding 3D volume. The method works in data without anatomical priors such as images of tumors. It addresses the dimensionality disparity and establishes correspondences between 2D in-plane and 3D out-of-plane rotation-equivariant features by using group equivariant CNNs. These rotation-equivariant features are extracted from the 2D query slice and aligned with their 3D counterparts. Results demonstrate the robustness of the proposed slice-in-volume registration on the NSCLC-Radiomics CT and KIRBY21 MRI datasets, attaining an absolute median angle error of less than 2 degrees and a mean-matching feature accuracy of 89% at a tolerance of 3 pixels.
WALINET: A water and lipid identification convolutional Neural Network for nuisance signal removal in 1H MR Spectroscopic Imaging
Oct 01, 2024



Purpose. Proton Magnetic Resonance Spectroscopic Imaging (1H-MRSI) provides non-invasive spectral-spatial mapping of metabolism. However, long-standing problems in whole-brain 1H-MRSI are spectral overlap of metabolite peaks with large lipid signal from scalp, and overwhelming water signal that distorts spectra. Fast and effective methods are needed for high-resolution 1H-MRSI to accurately remove lipid and water signals while preserving the metabolite signal. The potential of supervised neural networks for this task remains unexplored, despite their success for other MRSI processing. Methods. We introduce a deep-learning method based on a modified Y-NET network for water and lipid removal in whole-brain 1H-MRSI. The WALINET (WAter and LIpid neural NETwork) was compared to conventional methods such as the state-of-the-art lipid L2 regularization and Hankel-Lanczos singular value decomposition (HLSVD) water suppression. Methods were evaluated on simulated and in-vivo whole-brain MRSI using NMRSE, SNR, CRLB, and FWHM metrics. Results. WALINET is significantly faster and needs 8s for high-resolution whole-brain MRSI, compared to 42 minutes for conventional HLSVD+L2. Quantitative analysis shows WALINET has better performance than HLSVD+L2: 1) more lipid removal with 41% lower NRMSE, 2) better metabolite signal preservation with 71% lower NRMSE in simulated data, 155% higher SNR and 50% lower CRLB in in-vivo data. Metabolic maps obtained by WALINET in healthy subjects and patients show better gray/white-matter contrast with more visible structural details. Conclusions. WALINET has superior performance for nuisance signal removal and metabolite quantification on whole-brain 1H-MRSI compared to conventional state-of-the-art techniques. This represents a new application of deep-learning for MRSI processing, with potential for automated high-throughput workflow.