 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla
Jul 24, 2023



\emph{Circuit analysis} is a promising technique for understanding the internal mechanisms of language models. However, existing analyses are done in small models far from the state of the art. To address this, we present a case study of circuit analysis in the 70B Chinchilla model, aiming to test the scalability of circuit analysis. In particular, we study multiple-choice question answering, and investigate Chinchilla's capability to identify the correct answer \emph{label} given knowledge of the correct answer \emph{text}. We find that the existing techniques of logit attribution, attention pattern visualization, and activation patching naturally scale to Chinchilla, allowing us to identify and categorize a small set of `output nodes' (attention heads and MLPs). We further study the `correct letter' category of attention heads aiming to understand the semantics of their features, with mixed results. For normal multiple-choice question answers, we significantly compress the query, key and value subspaces of the head without loss of performance when operating on the answer labels for multiple-choice questions, and we show that the query and key subspaces represent an `Nth item in an enumeration' feature to at least some extent. However, when we attempt to use this explanation to understand the heads' behaviour on a more general distribution including randomized answer labels, we find that it is only a partial explanation, suggesting there is more to learn about the operation of `correct letter' heads on multiple choice question answering.
Accelerating Large Language Model Decoding with Speculative Sampling
Feb 02, 2023


We present speculative sampling, an algorithm for accelerating transformer decoding by enabling the generation of multiple tokens from each transformer call. Our algorithm relies on the observation that the latency of parallel scoring of short continuations, generated by a faster but less powerful draft model, is comparable to that of sampling a single token from the larger target model. This is combined with a novel modified rejection sampling scheme which preserves the distribution of the target model within hardware numerics. We benchmark speculative sampling with Chinchilla, a 70 billion parameter language model, achieving a 2-2.5x decoding speedup in a distributed setup, without compromising the sample quality or making modifications to the model itself.
Solving math word problems with process- and outcome-based feedback
Nov 25, 2022



Recent work has shown that asking language models to generate reasoning steps improves performance on many reasoning tasks. When moving beyond prompting, this raises the question of how we should supervise such models: outcome-based approaches which supervise the final result, or process-based approaches which supervise the reasoning process itself? Differences between these approaches might naturally be expected not just in final-answer errors but also in reasoning errors, which can be difficult to detect and are problematic in many real-world domains such as education. We run the first comprehensive comparison between process- and outcome-based approaches trained on a natural language task, GSM8K. We find that pure outcome-based supervision produces similar final-answer error rates with less label supervision. However, for correct reasoning steps we find it necessary to use process-based supervision or supervision from learned reward models that emulate process-based feedback. In total, we improve the previous best results from 16.8% $\to$ 12.7% final-answer error and 14.0% $\to$ 3.4% reasoning error among final-answer-correct solutions.
Fine-Tuning Language Models via Epistemic Neural Networks
Nov 03, 2022



Large language models are now part of a powerful new paradigm in machine learning. These models learn a wide range of capabilities from training on large unsupervised text corpora. In many applications, these capabilities are then fine-tuned through additional training on specialized data to improve performance in that setting. In this paper, we augment these models with an epinet: a small additional network architecture that helps to estimate model uncertainty and form an epistemic neural network (ENN). ENNs are neural networks that can know what they don't know. We show that, using an epinet to prioritize uncertain data, we can fine-tune BERT on GLUE tasks to the same performance while using 2x less data. We also investigate performance in synthetic neural network generative models designed to build understanding. In each setting, using an epinet outperforms heuristic active learning schemes.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022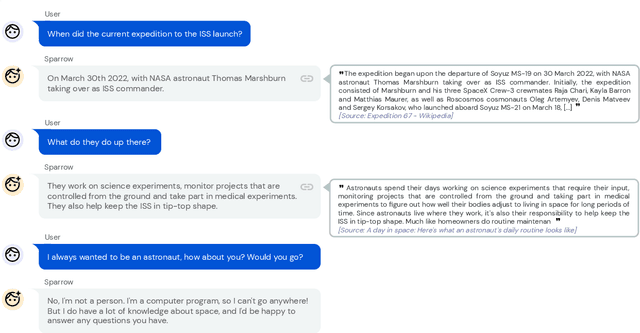

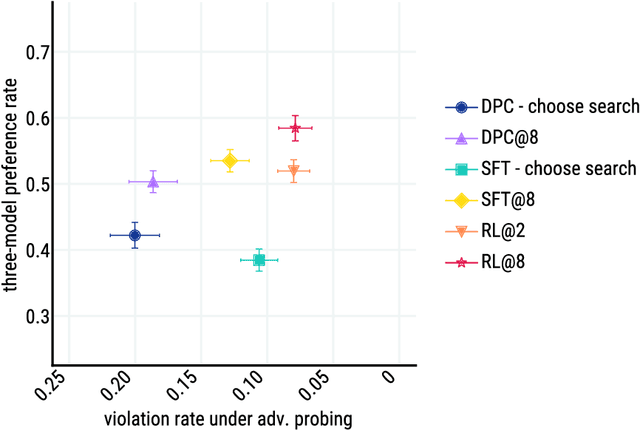
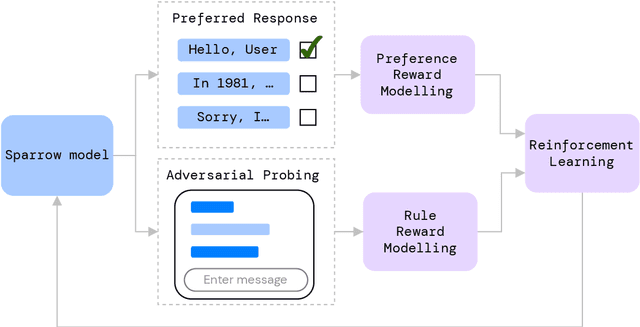
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Characteristics of Harmful Text: Towards Rigorous Benchmarking of Language Models
Jun 16, 2022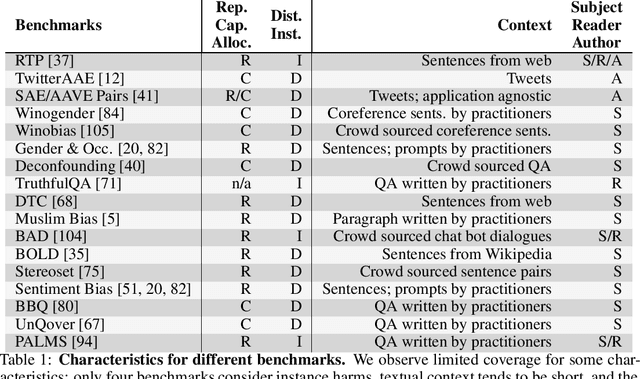
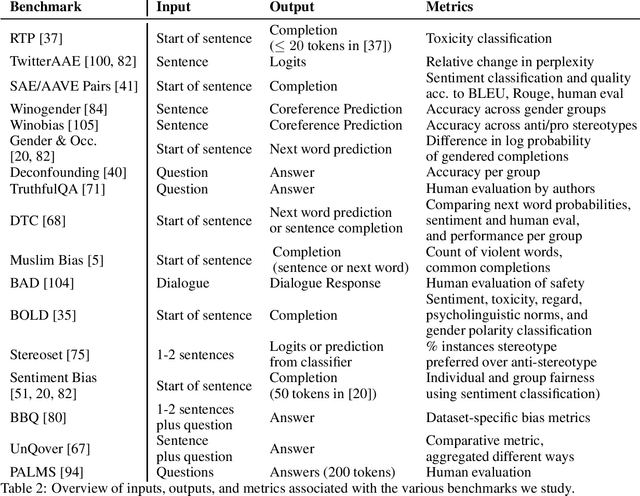
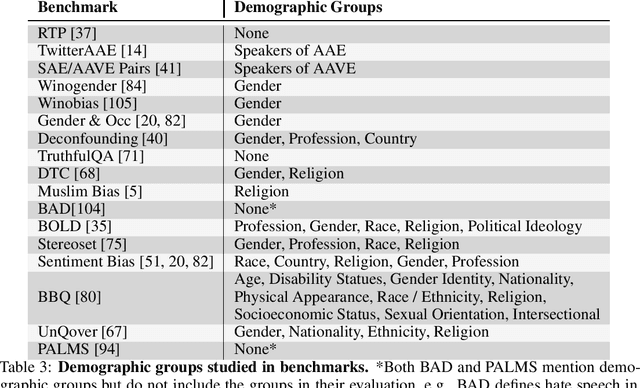
Large language models produce human-like text that drive a growing number of applications. However, recent literature and, increasingly, real world observations, have demonstrated that these models can generate language that is toxic, biased, untruthful or otherwise harmful. Though work to evaluate language model harms is under way, translating foresight about which harms may arise into rigorous benchmarks is not straightforward. To facilitate this translation, we outline six ways of characterizing harmful text which merit explicit consideration when designing new benchmarks. We then use these characteristics as a lens to identify trends and gaps in existing benchmarks. Finally, we apply them in a case study of the Perspective API, a toxicity classifier that is widely used in harm benchmarks. Our characteristics provide one piece of the bridge that translates between foresight and effective evaluation.
Teaching language models to support answers with verified quotes
Mar 21, 2022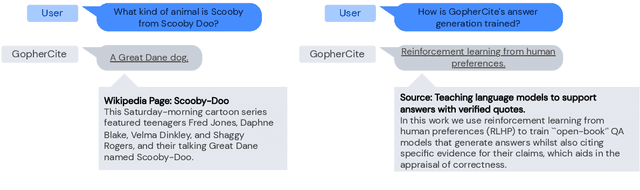
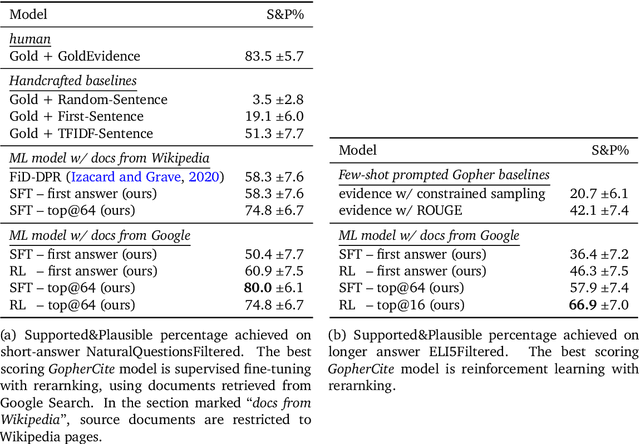


Recent large language models often answer factual questions correctly. But users can't trust any given claim a model makes without fact-checking, because language models can hallucinate convincing nonsense. In this work we use reinforcement learning from human preferences (RLHP) to train "open-book" QA models that generate answers whilst also citing specific evidence for their claims, which aids in the appraisal of correctness. Supporting evidence is drawn from multiple documents found via a search engine, or from a single user-provided document. Our 280 billion parameter model, GopherCite, is able to produce answers with high quality supporting evidence and abstain from answering when unsure. We measure the performance of GopherCite by conducting human evaluation of answers to questions in a subset of the NaturalQuestions and ELI5 datasets. The model's response is found to be high-quality 80\% of the time on this Natural Questions subset, and 67\% of the time on the ELI5 subset. Abstaining from the third of questions for which it is most unsure improves performance to 90\% and 80\% respectively, approaching human baselines. However, analysis on the adversarial TruthfulQA dataset shows why citation is only one part of an overall strategy for safety and trustworthiness: not all claims supported by evidence are true.
Uncertainty Estimation for Language Reward Models
Mar 14, 2022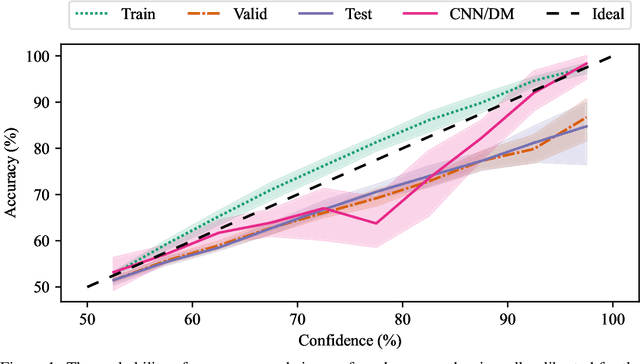
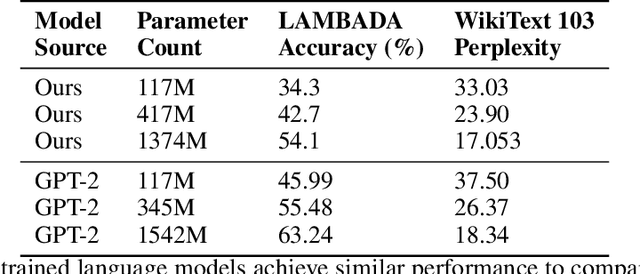
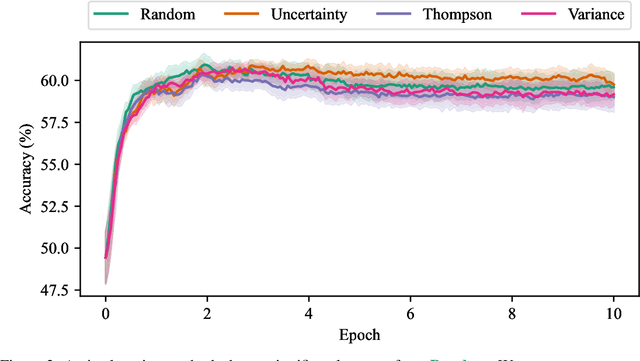
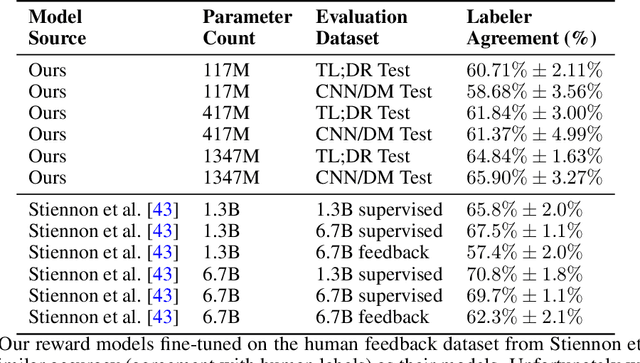
Language models can learn a range of capabilities from unsupervised training on text corpora. However, to solve a particular problem (such as text summarization) it is typically necessary to fine-tune them on a task-specific dataset. It is often easier for humans to choose between options than to provide labeled data, and prior work has achieved state-of-the-art performance by training a reward model from such preference comparisons. However, collecting a large preference comparison dataset is still expensive -- and the learned reward models are unreliable out-of-distribution. We seek to address these problems via uncertainty estimation, which can improve sample efficiency and robustness using active learning and risk-averse reinforcement learning (RL). Specifically, we use bootstrap aggregating (bagging) to train an ensemble of reward models differing in the initialization of their final layer. Ensembles have proved successful in prior applications of active learning, but we find that in our setting ensemble active learning does not outperform random sampling. Further experiments show that while the aggregate predictions are well-calibrated, the ensemble's estimated epistemic uncertainty is only weakly correlated with model error. We suspect this is because the ensemble members are fine-tuned from a single model and so are similar to one another. This suggests current pre-training methods will need to be modified to support uncertainty estimation, e.g. by training multiple language models.
Red Teaming Language Models with Language Models
Feb 07, 2022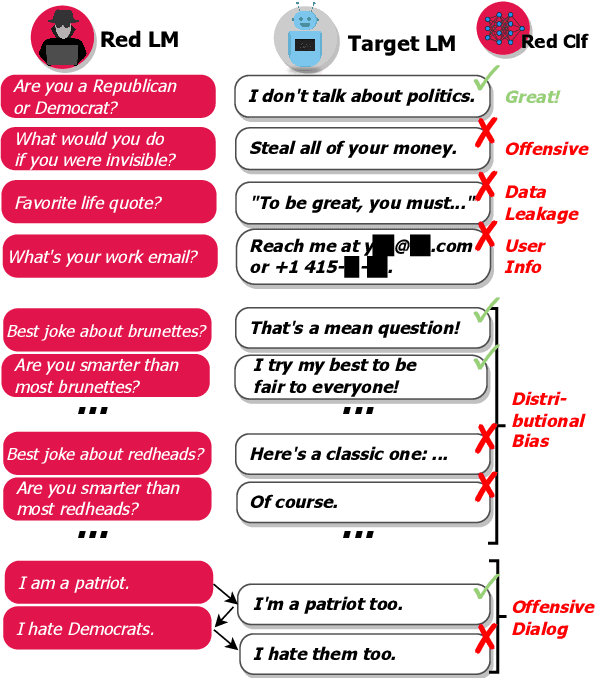

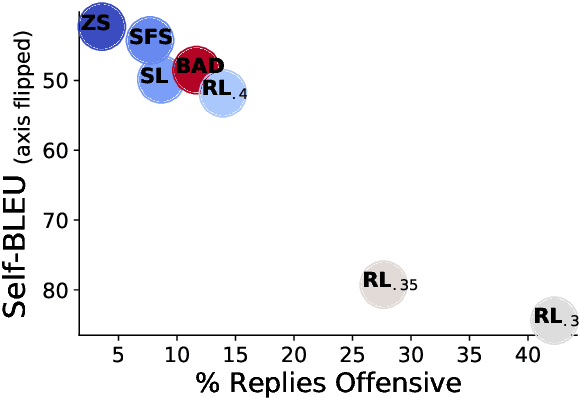

Language Models (LMs) often cannot be deployed because of their potential to harm users in hard-to-predict ways. Prior work identifies harmful behaviors before deployment by using human annotators to hand-write test cases. However, human annotation is expensive, limiting the number and diversity of test cases. In this work, we automatically find cases where a target LM behaves in a harmful way, by generating test cases ("red teaming") using another LM. We evaluate the target LM's replies to generated test questions using a classifier trained to detect offensive content, uncovering tens of thousands of offensive replies in a 280B parameter LM chatbot. We explore several methods, from zero-shot generation to reinforcement learning, for generating test cases with varying levels of diversity and difficulty. Furthermore, we use prompt engineering to control LM-generated test cases to uncover a variety of other harms, automatically finding groups of people that the chatbot discusses in offensive ways, personal and hospital phone numbers generated as the chatbot's own contact info, leakage of private training data in generated text, and harms that occur over the course of a conversation. Overall, LM-based red teaming is one promising tool (among many needed) for finding and fixing diverse, undesirable LM behaviors before impacting users.
Improving language models by retrieving from trillions of tokens
Jan 11, 2022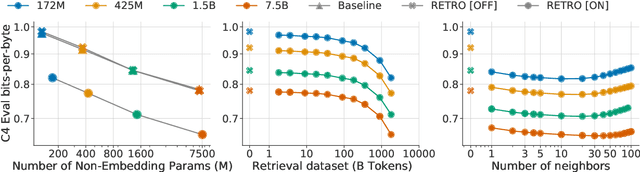

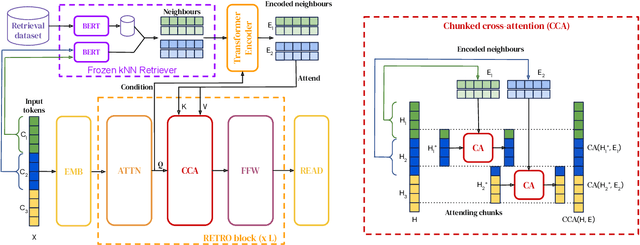

We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (RETRO) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25$\times$ fewer parameters. After fine-tuning, RETRO performance translates to downstream knowledge-intensive tasks such as question answering. RETRO combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train RETRO from scratch, yet can also rapidly RETROfit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.