 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonash University, UEA, UCR Time Series Regression Archive
Jun 22, 2020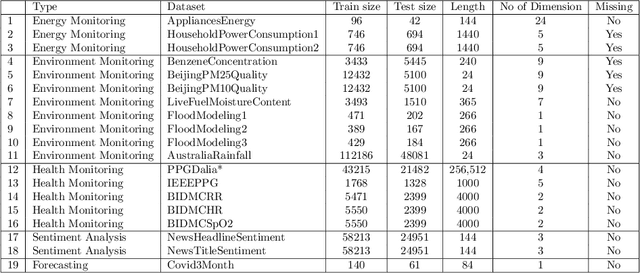
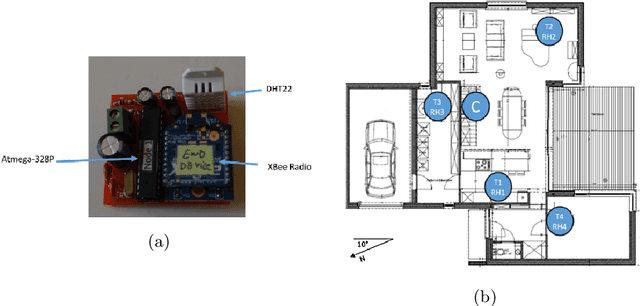
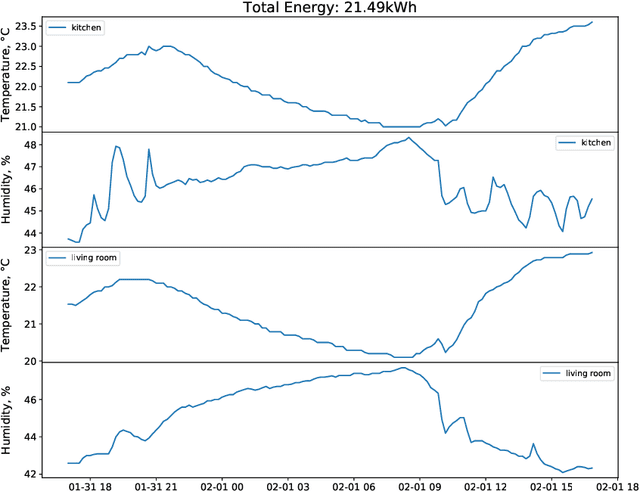
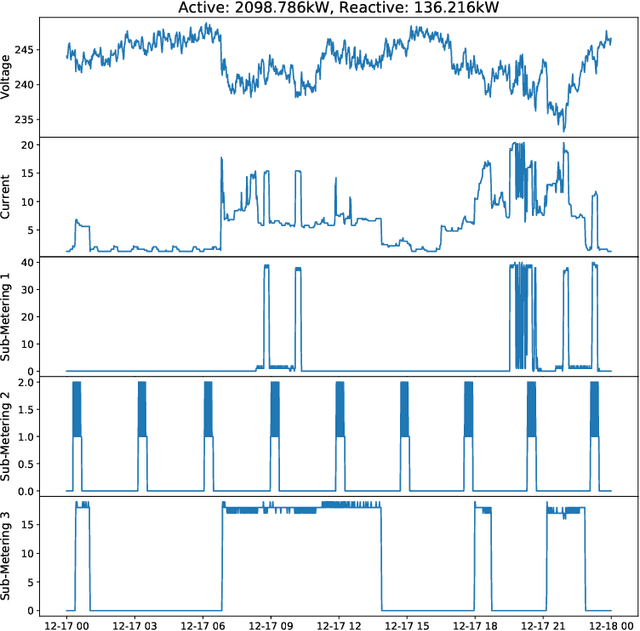
Time series research has gathered lots of interests in the last decade, especially for Time Series Classification (TSC) and Time Series Forecasting (TSF). Research in TSC has greatly benefited from the University of California Riverside and University of East Anglia (UCR/UEA) Time Series Archives. On the other hand, the advancement in Time Series Forecasting relies on time series forecasting competitions such as the Makridakis competitions, NN3 and NN5 Neural Network competitions, and a few Kaggle competitions. Each year, thousands of papers proposing new algorithms for TSC and TSF have utilized these benchmarking archives. These algorithms are designed for these specific problems, but may not be useful for tasks such as predicting the heart rate of a person using photoplethysmogram (PPG) and accelerometer data. We refer to this problem as Time Series Regression (TSR), where we are interested in a more general methodology of predicting a single continuous value, from univariate or multivariate time series. This prediction can be from the same time series or not directly related to the predictor time series and does not necessarily need to be a future value or depend heavily on recent values. To the best of our knowledge, research into TSR has received much less attention in the time series research community and there are no models developed for general time series regression problems. Most models are developed for a specific problem. Therefore, we aim to motivate and support the research into TSR by introducing the first TSR benchmarking archive. This archive contains 19 datasets from different domains, with varying number of dimensions, unequal length dimensions, and missing values. In this paper, we introduce the datasets in this archive and did an initial benchmark on existing models.
A Bayesian-inspired, deep learning, semi-supervised domain adaptation technique for land cover mapping
May 25, 2020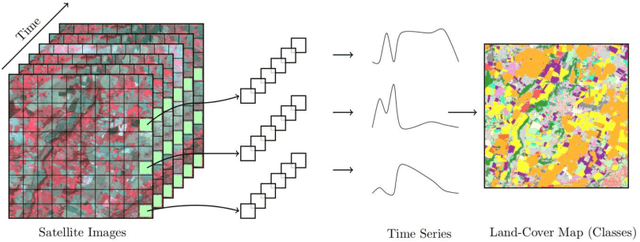
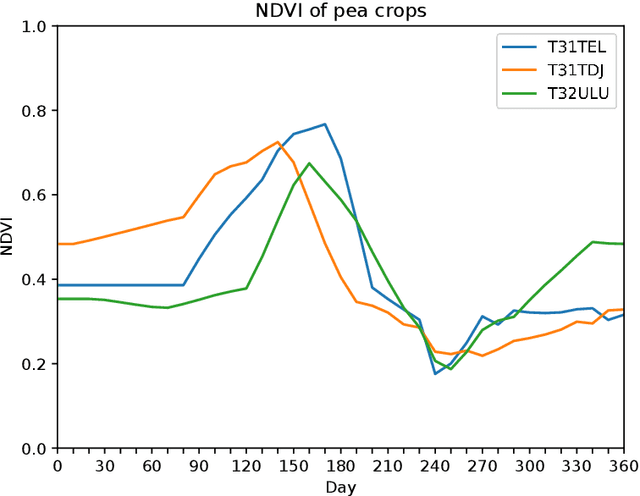
Land cover maps are a vital input variable to many types of environmental research and management. While they can be produced automatically by machine learning techniques, these techniques require substantial training data to achieve high levels of accuracy, which are not always available. One technique researchers use when labelled training data are scarce is domain adaptation (DA) -- where data from an alternate region, known as the source domain, are used to train a classifier and this model is adapted to map the study region, or target domain. The scenario we address in this paper is known as semi-supervised DA, where some labelled samples are available in the target domain. In this paper we present Sourcerer, a Bayesian-inspired, deep learning-based, semi-supervised DA technique for producing land cover maps from SITS data. The technique takes a convolutional neural network trained on a source domain and then trains further on the available target domain with a novel regularizer applied to the model weights. The regularizer adjusts the degree to which the model is modified to fit the target data, limiting the degree of change when the target data are few in number and increasing it as target data quantity increases. Our experiments on Sentinel-2 time series images compare Sourcerer with two state-of-the-art semi-supervised domain adaptation techniques and four baseline models. We show that on two different source-target domain pairings Sourcerer outperforms all other methods for any quantity of labelled target data available. In fact, the results on the more difficult target domain show that the starting accuracy of Sourcerer (when no labelled target data are available), 74.2%, is greater than the next-best state-of-the-art method trained on 20,000 labelled target instances.
ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels
Oct 29, 2019
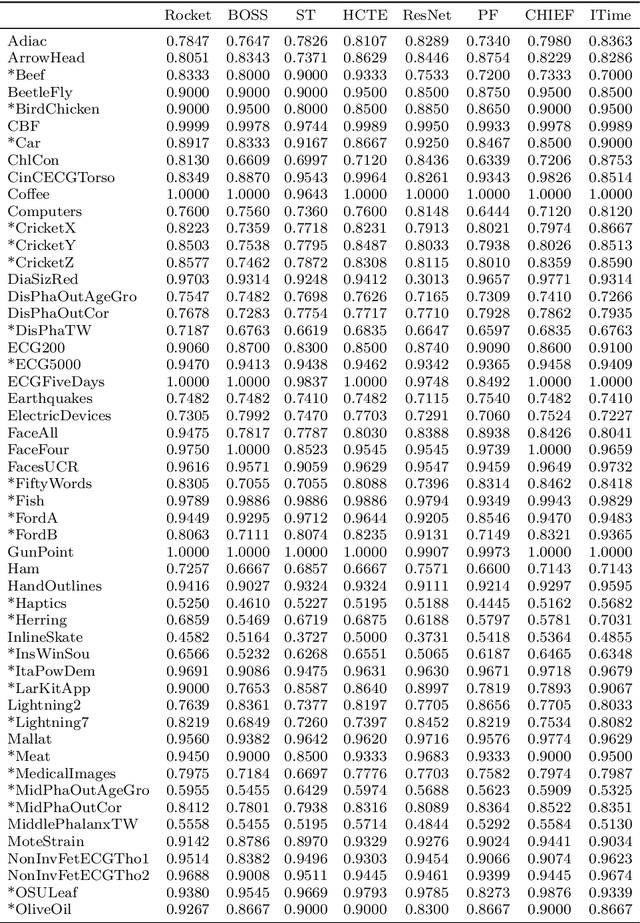
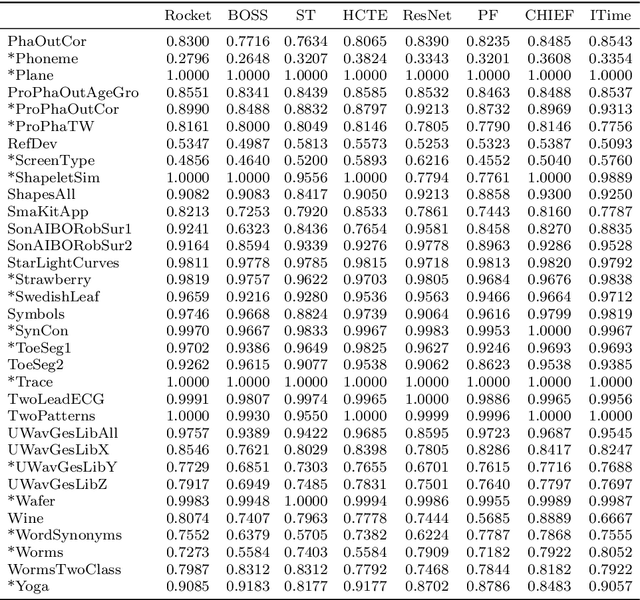
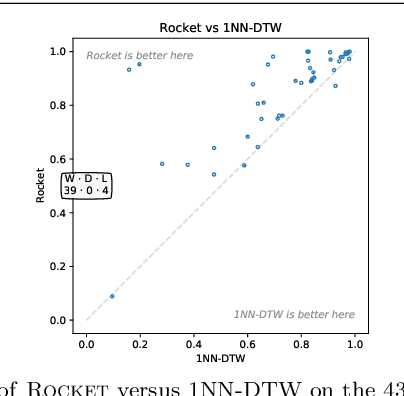
Most methods for time series classification that attain state-of-the-art accuracy have high computational complexity, requiring significant training time even for smaller datasets, and are intractable for larger datasets. Additionally, many existing methods focus on a single type of feature such as shape or frequency. Building on the recent success of convolutional neural networks for time series classification, we show that simple linear classifiers using random convolutional kernels achieve state-of-the-art accuracy with a fraction of the computational expense of existing methods.
Time series classification for varying length series
Oct 10, 2019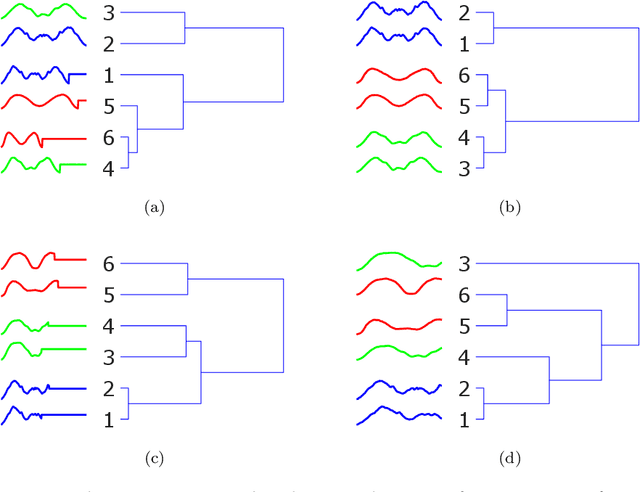
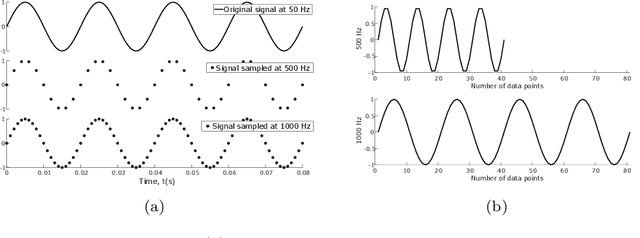
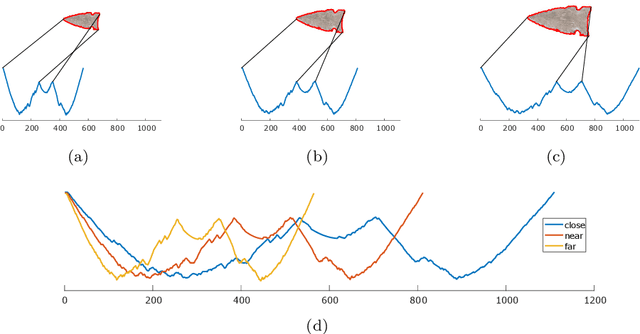
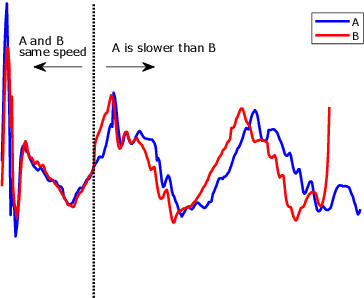
Research into time series classification has tended to focus on the case of series of uniform length. However, it is common for real-world time series data to have unequal lengths. Differing time series lengths may arise from a number of fundamentally different mechanisms. In this work, we identify and evaluate two classes of such mechanisms -- variations in sampling rate relative to the relevant signal and variations between the start and end points of one time series relative to one another. We investigate how time series generated by each of these classes of mechanism are best addressed for time series classification. We perform extensive experiments and provide practical recommendations on how variations in length should be handled in time series classification.
InceptionTime: Finding AlexNet for Time Series Classification
Sep 13, 2019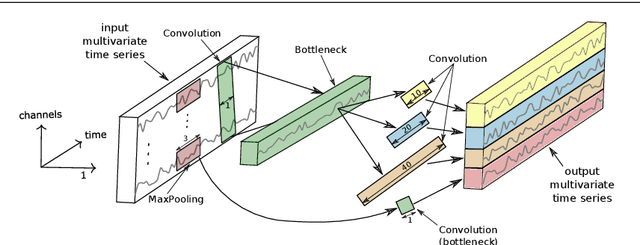
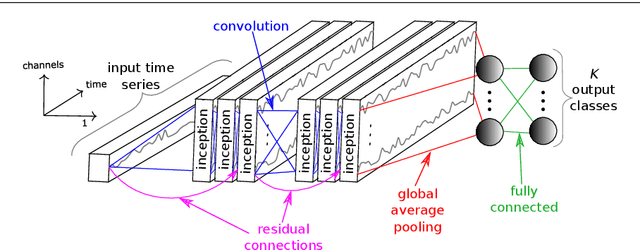
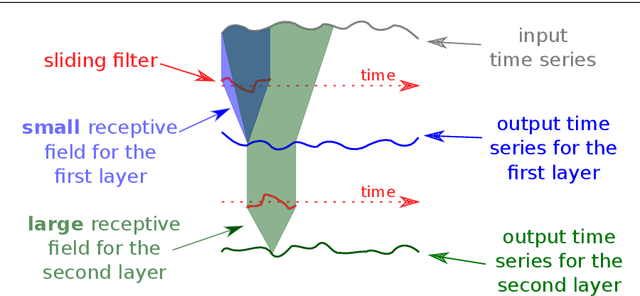
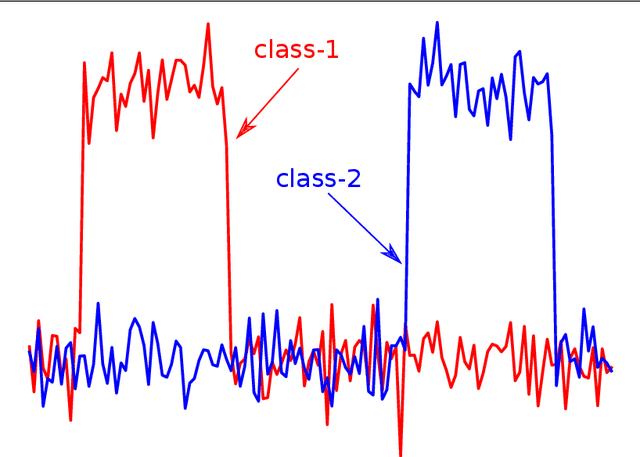
Time series classification (TSC) is the area of machine learning interested in learning how to assign labels to time series. The last few decades of work in this area have led to significant progress in the accuracy of classifiers, with the state of the art now represented by the HIVE-COTE algorithm. While extremely accurate, HIVE-COTE is infeasible to use in many applications because of its very high training time complexity in O(N^2*T^4) for a dataset with N time series of length T. For example, it takes HIVE-COTE more than 72,000s to learn from a small dataset with N=700 time series of short length T=46. Deep learning, on the other hand, has now received enormous attention because of its high scalability and state-of-the-art accuracy in computer vision and natural language processing tasks. Deep learning for TSC has only very recently started to be explored, with the first few architectures developed over the last 3 years only. The accuracy of deep learning for TSC has been raised to a competitive level, but has not quite reached the level of HIVE-COTE. This is what this paper achieves: outperforming HIVE-COTE's accuracy together with scalability. We take an important step towards finding the AlexNet network for TSC by presenting InceptionTime---an ensemble of deep Convolutional Neural Network (CNN) models, inspired by the Inception-v4 architecture. Our experiments show that InceptionTime slightly outperforms HIVE-COTE with a win/draw/loss on the UCR archive of 40/6/39. Not only is InceptionTime more accurate, but it is much faster: InceptionTime learns from that same dataset with 700 time series in 2,300s but can also learn from a dataset with 8M time series in 13 hours, a quantity of data that is fully out of reach of HIVE-COTE.
TS-CHIEF: A Scalable and Accurate Forest Algorithm for Time Series Classification
Jun 25, 2019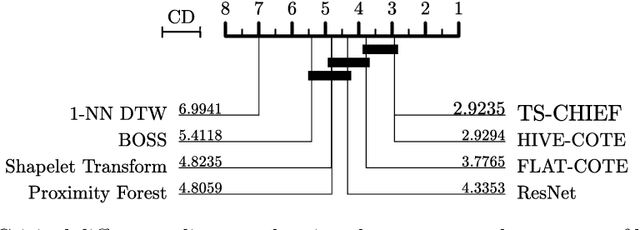
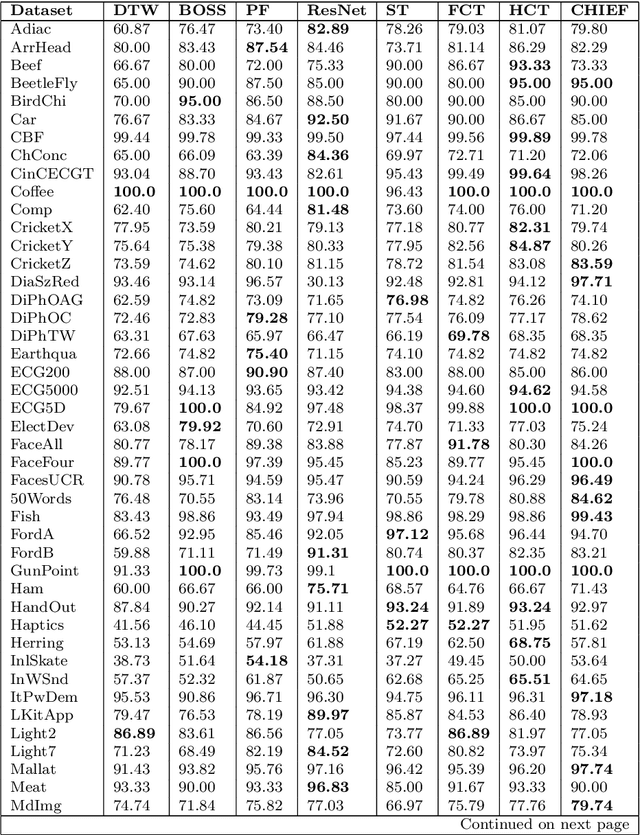
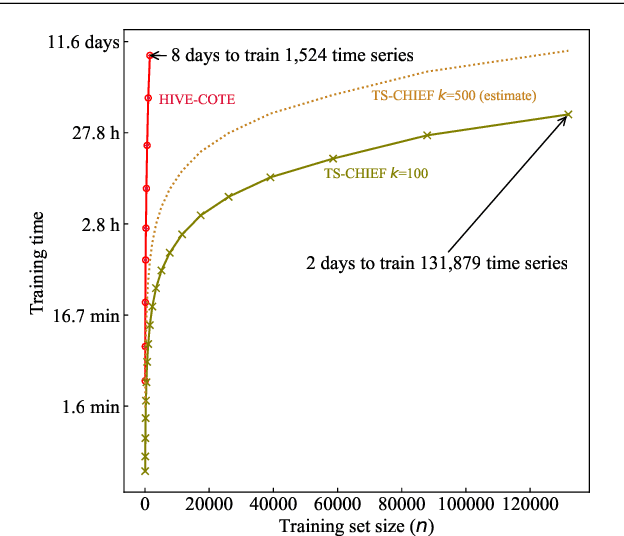
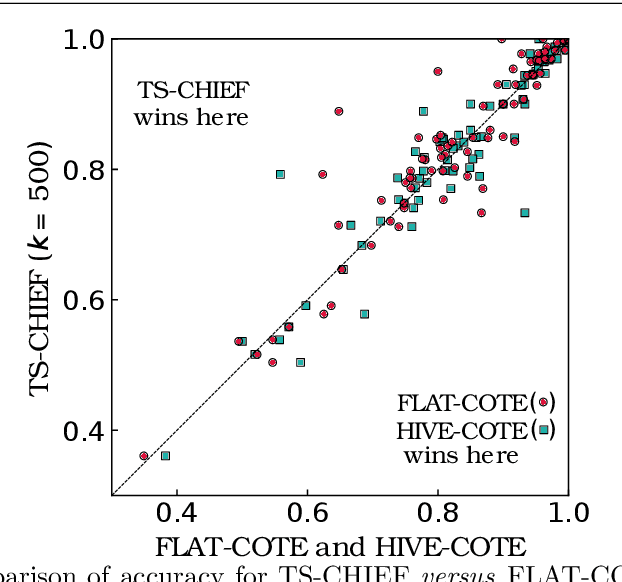
Time Series Classification (TSC) has seen enormous progress over the last two decades. HIVE-COTE (Hierarchical Vote Collective of Transformation-based Ensembles) is the current state of the art in terms of classification accuracy. HIVE-COTE recognizes that time series are a specific data type for which the traditional attribute-value representation, used predominantly in machine learning, fails to provide a relevant representation. HIVE-COTE combines multiple types of classifiers: each extracting information about a specific aspect of a time series, be it in the time domain, frequency domain or summarization of intervals within the series. However, HIVE-COTE (and its predecessor, FLAT-COTE) is often infeasible to run on even modest amounts of data. For instance, training HIVE-COTE on a dataset with only 1,500 time series can require 8 days of CPU time. It has polynomial runtime w.r.t training set size, so this problem compounds as data quantity increases. We propose a novel TSC algorithm, TS-CHIEF, which is highly competitive to HIVE-COTE in accuracy, but requires only a fraction of the runtime. TS-CHIEF constructs an ensemble classifier that integrates the most effective embeddings of time series that research has developed in the last decade. It uses tree-structured classifiers to do so efficiently. We assess TS-CHIEF on 85 datasets of the UCR archive, where it achieves state-of-the-art accuracy with scalability and efficiency. We demonstrate that TS-CHIEF can be trained on 130k time series in 2 days, a data quantity that is beyond the reach of any TSC algorithm with comparable accuracy.
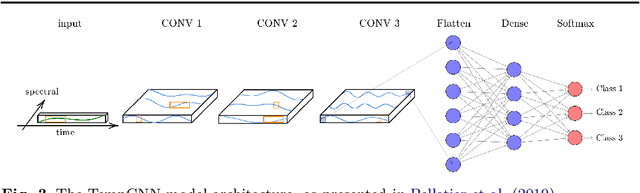
Temporal Convolutional Neural Network for the Classification of Satellite Image Time Series
Nov 26, 2018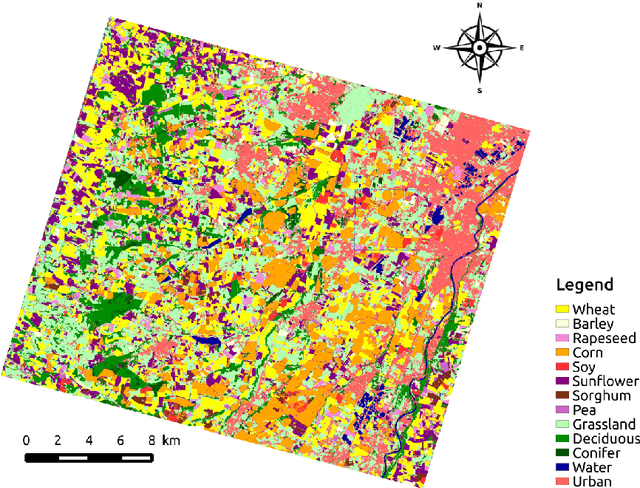

New remote sensing sensors acquire now high spatial and spectral Satellite Image Time Series (SITS) of the world. These series of images are a key component of any classification framework to obtain up-to-date and accurate land cover maps of the Earth's soils. More specifically, the combination of the temporal, spectral and spatial resolutions of new SITS enables the monitoring of vegetation dynamics. Although some traditional classification algorithms, such as Random Forest (RF), have been successfully applied for SITS classification, these algorithms do not fully take advantage of the temporal domain. Conversely, deep-learning based methods have been successfully used to make the most of sequential data such as text and audio data. For the first time, this paper explores the use of Convolutional Neural Networks (CNNs) with convolutions applied in the temporal dimension for SITS classification. The goal is to quantitatively and qualitatively evaluate the contribution of temporal CNNs for SITS classification. More precisely, this paper proposes a set of experiments performed on a million Formosat-2 time series. The experimental results show that temporal CNNs are 2 to 3 % more accurate than RF. The experiments also highlight some counter-intuitive results on pooling layers: contrary to image classification, their use decreases accuracy. Moreover, we provide some general guidelines on the network architecture, common regularization mechanisms, and hyper-parameter values such as the batch size. Finally, the visual quality of the land cover maps produced by the temporal CNN is assessed.
Elastic bands across the path: A new framework and methods to lower bound DTW
Oct 17, 2018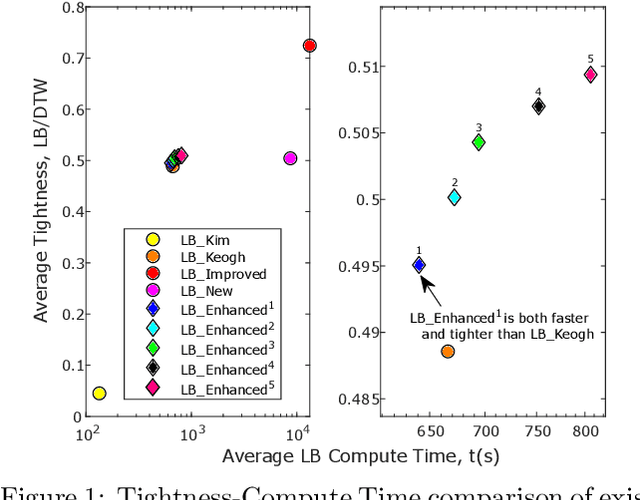
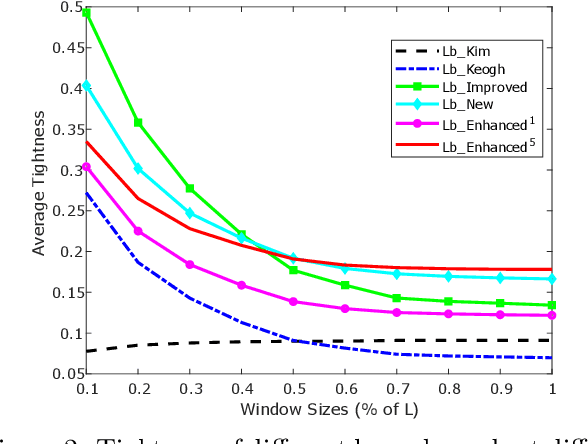
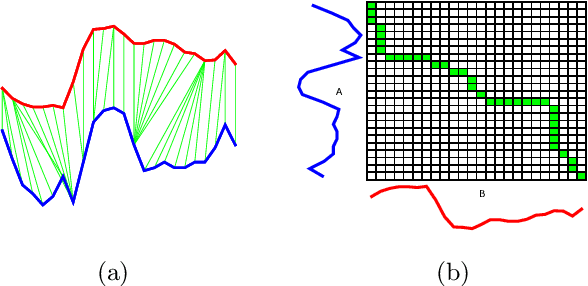
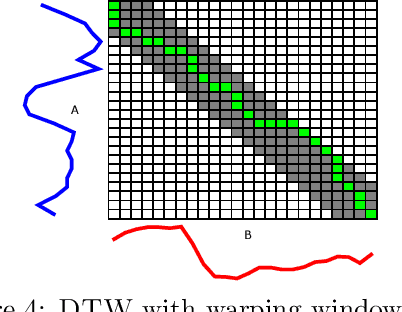
There has been renewed recent interest in developing effective lower bounds for Dynamic Time Warping (DTW) distance between time series. These have many applications in time series indexing, clustering, forecasting, regression and classification. One of the key time series classification algorithms, the nearest neighbor algorithm with DTW distance (NN-DTW) is very expensive to compute, due to the quadratic complexity of DTW. Lower bound search can speed up NN-DTW substantially. An effective and tight lower bound quickly prunes off unpromising nearest neighbor candidates from the search space and minimises the number of the costly DTW computations. The speed up provided by lower bound search becomes increasingly critical as training set size increases. Different lower bounds provide different trade-offs between computation time and tightness. Most existing lower bounds interact with DTW warping window sizes. They are very tight and effective at smaller warping window sizes, but become looser as the warping window increases, thus reducing the pruning effectiveness for NN-DTW. In this work, we present a new class of lower bounds that are tighter than the popular Keogh lower bound, while requiring similar computation time. Our new lower bounds take advantage of the DTW boundary condition, monotonicity and continuity constraints to create a tighter lower bound. Of particular significance, they remain relatively tight even for large windows. A single parameter to these new lower bounds controls the speed-tightness trade-off. We demonstrate that these new lower bounds provide an exceptional balance between computation time and tightness for the NN-DTW time series classification task, resulting in greatly improved efficiency for NN-DTW lower bound search.
Proximity Forest: An effective and scalable distance-based classifier for time series
Aug 31, 2018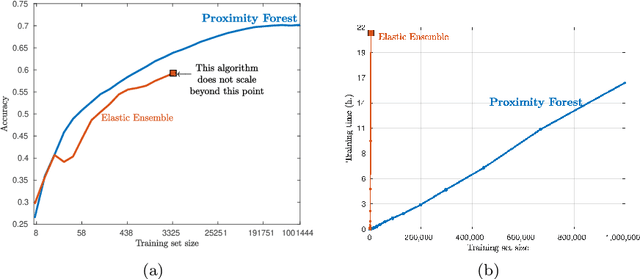
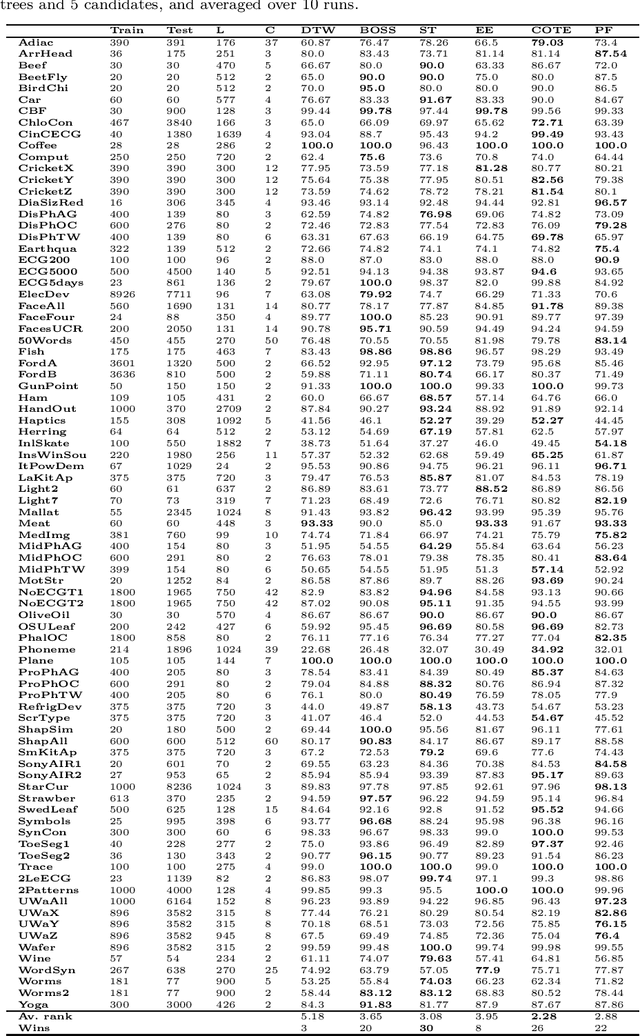
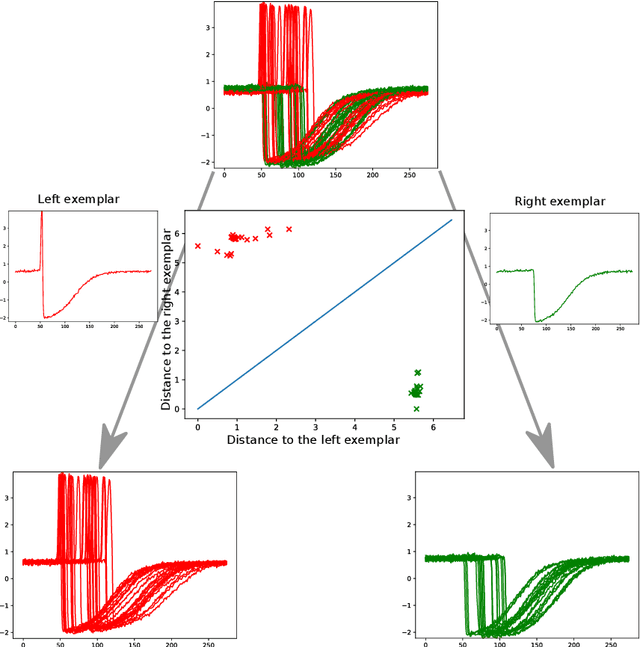
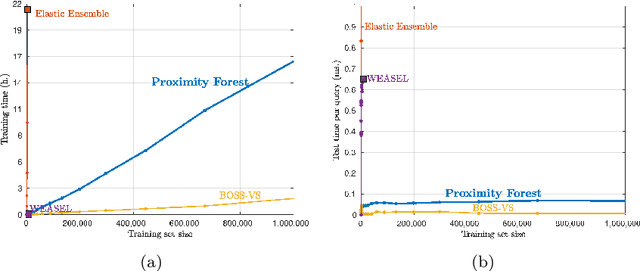
Research into the classification of time series has made enormous progress in the last decade. The UCR time series archive has played a significant role in challenging and guiding the development of new learners for time series classification. The largest dataset in the UCR archive holds 10 thousand time series only; which may explain why the primary research focus has been in creating algorithms that have high accuracy on relatively small datasets. This paper introduces Proximity Forest, an algorithm that learns accurate models from datasets with millions of time series, and classifies a time series in milliseconds. The models are ensembles of highly randomized Proximity Trees. Whereas conventional decision trees branch on attribute values (and usually perform poorly on time series), Proximity Trees branch on the proximity of time series to one exemplar time series or another; allowing us to leverage the decades of work into developing relevant measures for time series. Proximity Forest gains both efficiency and accuracy by stochastic selection of both exemplars and similarity measures. Our work is motivated by recent time series applications that provide orders of magnitude more time series than the UCR benchmarks. Our experiments demonstrate that Proximity Forest is highly competitive on the UCR archive: it ranks among the most accurate classifiers while being significantly faster. We demonstrate on a 1M time series Earth observation dataset that Proximity Forest retains this accuracy on datasets that are many orders of magnitude greater than those in the UCR repository, while learning its models at least 100,000 times faster than current state of the art models Elastic Ensemble and COTE.
An Incremental Construction of Deep Neuro Fuzzy System for Continual Learning of Non-stationary Data Streams
Aug 26, 2018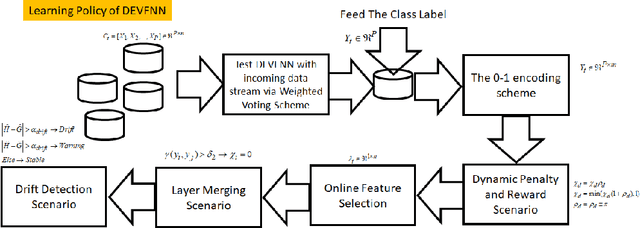
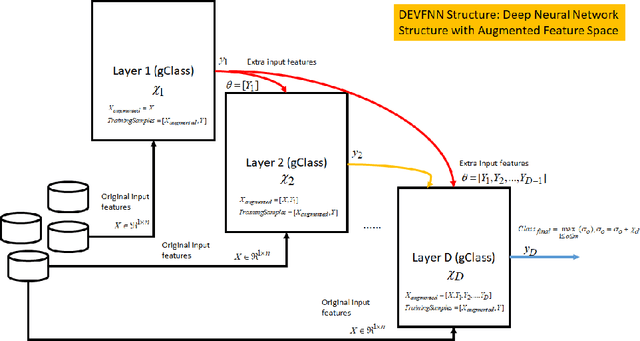
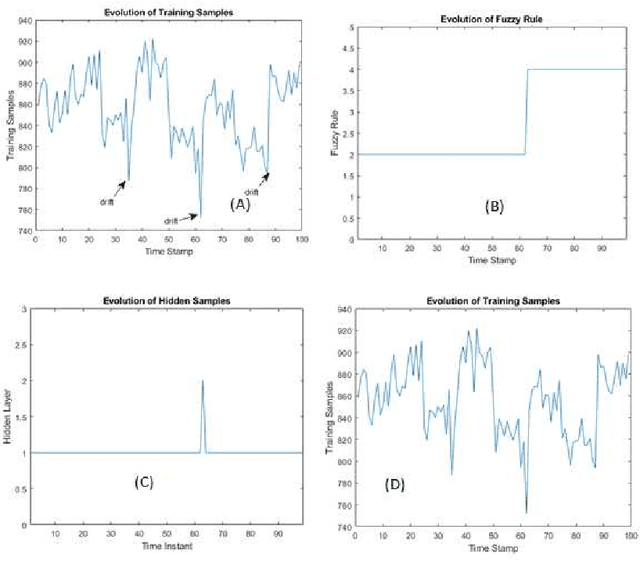
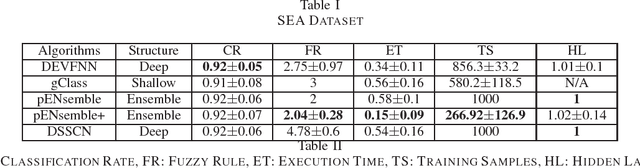
Existing fuzzy neural networks (FNNs) are mostly developed under a shallow network configuration having lower generalization power than those of deep structures. This paper proposes a novel self-organizing deep fuzzy neural network, namely deep evolving fuzzy neural networks (DEVFNN). Fuzzy rules can be automatically extracted from data streams or removed if they play little role during their lifespan. The structure of the network can be deepened on demand by stacking additional layers using a drift detection method which not only detects the covariate drift, variations of input space, but also accurately identifies the real drift, dynamic changes of both feature space and target space. DEVFNN is developed under the stacked generalization principle via the feature augmentation concept where a recently developed algorithm, namely Generic Classifier (gClass), drives the hidden layer. It is equipped by an automatic feature selection method which controls activation and deactivation of input attributes to induce varying subsets of input features. A deep network simplification procedure is put forward using the concept of hidden layer merging to prevent uncontrollable growth of input space dimension due to the nature of feature augmentation approach in building a deep network structure. DEVFNN works in the sample-wise fashion and is compatible for data stream applications. The efficacy of DEVFNN has been thoroughly evaluated using six datasets with non-stationary properties under the prequential test-then-train protocol. It has been compared with four state-of the art data stream methods and its shallow counterpart where DEVFNN demonstrates improvement of classification accuracy.